| Penser en Java 2nde édition | - | Sommaire | Préface | Avant-propos | Chapitre : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Annexe : A B C D | Tables des matières | - | Thinking in Java |
Prenons l'exemple d'une machine de recyclage qui trie les détritus. Le type de base serait « détritus », caractérisé par un poids, une valeur, etc.. et peut être concassé, fondu, ou décomposé. A partir de ce type de base, sont dérivés des types de détritus plus spécifiques qui peuvent avoir des caractéristiques supplémentaires (une bouteille a une couleur) ou des actions additionnelles (une canette peut être découpée, un container d'acier est magnétique). De plus, des comportements peuvent être différents (la valeur du papier dépend de son type et de son état général). En utilisant l'héritage, on peut bâtir une hiérarchie qui exprime le problème avec ses propres termes.
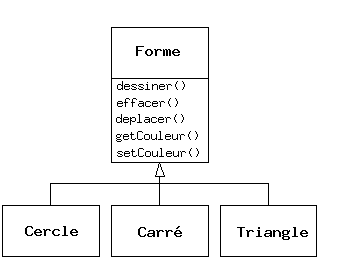
Un autre exemple classique : les « formes géométriques », utilisées entre autres dans les systèmes d'aide à la conception ou dans les jeux vidéos. Le type de base est la « forme géométrique », et chaque forme a une taille, une couleur, une position, etc... Chaque forme peut être dessinée, effacée, déplacée, peinte, etc... A partir de ce type de base, des types spécifiques sont dérivés (hérités) : des cercles, des carrés, des triangles et autres, chacun avec des caractéristiques et des comportements additionnels (certaines figures peuvent être inversées par exemple). Certains comportements peuvent être différents, par exemple quand on veut calculer l'aire de la forme. La hiérarchie des types révèle à la fois les similarités et les différences entre les formes.
Représenter la solution avec les mêmes termes que ceux du problème est extraordinairement bénéfique car on n'a pas besoin de modèles intermédiaires pour passer de la description du problème à la description de la solution. Avec les objets, la hiérarchie de types est le modèle primaire, on passe donc du système dans le monde réel directement au système du code. En fait, l'une des difficultés à laquelle les gens se trouvent confrontés lors de la conception orientée objet est que c'est trop simple de passer du début à la fin. Les esprits habitués à des solutions compliquées sont toujours stupéfaits par cette simplicité.
Quand on hérite d'un certain type, on crée un nouveau type. Ce nouveau type non seulement contient tous les membres du type existant (bien que les membres privés soient cachés et inaccessibles), mais plus important, il duplique aussi l'interface de la classe de la base. Autrement dit, tous les messages acceptés par les objets de la classe de base seront acceptés par les objets de la classe dérivée. Comme on connaît le type de la classe par les messages qu'on peut lui envoyer, cela veut dire que la classe dérivée est du même type que la classe de base. Dans l'exemple précédent, « un cercle est une forme ». Cette équivalence de type via l'héritage est l'une des notions fondamentales dans la compréhension de la programmation orientée objet.
Comme la classe de base et la classe dérivée ont toutes les deux la même interface, certaines implémentations accompagnent cette interface. C'est à dire qu'il doit y avoir du code à exécuter quand un objet reçoit un message particulier. Si on ne fait qu'hériter une classe sans rien lui rajouter, les méthodes de l'interface de la classe de base sont importées dans la classe dérivée. Cela veut dire que les objets de la classe dérivée n'ont pas seulement le même type, ils ont aussi le même comportement, ce qui n'est pas particulièrement intéressant.
Il y a deux façons de différencier la nouvelle classe dérivée de la classe de base originale. La première est relativement directe : il suffit d'ajouter de nouvelles fonctions à la classe dérivée. Ces nouvelles fonctions ne font pas partie de la classe parent. Cela veut dire que la classe de base n'était pas assez complète pour ce qu'on voulait en faire, on a donc ajouté de nouvelles fonctions. Cet usage simple de l'héritage se révèle souvent être une solution idéale. Cependant, il faut tout de même vérifier s'il ne serait pas souhaitable d'intégrer ces fonctions dans la classe de base qui pourrait aussi en avoir l'usage. Ce processus de découverte et d'itération dans la conception est fréquent dans la programmation orientée objet.
Bien que l'héritage puisse parfois impliquer (spécialement en Java, où le mot clef qui indique l'héritage est extends) que de nouvelles fonctions vont être ajoutées à l'interface, ce n'est pas toujours vrai. La seconde et plus importante manière de différencier la nouvelle classe est de changer le comportement d'une des fonctions existantes de la superclasse. Cela s'appelle redéfinir cette fonction.
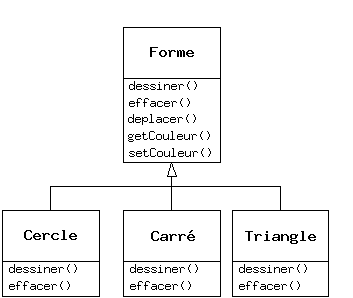
Pour redéfinir une fonction, il suffit de créer une nouvelle définition pour la fonction dans la classe dérivée. C'est comme dire : « j'utilise la même interface ici, mais je la traite d'une manière différente dans ce nouveau type ».
Un certain débat est récurrent à propos de l'héritage : l'héritage ne devrait-il pas seulement redéfinir les fonctions de la classe de base (et ne pas ajouter de nouvelles fonctions membres qui ne font pas partie de la superclasse) ? Cela voudrait dire que le type dérivé serait exactement le même que celui de la classe de base puisqu'il aurait exactement la même interface. Avec comme conséquence logique le fait qu'on puisse exactement substituer un objet de la classe dérivée à un objet de la classe de base. On fait souvent référence à cette substitution pure sous le nom de principe de substitution. Dans un sens, c'est la manière idéale de traiter l'héritage. La relation entre la classe de base et la classe dérivée dans ce cas est une relation est-un, parce qu'on peut dire « un cercle est une forme ». Un test pour l'héritage est de déterminer si la relation est-un entre les deux classes considérées a un sens.
Mais parfois il est nécessaire d'ajouter de nouveaux éléments à l'interface d'un type dérivé, et donc étendre l'interface et créer un nouveau type. Le nouveau type peut toujours être substitué au type de base, mais la substitution n'est plus parfaite parce que les nouvelles fonctions ne sont pas accessibles à partir de la classe parent. On appelle cette relation une relation est-comme-un [6]; le nouveau type dispose de l'interface de l'ancien type mais il contient aussi d'autres fonctions, on ne peut donc pas réellement dire que ce soient exactement les mêmes. Prenons le cas d'un système de climatisation. Supposons que notre maison dispose des tuyaux et des systèmes de contrôle pour le refroidissement, autrement dit elle dispose d'une interface qui nous permet de contrôler le refroidissement. Imaginons que le système de climatisation tombe en panne et qu'on le remplace par une pompe à chaleur, qui peut à la fois chauffer et refroidir. La pompe à chaleur est-comme-un système de climatisation, mais il peut faire plus de choses. Parce que le système de contrôle n'a été conçu que pour contrôler le refroidissement, il en est restreint à ne communiquer qu'avec la partie refroidissement du nouvel objet. L'interface du nouvel objet a été étendue, mais le système existant ne connaît rien qui ne soit dans l'interface originale.
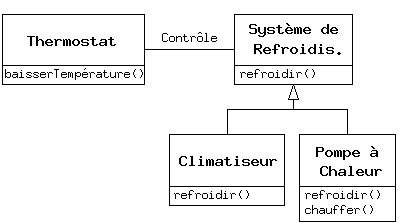
Bien sûr, quand on voit cette modélisation, il est clair que la classe de base « Système de refroidissement » n'est pas assez générale, et devrait être renommée en « Système de contrôle de température » afin de pouvoir inclure le chauffage - auquel cas le principe de substitution marcherait. Cependant, le diagramme ci-dessus est un exemple de ce qui peut arriver dans le monde réel.
Quand on considère le principe de substitution, il est tentant de se dire que cette approche (la substitution pure) est la seule manière correcte de modéliser, et de fait c'est appréciable si la conception fonctionne ainsi. Mais dans certains cas il est tout aussi clair qu'il faut ajouter de nouvelles fonctions à l'interface d'une classe dérivée. En examinant le problème, les deux cas deviennent relativement évidents.
Il arrive qu'on veuille traiter un objet non en tant qu'objet du type spécifique qu'il est, mais en tant qu'objet de son type de base. Cela permet d'écrire du code indépendant des types spécifiques. Dans l'exemple de la forme géométrique, les fonctions manipulent des formes génériques sans se soucier de savoir si ce sont des cercles, des carrés, des triangles ou même des formes non encore définies. Toutes les formes peuvent être dessinées, effacées, et déplacées, donc ces fonctions envoient simplement un message à un objet forme, elles ne se soucient pas de la manière dont l'objet traite le message.
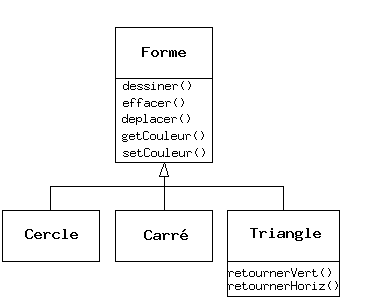
Un tel code n'est pas affecté par l'addition de nouveaux types, et ajouter de nouveaux types est la façon la plus commune d'étendre un programme orienté objet pour traiter de nouvelles situations. Par exemple, on peut dériver un nouveau type de forme appelé pentagone sans modifier les fonctions qui traitent des formes génériques. Cette capacité à étendre facilement un programme en dérivant de nouveaux sous-types est important car il améliore considérablement la conception tout en réduisant le coût de maintenance.
Un problème se pose cependant en voulant traiter les types dérivés comme leur type de base générique (les cercles comme des formes géométriques, les vélos comme des véhicules, les cormorans comme des oiseaux, etc...). Si une fonction demande à une forme générique de se dessiner, ou à un véhicule générique de tourner, ou à un oiseau générique de se déplacer, le compilateur ne peut savoir précisément lors de la phase de compilation quelle portion de code sera exécutée. C'est d'ailleurs le point crucial : quand le message est envoyé, le programmeur ne veut pas savoir quelle portion de code sera exécutée ; la fonction dessiner peut être appliquée aussi bien à un cercle qu'à un carré ou un triangle, et l'objet va exécuter le bon code suivant son type spécifique. Si on n'a pas besoin de savoir quelle portion de code est exécutée, alors le code exécuté lorsque on ajoute un nouveau sous-type peut être différent sans exiger de modification dans l'appel de la fonction. Le compilateur ne peut donc précisément savoir quelle partie de code sera exécutée, donc que va-t-il faire ? Par exemple, dans le diagramme suivant, l'objet Contrôleur d'oiseaux travaille seulement avec des objets Oiseaux génériques, et ne sait pas de quel type ils sont. Cela est pratique du point de vue de Contrôleur d'oiseaux car il n'a pas besoin d'écrire du code spécifique pour déterminer le type exact d'Oiseau avec lequel il travaille, ou le comportement de cet Oiseau. Comment se fait-il donc que, lorsque bouger() est appelé tout en ignorant le type spécifique de l'Oiseau, on obtienne le bon comportement (une Oie court, vole ou nage, et un Pingouin court ou nage) ?
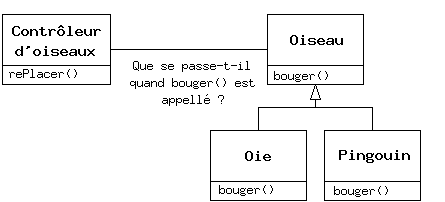
La réponse constitue l'astuce fondamentale de la programmation orientée objet : le compilateur ne peut faire un appel de fonction au sens traditionnel du terme. Un appel de fonction généré par un compilateur non orienté objet crée ce qu'on appelle une association prédéfinie, un terme que vous n'avez sans doute jamais entendu auparavant car vous ne pensiez pas qu'on puisse faire autrement. En d'autres termes, le compilateur génère un appel à un nom de fonction spécifique, et l'éditeur de liens résout cet appel à l'adresse absolue du code à exécuter. En POO, le programme ne peut déterminer l'adresse du code avant la phase d'exécution, un autre mécanisme est donc nécessaire quand un message est envoyé à un objet générique.
Pour résoudre ce problème, les langages orientés objet utilisent le concept d'association tardive. Quand un objet reçoit un message, le code appelé n'est pas déterminé avant l'exécution. Le compilateur s'assure que la fonction existe et vérifie le type des arguments et de la valeur de retour (un langage omettant ces vérifications est dit faiblement typé), mais il ne sait pas exactement quel est le code à exécuter.
Pour créer une association tardive, Java utilise une portion spéciale de code en lieu et place de l'appel absolu. Ce code calcule l'adresse du corps de la fonction, en utilisant des informations stockées dans l'objet (ce mécanisme est couvert plus en détails dans le Chapitre 7). Ainsi, chaque objet peut se comporter différemment suivant le contenu de cette portion spéciale de code. Quand un objet reçoit un message, l'objet sait quoi faire de ce message.
Dans certains langages (en particulier le C++), il faut préciser explicitement qu'on souhaite bénéficier de la flexibilité de l'association tardive pour une fonction. Dans ces langages, les fonctions membres ne sont pas liées dynamiquement par défaut. Cela pose des problèmes, donc en Java l'association dynamique est le défaut et aucun mot clef supplémentaire n'est requis pour bénéficier du polymorphisme.
Reprenons l'exemple de la forme géométrique. Le diagramme de la hiérarchie des classes (toutes basées sur la même interface) se trouve plus haut dans ce chapitre. Pour illustrer le polymorphisme, écrivons un bout de code qui ignore les détails spécifiques du type et parle uniquement à la classe de base. Ce code est déconnecté des informations spécifiques au type, donc plus facile à écrire et à comprendre. Et si un nouveau type - un Hexagone, par exemple - est ajouté grâce à l'héritage, le code continuera de fonctionner aussi bien pour ce nouveau type de Forme qu'il le faisait avec les types existants. Le programme est donc extensible.
Si nous écrivons une méthode en Java (comme vous allez bientôt apprendre à le faire) :
Cette fonction s'adresse à n'importe quelle Forme, elle est donc indépendante du type spécifique de l'objet qu'elle dessine et efface. Si nous utilisons ailleurs dans le programme cette fonction faireQuelqueChose() :
Les appels à faireQuelqueChose() fonctionnent correctement, sans se préoccuper du type exact de l'objet.
En fait c'est une manière de faire très élégante. Considérons la ligne :
Un Cercle est ici passé à une fonction qui attend une Forme. Comme un Cercle est-une Forme, il peut être traité comme tel par faireQuelqueChose(). C'est à dire qu'un Cercle peut accepter tous les messages que faireQuelqueChose() pourrait envoyer à une forme. C'est donc une façon parfaitement logique et sûre de faire.
Traiter un type dérivé comme s'il était son type de base est appelé transtypage ascendant, surtypage ou généralisation (upcasting). L'adjectif ascendant vient du fait que dans un diagramme d'héritage typique, le type de base est représenté en haut, les classes dérivées s'y rattachant par le bas. Ainsi, changer un type vers son type de base revient à remonter dans le diagramme d'héritage : transtypage « ascendant ».
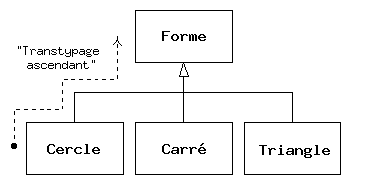
Un programme orienté objet contient obligatoirement des transtypages ascendants, car c'est de cette manière que le type spécifique de l'objet peut être délibérément ignoré. Examinons le code de faireQuelqueChose() :
Remarquez qu'il ne dit pas « Si tu es un Cercle, fais ceci, si tu es un Carré, fais cela, etc... ». Ce genre de code qui vérifie tous les types possibles que peut prendre une Forme est confus et il faut le changer à chaque extension de la classe Forme. Ici, il suffit de dire : « Tu es une forme géométrique, je sais que tu peux te dessiner() et t'effacer(), alors fais-le et occupe-toi des détails spécifiques ».
Ce qui est impressionnant dans le code de faireQuelqueChose(), c'est que tout fonctionne comme on le souhaite. Appeler dessiner() pour un Cercle exécute une portion de code différente de celle exécutée lorsqu'on appelle dessiner() pour un Carré ou une Ligne, mais lorsque le message dessiner() est envoyé à une Forme anonyme, on obtient le comportement idoine basé sur le type réel de la Forme. Cela est impressionnant dans la mesure où le compilateur Java ne sait pas à quel type d'objet il a affaire lors de la compilation du code de faireQuelqueChose(). On serait en droit de s'attendre à un appel aux versions dessiner() et effacer() de la classe de base Forme, et non celles des classes spécifiques Cercle, Carré et Ligne. Mais quand on envoie un message à un objet, il fera ce qu'il a à faire, même quand la généralisation est impliquée. C'est ce qu'implique le polymorphisme. Le compilateur et le système d'exécution s'occupent des détails, et c'est tout ce que vous avez besoin de savoir, en plus de savoir comment modéliser avec.
Dans une modélisation, il est souvent souhaitable qu'une classe de base ne présente qu'une interface pour ses classes dérivées. C'est à dire qu'on ne souhaite pas qu'il soit possible de créer un objet de cette classe de base, mais seulement pouvoir surtyper jusqu'à elle pour pouvoir utiliser son interface. Cela est possible en rendant cette classe abstraite en utilisant le mot clef abstract. Le compilateur se plaindra si une tentative est faite de créer un objet d'une classe définie comme abstract. C'est un outil utilisé pour forcer une certain conception.
Le mot clef abstract est aussi utilisé pour décrire une méthode qui n'a pas encore été implémentée - comme un panneau indiquant « voici une fonction de l'interface dont les types dérivés ont hérité, mais actuellement je n'ai aucune implémentation pour elle ». Une méthode abstract peut seulement être créée au sein d'une classe abstract. Quand cette classe est dérivée, cette méthode doit être implémentée, ou la classe dérivée devient abstract elle aussi. Créer une méthode abstract permet de l'inclure dans une interface sans être obligé de fournir une portion de code éventuellement dépourvue de sens pour cette méthode.
Le mot clef interface pousse le concept de classe abstract un cran plus loin en évitant toute définition de fonction. Une interface est un outil très pratique et très largement répandu, car il fournit une séparation parfaite entre l'interface et l'implémentation. De plus, on peut combiner plusieurs interfaces, alors qu'hériter de multiples classes normales ou abstraites est impossible.
Techniquement, les spécificités de la programmation orientée objet se résument au typage abstrait des données, à l'héritage et au polymorphisme, mais d'autres particularités peuvent se révéler aussi importantes. Le reste de cette section traite de ces particularités.
L'une des particularités les plus importantes est la façon dont les objets sont créés et détruits. Où se trouvent les données d'un objet et comment sa durée de vie est-elle contrôlée ? Différentes philosophies existent. En C++, qui prône que l'efficacité est le facteur le plus important, le programmeur a le choix. Pour une vitesse optimum à l'exécution, le stockage et la durée de vie peuvent être déterminé quand le programme est écrit, en plaçant les objets sur la pile (ces variables sont parfois appelées automatiques ou de portée) ou dans l'espace de stockage statique. La vitesse d'allocation et de libération est dans ce cas prioritaire et leur contrôle peut être vraiment appréciable dans certaines situations. Cependant, cela se fait aux dépends de la flexibilité car il faut connaître la quantité exacte, la durée de vie et le type des objets pendant qu'on écrit le programme. Si le problème à résoudre est plus général, tel que de la modélisation assistée par ordinateur, de la gestion d'entrepôts ou du contrôle de trafic aérien, cela se révèle beaucoup trop restrictif.
La deuxième approche consiste à créer les objets dynamiquement dans un pool de mémoire appelé le segment. Dans cette approche, le nombre d'objets nécessaire n'est pas connu avant l'exécution, de même que leur durée de vie ou leur type exact. Ces paramètres sont déterminés sur le coup, au moment où le programme s'exécute. Si on a besoin d'un nouvel objet, il est simplement créé dans le segment au moment où on en a besoin. Comme le stockage est géré de manière dynamique lors de l'exécution, le temps de traitement requis pour allouer de la place dans le segment est plus important que le temps mis pour stocker sur la pile (stocker sur la pile se résume souvent à une instruction assembleur pour déplacer le pointeur de pile vers le bas, et une autre pour le redéplacer vers le haut). L'approche dynamique fait la supposition généralement justifiée que les objets ont tendance à être compliqués, et que le surcoût de temps dû à la recherche d'une place de stockage et à sa libération n'aura pas d'impact significatif sur la création d'un objet. De plus, la plus grande flexibilité qui en résulte est essentielle pour résoudre le problème modélisé par le programme.