| Penser en Java 2nde édition | - | Sommaire | Préface | Avant-propos | Chapitre : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Annexe : A B C D | Tables des matières | - | Thinking in Java |
Le Web est la solution la plus générique au problème du client/serveur, il est donc logique de vouloir appliquer la même technologie pour résoudre ceux liés aux client/serveur à l'intérieur d'une entreprise. Avec l'approche traditionnelle du client/serveur se pose le problème de l'hétérogénéité du parc de clients, de même que les difficultés pour installer les nouveaux logiciels clients. Ces problèmes sont résolus par les browsers Web et la programmation côté client. Quand la technologie du Web est utilisée dans le système d'information d'une entreprise, on s'y réfère en tant qu'intranet. Les intranets fournissent une plus grande sécurité qu'Internet puisqu'on peut contrôler les accès physiques aux serveurs à l'intérieur de l'entreprise. En terme d'apprentissage, il semblerait qu'une fois que les utilisateurs se sont familiarisés avec le concept d'un browser il leur est plus facile de gérer les différences de conception entre les pages et applets, et le coût d'apprentissage de nouveaux systèmes semble se réduire.
Le problème de la sécurité nous mène à l'une des divisions qui semble se former automatiquement dans le monde de la programmation côté client. Si un programme est distribué sur Internet, on ne sait pas sur quelle plateforme il va tourner et il faut être particulièrement vigilant pour ne pas diffuser du code buggué. Il faut une solution multiplateformes et sûre, comme un langage de script ou Java.
Dans le cas d'un intranet, les contraintes peuvent être complètement différentes. Le temps passé à installer les nouvelles versions est la raison principale qui pousse à passer aux browsers, car les mises à jours sont invisibles et automatiques. Il n'est pas rare que tous les clients soient des plateformes Wintel (Intel / Windows). Dans un intranet, on est responsable de la qualité du code produit et on peut corriger les bugs quand ils sont découverts. De plus, on dispose du code utilisé dans une approche plus traditionnelle du client/serveur où il fallait installer physiquement le client à chaque mise à jour du logiciel. Dans le cas d'un tel intranet, l'approche la plus raisonnable consiste à choisir la solution qui permettra de réutiliser le code existant plutôt que de repartir de zéro dans un nouveau langage.
Quand on est confronté au problème de la programmation côté client, la meilleure chose à faire est une analyse coûts-bénéfices. Il faut prendre en compte les contraintes du problème, et la solution qui serait la plus rapide à mettre en oeuvre. En effet, comme la programmation côté client reste de la programmation, c'est toujours une bonne idée de choisir l'approche permettant un développement rapide.
Toute cette discussion a passé sous silence la programmation côté serveur. Que se passe-t-il lorsqu'un serveur reçoit une requête ? La plupart du temps cette requête est simplement « envoie-moi ce fichier ». Le browser interprète alors ce fichier d'une manière particulière : comme une page HTML, une image graphique, une applet Java, un programme script, etc... Une requête plus compliquée à un serveur implique généralement une transaction vers une base de données. Un scénario classique consiste en une requête complexe de recherche d'enregistrements dans une base de données que le serveur formate dans une page HTML et renvoie comme résultat (bien sûr, si le client est « intelligent » via Java ou un langage de script, la phase de formatage peut être réalisée par le client et le serveur n'aura qu'a envoyer les données brutes, ce qui allégera la charge et le trafic engendré). Ou alors un client peut vouloir s'enregistrer dans une base de données quand il joint un groupe ou envoie une commande, ce qui implique des changements dans la base de données. Ces requêtes doivent être traitées par du code s'exécutant sur le serveur, c'est ce qu'on appelle la programmation côté serveur. Traditionnellement, la programmation côté serveur s'est appuyée sur Perl et les scripts CGI, mais des systèmes plus sophistiqués sont en train de voir le jour. Cela inclut des serveurs Web écrits en Java qui permettent de réaliser toute la programmation côté serveur en Java en écrivant ce qu'on appelle des servlets. Les servlets et leur progéniture, les JSPs, sont les deux raisons principales qui poussent les entreprises qui développent un site Web à se tourner vers Java, en particulier parce qu'ils éliminent les problèmes liés aux différences de capacité des browsers.
La plupart de la publicité faite autour de Java se référait aux applets. Mais Java est aussi un langage de programmation à vocation plus générale qui peut résoudre n'importe quel type de problème - du moins en théorie. Et comme précisé plus haut, il peut y avoir des moyens plus efficaces de résoudre la plupart des problèmes client/serveur. Quand on quitte la scène des applets (et les restrictions qui y sont liées telles que les accès en écriture sur le disque), on entre dans le monde des applications qui s'exécutent sans le soutien d'un browser, comme n'importe quel programme. Les atouts de Java sont là encore non seulement sa portabilité, mais aussi sa facilité de programmation. Comme vous allez le voir tout au long de ce livre, Java possède beaucoup de fonctionnalités qui permettent de créer des programmes robustes dans un laps de temps plus court qu'avec d'autres langages de programmation.
Mais il faut bien être conscient qu'il s'agit d'un compromis. Le prix à payer pour ces améliorations est une vitesse d'exécution réduite (bien que des efforts significatifs soient mis en oeuvre dans ce domaine - JDK 1.3, en particulier, introduit le concept d'amélioration de performances « hotspot »). Comme tout langage de programmation, Java a des limitations internes qui peuvent le rendre inadéquat pour résoudre certains types de problèmes. Java évolue rapidement cependant, et à chaque nouvelle version il permet d'adresser un spectre de plus en plus large de problèmes.
Le paradigme de la POO constitue une approche nouvelle et différente de la programmation. Beaucoup de personnes rencontrent des difficultés pour appréhender leur premier projet orienté objet. Une fois compris que tout est supposé être un objet, et au fur et à mesure qu'on se met à penser dans un style plus orienté objet, on commence à créer de « bonnes » conceptions qui s'appuient sur tous les avantages que la POO offre.
Une méthode (ou méthodologie) est un ensemble de processus et d'heuristiques utilisés pour réduire la complexité d'un problème. Beaucoup de méthodes orientées objet ont été formulées depuis l'apparition de la POO. Cette section vous donne un aperçu de ce que vous essayez d'accomplir en utilisant une méthode.
Une méthodologie s'appuie sur un certain nombre d'expériences, il est donc important de comprendre quel problème la méthode tente de résoudre avant d'en adopter une. Ceci est particulièrement vrai avec Java, qui a été conçu pour réduire la complexité (comparé au C) dans l'expression d'un programme. Cette philosophie supprime le besoin de méthodologies toujours plus complexes. Des méthodologies simples peuvent se révéler tout à fait suffisantes avec Java pour une classe de problèmes plus large que ce qu'elles ne pourraient traiter avec des langages procéduraux.
Il est important de réaliser que le terme «> méthodologie » est trompeur et promet trop de choses. Tout ce qui est mis en oeuvre quand on conçoit et réalise un programme est une méthode. Ca peut être une méthode personnelle, et on peut ne pas en être conscient, mais c'est une démarche qu'on suit au fur et à mesure de l'avancement du projet. Si cette méthode est efficace, elle ne nécessitera sans doute que quelques petites adaptations pour fonctionner avec Java. Si vous n'êtes pas satisfait de votre productivité ou du résultat obtenu, vous serez peut-être tenté d'adopter une méthode plus formelle, ou d'en composer une à partir de plusieurs méthodes formelles.
Au fur et à mesure que le projet avance, le plus important est de ne pas se perdre, ce qui est malheureusement très facile. La plupart des méthodes d'analyse et de conception sont conçues pour résoudre même les problèmes les plus gros. Il faut donc bien être conscient que la plupart des projets ne rentrant pas dans cette catégorie, on peut arriver à une bonne analyse et conception avec juste une petite partie de ce qu'une méthode recommande href="#fn8" name="fnB8">[8]. Une méthode de conception, même limitée, met sur la voie bien mieux que si on commence à coder directement.
Il est aussi facile de rester coincé et tomber dans la « paralysie analytique » où on se dit qu'on ne peut passer à la phase suivante car on n'a pas traqué le moindre petit détail de la phase courante. Il faut bien se dire que quelle que soit la profondeur de l'analyse, certains aspects d'un problème ne se révéleront qu'en phase de conception, et d'autres en phase de réalisation, voire même pas avant que le programme ne soit achevé et exécuté. A cause de ceci, il est crucial d'avancer relativement rapidement dans l'analyse et la conception, et d'implémenter un test du système proposé.
Il est bon de développer un peu ce point. A cause des déboires rencontrés avec les langages procéduraux, il est louable qu'une équipe veuille avancer avec précautions et comprendre tous les détails avant de passer à la conception et l'implémentation. Il est certain que lors de la création d'une base de données, il est capital de comprendre à fond les besoins du client. Mais la conception d'une base de données fait partie d'une classe de problèmes bien définie et bien comprise ; dans ce genre de programmes, la structure de la base de données est le problème à résoudre. Les problèmes traités dans ce chapitre font partie de la classe de problèmes « joker » (invention personnelle), dans laquelle la solution n'est pas une simple reformulation d'une solution déjà éprouvée de nombreuses fois, mais implique un ou plusieurs « facteurs joker » - des éléments pour lesquels il n'existe aucune solution préétablie connue, et qui nécessitent de pousser les recherches [9]. Tenter d'analyser à fond un problème joker avant de passer à la conception et l'implémentation mène à la paralysie analytique parce qu'on ne dispose pas d'assez d'informations pour résoudre ce type de problèmes durant la phase d'analyse. Résoudre ce genre de problèmes requiert de répéter le cycle complet, et cela demande de prendre certains risques (ce qui est sensé, car on essaie de faire quelque chose de nouveau et les revenus potentiels en sont plus élevés). On pourrait croire que le risque est augmenté par cette ruée vers une première implémentation, mais elle peut réduire le risque dans un projet joker car on peut tout de suite se rendre compte si telle approche du problème est viable ou non. Le développement d'un produit s'apparente à de la gestion de risque.
Souvent cela se traduit par « construire un prototype qu'il va falloir jeter ». Avec la POO, on peut encore avoir à en jeter une partie, mais comme le code est encapsulé dans des classes, on aura inévitablement produit durant la première passe quelques classes qui valent la peine d'être conservées et développé des idées sur la conception du système. Ainsi, une première passe rapide sur un problème non seulement fournit des informations critiques pour la prochaine passe d'analyse, de conception et d'implémentation, mais elle produit aussi une base du code.
Ceci dit, si on cherche une méthode qui contient de nombreux détails et suggère de nombreuses étapes et documents, il est toujours difficile de savoir où s'arrêter. Il faut garder à l'esprit ce qu'on essaye de découvrir :
Si on arrive à trouver quels sont les objets et leur interface, alors on peut commencer à coder. On pourra avoir besoin d'autres descriptions et documents, mais on ne peut pas faire avec moins que ça.
Le développement peut être décomposé en cinq phases, et une Phase 0 qui est juste l'engagement initial à respecter une structure de base.
Il faut d'abord décider quelles étapes on va suivre dans le développement. Cela semble simple (en fait, tout semble simple), et malgré tout les gens ne prennent cette décision qu'après avoir commencé à coder. Si le plan se résume à « retroussons nos manches et codons », alors ça ne pose pas de problèmes (quelquefois c'est une approche valable quand on a affaire à un problème bien connu). Mais il faut néanmoins accepter que c'est le plan.
On peut aussi décider dans cette phase qu'une structure additionnelle est nécessaire. Certains programmeurs aiment travailler en « mode vacances », sans structure imposée sur le processus de développement de leur travail : « Ce sera fait lorsque ce sera fait ». Cela peut être séduisant un moment, mais disposer de quelques jalons aide à se concentrer et focalise les efforts sur ces jalons au lieu d'être obnubilé par le but unique de « finir le projet ». De plus, cela divise le projet en parties plus petites, ce qui le rend moins redoutable (sans compter que les jalons offrent des opportunités de fête).
Quand j'ai commencé à étudier la structure des histoires (afin de pouvoir un jour écrire un roman), j'étais réticent au début à l'idée de structure, trouvant que j'écrivais mieux quand je laissais juste la plume courir sur le papier. Mais j'ai réalisé plus tard que quand j'écris à propos des ordinateurs, la structure est suffisamment claire pour moi pour que je n'ai pas besoin de trop y réfléchir. Mais je structure tout de même mon travail, bien que ce soit inconsciemment dans ma tête. Même si on pense que le plan est juste de commencer à coder, on passe tout de même par les phases successives en se posant certaines questions et en y répondant.
Tout système qu'on construit, quelle que soit sa complexité, a un but, un besoin fondamental qu'il satisfait. Si on peut voir au delà de l'interface utilisateur, des détails spécifiques au matériel - ou au système -, des algorithmes de codage et des problèmes d'efficacité, on arrive finalement au coeur du problème - simple et nu. Comme le soi-disant concept fondamental d'un film hollywoodien, on peut le décrire en une ou deux phrases. Cette description pure est le point de départ.
Le concept fondamental est assez important car il donne le ton du projet ; c'est l'exposé de la mission. Ce ne sera pas nécessairement le premier jet qui sera le bon (on peut être dans une phase ultérieure du projet avant qu'il ne soit complètement clair), mais il faut continuer d'essayer jusqu'à ce que ça sonne bien. Par exemple, dans un système de contrôle de trafic aérien, on peut commencer avec un concept fondamental basé sur le système qu'on construit : « Le programme tour de contrôle garde la trace d'un avion ». Mais cela n'est plus valable quand le système se réduit à un petit aérodrome, avec un seul contrôleur, ou même aucun. Un modèle plus utile ne décrira pas tant la solution qu'on crée que le problème : « Des avions arrivent, déchargent, partent en révision, rechargent et repartent ».
Dans la génération précédente de conception de programmes (conception procédurale), cela s'appelait « l'analyse des besoins et les spécifications du système ». C'étaient des endroits où on se perdait facilement, avec des documents au nom intimidant qui pouvaient occulter le projet. Leurs intentions étaient bonnes, pourtant. L'analyse des besoins consiste à « faire une liste des indicateurs qu'on utilisera pour savoir quand le travail sera terminé et le client satisfait ». Les spécifications du système consistent en « une description de ce que le programme fera (sans ce préoccuper du comment) pour satisfaire les besoins ». L'analyse des besoins est un contrat entre le développeur et le client (même si le client travaille dans la même entreprise, ou se trouve être un objet ou un autre système). Les spécifications du système sont une exploration générale du problème, et en un sens permettent de savoir s'il peut être résolu et en combien de temps. Comme ils requièrent des consensus entre les intervenants sur le projet (et parce qu'ils changent au cours du temps), il vaut mieux les garder aussi bruts que possible - idéalement en tant que listes et diagrammes - pour ne pas perdre de temps. Il peut y avoir d'autres contraintes qui demandent de produire de gros documents, mais en gardant les documents initiaux petits et concis, cela permet de les créer en quelques sessions de brainstorming avec un leader qui affine la description dynamiquement. Cela permet d'impliquer tous les acteurs du projet, et encourage la participation de toute l'équipe. Plus important encore, cela permet de lancer un projet dans l'enthousiasme.
Il est nécessaire de rester concentré sur ce qu'on essaye d'accomplir dans cette phase : déterminer ce que le système est supposé faire. L'outil le plus utile pour cela est une collection de ce qu'on appelle « cas d'utilisation ». Les cas d'utilisation identifient les caractéristiques clefs du système qui vont révéler certaines des classes fondamentales qu'on utilisera. Ce sont essentiellement des réponses descriptives à des questions comme[10] :
Si on conçoit un guichet automatique, par exemple, le cas d'utilisation pour un aspect particulier des fonctionnalités du système est capable de décrire ce que le guichet fait dans chaque situation possible. Chacune de ces situations est appelée un scénario, et un cas d'utilisation peut être considéré comme une collection de scénarios. On peut penser à un scénario comme à une question qui commence par « Qu'est-ce que le système fait si... ? ». Par exemple, « Qu'est que le guichet fait si un client vient de déposer un chèque dans les dernières 24 heures, et qu'il n'y a pas assez dans le compte sans que le chèque soit encaissé pour fournir le retrait demandé ? ».
Les diagrammes de cas d'utilisations sont voulus simples pour ne pas se perdre prématurément dans les détails de l'implémentation du système :
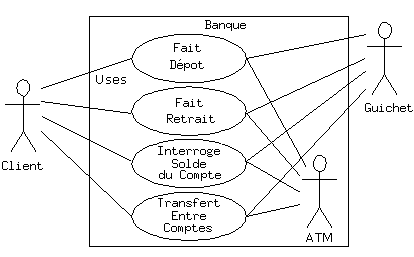
Chaque bonhomme représente un « acteur », typiquement une personne ou une autre sorte d'agent (cela peut même être un autre système informatique, comme c'est le cas avec « ATM »). La boîte représente les limites du système. Les ellipses représentent les cas d'utilisation, qui sont les descriptions des actions qui peuvent être réalisées avec le système. Les lignes entre les acteurs et les cas d'utilisation représentent les interactions.
Tant que le système est perçu ainsi par l'utilisateur, son implémentation n'est pas importante.
Un cas d'utilisation n'a pas besoin d'être complexe, même si le système sous-jacent l'est. Il est seulement destiné à montrer le système tel qu'il apparaît à l'utilisateur. Par exemple :

Les cas d'utilisation produisent les spécifications des besoins en déterminant toutes les interactions que l'utilisateur peut avoir avec le système. Il faut trouver un ensemble complet de cas d'utilisations du système, et cela terminé on se retrouve avec le coeur de ce que le système est censé faire. La beauté des cas d'utilisation est qu'ils ramènent toujours aux points essentiels et empêchent de se disperser dans des discussions non essentielles à la réalisation du travail à faire. Autrement dit, si on dispose d'un ensemble complet de cas d'utilisation, on peut décrire le système et passer à la phase suivante. Tout ne sera pas parfaitement clair dès le premier jet, mais ça ne fait rien. Tout se décantera avec le temps, et si on cherche à obtenir des spécifications du système parfaites à ce point on se retrouvera coincé.
Si on est bloqué, on peut lancer cette phase en utilisant un outil d'approximation grossier : décrire le système en quelques paragraphes et chercher les noms et les verbes. Les noms suggèrent les acteurs, le contexte des cas d'utilisation ou les objets manipulés dans les cas d'utilisation. Les verbes suggèrent les interactions entre les acteurs et les cas d'utilisation, et spécifient les étapes à l'intérieur des cas d'utilisation. On verra aussi que les noms et les verbes produisent des objets et des messages durant la phase de design (on peut noter que les cas d'utilisation décrivent les interactions entre les sous-systèmes, donc la technique « des noms et des verbes » ne peut être utilisée qu'en tant qu'outil de brainstorming car il ne fournit pas les cas d'utilisation) [11].