| Penser en Java 2nde édition | - | Sommaire | Préface | Avant-propos | Chapitre : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Annexe : A B C D | Tables des matières | - | Thinking in Java |
La révolution informatique a pris naissance dans une machine. Nos langages de programmation ont donc tendance à ressembler à cette machine.
Mais les ordinateurs ne sont pas tant des machines que des outils au service de l'esprit (« des vélos pour le cerveau », comme aime à le répéter Steve Jobs) et un nouveau moyen d'expression. Ainsi, ces outils commencent à moins ressembler à des machines et plus à des parties de notre cerveau ou d'autres formes d'expressions telles que l'écriture, la peinture, la sculpture ou la réalisation de films. La Programmation Orientée Objet (POO) fait partie de ce mouvement qui utilise l'ordinateur en tant que moyen d'expression.
Ce chapitre présente les concepts de base de la POO, y compris quelques méthodes de développement. Ce chapitre et ce livre présupposent que vous avez déjà expérimenté avec un langage de programmation procédural, bien que celui-ci ne soit pas forcément le C. Si vous pensez que vous avez besoin de plus de pratique dans la programmation et / ou la syntaxe du C avant de commencer ce livre, vous devriez explorer le CD ROM fourni avec le livre, Thinking in C: Foundations for C++ and Java, aussi disponible sur www.BruceEckel.com.
Ce chapitre tient plus de la culture générale. Beaucoup de personnes ne veulent pas se lancer dans la programmation orientée objet sans en comprendre d'abord les tenants et les aboutissants. C'est pourquoi nous allons introduire ici de nombreux concepts afin de vous donner un solide aperçu de la POO. Au contraire, certaines personnes ne saisissent les concepts généraux qu'après en avoir vu quelques mécanismes mis en oeuvre ; ces gens-là se sentent perdus s'ils n'ont pas un bout de code à se mettre sous la dent. Si vous faites partie de cette catégorie de personnes et êtes impatients d'attaquer les spécificités du langage, vous pouvez sauter ce chapitre - cela ne vous gênera pas pour l'écriture de programme ou l'apprentissage du langage. Mais vous voudrez peut-être y revenir plus tard pour approfondir vos connaissances sur les objets, les comprendre et assimiler la conception objet.
Tous les langages de programmation fournissent des abstractions. On peut dire que la complexité des problèmes qu'on est capable de résoudre est directement proportionnelle au type et à la qualité de nos capacités d'abstraction. Par « type », il faut comprendre « Qu'est-ce qu'on tente d'abstraire ? ». Le langage assembleur est une petite abstraction de la machine sous-jacente. Beaucoup de langages « impératifs » (tels que Fortran, BASIC, et C) sont des abstractions du langage assembleur. Ces langages sont de nettes améliorations par rapport à l'assembleur, mais leur abstraction première requiert une réflexion en termes de structure ordinateur plutôt qu'à la structure du problème qu'on essaye de résoudre. Le programmeur doit établir l'association entre le modèle de la machine (dans « l'espace solution », qui est l'endroit où le problème est modélisé, tel que l'ordinateur) et le modèle du problème à résoudre (dans « l'espace problème », qui est l'endroit où se trouve le problème). Les efforts requis pour réaliser cette association, et le fait qu'elle est étrangère au langage de programmation, produit des programmes difficiles à écrire et à maintenir, et comme effet de bord a mené à la création de l'industrie du « Génie Logiciel ».
L'autre alternative à la modélisation de la machine est de modéliser le problème qu'on tente de résoudre. Les premiers langages tels que LISP ou APL choisirent une vue particulière du monde (« Tous les problèmes se ramènent à des listes » ou « Tous les problèmes sont algorithmiques », respectivement). PROLOG convertit tous les problèmes en chaînes de décisions. Des langages ont été créés en vue de programmer par contrainte, ou pour programmer en ne manipulant que des symboles graphiques (ces derniers se sont révélés être trop restrictifs). Chacune de ces approches est une bonne solution pour la classe particulière de problèmes pour laquelle ils ont été conçus, mais devient une horreur dès lors que vous les sortez de leur domaine d'application.
L'approche orientée objet va un cran plus loin en fournissant des outils au programmeur pour représenter des éléments dans l'espace problème. Cette représentation se veut assez générale pour ne pas restreindre le programmeur à un type particulier de problèmes. Nous nous référons aux éléments dans l'espace problème et leur représentation dans l'espace solution en tant qu'« objets ». (Bien sûr, on aura aussi besoin d'autres objets qui n'ont pas leur analogue dans l'espace problème). L'idée est que le programme est autorisé à s'adapter à l'esprit du problème en ajoutant de nouveaux types d'objet, de façon à ce que, quand on lit le code décrivant la solution, on lit aussi quelque chose qui décrit le problème. C'est une abstraction plus flexible et puissante que tout ce qu'on a pu voir jusqu'à présent. Ainsi, la POO permet de décrire le problème avec les termes mêmes du problème plutôt qu'avec les termes de la machine où la solution sera mise en oeuvre. Il y a tout de même une connexion avec l'ordinateur, bien entendu. Chaque objet ressemble à un mini-ordinateur ; il a un état, et il a à sa disposition des opérations qu'on peut lui demander d'exécuter. Cependant, là encore on retrouve une analogie avec les objets du monde réel - ils ont tous des caractéristiques et des comportements.
Des concepteurs de langage ont décrété que la programmation orientée objet en elle-même n'était pas adéquate pour résoudre facilement tous les problèmes de programmation, et recommandent la combinaison d'approches variées dans des langages de programmation multiparadigmes.[2]
Alan Kay résume les cinq caractéristiques principales de Smalltalk, le premier véritable langage de programmation orienté objet et l'un des langages sur lequel est basé Java. Ces caractéristiques représentent une approche purement orientée objet :
Aristote fut probablement le premier à commencer une étude approfondie du concept de type ; il parle de « la classe des poissons et la classe des oiseaux ». L'idée que tous les objets, tout en étant uniques, appartiennent à une classe d'objets qui ont des caractéristiques et des comportements en commun fut utilisée directement dans le premier langage orienté objet, Simula-67, avec son mot clef fondamental class qui introduit un nouveau type dans un programme.
Simula, comme son nom l'indique, a été conçu pour développer des simulations telles qu'un guichet de banque. Dans celle-ci, vous avez un ensemble de guichetiers, de clients, de comptes, de transactions et de devises - un tas « d'objets ». Des objets semblables, leur état durant l'exécution du programme mis à part, sont groupés ensemble en tant que « classes d'objets » et c'est de là que vient le mot clef class. Créer des types de données abstraits (des classes) est un concept fondamental dans la programmation orientée objet. On utilise les types de données abstraits exactement de la même manière que les types de données prédéfinis. On peut créer des variables d'un type particulier (appelés objets ou instances dans le jargon OO) et manipuler ces variables (ce qu'on appelle envoyer des messages ou des requêtes ; on envoie un message et l'objet se débrouille pour le traiter). Les membres (éléments) d'une même classe partagent des caractéristiques communes : chaque compte dispose d'un solde, chaque guichetier peut accepter un dépôt, etc... Cependant, chaque élément a son propre état : chaque compte a un solde différent, chaque guichetier a un nom. Ainsi, les guichetiers, clients, comptes, transactions, etc... peuvent tous être représentés par la même entité au sein du programme. Cette entité est l'objet, et chaque objet appartient à une classe particulière qui définit ses caractéristiques et ses comportements.
Donc, comme la programmation orientée objet consiste en la création de nouveaux types de données, quasiment tous les langages orientés objet utilisent le mot clef « class ». Quand vous voyez le mot « type » pensez « classe » et inversement [3].
Comme une classe décrit un ensemble d'objets partageant des caractéristiques communes (données) et des comportements (fonctionnalités), une classe est réellement un type de données. En effet, un nombre en virgule flottante par exemple, dispose d'un ensemble de caractéristiques et de comportements. La différence est qu'un programmeur définit une classe pour représenter un problème au lieu d'être forcé d'utiliser un type de données conçu pour représenter une unité de stockage de l'ordinateur. Le langage de programmation est étendu en ajoutant de nouveaux types de données spécifiques à nos besoins. Le système de programmation accepte la nouvelle classe et lui donne toute l'attention et le contrôle de type qu'il fournit aux types prédéfinis.
L'approche orientée objet n'est pas limitée aux simulations. Que vous pensiez ou non que tout programme n'est qu'une simulation du système qu'on représente, l'utilisation des techniques de la POO peut facilement réduire un ensemble de problèmes à une solution simple.
Une fois qu'une classe est créée, on peut créer autant d'objets de cette classe qu'on veut et les manipuler comme s'ils étaient les éléments du problème qu'on tente de résoudre. En fait, l'une des difficultés de la programmation orientée objet est de créer une association un-à-un entre les éléments de l'espace problème et les éléments de l'espace solution.
Mais comment utiliser un objet ? Il faut pouvoir lui demander d'exécuter une requête, telle que terminer une transaction, dessiner quelque chose à l'écran, ou allumer un interrupteur. Et chaque objet ne peut traiter que certaines requêtes. Les requêtes qu'un objet est capable de traiter sont définies par son interface, et son type est ce qui détermine son interface. Prenons l'exemple d'une ampoule électrique :
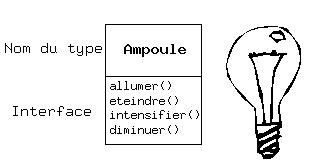
L'interface précise quelles opérations on peut effectuer sur un objet particulier. Cependant, il doit exister du code quelque part pour satisfaire cette requête. Ceci, avec les données cachées, constitue l'implémentation. Du point de vue de la programmation procédurale, ce n'est pas si compliqué. Un type dispose d'une fonction associée à chaque requête possible, et quand on effectue une requête particulière sur un objet, cette fonction est appelée. Ce mécanisme est souvent résumé en disant qu'on « envoie un message » (fait une requête) à un objet, et l'objet se débrouille pour l'interpréter (il exécute le code associé).
Ici, le nom du type / de la classe est Ampoule, le nom de l'objet Ampoule créé est amp, et on peut demander à un objet Ampoule de s'allumer, de s'éteindre, d'intensifier ou de diminuer sa luminosité. Un objet Ampoule est créé en définissant une « référence » (amp) pour cet objet et en appelant new pour créer un nouvel objet de ce type. Pour envoyer un message à cet objet, il suffit de spécifier le nom de l'objet suivi de la requête avec un point entre les deux. Du point de vue de l'utilisateur d'une classe prédéfinie, c'est tout ce qu'il est besoin de savoir pour programmer avec des objets.
L'illustration ci-dessus reprend le formalisme UML (Unified Modeling Language). Chaque classe est représentée par une boîte, avec le nom du type dans la partie supérieure, les données membres qu'on décide de décrire dans la partie du milieu et les fonctions membres (les fonctions appartenant à cet objet qui reçoivent les messages envoyées à cet objet) dans la partie du bas de la boîte. Souvent on ne montre dans les diagrammes UML que le nom de la classe et les fonctions publiques, et la partie du milieu n'existe donc pas. Si seul le nom de la classe nous intéresse, alors la portion du bas n'a pas besoin d'être montrée non plus.
Il est plus facile de diviser les personnes en créateurs de classe (ceux qui créent les nouveaux types de données) et programmeurs clients [4] (ceux qui utilisent ces types de données dans leurs applications). Le but des programmeurs clients est de se monter une boîte à outils pleine de classes réutilisables pour le développement rapide d'applications (RAD, Rapid Application Development en anglais). Les créateurs de classes, eux, se focalisent sur la construction d'une classe qui n'expose que le nécessaire aux programmeurs clients et cache tout le reste. Pourquoi cela ? Parce que si c'est caché, le programmeur client ne peut l'utiliser, et le créateur de la classe peut changer la portion cachée comme il l'entend sans se préoccuper de l'impact que cela pourrait avoir chez les utilisateurs de sa classe. La portion cachée correspond en général aux données de l'objet qui pourraient facilement être corrompues par un programmeur client négligent ou mal informé. Ainsi, cacher l'implémentation réduit considérablement les bugs.
Le concept d'implémentation cachée ne saurait être trop loué : dans chaque relation il est important de fixer des frontières respectées par toutes les parties concernées. Quand on crée une bibliothèque, on établit une relation avec un programmeur client, programmeur qui crée une application (ou une bibliothèque plus conséquente) en utilisant notre bibliothèque.
Si tous les membres d'une classe sont accessibles pour tout le monde, alors le programmeur client peut faire ce qu'il veut avec cette classe et il n'y a aucun moyen de faire respecter certaines règles. Même s'il est vraiment préférable que l'utilisateur de la classe ne manipule pas directement certains membres de la classe, sans contrôle d'accès il n'y a aucun moyen de l'empêcher : tout est exposé à tout le monde.
La raison première du contrôle d'accès est donc d'empêcher les programmeurs clients de toucher à certaines portions auxquelles ils ne devraient pas avoir accès - les parties qui sont nécessaires pour les manipulations internes du type de données mais n'appartiennent pas à l'interface dont les utilisateurs ont besoin pour résoudre leur problème. C'est en réalité un service rendu aux utilisateurs car ils peuvent voir facilement ce qui est important pour leurs besoins et ce qu'ils peuvent ignorer.
La deuxième raison d'être du contrôle d'accès est de permettre au concepteur de la bibliothèque de changer le fonctionnement interne de la classe sans se soucier des effets que cela peut avoir sur les programmeurs clients. Par exemple, on peut implémenter une classe particulière d'une manière simpliste afin d'accélérer le développement, et se rendre compte plus tard qu'on a besoin de la réécrire afin de gagner en performances. Si l'interface et l'implémentation sont clairement séparées et protégées, cela peut être réalisé facilement.
Java utilise trois mots clefs pour fixer des limites au sein d'une classe : public, private et protected. Leur signification et leur utilisation est relativement explicite. Ces spécificateurs d'accès déterminent qui peut utiliser les définitions qui suivent. public veut dire que les définitions suivantes sont disponibles pour tout le monde. Le mot clef private, au contraire, veut dire que personne, le créateur de la classe et les fonctions internes de ce type mis à part, ne peut accéder à ces définitions. private est un mur de briques entre le créateur de la classe et le programmeur client. Si quelqu'un tente d'accéder à un membre défini comme private, ils récupèreront une erreur lors de la compilation. protected se comporte comme private, en moins restrictif : une classe dérivée a accès aux membres protected, mais pas aux membres private. L'héritage sera introduit bientôt.
Java dispose enfin d'un accès « par défaut », utilisé si aucun de ces spécificateurs n'est mentionné. Cet accès est souvent appelé accès « amical » car les classes peuvent accéder aux membres amicaux des autres classes du même package, mais en dehors du package ces mêmes membres amicaux se comportent comme des attributs private.
Une fois qu'une classe a été créée et testée, elle devrait (idéalement) représenter une partie de code utile. Il s'avère que cette réutilisabilité n'est pas aussi facile à obtenir que cela ; cela demande de l'expérience et de l'anticipation pour produire un bon design. Mais une fois bien conçue, cette classe ne demande qu'à être réutilisée. La réutilisation de code est l'un des plus grands avantages que les langages orientés objets fournissent.
La manière la plus simple de réutiliser une classe est d'utiliser directement un objet de cette classe, mais on peut aussi placer un objet de cette classe à l'intérieur d'une nouvelle classe. On appelle cela « créer un objet membre ». La nouvelle classe peut être constituée de n'importe quel nombre d'objets d'autres types, selon la combinaison nécessaire pour que la nouvelle classe puisse réaliser ce pour quoi elle a été conçue. Parce que la nouvelle classe est composée à partir de classes existantes, ce concept est appelé composition (ou, plus généralement, agrégation). On se réfère souvent à la composition comme à une relation « possède-un », comme dans « une voiture possède un moteur ».
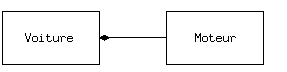
(Le diagramme UML ci-dessus indique la composition avec le losange rempli, qui indique qu'il y a un moteur dans une voiture. J'utiliserai une forme plus simple : juste une ligne, sans le losange, pour indiquer une association [5].)
La composition s'accompagne d'une grande flexibilité : les objets membres de la nouvelle classe sont généralement privés, ce qui les rend inaccessibles aux programmeurs clients de la classe. Cela permet de modifier ces membres sans perturber le code des clients existants. On peut aussi changer les objets membres lors la phase d'exécution, pour changer dynamiquement le comportement du programme. L'héritage, décrit juste après, ne dispose pas de cette flexibilité car le compilateur doit placer des restrictions lors de la compilation sur les classes créées avec héritage.
Parce que la notion d'héritage est très importante au sein de la programmation orientée objet, elle est trop souvent martelée, et le nouveau programmeur pourrait croire que l'héritage doit être utilisé partout. Cela mène à des conceptions ultra compliquées et cauchemardesques. La composition est la première approche à examiner lorsqu'on crée une nouvelle classe, car elle est plus simple et plus flexible. Le design de la classe en sera plus propre. Avec de l'expérience, les endroits où utiliser l'héritage deviendront raisonnablement évidents.
L'idée d'objet en elle-même est un outil efficace. Elle permet de fournir des données et des fonctionnalités liées entre elles par concept, afin de représenter une idée de l'espace problème plutôt que d'être forcé d'utiliser les idiomes internes de la machine. Ces concepts sont exprimés en tant qu'unité fondamentale dans le langage de programmation en utilisant le mot clef class.
Il serait toutefois dommage, après s'être donné beaucoup de mal pour créer une classe de devoir en créer une toute nouvelle qui aurait des fonctionnalités similaires. Ce serait mieux si on pouvait prendre la classe existante, la cloner, et faire des ajouts ou des modifications à ce clone. C'est ce que l'héritage permet de faire, avec la restriction suivante : si la classe originale (aussi appelée classe de base, superclasse ou classe parent) est changée, le « clone » modifié (appelé classe dérivée, héritée, enfant ou sousclasse) répercutera aussi ces changements.
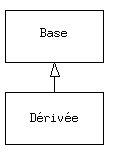
(La flèche dans le diagramme UML ci-dessus pointe de la classe dérivée vers la classe de base. Comme vous le verrez, il peut y avoir plus d'une classe dérivée.)