


XI. Collections d'Objets▲
C'est un programme relativement simple que celui qui ne manipule que des objets dont le nombre et la durée de vie sont connus à l'avance.
Mais en général, vos programmes créeront de nouveaux objets basés sur des informations qui ne seront pas connues avant le lancement du programme. Le nombre, voire le type des objets nécessaires ne seront pas connus avant la phase d'exécution du programme. Pour résoudre le problème considéré, il faut donc être capable de créer un certain nombre d'objets, n'importe quand, n'importe où. Ce qui implique qu'on ne peut se contenter d'une référence nommée pour stocker chacun des objets du programme :
MyObject myReference;puisqu'on ne connaît pas le nombre exact de références qui seront manipulées.
La plupart des langages fournissent des moyens pour résoudre ce problème fondamental. Java dispose de plusieurs manières de stocker les objets (ou plus exactement les références sur les objets). Le type interne est le tableau, dont nous avons déjà parlé auparavant. De plus, la bibliothèque des utilitaires de Java propose un ensemble relativement complet de classes conteneurs (aussi connues sous le nom de classes collections, mais comme les bibliothèques de Java 2 utilisent le nom Collection pour un sous-ensemble particulier de cette bibliothèque, j'utiliserai ici le terme plus générique « conteneur »). Les conteneurs fournissent des moyens sophistiqués pour stocker et même manipuler vos objets.
XI-A. Arrays▲
Les tableaux ont déjà été introduits dans la dernière section du Chapitre 4, qui montrait comment définir et initialiser un tableau. Ce chapitre traite du stockage des objets, et un tableau n'est ni plus ni moins qu'un moyen de stocker des objets. Mais il existe de nombreuses autres manières de stocker des objets : qu'est-ce qui rend donc les tableaux si spéciaux ?
Les tableaux se distinguent des autres types de conteneurs sur trois points : l'efficacité, le type et la capacité de stocker des primitives. Un tableau constitue la manière la plus efficace que propose Java pour stocker et accéder aléatoirement à une séquence d'objets. Un tableau est une simple séquence linéaire, ce qui rend l'accès aux éléments extrêmement rapide ; mais cette rapidité se paye : la taille d'un tableau est fixée lors de sa création et ne peut plus être changée pendant toute la durée de sa vie. Une solution est de créer un tableau d'une taille donnée et, lorsque celui-ci est saturé, en créer un nouveau et déplacer toutes les références de l'ancien tableau dans le nouveau. C'est précisément ce que fait la classe ArrayList, qui sera étudiée plus loin dans ce chapitre. Cependant, du fait du surcoût engendré par la flexibilité apportée au niveau de la taille, une ArrayList est beaucoup moins efficace qu'un tableau.
La classe conteneur vector en C++ connaît le type des objets qu'elle stocke, mais elle a un inconvénient , comparée aux tableaux de Java : l'opérateur [] des vector C++ ne réalise pas de contrôle sur les indices, on peut donc tenter d'accéder à un élément au-delà de la taille du vector(51) En Java, un contrôle d'indices est automatiquement effectué, qu'on utilise un tableau ou un conteneur - une exception RuntimeException est générée si les frontières sont dépassées. Comme vous le verrez dans le Chapitre 10, ce type d'exception indique une erreur due au programmeur et, comme telle, il ne faut pas la prendre en considération dans le code. Bien entendu, la raison pour laquelle le vector C++ n'effectue pas de vérifications à chaque accès est la rapidité - en Java, la vérification continuelle des frontières implique une dégradation des performances pour les tableaux comme pour les conteneurs.
Les autres classes de conteneurs génériques qui seront étudiés dans ce chapitre, les Lists, les Sets et les Maps, traitent les objets comme s'ils n'avaient pas de type spécifique. C'est-à-dire qu'ils les traitent comme s'ils étaient des Objects, la classe de base de toutes les classes en Java. Ceci est très intéressant d'un certain point de vue : un seul conteneur est nécessaire pour stocker tous les objets Java (excepté les types scalaires - ils peuvent toutefois être stockés dans les conteneurs sous forme de constantes en utilisant les classes Java d'encapsulation des types primitifs, ou sous forme de valeurs modifiables en les encapsulant dans des classes personnelles). C'est le deuxième point où les tableaux sont supérieurs aux conteneurs génériques : lorsqu'un tableau est créé, il faut spécifier le type d'objets qu'il est destiné à stocker. Ce qui implique qu'on va bénéficier d'un contrôle de type lors de la phase compilation, empêchant de stocker des objets d'un mauvais type ou de se tromper sur le type de l'objet qu'on extrait. Bien sûr, Java empêchera tout envoi de message inapproprié à un objet, soit lors de la compilation soit lors de l'exécution du programme. Aucune des deux approches n'est donc plus risquée que l'autre, mais c'est tout de même mieux si c'est le compilateur qui signale l'erreur, plus rapide à l'exécution, et il y a moins de chances que l'utilisateur final soit surpris par une exception.
Du fait de l'efficacité et du contrôle de type, il est toujours préférable d'utiliser un tableau si c'est possible. Cependant, les tableaux peuvent se révéler trop restrictifs pour résoudre certains problèmes plus généraux. Après un examen des tableaux, le reste de ce chapitre sera consacré aux classes conteneurs proposées par Java.
XI-A-1. Les tableaux sont des objets▲
Indépendamment du type de tableau qu'on utilise, un identifiant de tableau est en fait une référence sur un vrai objet créé dans le segment. C'est l'objet qui stocke les références sur les autres objets, et il peut être créé soit implicitement grâce à la syntaxe d'initialisation de tableau, soit explicitement avec une expression new. Une partie de l'objet tableau (en fait, la seule méthode ou champ auquel on peut accéder) est le membre en lecture seule length qui indique combien d'éléments peuvent être stockés dans l'objet. La syntaxe '[]' est le seul autre accès disponible pour les objets tableaux.
L'exemple suivant montre les différentes façons d'initialiser un tableau, et comment les références sur un tableau peuvent être assignées à différents objets tableau. Il montre aussi que les tableaux d'objets et les tableaux de types primitifs sont quasi identiques dans leur utilisation. La seule différence est qu'un tableau d'objets stocke des références, alors qu'un tableau de types primitif stocke les valeurs directement.
//: c11:ArraySize.java
// Initialisation & réassignation des tableaux.
import com.bruceeckel.simpletest.*;
class Weeble {} // Une petite créature mythique
public class ArraySize {
private static Test monitor = new Test();
public static void main(String[] args) {
// Tableaux d'objets :
Weeble[] a; // variable locale non initialisée
Weeble[] b = new Weeble[5]; // Référence Null
Weeble[] c = new Weeble[4];
for(int i = 0; i < c.length; i++)
if(c[i] == null) // test pour les références null
c[i] = new Weeble();
// Initialisation par agrégat :
Weeble[] d = {
new Weeble(), new Weeble(), new Weeble()
};
// Initialisation dynamique par agrégat :
a = new Weeble[] {
new Weeble(), new Weeble()
};
System.out.println("a.length=" + a.length);
System.out.println("b.length = " + b.length);
// Les références à l'intérieur du tableau sont
// automatiquement initialisées à null :
for(int i = 0; i < b.length; i++)
System.out.println("b[" + i + "]=" + b[i]);
System.out.println("c.length = " + c.length);
System.out.println("d.length = " + d.length);
a = d;
System.out.println("a.length = " + a.length);
// tableau de types primitifs :
int[] e; // Référence Null
int[] f = new int[5];
int[] g = new int[4];
for(int i = 0; i < g.length; i++)
g[i] = i*i;
int[] h = { 11, 47, 93 };
// Erreur de compilation : variable e non initialisée :
//!System.out.println("e.length=" + e.length);
System.out.println("f.length = " + f.length);
// Les primitives dans le tableau sont
// automatiquement initialisées à zéro :
for(int i = 0; i < f.length; i++)
System.out.println("f[" + i + "]=" + f[i]);
System.out.println("g.length = " + g.length);
System.out.println("h.length = " + h.length);
e = h;
System.out.println("e.length = " + e.length);
e = new int[] { 1, 2 };
System.out.println("e.length = " + e.length);
monitor.expect(new String[] {
"a.length=2",
"b.length = 5",
"b[0]=null",
"b[1]=null",
"b[2]=null",
"b[3]=null",
"b[4]=null",
"c.length = 4",
"d.length = 3",
"a.length = 3",
"f.length = 5",
"f[0]=0",
"f[1]=0",
"f[2]=0",
"f[3]=0",
"f[4]=0",
"g.length = 4",
"h.length = 3",
"e.length = 3",
"e.length = 2"
});
}
} ///:~Le tableau a est une variable locale non initialisée, et le compilateur interdit d'utiliser cette référence tant qu'elle n'est pas correctement initialisée. Le tableau b est initialisé afin de pointer sur un tableau de références Weeble, même si aucun objet Weeble n'est réellement stocké dans le tableau. Cependant, on peut toujours demander la taille du tableau, puisque b pointe sur un objet valide.Ceci montre un inconvénient des tableaux : on ne peut savoir combien d'éléments sont actuellement stockés dans le tableau, puisque length renvoie seulement le nombre d'éléments qu'on peut stocker dans le tableau, autrement dit la taille de l'objet tableau, et non le nombre d'éléments qu'il contient réellement. Cependant, quand un objet tableau est créé, ses références sont automatiquement initialisées à null, on peut donc facilement savoir si une cellule du tableau contient un objet ou pas en testant si son contenu est null. De même, un tableau de types primitif est automatiquement initialisé à zéro pour les types numériques, (char)0 pour les caractères et false pour les booleans.
Le tableau c montre la création d'un objet tableau suivi par l'assignation d'un objet Weeble à chacune des cellules du tableau. Le tableau d illustre la syntaxe d'« initialisation par agrégat » qui permet de créer un objet tableau (implicitement sur le segment avec new, comme le tableau c) et de l'initialiser avec des objets Weeble, le tout dans une seule instruction.
L'initialisation de tableau suivante peut être qualifiée d'« initialisation dynamique par agrégat ». L'initialisation par agrégat utilisée par d doit être utilisée lors de la définition de d, mais avec la seconde syntaxe il est possible de créer et d'initialiser un objet tableau n'importe où. Par exemple, supposons que hide( ) soit une méthode qui accepte un tableau d'objets Weeble comme argument. On peut l'appeler via :
hide(d);mais on peut aussi créer dynamiquement le tableau qu'on veut passer comme argument :
hide(new Weeble[] { new Weeble(), new Weeble() });Cette nouvelle syntaxe est bien plus pratique pour certaines parties de code.
L'expression :
a = d;montre comment prendre une référence attachée à un tableau d'objets et l'assigner à un autre objet tableau, de la même manière qu'avec n'importe quel type de référence. Maintenant a et d pointent sur le même tableau d'objets dans le segment.
La seconde partie de ArraySize.java montre que les tableaux de types primitifs fonctionnent de la même manière que les tableaux d'objets sauf qu'ils stockent directement les valeurs des types primitifs.
XI-A-1-a. Conteneurs de type primitif▲
Les classes conteneurs ne peuvent stocker que des références sur des Objetcs. Un tableau, par contre, peut stocker directement des types primitifs aussi bien que des références sur des Objetcs. Il est possible d'utiliser des classes d'« encapsulation » telles qu'Integer, Double, etc. pour stocker des valeurs de types primitifs dans un conteneur, mais les classes d'encapsulation pour les types primitifs se révèlent souvent lourdes à utiliser. De plus, il est bien plus efficace de créer et d'accéder à un tableau de types primitif qu'à un conteneur de types primitifs encapsulés.
Bien sûr, si on utilise un type primitif et qu'on a besoin de la flexibilité d'un conteneur qui ajuste sa taille automatiquement, le tableau ne convient plus et il faut se rabattre sur un conteneur de types primitifs encapsulés. On pourrait se dire qu'il serait bon d'avoir un type ArrayList spécialisé pour chacun des types de base, mais ils n'existent pas dans Java. (52)
XI-A-2. Renvoyer un tableau▲
Supposons qu'on veuille écrire une méthode qui ne renvoie pas une seule chose, mais tout un ensemble de choses. Ce n'est pas facile à réaliser dans des langages tels que C ou C++ puisqu'ils ne permettent pas de renvoyer un tableau, mais seulement un pointeur sur un tableau. Cela ouvre la porte à de nombreux problèmes du fait qu'il devient ardu de contrôler la durée de vie du tableau, ce qui mène très rapidement à des fuites de mémoire.
Java utilise une approche similaire, mais permet de « renvoyer un tableau ». Contrairement au C++, Java assume de manière transparente la responsabilité de ce tableau - il sera disponible tant qu'on en aura besoin, et le ramasse-miettes le nettoiera lorsqu'on en aura fini avec lui.
Voici un exemple retournant un tableau de String :
//: c11:IceCream.java
// Renvoyer un tableau depuis des méthodes.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class IceCream {
private static Test monitor = new Test();
private static Random rand = new Random();
public static final String[] flavors = {
"Chocolate", "Strawberry", "Vanilla Fudge Swirl",
"Mint Chip", "Mocha Almond Fudge", "Rum Raisin",
"Praline Cream", "Mud Pie"
};
public static String[] flavorSet(int n) {
String[] results = new String[n];
boolean[] picked = new boolean[flavors.length];
for(int i = 0; i < n; i++) {
int t;
do
t = rand.nextInt(flavors.length);
while(picked[t]);
results[i] = flavors[t];
picked[t] = true;
}
return results;
}
public static void main(String[] args) {
for(int i = 0; i < 20; i++) {
System.out.println(
"flavorSet(" + i + ") = ");
String[] fl = flavorSet(flavors.length);
for(int j = 0; j < fl.length; j++)
System.out.println("\t" + fl[j]);
monitor.expect(new Object[] {
"%% flavorSet\\(\\d+\\) = ",
new TestExpression("%% \\t(Chocolate|Strawberry|"
+ "Vanilla Fudge Swirl|Mint Chip|Mocha Almond "
+ "Fudge|Rum Raisin|Praline Cream|Mud Pie)", 8)
});
}
}
} ///:~La méthode flavorSet( ) crée un tableau de String appelé results.La taille de ce tableau est n, déterminé par l'argument que vous passez à la méthode. Elle choisit alors au hasard des parfums dans le tableau flav et les place dans results, qu'elle renvoie quand elle en a terminé. Renvoyer un tableau s'apparente à renvoyer n'importe quel autre objet - ce n'est qu'une référence. Le fait que le tableau ait été créé dans flavorSet( ) n'est pas important, il aurait pu être créé n'importe où. Le ramasse-miettes s'occupe de nettoyer le tableau quand on en a fini avec lui, mais le tableau existera tant qu'on en aura besoin.
Notez en passant que quand flavorSet( ) choisit des parfums au hasard, elle s'assure que le parfum n'a pas déjà été choisi auparavant. Ceci est réalisé par une boucle do qui continue de tirer un parfum au sort jusqu'à ce qu'elle en trouve un qui ne soit pas dans le tableau picked (bien sûr, on aurait pu utiliser une comparaison sur String avec les éléments du tableau results). Une fois le parfum sélectionné, elle l'ajoute dans le tableau et trouve le parfum suivant (i est alors incrémenté).
main( ) affiche 20 ensembles de parfums, et on peut voir que flavorSet( ) choisit les parfums dans un ordre aléatoire à chaque fois. Il est plus facile de s'en rendre compte si on redirige la sortie dans un fichier. Et lorsque vous examinerez ce fichier, rappelez-vous que vous voulez juste la glace, vous n'en avez pas besoin.
XI-A-3. La classe Arrays▲
java.util contient la classe Arrays, qui propose un ensemble de méthodes static réalisant des opérations utiles sur les tableaux. Elle dispose de quatre fonctions de base : equals( ), qui compare deux tableaux ; fill( ), pour remplir un tableau avec une valeur ; sort( ), pour trier un tableau ; et binarySearch( ), pour trouver un élément dans un tableau trié. Toutes ces méthodes sont surchargées pour tous les types primitifs et les Objects. De plus, il existe une méthode asList( ) qui transforme un tableau en un conteneur List - que nous rencontrerons plus tard dans ce chapitre.
Bien que pratique, la classe Arrays montre vite ses limites. Par exemple, il serait agréable de pouvoir facilement afficher les éléments d'un tableau sans avoir à coder une boucle for à chaque fois. Et comme nous allons le voir, la méthode fill( ) n'accepte qu'une seule valeur pour remplir le tableau, ce qui la rend inutile si on voulait - par exemple - remplir le tableau avec des nombres aléatoires.
Nous allons donc compléter la classe Arrays avec d'autres utilitaires, qui seront placés dans le package com.bruceeckel.util. Ces utilitaires permettront d'afficher un tableau de n'importe quel type, et de remplir un tableau avec des valeurs ou des objets créés par un objet appelé générateur qu'il est possible de définir.
Du fait qu'il faut écrire du code pour chaque type primitif de base aussi bien que pour la classe Object, une grande majorité de ce code est dupliqué. (53) Par exemple une interface « générateur » est requise pour chaque type parce que le type renvoyé par next( ) doit être différent dans chaque cas :
//: com:bruceeckel:util:Generator.java
package com.bruceeckel.util;
public interface Generator { Object next(); } ///:~//: com:bruceeckel:util:BooleanGenerator.java
package com.bruceeckel.util;
public interface BooleanGenerator { boolean next(); } ///:~//: com:bruceeckel:util:ByteGenerator.java
package com.bruceeckel.util;
public interface ByteGenerator { byte next(); } ///:~//: com:bruceeckel:util:CharGenerator.java
package com.bruceeckel.util;
public interface CharGenerator { char next(); } ///:~//: com:bruceeckel:util:ShortGenerator.java
package com.bruceeckel.util;
public interface ShortGenerator { short next(); } ///:~//: com:bruceeckel:util:IntGenerator.java
package com.bruceeckel.util;
public interface IntGenerator { int next(); } ///:~//: com:bruceeckel:util:LongGenerator.java
package com.bruceeckel.util;
public interface LongGenerator { long next(); } ///:~//: com:bruceeckel:util:FloatGenerator.java
package com.bruceeckel.util;
public interface FloatGenerator { float next(); } ///:~//: com:bruceeckel:util:DoubleGenerator.java
package com.bruceeckel.util;
public interface DoubleGenerator { double next(); } ///:~Arrays2 contient plusieurs méthodes toString( ), surchargées pour chaque type. Ces méthodes permettent d'afficher plus facilement le contenu d'un tableau. La méthode toString( ) introduit l'utilisation d'un StringBuffer à la place d'un objet String. Ceci est logique, quand vous assemblez une chaine dans une méthode qui pourrait être appelée un certain nombre de fois, il est plus sage d'utiliser les opérations les plus efficaces de StringBuffer plutôt que les moins commodes de String. Ici un StringBuffer est créé avec une valeur initiale, and Strings are appended. Finallement, le result est converti en une String en tant que valeur de retour:
//: com:bruceeckel:util:Arrays2.java
// Un complément à java.util.Arrays, pour fournir
// de nouvelles fonctionnalités utiles lorsqu'on
// travaille avec des tableaux. Permet d'afficher
// n'importe quel tableau, et de le remplir via un
// objet « générateur » personnalisable.
package com.bruceeckel.util;
import java.util.*;
public class Arrays2 {
public static String toString(boolean[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(byte[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(char[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(short[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(int[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(long[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(float[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
public static String toString(double[] a) {
StringBuffer result = new StringBuffer("[");
for(int i = 0; i < a.length; i++) {
result.append(a[i]);
if(i < a.length - 1)
result.append(", ");
}
result.append("]");
return result.toString();
}
// Fill an array using a generator:
public static void fill(Object[] a, Generator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(Object[] a, int from, int to, Generator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void
fill(boolean[] a, BooleanGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(boolean[] a, int from, int to,BooleanGenerator gen){
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(byte[] a, ByteGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(byte[] a, int from, int to, ByteGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(char[] a, CharGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(char[] a, int from, int to, CharGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(short[] a, ShortGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(short[] a, int from, int to, ShortGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(int[] a, IntGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(int[] a, int from, int to, IntGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(long[] a, LongGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(long[] a, int from, int to, LongGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(float[] a, FloatGenerator gen) {
fill(a, 0, a.length, gen);
}
public static void
fill(float[] a, int from, int to, FloatGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
public static void fill(double[] a, DoubleGenerator gen){
fill(a, 0, a.length, gen);
}
public static void
fill(double[] a, int from, int to, DoubleGenerator gen) {
for(int i = from; i < to; i++)
a[i] = gen.next();
}
private static Random r = new Random();
public static class
RandBooleanGenerator implements BooleanGenerator {
public boolean next() { return r.nextBoolean(); }
}
public static class
RandByteGenerator implements ByteGenerator {
public byte next() { return (byte)r.nextInt(); }
}
private static String ssource =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
private static char[] src = ssource.toCharArray();
public static class
RandCharGenerator implements CharGenerator {
public char next() {
return src[r.nextInt(src.length)];
}
}
public static class
RandStringGenerator implements Generator {
private int len;
private RandCharGenerator cg = new RandCharGenerator();
public RandStringGenerator(int length) {
len = length;
}
public Object next() {
char[] buf = new char[len];
for(int i = 0; i < len; i++)
buf[i] = cg.next();
return new String(buf);
}
}
public static class
RandShortGenerator implements ShortGenerator {
public short next() { return (short)r.nextInt(); }
}
public static class
RandIntGenerator implements IntGenerator {
private int mod = 10000;
public RandIntGenerator() {}
public RandIntGenerator(int modulo) { mod = modulo; }
public int next() { return r.nextInt(mod); }
}
public static class
RandLongGenerator implements LongGenerator {
public long next() { return r.nextLong(); }
}
public static class
RandFloatGenerator implements FloatGenerator {
public float next() { return r.nextFloat(); }
}
public static class
RandDoubleGenerator implements DoubleGenerator {
public double next() {return r.nextDouble();}
}
} ///:~Pour remplir un tableau en utilisant un générateur, la méthode fill( ) accepte une référence sur une interface générateur, qui dispose d'une méthode next( ) produisant d'une façon ou d'une autre (selon l'implémentation de l'interface) un objet du bon type. La méthode fill( ) se contente d'appeler next( ) jusqu'à ce que la plage désirée du tableau soit remplie. Il est donc maintenant possible de créer un générateur en implémentant l'interface appropriée, et d'utiliser ce générateur avec fill( ).
Les générateurs de données aléatoires sont utiles lors des tests, un ensemble de classes internes a donc été créé pour implémenter toutes les interfaces pour les types primitifs de base, de même qu'un générateur de String pour représenter des Objects. On peut noter au passage que RandStringGenerator utilise RandCharGenerator pour remplir un tableau de caractères, qui est ensuite transformé en String. La taille du tableau est déterminée par l'argument du constructeur.
Afin de générer des nombres qui ne soient pas trop grands, RandIntGenerator utilise un modulo par défaut de 10'000, mais un constructeur surchargé permet de choisir une valeur plus petite.
Voici un programme qui teste la bibliothèque et illustre la manière dont elle est utilisée :
<![CDATA[
//: c11:TestArrays2.java
// Teste et illustre les utilitaires d'Arrays2.
import com.bruceeckel.util.*;
public class TestArrays2 {
public static void main(String[] args) {
int size = 6;
// Ou récupère la taille depuis la ligne de commande :
if(args.length != 0) {
size = Integer.parseInt(args[0]);
if(size < 3) {
System.out.println("arg must be >= 3");
System.exit(1);
}
}
boolean[] a1 = new boolean[size];
byte[] a2 = new byte[size];
char[] a3 = new char[size];
short[] a4 = new short[size];
int[] a5 = new int[size];
long[] a6 = new long[size];
float[] a7 = new float[size];
double[] a8 = new double[size];
Arrays2.fill(a1, new Arrays2.RandBooleanGenerator());
System.out.println("a1 = " + Arrays2.toString(a1));
Arrays2.fill(a2, new Arrays2.RandByteGenerator());
System.out.println("a2 = " + Arrays2.toString(a2));
Arrays2.fill(a3, new Arrays2.RandCharGenerator());
System.out.println("a3 = " + Arrays2.toString(a3));
Arrays2.fill(a4, new Arrays2.RandShortGenerator());
System.out.println("a4 = " + Arrays2.toString(a4));
Arrays2.fill(a5, new Arrays2.RandIntGenerator());
System.out.println("a5 = " + Arrays2.toString(a5));
Arrays2.fill(a6, new Arrays2.RandLongGenerator());
System.out.println("a6 = " + Arrays2.toString(a6));
Arrays2.fill(a7, new Arrays2.RandFloatGenerator());
System.out.println("a7 = " + Arrays2.toString(a7));
Arrays2.fill(a8, new Arrays2.RandDoubleGenerator());
System.out.println("a8 = " + Arrays2.toString(a8));
}
} ///:~Le paramètre size possède une valeur par défaut, mais vous pouvez aussi la préciser sur la ligne de commande.
XI-A-4. Remplir un tableau▲
La bibliothèque standard Java Arrays propose aussi une méthode fill( ), mais celle-ci est relativement triviale : elle ne fait que dupliquer une certaine valeur dans chaque cellule, ou dans le cas d'objets, copier la même référence dans chaque cellule. En utilisant Arrays2.print( ), les méthodes Arrays.fill( ) peuvent être facilement illustrées :
//: c11:FillingArrays.java
// Utilisation de Arrays.fill()
import com.bruceeckel.simpletest.*;
import com.bruceeckel.util.*;
import java.util.*;
public class FillingArrays {
private static Test monitor = new Test();
public static void main(String[] args) {
int size = 6;
// Ou récupère la taille depuis la ligne de commande :
if(args.length != 0)
size = Integer.parseInt(args[0]);
boolean[] a1 = new boolean[size];
byte[] a2 = new byte[size];
char[] a3 = new char[size];
short[] a4 = new short[size];
int[] a5 = new int[size];
long[] a6 = new long[size];
float[] a7 = new float[size];
double[] a8 = new double[size];
String[] a9 = new String[size];
Arrays.fill(a1, true);
System.out.println("a1 = " + Arrays2.toString(a1));
Arrays.fill(a2, (byte)11);
System.out.println("a2 = " + Arrays2.toString(a2));
Arrays.fill(a3, 'x');
System.out.println("a3 = " + Arrays2.toString(a3));
Arrays.fill(a4, (short)17);
System.out.println("a4 = " + Arrays2.toString(a4));
Arrays.fill(a5, 19);
System.out.println("a5 = " + Arrays2.toString(a5));
Arrays.fill(a6, 23);
System.out.println("a6 = " + Arrays2.toString(a6));
Arrays.fill(a7, 29);
System.out.println("a7 = " + Arrays2.toString(a7));
Arrays.fill(a8, 47);
System.out.println("a8 = " + Arrays2.toString(a8));
Arrays.fill(a9, "Hello");
System.out.println("a9 = " + Arrays.asList(a9));
// Manipulation de plages d'index :
Arrays.fill(a9, 3, 5, "World");
System.out.println("a9 = " + Arrays.asList(a9));
monitor.expect(new String[] {
"a1 = [true, true, true, true, true, true]",
"a2 = [11, 11, 11, 11, 11, 11]",
"a3 = [x, x, x, x, x, x]",
"a4 = [17, 17, 17, 17, 17, 17]",
"a5 = [19, 19, 19, 19, 19, 19]",
"a6 = [23, 23, 23, 23, 23, 23]",
"a7 = [29.0, 29.0, 29.0, 29.0, 29.0, 29.0]",
"a8 = [47.0, 47.0, 47.0, 47.0, 47.0, 47.0]",
"a9 = [Hello, Hello, Hello, Hello, Hello, Hello]",
"a9 = [Hello, Hello, Hello, World, World, Hello]"
});
}
} ///:~On peut soit remplir un tableau complètement, soit - comme le montrent les deux dernières instructions - une certaine plage d'indices. Mais comme il n'est possible de ne fournir qu'une seule valeur pour le remplissage dans Arrays.fill( ), les méthodes Arrays2.fill( ) sont bien plus intéressantes.
XI-A-5. Copier un tableau▲
La bibliothèque standard Java propose une méthode static, System.arraycopy( ), qui réalise des copies de tableau bien plus rapidement qu'une boucle for. System.arraycopy( ) est surchargée afin de gérer tous les types. Voici un exemple qui manipule des tableaux d'int:
//: c11:CopyingArrays.java
// Utilisation de System.arraycopy()
import com.bruceeckel.simpletest.*;
import com.bruceeckel.util.*;
import java.util.*;
public class CopyingArrays {
private static Test monitor = new Test();
public static void main(String[] args) {
int[] i = new int[7];
int[] j = new int[10];
Arrays.fill(i, 47);
Arrays.fill(j, 99);
System.out.println("i = " + Arrays2.toString(i));
System.out.println("j = " + Arrays2.toString(j));
System.arraycopy(i, 0, j, 0, i.length);
System.out.println("j = " + Arrays2.toString(j));
int[] k = new int[5];
Arrays.fill(k, 103);
System.arraycopy(i, 0, k, 0, k.length);
System.out.println("k = " + Arrays2.toString(k));
Arrays.fill(k, 103);
System.arraycopy(k, 0, i, 0, k.length);
System.out.println("i = " + Arrays2.toString(i));
// Objects:
Integer[] u = new Integer[10];
Integer[] v = new Integer[5];
Arrays.fill(u, new Integer(47));
Arrays.fill(v, new Integer(99));
System.out.println("u = " + Arrays.asList(u));
System.out.println("v = " + Arrays.asList(v));
System.arraycopy(v, 0, u, u.length/2, v.length);
System.out.println("u = " + Arrays.asList(u));
monitor.expect(new String[] {
"i = [47, 47, 47, 47, 47, 47, 47]",
"j = [99, 99, 99, 99, 99, 99, 99, 99, 99, 99]",
"j = [47, 47, 47, 47, 47, 47, 47, 99, 99, 99]",
"k = [47, 47, 47, 47, 47]",
"i = [103, 103, 103, 103, 103, 47, 47]",
"u = [47, 47, 47, 47, 47, 47, 47, 47, 47, 47]",
"v = [99, 99, 99, 99, 99]",
"u = [47, 47, 47, 47, 47, 99, 99, 99, 99, 99]"
});
}
} ///:~Les arguments de arraycopy( ) sont le tableau source, la position dans le tableau source à partir duquel démarrer la copie, le tableau destination, la position dans le tableau destination à partir duquel démarrer la copie, et le nombre d'éléments à copier. Bien entendu, toute violation des frontières du tableau générera une exception.
L'exemple montre bien qu'on peut copier des tableaux de types primitifs comme des tableaux d'objets. Cependant, dans le cas de la copie de tableaux d'objets, seules les références sont copiées - il n'y a pas duplication des objets eux-mêmes. C'est ce qu'on appelle une copie superficielle (voir l'Annexe A).
XI-A-6. Comparer des tableaux▲
Arrays fournit la méthode surchargée equals( ) pour comparer des tableaux entiers. Encore une fois, ces méthodes sont surchargées pour chacun des types de base, ainsi que pour les Objects. Pour être égaux, les tableaux doivent avoir la même taille et chaque élément doit être équivalent (au sens de la méthode equals( )) à l'élément correspondant dans l'autre tableau (pour les types scalaires, la méthode equals( ) de la classe d'encapsulation du type concerné est utilisée ; par exemple, Integer.equals( ) est utilisée pour les int). Voici un exemple :
//: c11:ComparingArrays.java
// Utilisation de Arrays.equals()
import com.bruceeckel.simpletest.*;
import java.util.*;
public class ComparingArrays {
private static Test monitor = new Test();
public static void main(String[] args) {
int[] a1 = new int[10];
int[] a2 = new int[10];
Arrays.fill(a1, 47);
Arrays.fill(a2, 47);
System.out.println(Arrays.equals(a1, a2));
a2[3] = 11;
System.out.println(Arrays.equals(a1, a2));
String[] s1 = new String[5];
Arrays.fill(s1, "Hi");
String[] s2 = {"Hi", "Hi", "Hi", "Hi", "Hi"};
System.out.println(Arrays.equals(s1, s2));
monitor.expect(new String[] {
"true",
"false",
"true"
});
}
} ///:~Au début du programme, a1 et a2 sont identiques, donc le résultat est « true » ; puis l'un des éléments est changé donc la deuxième ligne affichée est « false ». Dans le dernier cas, tous les éléments de s1 pointent sur le même objet, alors que s2 contient cinq objets différents. Cependant, l'égalité de tableaux est basée sur le contenu (via Object.equals( )) et donc le résultat est « true ».
XI-A-7. Comparaison d'éléments d'un tableau▲
L'une des fonctionnalités manquantes dans les bibliothèques Java 1.0 et 1.1 est les opérations algorithmiques - y compris les simples tris. Ceci était relativement frustrant pour quiconque s'attendait à une bibliothèque standard suffisante. Heureusement, Java 2 a corrigé cette situation, au moins pour le problème du tri.
Le problème avec l'écriture d'une méthode de tri générique est que le tri doit réaliser des comparaisons basées sur le type réel de l'objet. Bien sûr, l'une des approches consiste à écrire une méthode de tri différente pour chaque type, mais cela va à l'encontre du principe de réutilisabilité du code pour les nouveaux types.
L'un des buts principaux de la conception est de « séparer les choses qui changent de celles qui restent les mêmes », ici, le code qui reste le même est l'algorithme général de tri, alors que la manière de comparer les objets entre eux est ce qui change d'un cas d'utilisation à l'autre. Donc au lieu de placer la comparaison dans différentes procédures de tri, on utilise ici la technique des « callbacks ». Avec un « callback », la partie du code qui varie d'un cas à l'autre est séparée, et la partie du code qui est toujours la même sera appelée par le code qui change.
Java a deux manières de fournir la fonctionnalité de comparaison. La première est avec la méthode « naturelle » de comparaison elle est annoncée dans une classe en implémentant l'interface java.lang.Comparable. C'est une interface très simple ne disposant que d'une seule méthode, compareTo( ). Cette méthode accepte un autre Object comme argument, et renvoie une valeur négative si l'objet courant est plus petit que l'argument, zéro si l'argument est égal, et une valeur positive si l'argument l'objet courant est plus grand que l'argument.
Voici une classe qui implémente Comparable et illustre la comparaison en utilisant la méthode Arrays.sort( ) de la bibliothèque standard Java :
//: c11:CompType.java
// Implémenter Comparable dans une classe.
import com.bruceeckel.util.*;
import java.util.*;
public class CompType implements Comparable {
int i;
int j;
public CompType(int n1, int n2) {
i = n1;
j = n2;
}
public String toString() {
return "[i = " + i + ", j = " + j + "]";
}
public int compareTo(Object rv) {
int rvi = ((CompType)rv).i;
return (i < rvi ? -1 : (i == rvi ? 0 : 1));
}
private static Random r = new Random();
public static Generator generator() {
return new Generator() {
public Object next() {
return new CompType(r.nextInt(100),r.nextInt(100));
}
};
}
public static void main(String[] args) {
CompType[] a = new CompType[10];
Arrays2.fill(a, generator());
System.out.println(
"avant tri, a = " + Arrays.asList(a));
Arrays.sort(a);
System.out.println(
"après tri, a = " + Arrays.asList(a));
}
} ///:~Lorsque la fonction de comparaison est définie, il vous incombe de décider du sens à donner à la comparaison entre deux objets. Ici, seules les valeurs i sont utilisées dans la comparaison, les valeurs j sont ignorées.
La méthode static randInt( ) produit des valeurs positives entre zéro et 100, et la méthode generator( ) produit un objet implémentant l'interface Generator en créant une classe interne anonyme (voir Chapitre 8). Cela génère des objets CompType en les initialisant à des valeurs aléatoires. Dans main( ), le générateur est utilisé pour remplir un tableau de CompType, qui est alors trié. Si Comparable n'avait pas été implémentée, vous auriez obtenu une ClassCastException à l'exécution lors de l'appel à sort( ). Ceci parce que sort( ) converti son argument en Comparable.
Dans le cas où une classe n'implémente pas Comparable, ou une classe qui implémenteComparable, mais d'une manière qui ne vous satisfait pas et vous préféreriez avoir une méthode de comparaison différente pour ce type. La solution est qu'il ne faut pas écrire en dur le code de comparaison dans chaque objet. À la place, la stratégie du modèle de conception « design pattern » (54) est utilisée. Avec cette stratégie, la partie du code qui change est encapsulée dans sa propre classe (la stratégie objet). Vous donnez une stratégie objet au code qui est toujours la même pour réaliser l'algorithme. De cette façon, vous pouvez créer des objets différents pour exprimer différents moyens de comparaison et les utiliser avec le même code de tri. Ici, vous créez une stratégie en définissant une classe séparée qui implémente une interface appelée Comparator. Elle a deux méthodes, compare( ) et equals( ). Cependant, vous n'avez pas à implémenter equals( ), sauf pour des besoins spéciaux de performance, car chaque classe dérive implicitement de Object, qui fournit déjà une méthode equals( ). On peut donc se contenter de la méthode equals( ) d'Object pour satisfaire le contrat imposé par l'interface.
La classe Collections (que nous étudierons plus en détail par la suite) dispose d'un Comparator qui inverse l'ordre naturel de tri. Ceci peut facilement être appliqué à CompType:
//: c11:Reverse.java
// Le Comparator Collecions.reverseOrder().
import com.bruceeckel.util.*;
import java.util.*;
public class Reverse {
public static void main(String[] args) {
CompType[] a = new CompType[10];
Arrays2.fill(a, CompType.generator());
System.out.println(
"avant le tri, a = " + Arrays.asList(a));
Arrays.sort(a, Collections.reverseOrder());
System.out.println(
"après le tri, a = " + Arrays.asList(a));
}
} ///:~L'appel à Collections.reverseOrder( ) produit une référence sur le Comparator.
Voici un deuxième exemple dans lequel un Comparator compare des objets CompType en se basant cette fois sur la valeur de leur j plutôt que sur celle de i :
//: c11:ComparatorTest.java
// Implémenter un Comparator pour une classe.
import com.bruceeckel.util.*;
import java.util.*;
class CompTypeComparator implements Comparator {
public int compare(Object o1, Object o2) {
int j1 = ((CompType)o1).j;
int j2 = ((CompType)o2).j;
return (j1 < j2 ? -1 : (j1 == j2 ? 0 : 1));
}
}
public class ComparatorTest {
public static void main(String[] args) {
CompType[] a = new CompType[10];
Arrays2.fill(a, CompType.generator());
System.out.println(
"avant le tri, a = " + Arrays.asList(a));
Arrays.sort(a, new CompTypeComparator());
System.out.println(
"après le tri, a = " + Arrays.asList(a));
}
} ///:~La méthode compare( ) doit renvoyer un entier négatif, zéro ou un entier positif selon que le premier argument est respectivement plus petit, égal ou plus grand que le second.
XI-A-8. Trier un tableau▲
Avec les méthodes de tri intégrées, il est maintenant possible de trier n'importe quel tableau de types primitifs ou d'objets implémentant Comparable ou disposant d'une classe Comparator associée. Ceci comble un énorme trou dans les bibliothèques de Java - croyez-le ou non, Java 1.0 ou 1.1 ne fournissaient aucun moyen de trier des Strings ! Voici un exemple qui génère des objets String aléatoirement et les trie :
//: c11:StringSorting.java
// Trier un tableau de Strings.
import com.bruceeckel.util.*;
import java.util.*;
public class StringSorting {
public static void main(String[] args) {
String[] sa = new String[30];
Arrays2.fill(sa, new Arrays2.RandStringGenerator(5));
System.out.println(
"Before sorting: " + Arrays.asList(sa));
Arrays.sort(sa);
System.out.println(
"After sorting: " + Arrays.asList(sa));
}
} ///:~Il est bon de noter que le tri effectué sur les Strings est lexicographique, c'est-à-dire que les mots commençant par des majuscules apparaissent avant ceux débutant par une minuscule (typiquement les annuaires sont triés de cette façon). Il est toutefois possible de redéfinir ce comportement et d'ignorer la casse en définissant une classe Comparator, ceci en surchargeant le comportement de la comparaison des Strings. Cette classe sera placée dans le package « util » à des fins de réutilisation :
//: com:bruceeckel:util:AlphabeticComparator.java
// Garder les lettres majuscules et minuscules ensemble.
package com.bruceeckel.util;
import java.util.*;
public class AlphabeticComparator implements Comparator {
public int compare(Object o1, Object o2) {
String s1 = (String)o1;
String s2 = (String)o2;
return s1.toLowerCase().compareTo(s2.toLowerCase());
}
} ///:~En convertissant explicitement en String dès le début, vous obtiendrez une exception si vous tentez de l'utiliser avec le mauvais type. Chaque String est converti en minuscules avant la comparaison. La méthode compareTo( ) de String fournit ensuite le comparateur désiré.
Voici un exemple utilisant AlphabeticComparator:
//: c11:AlphabeticSorting.java
// Garder les lettres majuscules et minuscules ensemble.
import com.bruceeckel.util.*;
import java.util.*;
public class AlphabeticSorting {
public static void main(String[] args) {
String[] sa = new String[30];
Arrays2.fill(sa, new Arrays2.RandStringGenerator(5));
System.out.println(
"Before sorting: " + Arrays.asList(sa));
Arrays.sort(sa, new AlphabeticComparator());
System.out.println(
"After sorting: " + Arrays.asList(sa));
}
} ///:~L'algorithme de tri utilisé dans la bibliothèque standard de Java est conçu pour être optimal suivant le type d'objets triés : un tri rapide pour les types primitifs et un tri-fusion stable pour les objets. Vous ne devriez donc pas avoir à vous soucier des performances à moins qu'un outil de profilage ne vous démontre explicitement que le goulot d'étranglement de votre programme est le processus de tri.
XI-A-9. Rechercher dans un tableau trié▲
Une fois un tableau trié, il est possible d'effectuer une recherche rapide sur un item en utilisant Arrays.binarySearch( ). Il est toutefois très important de ne pas utiliser binarySearch( ) sur un tableau non trié ; le résultat en serait imprévisible. L'exemple suivant utilise un RandIntGenerator pour remplir un tableau et produire des valeurs à chercher dans ce tableau :
//: c11:ArraySearching.java
// Utilisation de Arrays.binarySearch().
import com.bruceeckel.util.*;
import java.util.*;
public class ArraySearching {
public static void main(String[] args) {
int[] a = new int[100];
Arrays2.RandIntGenerator gen =
new Arrays2.RandIntGenerator(1000);
Arrays2.fill(a, gen);
Arrays.sort(a);
System.out.println(
"Sorted array: " + Arrays2.toString(a));
while(true) {
int r = gen.next();
int location = Arrays.binarySearch(a, r);
if(location >= 0) {
System.out.println("Location of " + r +
" is " + location + ", a[" +
location + "] = " + a[location]);
break; // Sortie de la boucle while
}
}
}
} ///:~Dans la boucle while, des valeurs aléatoires sont générées tant que l'une de ces valeurs n'est pas trouvée dans le tableau.
Arrays.binarySearch( ) renvoie une valeur supérieure ou égale à zéro si l'item recherché est trouvé. Dans le cas contraire, elle renvoie une valeur négative représentant l'endroit où insérer l'élément si on désirait maintenir le tableau trié à la main. La valeur retournée est :
-(insertion point) - 1Le point d'insertion est l'index du premier élément plus grand que la clef, ou a.size( ) si tous les éléments du tableau sont plus petits que la clef spécifiée.
Si le tableau contient des éléments dupliqués, aucune garantie n'est apportée quant à celui qui sera trouvé. L'algorithme n'est donc pas conçu pour les tableaux comportant des doublons, bien qu'il les tolère. Dans le cas où on a besoin d'une liste triée d'éléments sans doublons, mieux vaut se tourner vers un TreeSet (pour garder l'ordre trié) ou vers un LinkedHashSet (pour maintenir l'ordre d'insertion). Qui seront introduites plus loin dans ce chapitre, plutôt que de maintenir un tableau à la main (à moins que des questions de performance ne se greffent là-dessus). Ces classes gèrent tous ces détails automatiquement pour vous.
Il faut fournir à binarySearch( ) le même objet Comparator que celui utilisé pour trier le tableau d'objets (les tableaux de scalaires n'autorisent pas les tris avec des Comparator), afin qu'elle utilise la version redéfinie de la fonction de comparaison. Ainsi, le programme AlphabeticSorting.java peut être modifié pour effectuer une recherche :
//: c11:AlphabeticSearch.java
// Rechercher avec un Comparator.
import com.bruceeckel.simpletest.*;
import com.bruceeckel.util.*;
import java.util.*;
public class AlphabeticSearch {
private static Test monitor = new Test();
public static void main(String[] args) {
String[] sa = new String[30];
Arrays2.fill(sa, new Arrays2.RandStringGenerator(5));
AlphabeticComparator comp = new AlphabeticComparator();
Arrays.sort(sa, comp);
int index = Arrays.binarySearch(sa, sa[10], comp);
System.out.println("Index = " + index);
monitor.expect(new String[] {
"Index = 10"
});
}
} ///:~Le Comparator doit être donné en troisième argument à binarySearch( ) as the third argument. Dans l'exemple précédent, le succès de la recherche est garanti puisque l'item recherché est tiré du tableau lui-même.
XI-A-10. Résumé sur les tableaux▲
Pour résumer ce qu'on a vu jusqu'à présent, un tableau se révèle la manière la plus simple et la plus efficace pour stocker un groupe d'objets, et le seul choix possible dans le cas où on veut stocker un ensemble de scalaires. Dans le reste de ce chapitre, nous allons étudier le cas plus général dans lequel on ne sait pas au moment de l'écriture du programme combien d'objets seront requis, ainsi que des moyens plus sophistiqués de stocker les objets. Java propose en effet des classes conteneurs qui adressent différents problèmes. Les types de base en sont les Lists, les Sets et les Maps. Un nombre surprenant de problèmes peuvent être facilement résolus grâce à ces outils.
Parmi leurs autres caractéristiques - les Sets, par exemple, ne stockent qu'un objet de chaque valeur, les Maps sont des tableaux associatifs qui permettent d'associer n'importe quel objet avec n'importe quel autre objet - les classes conteneurs de Java se redimensionnent automatiquement. À l'inverse des tableaux, ils peuvent donc stocker un nombre quelconque d'objets et on n'a pas besoin de se soucier de leur taille lors de l'écriture du programme.
XI-B. Introduction sur les conteneurs▲
Les classes conteneurs sont à mon sens l'un des outils les plus puissants disponibles parce qu'ils augmentent de façon significative la productivité du développement. Les conteneurs de Java 2 résultent d'une reconception approfondie (55) des implémentations relativement pauvres disponibles dans Java 1.0 et 1.1. Cette reconception a permis d'unifier et de rationaliser certains fonctionnements. Elle a aussi comblé certains manques de la bibliothèque des conteneurs tels que les listes chaînées, les files (queues) et les files doubles (queues à double entrée).
La conception d'une bibliothèque de conteneurs est difficile (de même que tous les problèmes de conception des bibliothèques). En C++, les classes conteneurs couvrent les bases grâce à de nombreuses classes différentes. C'est mieux que ce qui était disponible avant (ie, rien), mais le résultat ne se transpose pas facilement dans Java. J'ai aussi rencontré l'approche opposée, où la bibliothèque de conteneurs consistait en une seule classe qui fonctionnait à la fois comme une séquence linéaire et un tableau associatif. La bibliothèque de conteneurs de Java 2 essaie de trouver un juste milieu : les fonctionnalités auxquelles on peut s'attendre de la part d'une bibliothèque de conteneurs mâture, mais plus facile à appréhender que les classes conteneurs du C++ ou d'autres bibliothèques de conteneurs similaires. Le résultat peut paraître étrange dans certains cas. Mais contrairement à certaines décisions prises dans la conception des premières bibliothèques Java, ces bizarreries ne sont pas des accidents de conception, mais des compromis minutieusement examinés sur la complexité. Il vous faudra peut-être un petit moment avant d'être à l'aise avec certains aspects de la bibliothèque, mais je pense que vous adopterez quand même très rapidement ces nouveaux outils.
Le but de la bibliothèque de conteneurs de Java 2 est de « stocker des objets » et le divise en deux concepts bien distincts :
- Collection: un groupe d'éléments individuels, souvent associé à une règle définissant leur comportement. Une List doit garder les éléments dans un ordre précis, et un Set ne peut contenir de doublons (les sacs [NDT : bag en anglais], qui ne sont pas implémentés dans la bibliothèque de conteneurs de Java - les Lists fournissant des fonctionnalités équivalentes - ne possèdent pas une telle règle).
- Map: un ensemble de paires clef - valeur. À première vue, on pourrait penser qu'il ne s'agit que d'une Collection de paires, mais lorsqu'on essaie de l'implémenter de cette manière, le design devient très rapidement bancal et lourd à mettre en œuvre ; il est donc plus simple d'en faire un concept séparé. D'un autre côté, il est bien pratique d'examiner certaines portions d'une Map en créant une Collection représentant cette portion. Une Map peut donc renvoyer un Set de ses clefs, une Collection de ses valeurs, ou un Set de ses paires. Les Maps, comme les tableaux, peuvent facilement être étendus dans de multiples dimensions sans ajouter de nouveaux concepts : il suffit de créer une Map dont les valeurs sont des Maps (les valeurs de ces Maps pouvant elles-mêmes être des Maps, etc.).
Nous allons d'abord examiner les fonctionnalités générales des conteneurs, puis aller dans leurs spécificités et enfin nous apprendrons pourquoi certains conteneurs sont déclinés en plusieurs versions, et comment choisir entre eux.
XI-B-1. Afficher les conteneurs▲
À l'inverse des tableaux, les conteneurs s'affichent correctement sans aide. Voici un exemple qui introduit en même temps les conteneurs de base :
//: c11:PrintingContainers.java
// Containers print themselves automatically.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class PrintingContainers {
private static Test monitor = new Test();
static Collection fill(Collection c) {
c.add("dog");
c.add("dog");
c.add("cat");
return c;
}
static Map fill(Map m) {
m.put("dog", "Bosco");
m.put("dog", "Spot");
m.put("cat", "Rags");
return m;
}
public static void main(String[] args) {
System.out.println(fill(new ArrayList()));
System.out.println(fill(new HashSet()));
System.out.println(fill(new HashMap()));
monitor.expect(new String[] {
"[dog, dog, cat]",
"[dog, cat]",
"{dog=Spot, cat=Rags}"
});
}
} ///:~Comme mentionné précédemment, il existe deux catégories de base dans la bibliothèque de conteneurs Java. La distinction est basée sur le nombre d'éléments stockés dans chaque cellule du conteneur. La catégorie Collection ne stocke qu'un élément dans chaque emplacement (le nom est un peu trompeur puisque les bibliothèques des conteneurs sont souvent appelées des « collections »). Elle inclut la List, qui stocke un groupe d'éléments dans un ordre spécifique et le Set, qui autorise l'addition d'une seule instance pour chaque élément. Une ArrayList est un type de List et HashSet est un type de Set. La méthode add( ) permet d'ajouter des éléments dans une Collection.
Une Map contient des paires clef - valeur, un peu à la manière d'une mini base de données. Le programme précédent utilise un type de Map, le HashMap. Si on dispose d'une Map qui associe les États des USA avec leur capitale et qu'on souhaite connaître la capitale de l'Ohio, il suffit de la rechercher - comme si on indexait un tableau (les Maps sont aussi appelés des tableaux associatifs). La méthode put( ), qui accepte deux arguments - la clef et la valeur -, permet de stocker des éléments dans une Map. L'exemple précédent se contente d'ajouter des éléments, mais ne les récupère pas une fois stockés. Ceci sera illustré plus tard.
Les méthodes surchargées fill( ) remplissent respectivement des Collections et des Maps. En examinant la sortie produite par le programme, on peut voir que le comportement par défaut pour l'affichage (fourni par les méthodes toString( ) des différents conteneurs) produit un résultat relativement clair, il n'est donc pas nécessaire d'ajouter du code pour imprimer les conteneurs comme nous avons du le faire avec les tableaux. Une Collection est imprimée entre crochets, chaque élément étant séparé par une virgule. Une Map est entourée par des accolades, chaque clef étant associée à sa valeur avec un signe égal (les clefs à gauche, les valeurs à droite).
Le comportement de base des différents conteneurs est évident dans cet exemple. La List stocke les objets dans l'ordre exact où ils ont été ajoutés, sans aucun réarrangement ni édition. Le Set, lui, n'accepte qu'une seule instance d'un objet et utilise une méthode interne de tri (en général, un Set sert à savoir si un élément est un membre d'un Set ou non et non l'ordre dans lequel il apparaît dans ce Set - pour cela il faut utiliser une List). La Map elle aussi n'accepte qu'une seule instance d'un objet pour la clef, possède elle aussi sa propre organisation interne et ne tient pas compte de l'ordre dans lequel les éléments ont été insérés. Si le maintien de l'ordre d'insertion est important, vous pouvez utiliser les LinkedHashSet ou les LinkedHashMap.
XI-B-2. Remplir les conteneurs▲
Bien que le problème d'affichage des conteneurs soit géré pour nous, le remplissage des conteneurs souffre des mêmes limitations que java.util.Arrays. De même que pour les Arrays, il existe une classe compagnon appelée Collections contenant des méthodes static dont l'une s'appelle fill( ). Cette méthode fill( ) ne fait que dupliquer une unique référence sur un objet dans le conteneur, et ne fonctionne que sur les objets List, pas sur les Sets ni les Maps :
//: c11:FillingLists.java
// La méthode Collections.fill()
import com.bruceeckel.simpletest.*;
import java.util.*;
public class FillingLists {
private static Test monitor = new Test();
public static void main(String[] args) {
List list = new ArrayList();
for(int i = 0; i < 10; i++)
list.add("");
Collections.fill(list, "Hello");
System.out.println(list);
monitor.expect(new String[] {
"[Hello, Hello, Hello, Hello, Hello, " +
"Hello, Hello, Hello, Hello, Hello]"
});
}
} ///:~Cette méthode est encore moins intéressante parce qu'elle ne fait que remplacer les éléments déjà présents dans la List, sans ajouter aucun élément.
Pour être capable de créer des exemples intéressants, voici une bibliothèque complémentaire Collections2 (appartenant par commodité à com.bruceeckel.util) disposant d'une méthode fill( ) utilisant un générateur pour ajouter des éléments, et permettant de spécifier le nombre d'éléments qu'on souhaite ajouter. L'interface Generator définie précédemment fonctionne pour les Collections, mais les Maps requièrent leur propre interface générateur puisqu'un appel à next( ) doit produire une paire d'objets (une clef et une valeur). Voici tout d'abord la classe Pair :
//: com:bruceeckel:util:Pair.java
package com.bruceeckel.util;
public class Pair {
public Object key, value;
public Pair(Object k, Object v) {
key = k;
value = v;
}
} ///:~Ensuite, l'interface générateur qui produit un objet Pair :
//: com:bruceeckel:util:MapGenerator.java
package com.bruceeckel.util;
public interface MapGenerator { Pair next(); } ///:~Avec ces deux objets, un ensemble d'utilitaires pour travailler avec les classes conteneurs peuvent être développés :
//: com:bruceeckel:util:Collections2.java
// Remplir n'importe quel type de conteneur en utilisant un objet générateur.
package com.bruceeckel.util;
import java.util.*;
public class Collections2 {
// Fill an array using a generator:
public static void
fill(Collection c, Generator gen, int count) {
for(int i = 0; i < count; i++)
c.add(gen.next());
}
public static void
fill(Map m, MapGenerator gen, int count) {
for(int i = 0; i < count; i++) {
Pair p = gen.next();
m.put(p.key, p.value);
}
}
public static class
RandStringPairGenerator implements MapGenerator {
private Arrays2.RandStringGenerator gen;
public RandStringPairGenerator(int len) {
gen = new Arrays2.RandStringGenerator(len);
}
public Pair next() {
return new Pair(gen.next(), gen.next());
}
}
// Objet par défaut afin de ne pas avoir à créer le votre
public static RandStringPairGenerator rsp =
new RandStringPairGenerator(10);
public static class
StringPairGenerator implements MapGenerator {
private int index = -1;
private String[][] d;
public StringPairGenerator(String[][] data) {
d = data;
}
public Pair next() {
// Force l'index dans la plage de valeurs :
index = (index + 1) % d.length;
return new Pair(d[index][0], d[index][1]);
}
public StringPairGenerator reset() {
index = -1;
return this;
}
}
// Utilisation d'un ensemble de données prédéfinies :
public static StringPairGenerator geography =
new StringPairGenerator(CountryCapitals.pairs);
// Produit une séquence à partir d'un tableau 2D :
public static class StringGenerator implements Generator{
private String[][] d;
private int position;
private int index = -1;
public StringGenerator(String[][] data, int pos) {
d = data;
position = pos;
}
public Object next() {
// Force l'index dans la plage de valeurs :
index = (index + 1) % d.length;
return d[index][position];
}
public StringGenerator reset() {
index = -1;
return this;
}
}
// Utilisation d'un ensemble de données prédéfinies :
public static StringGenerator countries =
new StringGenerator(CountryCapitals.pairs, 0);
public static StringGenerator capitals =
new StringGenerator(CountryCapitals.pairs, 1);
} ///:~Les deux versions de fill( ) prennent un argument qui détermine le nombre d'éléments à ajouter au conteneur. De plus, il y a deux générateurs pour les map: RandStringPairGenerator, qui cré n'importe quel nombre de pairs de Strings avec une longueur déterminée par l'argument du constructeur; et StringPairGenerator, qui produit des paires de Strings donnant un tableau à deux dimensions de String. StringGenerator accepte aussi un tableau bidimensionnel de String, mais génère de simples items plutôt que des Pairs.Les objets static rsp, geography, countries, et capitals fournissent des générateurs préconstruits, les trois derniers utilisant tous les pays du monde et leur capitale. Remarquez que si vous essayez de créer plus de pairs qu'il n'en existe, alors le générateur retournera au début, et si vous mettez les pairs dans une Map, les doublons seront tout simplement ignorés.
Voici l'ensemble de données prédéfinies, qui consiste en noms de pays avec leur capitale :
//: com:bruceeckel:util:CountryCapitals.java
package com.bruceeckel.util;
public class CountryCapitals {
public static final String[][] pairs = {
// Afrique
{"ALGERIA","Algiers"}, {"ANGOLA","Luanda"},
{"BENIN","Porto-Novo"}, {"BOTSWANA","Gaberone"},
{"BURKINA FASO","Ouagadougou"},
{"BURUNDI","Bujumbura"},
{"CAMEROON","Yaounde"}, {"CAPE VERDE","Praia"},
{"CENTRAL AFRICAN REPUBLIC","Bangui"},
{"CHAD","N'djamena"}, {"COMOROS","Moroni"},
{"CONGO","Brazzaville"}, {"DJIBOUTI","Dijibouti"},
{"EGYPT","Cairo"}, {"EQUATORIAL GUINEA","Malabo"},
{"ERITREA","Asmara"}, {"ETHIOPIA","Addis Ababa"},
{"GABON","Libreville"}, {"THE GAMBIA","Banjul"},
{"GHANA","Accra"}, {"GUINEA","Conakry"},
{"GUINEA","-"}, {"BISSAU","Bissau"},
{"COTE D'IVOIR (IVORY COAST)","Yamoussoukro"},
{"KENYA","Nairobi"}, {"LESOTHO","Maseru"},
{"LIBERIA","Monrovia"}, {"LIBYA","Tripoli"},
{"MADAGASCAR","Antananarivo"}, {"MALAWI","Lilongwe"},
{"MALI","Bamako"}, {"MAURITANIA","Nouakchott"},
{"MAURITIUS","Port Louis"}, {"MOROCCO","Rabat"},
{"MOZAMBIQUE","Maputo"}, {"NAMIBIA","Windhoek"},
{"NIGER","Niamey"}, {"NIGERIA","Abuja"},
{"RWANDA","Kigali"},
{"SAO TOME E PRINCIPE","Sao Tome"},
{"SENEGAL","Dakar"}, {"SEYCHELLES","Victoria"},
{"SIERRA LEONE","Freetown"}, {"SOMALIA","Mogadishu"},
{"SOUTH AFRICA","Pretoria/Cape Town"},
{"SUDAN","Khartoum"},
{"SWAZILAND","Mbabane"}, {"TANZANIA","Dodoma"},
{"TOGO","Lome"}, {"TUNISIA","Tunis"},
{"UGANDA","Kampala"},
{"DEMOCRATIC REPUBLIC OF THE CONGO (ZAIRE)",
"Kinshasa"},
{"ZAMBIA","Lusaka"}, {"ZIMBABWE","Harare"},
// Asie
{"AFGHANISTAN","Kabul"}, {"BAHRAIN","Manama"},
{"BANGLADESH","Dhaka"}, {"BHUTAN","Thimphu"},
{"BRUNEI","Bandar Seri Begawan"},
{"CAMBODIA","Phnom Penh"},
{"CHINA","Beijing"}, {"CYPRUS","Nicosia"},
{"INDIA","New Delhi"}, {"INDONESIA","Jakarta"},
{"IRAN","Tehran"}, {"IRAQ","Baghdad"},
{"ISRAEL","Tel Aviv"}, {"JAPAN","Tokyo"},
{"JORDAN","Amman"}, {"KUWAIT","Kuwait City"},
{"LAOS","Vientiane"}, {"LEBANON","Beirut"},
{"MALAYSIA","Kuala Lumpur"}, {"THE MALDIVES","Male"},
{"MONGOLIA","Ulan Bator"},
{"MYANMAR (BURMA)","Rangoon"},
{"NEPAL","Katmandu"}, {"NORTH KOREA","P'yongyang"},
{"OMAN","Muscat"}, {"PAKISTAN","Islamabad"},
{"PHILIPPINES","Manila"}, {"QATAR","Doha"},
{"SAUDI ARABIA","Riyadh"}, {"SINGAPORE","Singapore"},
{"SOUTH KOREA","Seoul"}, {"SRI LANKA","Colombo"},
{"SYRIA","Damascus"},
{"TAIWAN (REPUBLIC OF CHINA)","Taipei"},
{"THAILAND","Bangkok"}, {"TURKEY","Ankara"},
{"UNITED ARAB EMIRATES","Abu Dhabi"},
{"VIETNAM","Hanoi"}, {"YEMEN","Sana'a"},
// Australie et Océanie
{"AUSTRALIA","Canberra"}, {"FIJI","Suva"},
{"KIRIBATI","Bairiki"},
{"MARSHALL ISLANDS","Dalap-Uliga-Darrit"},
{"MICRONESIA","Palikir"}, {"NAURU","Yaren"},
{"NEW ZEALAND","Wellington"}, {"PALAU","Koror"},
{"PAPUA NEW GUINEA","Port Moresby"},
{"SOLOMON ISLANDS","Honaira"}, {"TONGA","Nuku'alofa"},
{"TUVALU","Fongafale"}, {"VANUATU","< Port-Vila"},
{"WESTERN SAMOA","Apia"},
// Europe de l'Est et ancienne URSS
{"ARMENIA","Yerevan"}, {"AZERBAIJAN","Baku"},
{"BELARUS (BYELORUSSIA)","Minsk"},
{"GEORGIA","Tbilisi"},
{"KAZAKSTAN","Almaty"}, {"KYRGYZSTAN","Alma-Ata"},
{"MOLDOVA","Chisinau"}, {"RUSSIA","Moscow"},
{"TAJIKISTAN","Dushanbe"}, {"TURKMENISTAN","Ashkabad"},
{"UKRAINE","Kyiv"}, {"UZBEKISTAN","Tashkent"},
// Europe
{"ALBANIA","Tirana"}, {"ANDORRA","Andorra la Vella"},
{"AUSTRIA","Vienna"}, {"BELGIUM","Brussels"},
{"BOSNIA","-"}, {"HERZEGOVINA","Sarajevo"},
{"CROATIA","Zagreb"}, {"CZECH REPUBLIC","Prague"},
{"DENMARK","Copenhagen"}, {"ESTONIA","Tallinn"},
{"FINLAND","Helsinki"}, {"FRANCE","Paris"},
{"GERMANY","Berlin"}, {"GREECE","Athens"},
{"HUNGARY","Budapest"}, {"ICELAND","Reykjavik"},
{"IRELAND","Dublin"}, {"ITALY","Rome"},
{"LATVIA","Riga"}, {"LIECHTENSTEIN","Vaduz"},
{"LITHUANIA","Vilnius"}, {"LUXEMBOURG","Luxembourg"},
{"MACEDONIA","Skopje"}, {"MALTA","Valletta"},
{"MONACO","Monaco"}, {"MONTENEGRO","Podgorica"},
{"THE NETHERLANDS","Amsterdam"}, {"NORWAY","Oslo"},
{"POLAND","Warsaw"}, {"PORTUGAL","Lisbon"},
{"ROMANIA","Bucharest"}, {"SAN MARINO","San Marino"},
{"SERBIA","Belgrade"}, {"SLOVAKIA","Bratislava"},
{"SLOVENIA","Ljujiana"}, {"SPAIN","Madrid"},
{"SWEDEN","Stockholm"}, {"SWITZERLAND","Berne"},
{"UNITED KINGDOM","London"}, {"VATICAN CITY","---"},
// Amérique du Nord et Amérique Centrale
{"ANTIGUA AND BARBUDA","Saint John's"},
{"BAHAMAS","Nassau"},
{"BARBADOS","Bridgetown"}, {"BELIZE","Belmopan"},
{"CANADA","Ottawa"}, {"COSTA RICA","San Jose"},
{"CUBA","Havana"}, {"DOMINICA","Roseau"},
{"DOMINICAN REPUBLIC","Santo Domingo"},
{"EL SALVADOR","San Salvador"},
{"GRENADA","Saint George's"},
{"GUATEMALA","Guatemala City"},
{"HAITI","Port-au-Prince"},
{"HONDURAS","Tegucigalpa"}, {"JAMAICA","Kingston"},
{"MEXICO","Mexico City"}, {"NICARAGUA","Managua"},
{"PANAMA","Panama City"}, {"ST. KITTS","-"},
{"NEVIS","Basseterre"}, {"ST. LUCIA","Castries"},
{"ST. VINCENT AND THE GRENADINES","Kingstown"},
{"UNITED STATES OF AMERICA","Washington, D.C."},
// Amérique du Sud
{"ARGENTINA","Buenos Aires"},
{"BOLIVIA","Sucre (legal)/La Paz(administrative)"},
{"BRAZIL","Brasilia"}, {"CHILE","Santiago"},
{"COLOMBIA","Bogota"}, {"ECUADOR","Quito"},
{"GUYANA","Georgetown"}, {"PARAGUAY","Asuncion"},
{"PERU","Lima"}, {"SURINAME","Paramaribo"},
{"TRINIDAD AND TOBAGO","Port of Spain"},
{"URUGUAY","Montevideo"}, {"VENEZUELA","Caracas"},
};
} ///:~Il s'agit juste d'un tableau à deux dimensions de String(56) Voici un simple test illustrant les méthodes fill( ) et les générateurs :
//: c11:FillTest.java
import com.bruceeckel.util.*;
import java.util.*;
public class FillTest {
private static Generator sg =
new Arrays2.RandStringGenerator(7);
public static void main(String[] args) {
List list = new ArrayList();
Collections2.fill(list, sg, 25);
System.out.println(list + "\n");
List list2 = new ArrayList();
Collections2.fill(list2, Collections2.capitals, 25);
System.out.println(list2 + "\n");
Set set = new HashSet();
Collections2.fill(set, sg, 25);
System.out.println(set + "\n");
Map m = new HashMap();
Collections2.fill(m, Collections2.rsp, 25);
System.out.println(m + "\n");
Map m2 = new HashMap();
Collections2.fill(m2, Collections2.geography, 25);
System.out.println(m2);
}
} ///:~Avec ces outils vous pourrez facilement tester les différents conteneurs en les remplissant avec des données intéressantes.
XI-C. L'inconvénient des conteneurs : le type est inconnu▲
L'« inconvénient » des conteneurs Java est qu'on perd l'information du type lorsqu'un objet est stocké dedans. Ce qui est tout à fait normal puisque le programmeur de la classe conteneur n'a aucune idée du type spécifique qu'on veut stocker dans le conteneur, et que fournir un conteneur qui ne sache stocker qu'un seul type d'objets irait à l'encontre du but de généricité. C'est pourquoi les conteneurs stockent des références sur des Objects, qui est la racine de toutes les classes, afin de pouvoir stocker n'importe quel type (à l'exception bien sûr des types primitifs, qui ne dérivent d'aucune classe). C'est une solution formidable, sauf :
- Puisque l'information de type est ignorée lorsqu'on stocke une référence dans un conteneur, on ne peut placer aucune restriction sur le type de l'objet stocké dans le conteneur, même si on l'a créé pour ne contenir, par exemple, que des chats. Quelqu'un pourrait très bien ajouter un chien dans le conteneur.
- Puisque l'information de type est perdue, la seule chose que le conteneur sache est qu'il contient une référence sur un objet. Il faut réaliser un transtypage sur le type adéquat avant de l'utiliser.
Du côté des choses positives, Java ne permettra pas de mal utiliser les objets mis dans un conteneur. Si on stocke un chien dans le conteneur de chats et qu'on essaie ensuite de traiter tous les objets du conteneur comme un chat, on obtiendra une RuntimeException lors de la tentative de transtypage en chat de la référence sur le chien.
Voici un exemple utilisant le conteneur à tout faire, ArrayList. Les débutants peuvent considérer une ArrayList comme « un tableau qui se redimensionne de lui-même ». L'utilisation d'une ArrayList est aisée : il suffit de la créer, d'y ajouter des éléments avec la méthode add( ), et d'y accéder par la suite grâce à la méthode get( ) en utilisant un index - comme pour un tableau, mais sans les crochets. (57)ArrayList propose aussi une méthode size( ) qui permet de savoir combien d'éléments ont été stockés afin de ne pas dépasser les frontières et causer une exception.
Tout d'abord, nous créons les classes Cat et Dog :
//: c11:Cat.java
package c11;
public class Cat {
private int catNumber;
public Cat(int i) { catNumber = i; }
public void id() {
System.out.println("Cat #" + catNumber);
}
} ///:~//: c11:Dog.java
package c11;
public class Dog {
private int dogNumber;
public Dog(int i) { dogNumber = i; }
public void id() {
System.out.println("Dog #" + dogNumber);
}
} ///:~Des Cats and Dogs sont placés dans le conteneur, puis extraits :
//: c11:CatsAndDogs.java
// Exemple simple avec un conteneur.
// {ThrowsException}
package c11;
import java.util.*;
public class CatsAndDogs {
public static void main(String[] args) {
List cats = new ArrayList();
for(int i = 0; i < 7; i++)
cats.add(new Cat(i));
// Ce n'est pas un problème d'ajouter un chien parmi les chats :
cats.add(new Dog(7));
for(int i = 0; i < cats.size(); i++)
((Cat)cats.get(i)).id();
// Le chien est détecté seulement lors de l'exécution.
}
} ///:~Les classes Cat et Dog sont distinctes ; elles n'ont rien en commun sinon que ce sont des Objects. (dans le cas où une classe ne spécifie pas de classe de base, elle hérite automatiquement de la classe Object). Comme l'ArrayList contient des Objects, on peut non seulement stocker des objets Cat dans le conteneur en utilisant la méthode add( ) de l'ArrayList, mais on peut aussi ajouter des objets Dog sans aucune erreur aussi bien lors de la compilation que de l'exécution. Par contre, lorsqu'une référence sur ce qu'on pense être un objet Cat est extraite via la méthode get( ) de l'ArrayList, on obtient une référence sur un objet qu'il faut transtyper en Cat. Pour éviter une erreur de syntaxe, il faut entourer l'expression par des parenthèses pour forcer l'évaluation du transtypage avant d'appeler la méthode id( ) pour Cat. Ensuite, à l'exécution, lorsque l'on tente de transtyper un objet Dog en Cat, on obtient une exception.
Ceci est plus qu'ennuyeux. Cela peut mener à des bugs relativement durs à trouver. Si une partie (ou plusieurs parties) du programme insère des objets dans le conteneur, et que l'on découvre dans une partie complètement différente du programme via une exception qu'un objet du mauvais type a été placé dans le conteneur, il faut alors déterminer où l'insertion coupable s'est produite. La plupart du temps ce n'est pas un problème, mais il faut avoir conscience de cette possibilité.
XI-C-1. Quelquefois ça marche quand même▲
Dans certains cas les choses semblent fonctionner correctement sans avoir à transtyper vers le type originel. Un cas est assez particulier : la classe String que le compilateur traite de manière particulière pour la faire fonctionner facilement. Quand le compilateur attend un objet String et qu'il ne l'obtient pas, il appellera automatiquement la méthode toString( ) définie dans Object et qui peut être redéfinie par chaque classe Java. Cette méthode produit l'objet String désiré, qui est ensuite utilisé là où il était attendu.
Il suffit donc de redéfinir la méthode toString( ), pour afficher un objet d'une classe donnée, comme on peut le voir dans l'exemple suivant :
//: c11:Mouse.java
// Redéfinition de toString().
public class Mouse {
private int mouseNumber;
public Mouse(int i) { mouseNumber = i; }
// Surcharge de Object.toString():
public String toString() {
return "This is Mouse #" + mouseNumber;
}
public int getNumber() { return mouseNumber; }
} ///:~//: c11:MouseTrap.java
public class MouseTrap {
static void caughtYa(Object m) {
Mouse mouse = (Mouse)m; // Transtypage depuis un Object
System.out.println("Mouse: " + mouse.getNumber());
}
} ///:~//: c11:WorksAnyway.java
// Dans certains cas spéciaux, les choses semblent fonctionner correctement.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class WorksAnyway {
private static Test monitor = new Test();
public static void main(String[] args) {
List mice = new ArrayList();
for(int i = 0; i < 3; i++)
mice.add(new Mouse(i));
for(int i = 0; i < mice.size(); i++) {
// Aucun transtypage nécessaire, appel
// automatique à Object.toString() :
System.out.println("Free mouse: " + mice.get(i));
MouseTrap.caughtYa(mice.get(i));
}
monitor.expect(new String[] {
"Free mouse: This is Mouse #0",
"Mouse: 0",
"Free mouse: This is Mouse #1",
"Mouse: 1",
"Free mouse: This is Mouse #2",
"Mouse: 2"
});
}
} ///:~La méthode toString( ) est redéfinie dans Mouse. Dans la deuxième boucle for de main( ) on peut voir l'instruction :
System.out.println("Free mouse: " + mice.get(i));Après le signe '+' le compilateur s'attend à trouver un objet String. get( ) renvoie un Object, le compilateur appelle donc implicitement la méthode toString( ) pour obtenir l'objet String désiré. Malheureusement, ce comportement magique n'est possible qu'avec les String ; il n'est pas disponible pour les autres types.
Une seconde approche pour cacher le transtypage est de le placer dans la classe MouseTrap. La méthode caughtYa( ) n'accepte pas une Mouse, mais un Object, qu'elle transtype alors en Mouse. Ceci ne fait que repousser le problème puisqu'en acceptant un Object, on peut passer un objet de n'importe quel type à la méthode. Cependant, si le transtypage n'est pas valide -si un objet du mauvais type est passé en argument- une exception est générée lors de l'exécution. Ce n'est pas aussi bien qu'un contrôle lors de la compilation, mais l'approche reste robuste. Notez que lors de l'utilisation de cette méthode :
MouseTrap.caughtYa(mice.get(i));aucun transtypage n'est nécessaire.
XI-C-2. Créer une ArrayList consciente du type▲
Pas question toutefois de s'arrêter en si bon chemin. Une solution encore plus robuste consiste à créer une nouvelle classe utilisant une ArrayList, n'acceptant et ne produisant que des objets du type voulu :
//: c11:MouseList.java
// Une ArrayList consciente du type.
import java.util.*;
public class MouseList {
private List list = new ArrayList();
public void add(Mouse m) { list.add(m); }
public Mouse get(int index) {
return (Mouse)list.get(index);
}
public int size() { return list.size(); }
} ///:~Voici un test pour le nouveau conteneur :
//: c11:MouseListTest.java
import com.bruceeckel.simpletest.*;
public class MouseListTest {
private static Test monitor = new Test();
public static void main(String[] args) {
MouseList mice = new MouseList();
for(int i = 0; i < 3; i++)
mice.add(new Mouse(i));
for(int i = 0; i < mice.size(); i++)
MouseTrap.caughtYa(mice.get(i));
monitor.expect(new String[] {
"Mouse: 0",
"Mouse: 1",
"Mouse: 2"
});
}
} ///:~Cet exemple est similaire au précédent, sauf que la nouvelle classe MouseList dispose d'un membre private de type ArrayList et de méthodes identiques à celles fournies par ArrayList. Cependant, ces méthodes n'acceptent et ne produisent pas des Objects génériques, seulement des objets Mouse.
Notez que si MouseList avait à la place héritée d'ArrayList, la méthode add(Mouse) surchargerait simplement la méthode existanteadd(Object), et aucune restriction sur le type d'objets acceptés n'aurait donc été ajoutée, et vous n'obtiendriez pas les résultats désirés. En utilisant une composition, MouseList utilise simplement l'ArrayList, réalisant certaines opérations avant de déléguer la responsabilité pour le reste de l'opération à l'ArrayList.
Comme une MouseList acceptera seulement une Mouse, si vous faites :
mice.add(new Pigeon());vous obtiendrez un message d'erreur à la compilation . Cette approche, bien que plus fastidieuse du point de vue du code, signalera immédiatement si l'utilisation d'un type incorrect.
Notez aussi qu'aucun transtypage n'est nécessaire lors d'un appel à get( ) ; c'est toujours une Mouse.
XI-C-2-a. Types paramétrés▲
Ce type de problème n'est pas isolé. Nombreux sont les cas dans lesquels on a besoin de créer de nouveaux types basés sur d'autres types, et dans lesquels il serait utile de récupérer des informations de type lors de la phase de compilation. C'est le concept des types paramétrés. En C++, ceci est directement supporté par le langage via les templates. Il est probable que Java JDK 1.5 fournira des generics, la version Java des types paramétrés.
XI-D. Iterators▲
Chaque classe conteneur fournit des méthodes pour stocker des objets et pour les extraire - après tout, le but d'un conteneur est de stocker des choses. Dans ArrayList, on insère des objets via la méthode add( ), et get( ) est l'un des moyens de récupérer ces objets. ArrayList est relativement souple - il est possible de sélectionner n'importe quel élément à n'importe quel moment, ou de sélectionner plusieurs éléments en même temps en utilisant différents index.
Si on se place à un niveau d'abstraction supérieur, on s'aperçoit d'un inconvénient : on a besoin de connaître le type exact du conteneur afin de l'utiliser. Ceci peut sembler bénin à première vue, mais qu'en est-il si on commence à programmer en utilisant une ArrayList, et qu'on se rend compte par la suite qu'il serait plus efficace d'utiliser un Set à la place ? Ou alors si on veut écrire une portion de code générique qui ne connait pas le type de conteneur avec lequel elle travaille, afin de pouvoir être utilisée avec différents types de conteneurs sans avoir à réécrire ce code ?
Le concept d'itérateur peut être utilisé pour réaliser cette abstraction. Un itérateur est un objet dont le travail est de se déplacer dans une séquence d'objets et de sélectionner chaque objet de cette séquence sans que le programmeur client n'ait à se soucier de la structure sous-jacente de cette séquence. De plus, un itérateur est généralement ce qu'il est convenu d'appeler un objet « léger » : un objet bon marché à construire. Pour cette raison, vous trouverez souvent des contraintes étranges sur les itérateurs ; par exemple, certains itérateurs ne peuvent se déplacer que dans un sens.
L'Iterator Java est l'exemple type d'un itérateur avec ce genre de contraintes. On ne peut faire grand-chose avec mis à part :
- Demander à un conteneur de renvoyer un Iterator en utilisant une méthode appelée iterator( ). Cet Iterator sera prêt à renvoyer le premier élément dans la séquence au premier appel à sa méthode next( ).
- Récupérer l'objet suivant dans la séquence grâce à sa méthode next( ).
- Vérifier s'il reste encore d'autres objets dans la séquence via la méthode hasNext( ).
- Enlever le dernier élément renvoyé par l'itérateur avec la méthode remove( ).
Et c'est tout. C'est une implémentation simple d'un itérateur, mais néanmoins puissante (et il existe un ListIterator plus sophistiqué pour les Lists). Pour le voir en action, revisitons le programme CatsAndDogs.java rencontré précédemment dans ce chapitre. Dans sa version originale, la méthode get( ) était utilisée pour sélectionner chaque élément, mais la version modifiée suivante se sert d'un Iterator :
//: c11:CatsAndDogs2.java
// Conteneur simple utilisant un Iterator.
package c11;
import com.bruceeckel.simpletest.*;
import java.util.*;
public class CatsAndDogs2 {
private static Test monitor = new Test();
public static void main(String[] args) {
List cats = new ArrayList();
for(int i = 0; i < 7; i++)
cats.add(new Cat(i));
Iterator e = cats.iterator();
while(e.hasNext())
((Cat)e.next()).id();
}
} ///:~Vous pouvez constater que les dernières lignes utilisent maintenant un Iterator pour se déplacer dans la séquence à la place d'une boucle for. Avec l'Iterator, on n'a pas besoin de se soucier du nombre d'éléments dans le conteneur. Cela est géré via les méthodes hasNext( ) et next( ).
Comme autre exemple, considérons maintenant la création d'une méthode générique d'affichage :
//: c11:Printer.java
// Using an Iterator.
import java.util.*;
public class Printer {
static void printAll(Iterator e) {
while(e.hasNext())
System.out.println(e.next());
}
} ///:~Examinez attentivement la méthode printAll( ) et notez qu'elle ne dispose d'aucune information sur le type de séquence. Tout ce dont elle dispose est un Iterator, et c'est la seule chose dont elle a besoin pour utiliser la séquence : elle peut récupérer l'objet suivant, et savoir si elle se trouve à la fin de la séquence. Cette idée de prendre un conteneur d'objets et de le parcourir pour réaliser une opération sur chaque élément est un concept puissant, et on le retrouvera tout au long de ce livre.
Cet exemple est même encore plus générique, puisqu'il utilise implicitement la méthode Object.toString( ). La méthode println( ) est surchargée pour tous les types primitifs ainsi que dans Object ; dans chaque cas une String est automatiquement produite en appelant la méthode toString( ) appropriée.
Bien que cela ne soit pas nécessaire, on pourrait être plus explicite en utilisant un cast, ce qui aurait pour effet d'appeler toString( ) :
System.out.println((String)e.next());En général, cependant, on voudra certainement aller au-delà de l'appel des méthodes de la classe Object, et on se heurte de nouveau au problème du transtypage. Il faut donc assumer qu'on a récupéré un Iterator sur une séquence contenant des objets du type particulier qui nous intéresse, et transtyper les objets dans ce type (et recevoir une exception à l'exécution si on se trompe).
Nous pouvons nous en rendre compte en affichant des Hamsters:
//: c11:Hamster.java
public class Hamster {
private int hamsterNumber;
public Hamster(int hamsterNumber) {
this.hamsterNumber = hamsterNumber;
}
public String toString() {
return "This is Hamster #" + hamsterNumber;
}
} ///:~//: c11:HamsterMaze.java
// Using an Iterator.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class HamsterMaze {
private static Test monitor = new Test();
public static void main(String[] args) {
List list = new ArrayList();
for(int i = 0; i < 3; i++)
list.add(new Hamster(i));
Printer.printAll(list.iterator());
monitor.expect(new String[] {
"This is Hamster #0",
"This is Hamster #1",
"This is Hamster #2"
});
}
} ///:~Vous pourriez écrire printAll( ) de telle sorte qu'il accepte un objet de type Collection plutôt qu'un Iterator, mais notre version fournit de meilleurs découplages.
XI-D-1. Récursion indésirable▲
Comme les conteneurs standard Java héritent de la classe Object (comme toutes les autres classes), ils contiennent une méthode toString( ). Celle-ci a été redéfinie afin de produire une représentation String d'eux-mêmes, incluant les objets qu'ils contiennent. À l'intérieur d'ArrayList, la méthode toString( ) parcourt les éléments de l'ArrayList et appelle toString( ) pour chacun d'eux. Supposons qu'on veuille afficher l'adresse de l'instance. Il semble raisonnable de se référer à this (en particulier pour les programmeurs C++ qui sont habitués à cette approche) :
//: c11:InfiniteRecursion.java
// Recursion accidentelle
import java.util.*;
public class InfiniteRecursion {
public String toString() {
return " InfiniteRecursion address: " + this + "\n";
}
public static void main(String[] args) {
List v = new ArrayList();
for(int i = 0; i < 10; i++)
v.add(new InfiniteRecursion());
System.out.println(v);
}
} ///:~Si on crée un objet InfiniteRecursion et qu'on veut l'afficher, on se retrouve avec une séquence infinie d'exceptions. C'est également vrai si on place des objets InfiniteRecursion dans une ArrayList et qu'on imprime cette ArrayList comme c'est le cas ici. Ceci est dû à la conversion automatique de type sur les Strings. Quand on écrit :
"InfiniteRecursion address: " + thisLe compilateur voit une String suivie par un « + » et quelque chose qui n'est pas une String, il essaie donc de convertir this en String. Il réalise cette conversion en appelant toString( ), ce qui produit un appel récursif.
Si on veut réellement imprimer l'adresse de l'objet dans ce cas, la solution est d'appeler la méthode Object.toString( ), qui réalise exactement ceci. Il faut donc utiliser super.toString( ) à la place de this.
XI-E. Classification des conteneurs▲
Les Collections et les Maps peuvent être implémentées de différentes manières, à vous de choisir la bonne selon vos besoins. Le diagramme suivant peut aider à s'y retrouver parmi les conteneurs Java (tel que dans le JDK 1.4) :
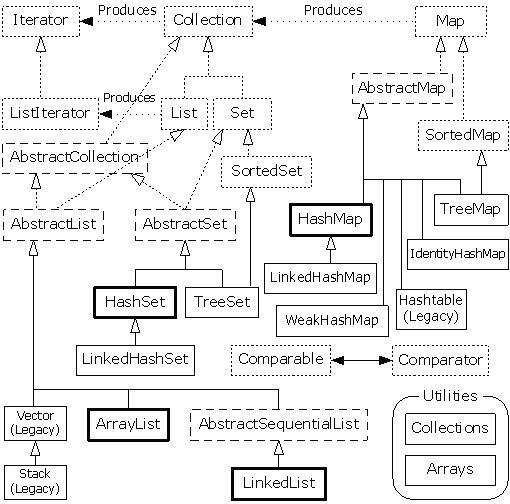
Ce diagramme peut sembler un peu surchargé à première vue, mais il n'y a en fait que trois types conteneurs de base : les Maps, les Lists et les Sets, chacun d'entre eux ne proposant que deux ou trois implémentations. Les conteneurs que vous utiliserez le plus souvent sont encadrés en noir. Quand on constate ceci, les conteneurs ne sont plus aussi intimidants.
Les boîtes en pointillé représentent les interfaces, les boîtes en tirets représentent des classes abstract, et les boîtes pleines sont des classes normales (concrètes). Les lignes pointillées indiquent qu'une classe particulière implémente une interface (ou dans le cas d'une classe abstract, implémente partiellement cette interface). Une flèche pleine indique qu'une classe peut produire des objets de la classe sur laquelle la flèche pointe. Par exemple, une Collection peut produire un Iterator, tandis qu'une List peut produire un ListIterator (ainsi qu'un Iterator ordinaire, puisque List est dérivée de Collection).
Les interfaces concernées par le stockage des objets sont Collection, List, Set et Map. Idéalement, la majorité du code qu'on écrit sera destinée à ces interfaces, et le seul endroit où on spécifiera le type précis utilisé est lors de la création. On pourra donc créer une List de cette manière :
List x = new LinkedList();bien sûr vous pouvez décidez de déclarer x en tant que LinkedList (plutôt que le type générique List). La beauté (et le but) d'utiliser une interface est que si vous souhaitez changer votre implémentation, tout ce dont vous avez besoin est de changer la création comme ceci :
List x = new ArrayList();Et on ne touche pas au reste du code (une telle généricité peut aussi être réalisée via des itérateurs).
Dans la hiérarchie de classes, on peut voir un certain nombre de classes dont le nom débute par « abstract », ce qui peut paraître un peu déroutant au premier abord. Ce sont simplement des outils qui implémentent partiellement une interface particulière. Si on voulait réaliser notre propre Set, par exemple, il serait plus simple de dériver AbstractSet et de réaliser le travail minimum pour créer la nouvelle classe, plutôt que d'implémenter l'interface Set et toutes les méthodes qui vont avec. Cependant, la bibliothèque de conteneurs possède assez de fonctionnalités pour satisfaire quasiment tous nos besoins. De notre point de vue, nous pouvons donc ignorer les classes débutant par « abstract ».
Ainsi, lorsqu'on regarde le diagramme, on n'est réellement concerné que par les interfaces du haut du diagramme et les classes concrètes (celles qui sont entourées par des boîtes solides). Typiquement, on se contentera de créer un objet d'une classe concrète, de la transtyper dans son interface correspondante, et ensuite utiliser cette interface tout au long du code. De plus, on n'a pas besoin de se préoccuper des éléments préexistants lorsqu'on produit du nouveau code. Le diagramme peut donc être grandement simplifié pour ressembler à ceci :
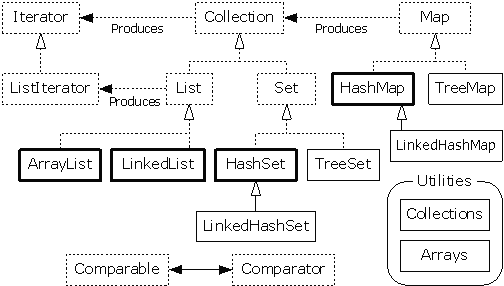
Il n'inclut plus maintenant que les classes et les interfaces que vous serez amenés à rencontrer régulièrement, ainsi que les éléments sur lesquels nous allons nous pencher dans ce chapitre. Remarquez que le WeakHashMap ainsi que le IdentityHashMap du jdk 1.4 ne sont pas inclus dans ce diagramme, car ils sont d'une utilité bien particulière qui vous concernera très rarement.
Voici un exemple simple, qui remplit une Collection (représenté ici par une ArrayList) avec des objets String, et affiche ensuite chaque élément de la Collection :
//: c11:SimpleCollection.java
// Un exemple simple d'utilisation des Collections Java 2
import com.bruceeckel.simpletest.*;
import java.util.*;
public class SimpleCollection {
private static Test monitor = new Test();
public static void main(String[] args) {
// Transtypage ascendant parce qu'on veut juste
// travailler avec les fonctionnalités d'une Collection
Collection c = new ArrayList();
for(int i = 0; i < 10; i++)
c.add(Integer.toString(i));
Iterator it = c.iterator();
while(it.hasNext())
System.out.println(it.next());
monitor.expect(new String[] {
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
});
}
} ///:~La première ligne de main( ) crée un objet ArrayList et le transtype ensuite en une Collection. Puisque cet exemple n'utilise que les méthodes de Collection, tout objet d'une classe dérivée de Collection fonctionnerait, mais l'ArrayList est la Collection à tout faire typique.
La méthode add( ), comme son nom le suggère, ajoute un nouvel élément dans la Collection. En fait, la documentation précise bien que add( ) « assure que le conteneur contiendra l'élément spécifié ». Cette précision concerne les Sets, qui n'ajoutent un élément que s'il n'est pas déjà présent. Avec une ArrayList, ou n'importe quel type de List, add( ) veut toujours dire « stocker dans », parce qu'une List se moque de contenir des doublons.
Toutes les Collections peuvent produire un Iterator grâce à leur méthode iterator( ). Ici, un Iterator est créé et utilisé pour traverser la Collection, en affichant chaque élément.
XI-F. Fonctionnalités des Collection▲
La table suivante contient toutes les opérations définies pour une Collection (sans inclure les méthodes directement héritées de la classe Object), et donc pour un Set ou une List (les Lists possèdent aussi d'autres fonctionnalités). Les Maps n'héritant pas de Collection, elles seront traitées séparément.
|
boolean add(Object) |
Assure que le conteneur stocke l'argument. Renvoie false si elle n'ajoute pas l'argument (c'est une méthode « optionnelle », décrite plus tard dans ce chapitre). |
|
boolean |
Ajoute tous les éléments de l'argument. Renvoie true si un élément a été ajouté (« optionnelle »). |
|
void clear( ) |
Supprime tous les éléments du conteneur (« optionnelle »). |
|
boolean |
true si le conteneur contient l'argument. |
|
boolean containsAll(Collection) |
true si le conteneur contient tous les éléments de l'argument. |
|
boolean isEmpty( ) |
true si le conteneur ne contient pas d'éléments. |
|
Iterator iterator( ) |
Renvoie un Iterator que vous pouvez utiliser pour parcourir les éléments du conteneur. |
|
boolean |
Si l'argument est dans le conteneur, une instance de cet élément est enlevée. Renvoie true si c'est le cas. (« optionnelle »). |
|
boolean removeAll(Collection) |
Supprime tous les éléments contenus dans l'argument. Renvoie true si au moins une suppression a été effectuée. (« optionnelle »). |
|
boolean retainAll(Collection) |
Ne garde que les éléments contenus dans l'argument (une « intersection » selon la théorie des ensembles). Renvoie true s'il y a eu un changement. (« optionnelle »). |
|
int size( ) |
Renvoie le nombre d'éléments dans le conteneur. |
|
Object[] toArray( ) |
Renvoie un tableau contenant tous les éléments du conteneur. |
|
Object[] |
Renvoie un tableau contenant tous les éléments du conteneur, dont le type est celui du tableau a au lieu d'Objects génériques (il faut transtyper le tableau dans son type correct). |
Notez qu'il n'existe pas de fonction get( ) permettant un accès aléatoire. Ceci parce que les Collections contiennent aussi les Sets, qui maintiennent leur propre ordre interne, faisant de toute tentative d'accès aléatoire un non-sens. Il faut donc utiliser un Iterator pour parcourir tous les éléments d'une Collection.
L'exemple suivant illustre toutes ces méthodes. Encore une fois, cet exemple marcherait avec tout objet héritant de Collection, mais nous utilisons ici une ArrayList comme « plus petit dénominateur commun » :
//: c11:Collection1.java
// Opérations disponibles sur les Collections.
import com.bruceeckel.simpletest.*;
import java.util.*;
import com.bruceeckel.util.*;
public class Collection1 {
private static Test monitor = new Test();
public static void main(String[] args) {
Collection c = new ArrayList();
Collections2.fill(c, Collections2.countries, 5);
c.add("ten");
c.add("eleven");
System.out.println(c);
// Crée un tableau à partir de la List :
Object[] array = c.toArray();
// Crée un tableau de Strings à partir de la List
String[] str = (String[])c.toArray(new String[1]);
// Trouve les éléments mini et maxi ; ceci peut
// signifier différentes choses suivant la manière
// dont l'interface Comparable est implémentée :
System.out.println("Collections.max(c) = " +
Collections.max(c));
System.out.println("Collections.min(c) = " +
Collections.min(c));
// Ajoute une Collection à une autre Collection
Collection c2 = new ArrayList();
Collections2.fill(c2, Collections2.countries, 5);
c.addAll(c2);
System.out.println(c);
c.remove(CountryCapitals.pairs[0][0]);
System.out.println(c);
c.remove(CountryCapitals.pairs[1][0]);
System.out.println(c);
// Supprime tous les éléments
// de la Collection argument :
c.removeAll(c2);
System.out.println(c);
c.addAll(c2);
System.out.println(c);
// Est-ce qu'un élément est dans la Collection ?
String val = CountryCapitals.pairs[3][0];
System.out.println("c.contains(" + val + ") = "
+ c.contains(val));
/ Est-ce qu'une Collection est contenue dans la Collection ?
System.out.println(
"c.containsAll(c2) = " + c.containsAll(c2));
Collection c3 = ((List)c).subList(3, 5);
// Garde les éléments présents à la fois dans
// c2 et c3 (intersection d'ensembles) :
c2.retainAll(c3);
System.out.println(c);
// Supprime tous les éléments
// de c2 qui apparaissent aussi dans c3 :
c2.removeAll(c3);
System.out.println("c.isEmpty() = " + c.isEmpty());
c = new ArrayList();
Collections2.fill(c, Collections2.countries, 5);
System.out.println(c);
c.clear(); // Supprime tous les éléments
System.out.println("after c.clear():");
System.out.println(c);
monitor.expect(new String[] {
"[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, " +
"ten, eleven]",
"Collections.max(c) = ten",
"Collections.min(c) = ALGERIA",
"[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, " +
"ten, eleven, BURUNDI, CAMEROON, CAPE VERDE, " +
"CENTRAL AFRICAN REPUBLIC, CHAD]",
"[ANGOLA, BENIN, BOTSWANA, BURKINA FASO, ten, " +
"eleven, BURUNDI, CAMEROON, CAPE VERDE, " +
"CENTRAL AFRICAN REPUBLIC, CHAD]",
"[BENIN, BOTSWANA, BURKINA FASO, ten, eleven, " +
"BURUNDI, CAMEROON, CAPE VERDE, " +
"CENTRAL AFRICAN REPUBLIC, CHAD]",
"[BENIN, BOTSWANA, BURKINA FASO, ten, eleven]",
"[BENIN, BOTSWANA, BURKINA FASO, ten, eleven, " +
"BURUNDI, CAMEROON, CAPE VERDE, " +
"CENTRAL AFRICAN REPUBLIC, CHAD]",
"c.contains(BOTSWANA) = true",
"c.containsAll(c2) = true",
"[BENIN, BOTSWANA, BURKINA FASO, ten, eleven, " +
"BURUNDI, CAMEROON, CAPE VERDE, " +
"CENTRAL AFRICAN REPUBLIC, CHAD]",
"c.isEmpty() = false",
"[COMOROS, CONGO, DJIBOUTI, EGYPT, " +
"EQUATORIAL GUINEA]",
"after c.clear():",
"[]"
});
}
} ///:~Les ArrayLists sont créées et initialisées avec différents ensembles de données, puis transtypées en objets Collection ; il est donc clair que seules les fonctions de l'interface Collection sont utilisées. main( ) réalise de simples opérations pour illustrer toutes les méthodes de Collection.
Les sections suivantes décrivent les diverses implémentations des List, Set et Map et indiquent dans chaque cas (à l'aide d'un astérisque) laquelle devrait être votre choix par défaut. Vous noterez que les classes préexistantes Vector, Stack et Hashtable ne sont pas incluses, car il existe des Classes à préférer dans les conteneurs Java 2.
XI-G. Fonctionnalités des List▲
La List de base est relativement simple à utiliser, comme vous avez pu le constater jusqu'à présent avec les ArrayLists. La plupart du temps, vous n'utiliserez que les méthodes courantes add( ) pour insérer des objets, get( ) pour les retrouver un par un, et iterator( ) pour obtenir un Iterator sur la séquence. Mais les Listes possèdent tout un ensemble de méthodes qui peuvent se révéler très pratiques.
Les Lists sont déclinées en deux versions : l'ArrayList de base, qui excelle dans les accès aléatoires aux éléments, et la LinkedList, bien plus puissante qui n'a pas été conçue pour un accès aléatoire optimisé, mais dispose d'un ensemble de méthodes bien plus conséquent.
|
List (interface) |
L'ordre est la caractéristique la plus importante d'une List ; elle garantit de maintenir les éléments dans un ordre particulier. Les Lists ajoutent des méthodes supplémentaires à Collection permettant l'insertion et la suppression d'éléments au milieu d'une List (ceci n'est toutefois recommandé que pour une LinkedList). Une List produit des ListIterators, qui permettent de parcourir la List dans les deux directions et d'insérer et de supprimer des éléments au sein de la List. |
|
ArrayList* |
Une List implémentée avec un tableau. Permet un accès aléatoire instantané aux éléments, mais se révèle plus lente lorsqu'on insère ou supprime un élément au milieu de la liste. Le ListIterator ne devrait être utilisé que pour parcourir l'ArrayList dans les deux sens, et non pour l'insertion et la suppression d'éléments, opérations coûteuses comparées aux LinkedLists. |
|
LinkedList |
Fournit un accès séquentiel optimal, avec des coûts d'insertion et de suppression d'éléments au sein de la List négligeables. Relativement lente pour l'accès aléatoire (préférer une ArrayList pour cela). Fournit aussi les méthodes addFirst( ), addLast( ), getFirst( ), getLast( ), removeFirst( ), et removeLast( ) (qui ne sont définies dans aucune interface ou classe de base) afin de pouvoir être utilisée comme une pile (« stack »), une file (une « queue ») ou une file double (queue à double entrée, « deque »). |
Les méthodes dans l'exemple suivant couvrent chacune un groupe de fonctionnalités : les opérations disponibles pour toutes les listes (basicTest( )), le déplacement dans une liste avec un Iterator (iterMotion( )) ainsi que la modification dans une liste avec un Iterator (iterManipulation( )), la visualisation des manipulations de la List (testVisual( )) et les opérations disponibles uniquement pour les LinkedLists.
//: c11:List1.java
// Opérations disponibles sur les Lists.
import java.util.*;
import com.bruceeckel.util.*;
public class List1 {
public static List fill(List a) {
Collections2.countries.reset();
Collections2.fill(a, Collections2.countries, 10);
return a;
}
private static boolean b;
private static Object o;
private static int i;
private static Iterator it;
private static ListIterator lit;
public static void basicTest(List a) {
a.add(1, "x"); // Ajout à l'emplacement 1
a.add("x"); // Ajout à la fin
// Ajout d'une Collection :
a.addAll(fill(new ArrayList()));
// Ajout d'une Collection à partir du 3e élément :
a.addAll(3, fill(new ArrayList()));
b = a.contains("1"); // L'élément est-il présent ?
// La Collection entière est-elle présente ?
b = a.containsAll(fill(new ArrayList()));
// Les Lists permettent un accès aléatoire aux éléments,
// bon marché pour les ArrayLists, coûteux pour les LinkedLists :
o = a.get(1); // Récupère l'objet du premier emplacement
i = a.indexOf("1"); // Donne l'index de l'objet
b = a.isEmpty(); // La List contient-elle des éléments ?
it = a.iterator(); // Iterator de base
lit = a.listIterator(); // ListIterator
lit = a.listIterator(3); // Démarre au 3e élément
i = a.lastIndexOf("1"); // Dernière concordance
a.remove(1); // Supprime le premier élément
a.remove("3"); // Supprime cet objet
a.set(1, "y"); // Positionne le premier élément à "y"
// Garde tous les éléments présents dans l'argument
// (intersection de deux ensembles) :
a.retainAll(fill(new ArrayList()));
// Supprime tous les éléments présents dans l'argument :
a.removeAll(fill(new ArrayList()));
i = a.size(); // Taille de la List ?
a.clear(); // Supprime tous les éléments
}
public static void iterMotion(List a) {
ListIterator it = a.listIterator();
b = it.hasNext();
b = it.hasPrevious();
o = it.next();
i = it.nextIndex();
o = it.previous();
i = it.previousIndex();
}
public static void iterManipulation(List a) {
ListIterator it = a.listIterator();
it.add("47");
// Doit aller sur un élément après add() :
it.next();
// Supprime l'élément qui vient d'être produit :
it.remove();
// Doit aller sur un élément après remove() :
it.next();
// Change l'élément qui vient d'être produit :
it.set("47");
}
public static void testVisual(List a) {
System.out.println(a);
List b = new ArrayList();
fill(b);
System.out.print("b = ");
System.out.println(b);
a.addAll(b);
a.addAll(fill(new ArrayList()));
System.out.println(a);
// Insère, supprime et remplace des éléments
// en utilisant un ListIterator :
ListIterator x = a.listIterator(a.size()/2);
x.add("one");
System.out.println(a);
System.out.println(x.next());
x.remove();
System.out.println(x.next());
x.set("47");
System.out.println(a);
// Traverse la liste à l'envers :
x = a.listIterator(a.size());
while(x.hasPrevious())
System.out.print(x.previous() + " ");
System.out.println();
System.out.println("testVisual finished"
}
// Certaines opérations ne sont disponibles
// que pour des LinkedLists :
public static void testLinkedList() {
LinkedList ll = new LinkedList();
fill(ll);
System.out.println(ll);
// Utilisation comme une pile, insertion (push) :
ll.addFirst("one");
ll.addFirst("two");
System.out.println(ll);
// Utilisation comme une pile, récupération de la valeur du premier élément (peek) :
System.out.println(ll.getFirst());
// Utilisation comme une pile, suppression (pop) :
System.out.println(ll.removeFirst());
System.out.println(ll.removeFirst());
// Utilisation comme une file, en retirant les
// éléments à la fin de la liste :
System.out.println(ll.removeLast());
// Avec les opérations ci-dessus, c'est une file double !
System.out.println(ll);
}
public static void main(String[] args) {
// Crée et remplit une nouvelle List à chaque fois :
basicTest(fill(new LinkedList()));
basicTest(fill(new ArrayList()));
iterMotion(fill(new LinkedList()));
iterMotion(fill(new ArrayList()));
iterManipulation(fill(new LinkedList()));
iterManipulation(fill(new ArrayList()));
testVisual(fill(new LinkedList()));
testLinkedList();
}
} ///:~Dans basicTest( ) et iterMotion( ), les appels sont présents pour montrer la bonne syntaxe, et bien que la valeur de retour soit récupérée, elle n'est pas utilisée. Dans certains cas, elle n'est même pas du tout capturée. Vous devriez bien observer l'utilisation de chacune de ces méthodes dans la documentation du JDK, sur java.sun.com avant de les utiliser.
Souvenez-vous qu'un conteneur est juste un « coffre » de stockage pour objets. Si ce coffre répond à vos besoins, la manière dont il est implémenté n'est pas très importante (un concept valable pour la plupart des types d'objets). Si vous travaillez dans un environnement de programmation qui incorpore des surcoûts pour d'autres raisons, la différence entre ArrayList et LinkedList peut ne pas compter. Vous pouvez n'avoir besoin que du type « sequence ». Vous pouvez même imaginer l'idée du parfait conteneur, qui change son implémentation sous-jacente selon la manière dont il est utilisé.
XI-G-1. Réaliser une pile à partir d'une LinkedList▲
Une pile est souvent assimilée à un conteneur « dernier arrivé, premier sorti » (LIFO - « Last In, First Out »). C'est-à-dire que l'objet qu'on « pousse » (« push »)sur la pile en dernier sera le premier accessible lors d'une extraction (« pop »). Comme tous les autres conteneurs de Java, on stocke et récupère des Objects, qu'il faudra donc transtyper après leur extraction, à moins qu'on ne se contente des fonctionnalités de la classe Object.
La classe LinkedList possède des méthodes qui implémentent directement les fonctionnalités d'une pile, on peut donc utiliser directement une LinkedList plutôt que de créer une classe implémentant une pile. Cependant une classe Pile est souvent plus explicite :
//: c11:StackL.java
// Réaliser une pile à partir d'une LinkedList.
import com.bruceeckel.simpletest.*;
import java.util.*;
import com.bruceeckel.util.*;
public class StackL {
private static Test monitor = new Test();
private LinkedList list = new LinkedList();
public void push(Object v) { list.addFirst(v); }
public Object top() { return list.getFirst(); }
public Object pop() { return list.removeFirst(); }
public static void main(String[] args) {
StackL stack = new StackL();
for(int i = 0; i < 10; i++)
stack.push(Collections2.countries.next());
System.out.println(stack.top());
System.out.println(stack.top());
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
monitor.expect(new String[] {
"CHAD",
"CHAD",
"CHAD",
"CENTRAL AFRICAN REPUBLIC",
"CAPE VERDE"
});
}
} ///:~L'héritage n'est pas approprié ici puisqu'il produirait une classe contenant toutes les méthodes d'une LinkedList (on verra plus tard que cette grossière erreur a déjà été faite par les concepteurs de la bibliothèque Java 1.0 avec la classe Stack).
XI-G-2. Réaliser une file à partir d'une LinkedList▲
Une file (ou queue) est un conteneur « premier arrivé, premier sorti » (FIFO - « First In, First Out »). C'est-à-dire qu'on « pousse » des objets à une extrémité et qu'on les en retire à l'autre extrémité. L'ordre dans lequel on pousse les objets sera donc le même que l'ordre dans lequel on les récupérera. La classe LinkedList possède des méthodes qui implémentent les fonctionnalités d'une file, on peut donc les utiliser directement dans une classe Queue :
//: c11:Queue.java
// Réaliser une file à partir d'une LinkedList.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class Queue {
private static Test monitor = new Test();
private LinkedList list = new LinkedList();
public void put(Object v) { list.addFirst(v); }
public Object get() { return list.removeLast(); }
public boolean isEmpty() { return list.isEmpty(); }
public static void main(String[] args) {
Queue queue = new Queue();
for(int i = 0; i < 10; i++)
queue.put(Integer.toString(i));
while(!queue.isEmpty())
System.out.println(queue.get());
monitor.expect(new String[] {
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
});
}
} ///:~Il est aussi facile de créer une file double (queue à double entrée) à partir d'une LinkedList. Une file double est une file à laquelle on peut ajouter et supprimer des éléments à chaque extrémité.
XI-H. Fonctionnalités des Sets▲
Les Sets ont exactement la même interface que les Collections, et à l'inverse des deux différentes Lists, ils ne proposent aucune fonctionnalité supplémentaire. Les Sets sont donc juste une Collection ayant un comportement particulier (implémenter un comportement différent constitue l'exemple type où il faut utiliser l'héritage et le polymorphisme). Un Set refuse de contenir plus d'une instance de chaque valeur d'un objet (savoir ce qu'est la « valeur » d'un objet est plus compliqué, comme nous allons le voir).
|
Set (interface) |
Chaque élément ajouté au Set doit être unique ; sinon le Set n'ajoutera pas le doublon. Les Objects ajoutés à un Set doivent définir la méthode equals() pour pouvoir établir l'unicité de l'objet. Un Set possède la même interface qu'une Collection. L'interface Set ne garantit pas qu'il maintiendra les éléments dans un ordre particulier. |
|
HashSet* |
Pour les Sets où le temps d'accès aux éléments est primordial. Les Objects doivent définir la méthode hashCode(). |
|
TreeSet |
Un Set trié stocké dans un arbre. De cette manière, on peut extraire une séquence triée à partir du Set. |
|
LinkedHashSet |
Possède la vitesse de temps d'accès d'un HashSet, mais maintient l'ordre dans lequel les éléments ont été insérés, utilise une liste chainée en interne. Donc quand vous itérez à travers un Set, le résultat apparait dans le sens d'insertion. |
L'exemple suivant ne montre pas tout ce qu'il est possible de faire avec un Set, puisque l'interface est la même que pour les Collections, et comme telle a déjà été testée dans l'exemple précédent. Par contre, il illustre les comportements qui rendent un Set particulier :
//: c11:Set1.java
// Opérations disponibles pour les Sets.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class Set1 {
private static Test monitor = new Test();
static void fill(Set s) {
s.addAll(Arrays.asList(
"one two three four five six seven".split(" ")));
}
public static void test(Set s) {
// Strip qualifiers from class name:
System.out.println(
s.getClass().getName().replaceAll("\\w+\\.", ""));
fill(s); fill(s); fill(s);
System.out.println(s); // Pas de doublons !
// Ajoute un autre ensemble à celui-ci :
s.addAll(s);
s.add("one");
s.add("one");
s.add("one");
System.out.println(s);
// Extraction d'item :
System.out.println("s.contains(\"one\"): " +
s.contains("one"));
}
public static void main(String[] args) {
test(new HashSet());
test(new TreeSet());
test(new LinkedHashSet());
monitor.expect(new String[] {
"HashSet",
"[one, two, five, four, three, seven, six]",
"[one, two, five, four, three, seven, six]",
"s.contains(\"one\"): true",
"TreeSet",
"[five, four, one, seven, six, three, two]",
"[five, four, one, seven, six, three, two]",
"s.contains(\"one\"): true",
"LinkedHashSet",
"[one, two, three, four, five, six, seven]",
"[one, two, three, four, five, six, seven]",
"s.contains(\"one\"): true"
});
}
} ///:~Cet exemple tente d'ajouter des valeurs dupliquées au Set, mais lorsqu'on l'affiche on voit que le Set n'accepte qu'une instance de chaque valeur.
Lorsqu'on lance ce programme, on voit que l'ordre interne maintenu par le HashSet est différent de celui de TreeSet et de LinkedHashSet, puisque chacune de ces implémentations stocke les éléments d'une manière différente(TreeSet garde les éléments triés, tandis que HashSet utilise une fonction de hachage, conçue spécialement pour des accès optimisés. LinkedHashSet utilise un hachage interne pour un accès rapide, mais semble maintenir les éléments dans l'ordre d'insertion utilisant une liste chainée.) Quand on crée un nouveau type, il faut bien se rappeler qu'un Set a besoin de maintenir un ordre de stockage, ce qui veut dire qu'il faut implémenter l'interface Comparable et définir la méthode compareTo(). Voici un exemple :
//: c11:Set2.java
// Ajout d'un type particulier dans un Set.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class Set2 {
private static Test monitor = new Test();
public static Set fill(Set a, int size) {
for(int i = 0; i < size; i++)
a.add(new MyType(i));
return a;
}
public static void test(Set a) {
fill(a, 10);
fill(a, 10); // Tente d'ajouter des doublons
fill(a, 10);
a.addAll(fill(new TreeSet(), 10));
System.out.println(a);
}
public static void main(String[] args) {
test(new HashSet());
test(new TreeSet());
test(new LinkedHashSet());
monitor.expect(new String[] {
"[2 , 4 , 9 , 8 , 6 , 1 , 3 , 7 , 5 , 0 ]",
"[9 , 8 , 7 , 6 , 5 , 4 , 3 , 2 , 1 , 0 ]",
"[0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]"
});
}
} ///:~La forme que doivent avoir les définitions des méthodes equals() et hashCode() sera décrite plus tard dans ce chapitre. Il faut définir une méthode equals() pour les deux implémentations de Set, mais hashCode() n'est nécessaire que si la classe est placée dans un HashSet (ce qui est probable, puisqu'il s'agit de l'implémentation recommandée pour un Set). Cependant, c'est une bonne pratique de programmation de redéfinir hashCode() lorsqu'on redéfinit equals(). Ce processus sera examiné en détail plus loin dans ce chapitre.
Notez que je n'ai pas utilisé la forme « simple et évidente » return i-i2 dans la méthode compareTo(). Bien que ce soit une erreur de programmation classique, elle ne fonctionne que si i et i2 sont des ints « non signés » (si Java disposait d'un mot-clef « unsigned », ce qu'il n'a pas). Elle ne marche pas pour les ints signés de Java, qui ne sont pas assez grands pour représenter la différence de deux ints signés. Si i est un grand entier positif et j un grand entier négatif, i-j débordera et renverra une valeur négative, ce qui n'est pas le résultat attendu.
XI-H-1. Ensemble trié : SortedSet▲
Si vous avez un SortedSet (dont TreeSet est l'unique représentant), les éléments sont garantis d'être en ordre trié, ce qui permet des fonctionnalités additionnelles aux méthodes de l'interface SortedSet :
Comparator comparator( ) : renvoie le Comparator utilisé pour ce Set, ou null pour l'ordre naturel.
Object first( ) : renvoie le plus petit élément.
Object last( ) : renvoie le plus grand élément.
SortedSet subSet(fromElement, toElement) : renvoie une vue de ce Set contenant les éléments de fromElement, inclus, à toElement, exclus.
SortedSet headSet(toElement) : renvoie une vue de ce Set contenant les éléments inférieurs à toElement.
SortedSet tailSet(fromElement) : renvoie une vue de ce Set contenant les éléments supérieurs ou égaux à fromElement.
Voici un exemple simple :
//: c11:SortedSetDemo.java
// Ce qui vous pouvez faire avec un TreeSet
import com.bruceeckel.simpletest.*;
import java.util.*;
public class SortedSetDemo {
private static Test monitor = new Test();
public static void main(String[] args) {
SortedSet sortedSet = new TreeSet(Arrays.asList(
"one two three four five six seven eight".split(" ")));
System.out.println(sortedSet);
Object
low = sortedSet.first(),
high = sortedSet.last();
System.out.println(low);
System.out.println(high);
Iterator it = sortedSet.iterator();
for(int i = 0; i <= 6; i++) {
if(i == 3) low = it.next();
if(i == 6) high = it.next();
else it.next();
}
System.out.println(low);
System.out.println(high);
System.out.println(sortedSet.subSet(low, high));
System.out.println(sortedSet.headSet(high));
System.out.println(sortedSet.tailSet(low));
monitor.expect(new String[] {
"[eight, five, four, one, seven, six, three, two]",
"eight",
"two",
"one",
"two",
"[one, seven, six, three]",
"[eight, five, four, one, seven, six, three]",
"[one, seven, six, three, two]"
});
}
} ///:~Notez que SortedSet signifie « trié selon une fonction de comparaison sur l'objet » , pas « insertion en ordre » .
XI-I. Fonctionnalités des Maps▲
Une ArrayList permet de sélectionner des éléments dans une séquence d'objets en utilisant un nombre, elle associe donc des nombres à des objets. Mais qu'en est-il si on souhaite sélectionner des éléments d'une séquence en utilisant un autre critère ? Une pile est un exemple. Son critère de sélection est « la dernière chose poussée sur la pile ». Une alternative particulièrement puissante de cette idée de « sélection à partir d'une séquence » est désignée par une map, un dictionnaire, ou un tableau associatif (vous en avez vu un exemple dans AssociativeArray.java au chapitre précédent). Conceptuellement, cela ressemble à une ArrayList, mais au lieu de rechercher un objet par un nombre, on le sélectionne en utilisant un autre objet! C'est une technique essentielle en programmation.
Le concept est illustré en Java via l'interface Map . La méthode put(Object key, Object value) ajoute une valeur (la chose que l'on veut stocker) et l'associe à une clé (la chose grâce à laquelle on va rechercher). La méthode get(Object key) renvoie la valeur associée à la clé correspondante. Il est aussi possible de tester une Map pour voir si elle contient une clé ou une valeur avec les méthodes containsKey( ) et containsValue( ).
La bibliothèque Java standard propose différents types de Maps: HashMap, TreeMap, LinkedHashMap, WeakHashMap, et IdentityHashMap. Toutes ont la même interface fondamentale Map , mais elles diffèrent dans les comportements pour l'efficacité, l'ordre dans lequel les paires sont gardées et présentées, combien de temps les objets sont contenus dans la « map », et comment l'égalité entre les clés est déterminée.
La performance est une question importante avec les maps. Si la recherche doit être faite pour un get( ), il est assez lent de chercher la clé dans une ArrayList par exemple. C'est là que la HashMap accélère les choses. Au lieu d'effectuer une recherche lente sur la clef, elle utilise une valeur spéciale appelée code de hachage. Le code de hachage est une façon d'extraire une partie de l'information de l'objet en question et de la convertir en un int « relativement unique » pour cet objet. Tous les objets Java peuvent produire un code de hachage, et hashCode( ) est une méthode de la classe racine Object. Une HashMap récupère le hashCode( ) de l'objet et l'utilise pour retrouver rapidement la clef. Le résultat en est une augmentation drastique des performances. (58)
|
Map (interface) |
Maintient des associations clef - valeur (des paires) afin de pouvoir accéder à une valeur en utilisant une clef. |
|
HashMap* |
Implémentation basée sur une table de hachage (utilisez ceci à la place d'une Hashtable). Fournit des performances en temps constant pour l'insertion et la recherche de paires. Les performances peuvent être ajustées via des constructeurs qui permettent de positionner la capacité et le facteur de charge de la table de hachage. |
|
LinkedHashMap |
Comme une HashMap, mais lors de son itération, vous récupérez les paires dans l'ordre d'insertion, ou dans l'ordre le moins récent d'utilisation. Seulement un peu plus lent qu'une HashMap, sauf pour l'itération, où cela est plus rapide grâce à la liste chaînée utilisée pour maintenir l'ordre initial. |
|
TreeMap |
Implémentation basée sur un arbre rouge-noir. L'extraction des clés ou des paires fournit une séquence triée (déterminée par Comparable ou Comparator, qui seront vus plus loin). Le point important dans une TreeMap est que l'on récupère les résultats dans l'ordre trié. TreeMap est la seule Map avec de la méthode subMap( ), qui permet de renvoyer une portion de l'arbre. |
|
WeakHashMap |
Une map de clés faibles qui permet aux objets référencés par la map d'être libérés ; conçue pour résoudre certains types de problèmes. S’il n'y a aucune référence en dehors de la map pour une clé particulière, il pourrait être nettoyé. |
|
IdentityHashMap |
Une table de hachage qui utilise == à la place de equals( ) pour comparer les clés. Seulement pour résoudre certains types de problèmes ; pas pour une utilisation générale. |
Le hachage est la façon la plus commune de stocker des éléments dans une map. Quelques fois vous avez besoin de connaître les détails de fonctionnement du hachage, nous le verrons un peu plus tard.
L'exemple suivant utilise la méthode Collections2.fill( ) et les ensembles de données définis précédemment :
//: c11:Map1.java
// Opérations disponibles pour les Maps.
import java.util.*;
import com.bruceeckel.util.*;
public class Map1 {
private static Collections2.StringPairGenerator geo =
Collections2.geography;
private static Collections2.RandStringPairGenerator
rsp = Collections2.rsp;
// Produire un Set de clefs :
public static void printKeys(Map map) {
System.out.print("Size = " + map.size() + ", ");
System.out.print("Keys: ");
System.out.println(map.keySet());
}
public static void test(Map map) {
// Enlève le qualificatif du nom de la classe :
System.out.println(
map.getClass().getName().replaceAll("\\w+\\.", ""));
Collections2.fill(map, geo, 25);
// Une Map a un comportement de « Set » pour les clefs
Collections2.fill(map, geo.reset(), 25);
printKeys(map);
// Produire une Collection de valeurs :
System.out.print("Values: ");
System.out.println(map.values());
System.out.println(map);
String key = CountryCapitals.pairs[4][0];
String value = CountryCapitals.pairs[4][1];
System.out.println("map.containsKey(\"" + key +
"\"): " + map.containsKey(key));
System.out.println("map.get(\"" + key + "\"): "
+ map.get(key));
System.out.println("map.containsValue(\""
+ value + "\"): " + map.containsValue(value));
Map map2 = new TreeMap();
Collections2.fill(map2, rsp, 25);
map.putAll(map2);
printKeys(map);
key = map.keySet().iterator().next().toString();
System.out.println("First key in map: " + key);
map.remove(key);
printKeys(map);
map.clear();
System.out.println("map.isEmpty(): " + map.isEmpty());
Collections2.fill(map, geo.reset(), 25);
// Les opérations sur le Set changent la Map :
map.keySet().removeAll(map.keySet());
System.out.println("map.isEmpty(): " + map.isEmpty());
}
public static void main(String[] args) {
test(new HashMap());
test(new TreeMap());
test(new LinkedHashMap());
test(new IdentityHashMap());
test(new WeakHashMap());
}
} ///:~Les méthodes printKeys( ) et printValues( )ne sont pas seulement des utilitaires pratiques, elles illustrent aussi comment produire une vue, sous forme de Collection, d'une Map. La méthode keySet( ) renvoie un Set rempli par les clés de la Map. Un traitement similaire est donné par values( ), qui retourne une Collection contenant toutes les valeurs de la Map (notez bien que les clefs doivent être uniques, alors que les valeurs peuvent contenir des doublons). Puisque ces Collections sont remplies avec la Map, tout changement dans une Collection sera donc répercuté dans la Map associée.
Le reste du programme fournit des exemples simples pour chacune des Map et teste chaque type de Map.
Comme exemple d'utilisation d'une HashMap, considérons un programme vérifiant la nature aléatoire de la classe Random. Idéalement, elle devrait produire une distribution parfaite de nombres aléatoires, mais pour tester cela il faut générer un ensemble de nombres aléatoires et compter ceux qui tombent dans les différentes plages. Une HashMap est parfaite pour ça, puisqu'elle associe des objets à des objets (dans ce cas, les objets valeurs contiennent le nombre produit par Math.random( ) ainsi que le nombre de fois où ce nombre apparaît):
//: c11:Statistics.java
// Simple démonstration de l'utilisation d'un HashMap.
import java.util.*;
class Counter {
int i = 1;
public String toString() { return Integer.toString(i); }
}
public class Statistics {
private static Random rand = new Random();
public static void main(String[] args) {
Map hm = new HashMap();
for(int i = 0; i < 10000; i++) {
// Produit un nombre entre 0 et 20 :
Integer r = new Integer(rand.nextInt(20));
if(hm.containsKey(r))
((Counter)hm.get(r)).i++;
else
hm.put(r, new Counter());
}
System.out.println(hm);
}
} ///:~Dans main( ), chaque fois qu'un nombre aléatoire est généré, il est encapsulé dans un objet Integer dont la référence sera utilisée par la HashMap. (on ne peut pas stocker un type primitif dans un conteneur -uniquement une référence sur un objet). La méthode containsKey( ) vérifie si la clef existe déjà dans le conteneur (c'est-à-dire, est-ce que le nombre a déjà été généré auparavant ?). Si c'est le cas, la méthode get( )renvoie la valeur associée à cette clé, qui est un objet Counter dans ce cas. La valeur i à l'intérieur du compteur est incrémentée pour indiquer qu'une occurrence de plus de ce nombre aléatoire particulier a été générée.
Si la clé n'a pas déjà été stockée, la méthode put( ) insèrera une nouvelle paire clef - valeur dans la HashMap. Puisque Counter initialise automatiquement sa variable i à 1 lorsqu'elle est créée, cela indique une première occurrence de ce nombre aléatoire particulier.
Pour afficher la HashMap, elle est simplement imprimée. La méthode toString( ) de HashMap parcourt toutes les paires clef - valeur et appelle toString( ) pour chacune. La méthode Integer.toString( ) est prédéfinie, et on peut voir la méthode toString( ) de Counter. La sortie du programme (après quelques sauts de ligne) est :
{15=529, 4=488, 19=518, 8=487, 11=501, 16=487, 18=507, 3=524, 7=474, 12=485, 17=493,
2=490, 13=540, 9=453, 6=512, 1=466, 14=522, 10=471, 5=522, 0=531}On peut s'interroger sur la nécessité d'une classe Counter, qui ne semble même pas avoir les fonctionnalités de la classe d'encapsulation Integer. Pourquoi ne pas utiliser un int ou un Integer ? On ne peut utiliser un int puisque les conteneurs ne peuvent stocker que des références d'Objects. On pourrait alors être tenté de se tourner vers les classes Java d'encapsulation des types primitifs. Cependant, ces classes d'encapsulation ne peuvent que stocker une valeur initiale et lire cette valeur. C'est-à-dire qu'il n'existe aucun moyen de changer cette valeur une fois qu'un objet d'encapsulation a été créé. Cela rend la classe englobante Integer inutile pour résoudre notre problème, et nous force à créer une nouvelle classe qui satisfait l'ensemble de nos besoins.
XI-I-1. SortedMap▲
Une SortedMap (dont TreeMap est l'unique représentant), garantit aux clés d'être en ordre trié, ce qui permet de proposer de nouvelles fonctionnalités grâce aux méthodes de l'interface SortedMap suivantes :
Comparator comparator( ) : Renvoie le comparateur utilisé pour cette Map, ou null pour l'ordre naturel.
Object firstKey( ) : Renvoie la plus petite clé.
Object lastKey( ) : Renvoie la plus grande clé.
SortedMap subMap(fromKey, toKey) : Renvoie une vue de cette Map avec les clés de fromKey, inclus, à toKey, exclus.
SortedMap headMap(toKey) : Renvoie une vue de la Map avec les clés inférieures à toKey.
SortedMap tailMap(fromKey) : Renvoie une vue de la Map avec les clés supérieures ou égales à fromKey.
Ci-dessous un exemple similaire à SortedSetDemo.java qui montre les fonctionnalités supplémentaires des TreeMaps :
//: c11:SimplePairGenerator.java
import com.bruceeckel.util.*;
//import java.util.*;
public class SimplePairGenerator implements MapGenerator {
public Pair[] items = {
new Pair("one", "A"), new Pair("two", "B"),
new Pair("three", "C"), new Pair("four", "D"),
new Pair("five", "E"), new Pair("six", "F"),
new Pair("seven", "G"), new Pair("eight", "H"),
new Pair("nine", "I"), new Pair("ten", "J")
};
private int index = -1;
public Pair next() {
index = (index + 1) % items.length;
return items[index];
}
public static SimplePairGenerator gen =
new SimplePairGenerator();
} ///:~//: c11:SortedMapDemo.java
// Ce que vous pouvez faire avec une TreeMap.
import com.bruceeckel.simpletest.*;
import com.bruceeckel.util.*;
import java.util.*;
public class SortedMapDemo {
private static Test monitor = new Test();
public static void main(String[] args) {
TreeMap sortedMap = new TreeMap();
Collections2.fill(
sortedMap, SimplePairGenerator.gen, 10);
System.out.println(sortedMap);
Object
low = sortedMap.firstKey(),
high = sortedMap.lastKey();
System.out.println(low);
System.out.println(high);
Iterator it = sortedMap.keySet().iterator();
for(int i = 0; i <= 6; i++) {
if(i == 3) low = it.next();
if(i == 6) high = it.next();
else it.next();
}
System.out.println(low);
System.out.println(high);
System.out.println(sortedMap.subMap(low, high));
System.out.println(sortedMap.headMap(high));
System.out.println(sortedMap.tailMap(low));
monitor.expect(new String[] {
"{eight=H, five=E, four=D, nine=I, one=A, seven=G," +
" six=F, ten=J, three=C, two=B}",
"eight",
"two",
"nine",
"ten",
"{nine=I, one=A, seven=G, six=F}",
"{eight=H, five=E, four=D, nine=I, " +
"one=A, seven=G, six=F}",
"{nine=I, one=A, seven=G, six=F, " +
"ten=J, three=C, two=B}"
});
}
} ///:~Ici, les paires sont stockées triées par un ordre sur les clés. Puisque l'ordre a un sens pour une TreeMap, le concept de « localisation » a un sens, vous pouvez donc avoir un premier et un dernier élément ainsi que des « sous-maps ».
XI-I-2. LinkedHashMap▲
La classe LinkedHashMap hache tout pour la rapidité, mais renvoie aussi les paires dans l'ordre d'insertion pendant son parcours. (La répétition des println( ) pour la map, permet de voir les résultats du parcours). De plus, une LinkedHashMap peut être configurée dans le constructeur pour utiliser un algorithme least-recently-used (LRU) (NDT : moins-récent-utilisé) basé sur les accès, ainsi des éléments qui n'ont pas été accédés (et qui sont donc candidat pour la suppression) apparaissent au début de la liste. Cela permet la création de programmes qui effectuent des nettoyages périodiques basés sur l'ordre pour libérer de l'espace. Voici un exemple simple montrant les fonctionnalités :
//: c11:LinkedHashMapDemo.java
// Ce que vous pouvez faire avec une LinkedHashMap.
import com.bruceeckel.simpletest.*;
import com.bruceeckel.util.*;
import java.util.*;
public class LinkedHashMapDemo {
private static Test monitor = new Test();
public static void main(String[] args) {
LinkedHashMap linkedMap = new LinkedHashMap();
Collections2.fill(
linkedMap, SimplePairGenerator.gen, 10);
System.out.println(linkedMap);
// Ordre le moins récent d'utilisation
linkedMap = new LinkedHashMap(16, 0.75f, true);
Collections2.fill(
linkedMap, SimplePairGenerator.gen, 10);
System.out.println(linkedMap);
for(int i = 0; i < 7; i++) // accès
linkedMap.get(SimplePairGenerator.gen.items[i].key);
System.out.println(linkedMap);
linkedMap.get(SimplePairGenerator.gen.items[0].key);
System.out.println(linkedMap);
monitor.expect(new String[] {
"{one=À, two=B, three=C, four=D, five=E, " +
"six=F, seven=G, eight=H, nine=I, ten=J}",
"{one=A, two=B, three=C, four=D, five=E, " +
"six=F, seven=G, eight=H, nine=I, ten=J}",
"{eight=H, nine=I, ten=J, one=A, two=B, " +
"three=C, four=D, five=E, six=F, seven=G}",
"{eight=H, nine=I, ten=J, two=B, three=C, " +
"four=D, five=E, six=F, seven=G, one=A}"
});
}
} ///:~Vous pouvez voir sur la sortie que les paires sont en effet parcourues dans l'ordre d'insertion, même pour la version LRU (moins-récent-utilisé). Cependant, après les sept premiers éléments (seulement) accédés, les trois derniers éléments sont déplacés au début de la liste. Ensuite, quand « un » élément est de nouveau accédé, il est déplacé en fond de liste.
XI-I-3. Hashing and hash codes▲
In Statistics.java, a standard library class (Integer) was used as a key for the HashMap. It worked because it has all the necessary wiring to make it behave correctly as a key. But a common pitfall occurs with HashMaps when you create your own classes to be used as keys. For example, consider a weather predicting system that matches Groundhog objects to Prediction objects. It seems fairly straightforward-you create the two classes, and use Groundhog as the key and Prediction as the value:
//: c11:Groundhog.java
// Looks plausible, but doesn't work as a HashMap key.
public class Groundhog {
protected int number;
public Groundhog(int n) { number = n; }
public String toString() {
return "Groundhog #" + number;
}
} ///:~//: c11:Prediction.java
// Predicting the weather with groundhogs.
public class Prediction {
private boolean shadow = Math.random() > 0.5;
public String toString() {
if(shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
} ///:~//: c11:SpringDetector.java
// What will the weather be?
import com.bruceeckel.simpletest.*;
import java.util.*;
import java.lang.reflect.*;
public class SpringDetector {
private static Test monitor = new Test();
// Uses a Groundhog or class derived from Groundhog:
public static void
detectSpring(Class groundHogClass) throws Exception {
Constructor ghog = groundHogClass.getConstructor(
new Class[] {int.class});
Map map = new HashMap();
for(int i = 0; i < 10; i++)
map.put(ghog.newInstance(
new Object[]{ new Integer(i) }), new Prediction());
System.out.println("map = " + map + "\n");
Groundhog gh = (Groundhog)
ghog.newInstance(new Object[]{ new Integer(3) });
System.out.println("Looking up prediction for " + gh);
if(map.containsKey(gh))
System.out.println((Prediction)map.get(gh));
else
System.out.println("Key not found: " + gh);
}
public static void main(String[] args) throws Exception {
detectSpring(Groundhog.class);
monitor.expect(new String[] {
"%% map = \\{(Groundhog #\\d=" +
"(Early Spring!|Six more weeks of Winter!)" +
"(, )?){10}\\}",
"",
"Looking up prediction for Groundhog #3",
"Key not found: Groundhog #3"
});
}
} ///:~Each Groundhog is given an identity number, so you can look up a Prediction in the HashMap by saying, « Give me the Prediction associated with Groundhog #3. » The Prediction class contains a boolean that is initialized using Math.random( ) and a toString( ) that interprets the result for you. The detectSpring( ) method is created using reflection to instantiate and use the Class Groundhog or any derived class. This will come in handy when we inherit a new type of Groundhog to solve the problem demonstrated here. A HashMap is filled with Groundhogs and their associated Predictions. The HashMap is printed so that you can see it has been filled. Then a Groundhog with an identity number of 3 is used as a key to look up the prediction for Groundhog #3 (which you can see must be in the Map).
It seems simple enough, but it doesn't work. The problem is that Groundhog is inherited from the common root class Object (which is what happens if you don't specify a base class, thus all classes are ultimately inherited from Object). It is Object's hashCode( ) method that is used to generate the hash code for each object, and by default it just uses the address of its object. Thus, the first instance of Groundhog(3) does not produce a hash code equal to the hash code for the second instance of Groundhog(3) that we tried to use as a lookup.
You might think that all you need to do is write an appropriate override for hashCode( ). But it still won't work until you've done one more thing: override the equals( ) that is also part of Object. equals( ) is used by the HashMap when trying to determine if your key is equal to any of the keys in the table.
A proper equals( ) must satisfy the following five conditions:
- Reflexive: For any x, x.equals(x) should return true.
- Symmetric: For any x and y, x.equals(y) should return true if and only if y.equals(x) returns true.
- Transitive: For any x, y, and z, if x.equals(y) returns true and y.equals(z) returns true, then x.equals(z) should return true.
- Consistent: For any x and y, multiple invocations of x.equals(y) consistently return true or consistently return false, provided no information used in equals comparisons on the object is modified.
- For any non-null x, x.equals(null) should return false.
Again, the default Object.equals( ) simply compares object addresses, so one Groundhog(3) is not equal to another Groundhog(3). Thus, to use your own classes as keys in a HashMap, you must override both hashCode( ) and equals( ), as shown in the following solution to the groundhog problem:
//: c11:Groundhog2.java
// A class that's used as a key in a HashMap
// must override hashCode() and equals().
public class Groundhog2 extends Groundhog {
public Groundhog2(int n) { super(n); }
public int hashCode() { return number; }
public boolean equals(Object o) {
return (o instanceof Groundhog2)
&& (number == ((Groundhog2)o).number);
}
} ///:~//: c11:SpringDetector2.java
// A working key.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class SpringDetector2 {
private static Test monitor = new Test();
public static void main(String[] args) throws Exception {
SpringDetector.detectSpring(Groundhog2.class);
monitor.expect(new String[] {
"%% map = \\{(Groundhog #\\d=" +
"(Early Spring!|Six more weeks of Winter!)" +
"(, )?){10}\\}",
"",
"Looking up prediction for Groundhog #3",
"%% Early Spring!|Six more weeks of Winter!"
});
}
} ///:~Groundhog2.hashCode( ) returns the groundhog number as a hash value. In this example, the programmer is responsible for ensuring that no two groundhogs exist with the same ID number. The hashCode( ) is not required to return a unique identifier (something you'll understand better later in this chapter), but the equals( ) method must be able to strictly determine whether two objects are equivalent. Here, equals( ) is based on the groundhog number, so if two Groundhog2 objects exist as keys in the HashMap with the same groundhog number, it will fail.
Even though it appears that the equals( ) method is only checking to see whether the argument is an instance of Groundhog2 (using the instanceof keyword, which was explained in Chapter 10), the instanceof actually quietly does a second sanity check to see if the object is null, since instanceof produces false if the left-hand argument is null. Assuming it's the correct type and not null, the comparison is based on the actual ghNumbers. You can see from the output that the behavior is now correct.
When creating your own class to use in a HashSet, you must pay attention to the same issues as when it is used as a key in a HashMap.
XI-I-3-a. Understanding hashCode( )▲
The preceding example is only a start toward solving the problem correctly. It shows that if you do not override hashCode( ) and equals( ) for your key, the hashed data structure (HashSet, HashMap, LinkedHashSet, or LinkedHashMap) will not be able to deal with your key properly. However, to get a good solution for the problem you need to understand what's going on inside the hashed data structure.
First, consider the motivation behind hashing: you want to look up an object using another object. But you can accomplish this with a TreeSet or TreeMap, too. It's also possible to implement your own Map. To do so, the Map.entrySet( ) method must be supplied to produce a set of Map.Entry objects. MPair will be defined as the new type of Map.Entry. In order for it to be placed in a TreeSet, it must implement equals( ) and be Comparable:
//: c11:MPair.java
// A new type of Map.Entry.
import java.util.*;
public class MPair implements Map.Entry, Comparable {
private Object key, value;
public MPair(Object k, Object v) {
key = k;
value = v;
}
public Object getKey() { return key; }
public Object getValue() { return value; }
public Object setValue(Object v) {
Object result = value;
value = v;
return result;
}
public boolean equals(Object o) {
return key.equals(((MPair)o).key);
}
public int compareTo(Object rv) {
return ((Comparable)key).compareTo(((MPair)rv).key);
}
} ///:~Notice that the comparisons are only interested in the keys, so duplicate values are perfectly acceptable.
The following example implements a Map using a pair of ArrayLists:
//: c11:SlowMap.java
// A Map implemented with ArrayLists.
import com.bruceeckel.simpletest.*;
import java.util.*;
import com.bruceeckel.util.*;
public class SlowMap extends AbstractMap {
private static Test monitor = new Test();
private List
keys = new ArrayList(),
values = new ArrayList();
public Object put(Object key, Object value) {
Object result = get(key);
if(!keys.contains(key)) {
keys.add(key);
values.add(value);
} else
values.set(keys.indexOf(key), value);
return result;
}
public Object get(Object key) {
if(!keys.contains(key))
return null;
return values.get(keys.indexOf(key));
}
public Set entrySet() {
Set entries = new HashSet();
Iterator
ki = keys.iterator(),
vi = values.iterator();
while(ki.hasNext())
entries.add(new MPair(ki.next(), vi.next()));
return entries;
}
public String toString() {
StringBuffer s = new StringBuffer("{");
Iterator
ki = keys.iterator(),
vi = values.iterator();
while(ki.hasNext()) {
s.append(ki.next() + "=" + vi.next());
if(ki.hasNext()) s.append(", ");
}
s.append("}");
return s.toString();
}
public static void main(String[] args) {
SlowMap m = new SlowMap();
Collections2.fill(m, Collections2.geography, 15);
System.out.println(m);
monitor.expect(new String[] {
"{ALGERIA=Algiers, ANGOLA=Luanda, BENIN=Porto-Novo,"+
" BOTSWANA=Gaberone, BURKINA FASO=Ouagadougou, " +
"BURUNDI=Bujumbura, CAMEROON=Yaounde, " +
"CAPE VERDE=Praia, CENTRAL AFRICAN REPUBLIC=Bangui,"+
" CHAD=N'djamena, COMOROS=Moroni, " +
"CONGO=Brazzaville, DJIBOUTI=Dijibouti, " +
"EGYPT=Cairo, EQUATORIAL GUINEA=Malabo}"
});
}
} ///:~The put( ) method simply places the keys and values in corresponding ArrayLists. In main( ), a SlowMap is loaded and then printed to show that it works.
This shows that it's not that hard to produce a new type of Map. But as the name suggests, a SlowMap isn't very fast, so you probably wouldn't use it if you had an alternative available. The problem is in the lookup of the key; there is no order, so a simple linear search is used, which is the slowest way to look something up.
The whole point of hashing is speed: Hashing allows the lookup to happen quickly. Since the bottleneck is in the speed of the key lookup, one of the solutions to the problem could be to keep the keys sorted and then use Collections.binarySearch( ) to perform the lookup (an exercise at the end of this chapter will walk you through this process).
Hashing goes further by saying that all you want to do is to store the key somewhere so that it can be quickly found. As you've seen in this chapter, the fastest structure in which to store a group of elements is an array, so that will be used for representing the key information (note carefully that I said « key information, » and not the key itself). Also seen in this chapter was the fact that an array, once allocated, cannot be resized, so we have a problem: We want to be able to store any number of values in the Map, but if the number of keys is fixed by the array size, how can this be?
The answer is that the array will not hold the keys. From the key object, a number will be derived that will index into the array. This number is the hash code, produced by the hashCode( ) method (in computer science parlance, this is the hash function) defined in Object and presumably overridden by your class. To solve the problem of the fixed-size array, more than one key may produce the same index. That is, there may be collisions. Because of this, it doesn't matter how big the array is; each key object will land somewhere in that array.
So the process of looking up a value starts by computing the hash code and using it to index into the array. If you could guarantee that there were no collisions (which could be possible if you have a fixed number of values) then you'd have a perfect hashing function, but that's a special case. In all other cases, collisions are handled by external chaining: The array points not directly to a value, but instead to a list of values. These values are searched in a linear fashion using the equals( ) method. Of course, this aspect of the search is much slower, but if the hash function is good, there will only be a few values in each slot. So instead of searching through the entire list, you quickly jump to a slot where you have to compare a few entries to find the value. This is much faster, which is why the HashMap is so quick.
Knowing the basics of hashing, it's possible to implement a simple hashed Map:
//: c11:SimpleHashMap.java
// A demonstration hashed Map.
import java.util.*;
import com.bruceeckel.util.*;
public class SimpleHashMap extends AbstractMap {
// Choose a prime number for the hash table
// size, to achieve a uniform distribution:
private static final int SZ = 997;
private LinkedList[] bucket = new LinkedList[SZ];
public Object put(Object key, Object value) {
Object result = null;
int index = key.hashCode() % SZ;
if(index < 0) index = -index;
if(bucket[index] == null)
bucket[index] = new LinkedList();
LinkedList pairs = bucket[index];
MPair pair = new MPair(key, value);
ListIterator it = pairs.listIterator();
boolean found = false;
while(it.hasNext()) {
Object iPair = it.next();
if(iPair.equals(pair)) {
result = ((MPair)iPair).getValue();
it.set(pair); // Replace old with new
found = true;
break;
}
}
if(!found)
bucket[index].add(pair);
return result;
}
public Object get(Object key) {
int index = key.hashCode() % SZ;
if(index < 0) index = -index;
if(bucket[index] == null) return null;
LinkedList pairs = bucket[index];
MPair match = new MPair(key, null);
ListIterator it = pairs.listIterator();
while(it.hasNext()) {
Object iPair = it.next();
if(iPair.equals(match))
return ((MPair)iPair).getValue();
}
return null;
}
public Set entrySet() {
Set entries = new HashSet();
for(int i = 0; i < bucket.length; i++) {
if(bucket[i] == null) continue;
Iterator it = bucket[i].iterator();
while(it.hasNext())
entries.add(it.next());
}
return entries;
}
public static void main(String[] args) {
SimpleHashMap m = new SimpleHashMap();
Collections2.fill(m, Collections2.geography, 25);
System.out.println(m);
}
} ///:~Because the « slots » in a hash table are often referred to as buckets, the array that represents the actual table is called bucket. To promote even distribution, the number of buckets is typically a prime number. (59) Notice that it is an array of LinkedList, which automatically provides for collisions; each new item is simply added to the end of the list.
The return value of put( ) is null or, if the key was already in the list, the old value associated with that key. The return value is result, which is initialized to null, but if a key is discovered in the list, then result is assigned to that key.
For both put( ) and get( ), the first thing that happens is that the hashCode( ) is called for the key, and the result is forced to a positive number. Then it is forced to fit into the bucket array using the modulus operator and the size of the array. If that location is null, it means there are no elements that hash to that location, so a new LinkedList is created to hold the object that just did. However, the normal process is to look through the list to see if there are duplicates, and if there are, the old value is put into result and the new value replaces the old. The found flag keeps track of whether an old key-value pair was found and, if not, the new pair is appended to the end of the list.
In get( ), you'll see very similar code as that contained in put( ), but simpler. The index is calculated into the bucket array, and if a LinkedList exists, it is searched for a match.
entrySet( ) must find and traverse all the lists, adding them to the result Set. Once this method has been created, the Map can be tested by filling it with values and then printing them.
XI-I-3-b. HashMap performance factors▲
To understand the issues, some terminology is necessary:
Capacity: The number of buckets in the table.
Initial capacity: The number of buckets when the table is created. HashMap and HashSet have constructors that allow you to specify the initial capacity.
Size: The number of entries currently in the table.
Load factor: size/capacity. À load factor of 0 is an empty table, 0.5 is a half-full table, etc. A lightly loaded table will have few collisions and so is optimal for insertions and lookups (but will slow down the process of traversing with an iterator). HashMap and HashSet have constructors that allow you to specify the load factor, which means that when this load factor is reached, the container will automatically increase the capacity (the number of buckets) by roughly doubling it and will redistribute the existing objects into the new set of buckets (this is called rehashing).
The default load factor used by HashMap is 0.75 (it doesn't rehash until the table is ¾ full). This seems to be a good trade-off between time and space costs. A higher load factor decreases the space required by the table but increases the lookup cost, which is important because lookup is what you do most of the time (including both get( ) and put( )).
If you know that you'll be storing many entries in a HashMap, creating it with an appropriately large initial capacity will prevent the overhead of automatic rehashing. (60)
XI-I-4. Surcharger hashCode( )▲
Maintenant que vous comprenez ce qui entre en compte dans le fonctionnement d'une HashMap, les problèmes qui surviennent lors de l'écriture d'une méthode hashCode( ) prendront plus de sens.
Premièrement, vous n'avez pas le contrôle de la création de la valeur réelle utilisée pour indexer le tableau de buckets. Celle-ci est dépendante de la capacité de l'objet HashMap, et cette capacité change suivant le taux de remplissage et le facteur de charge du conteneur. La valeur renvoyée par votre méthode hashCode( ) sera par la suite utilisée pour calculer l'index de bucket (dans SimpleHashMap, le calcul se résume à un modulo par la taille du tableau de buckets).
Le facteur le plus important lors de la création d'une méthode hashCode( ) est qu'elle doit toujours renvoyer la même valeur pour un objet particulier, quel que soit le moment où hashCode( ) est appelée. Si l'on a un objet dont le hashCode( ) renvoie une valeur lors d'un put( ) dans une HashMap et une autre valeur lors d'un get( ), on sera incapable de retrouver les objets. Aussi, si la méthode hashCode( ) s'appuie sur des données modifiables dans l'objet, l'utilisateur doit alors avoir conscience que changer ces données produira une clé différente en générant un hashCode( ) différent.
De plus, vous ne voudrez probablement pas générer un hashCode( ) qui soit basé uniquement sur des informations spécifiques à l'instance de l'objet, la valeur de this fait en particulier un mauvais hashCode( ) parce que vous ne pourrez pas générer une nouvelle clé identique à celle utilisée dans le put( ) de la paire originale clé-valeur. C'était le problème rencontré dans SpringDetector.java, parce que l'implémentation par défaut de hashCode( ) utilise l'adresse de l'objet. Aussi, vous voudrez utiliser des informations de l'objet qui identifient l'objet d'une façon significative.
Un exemple peut être vu dans la classe String. Les Strings ont cette caractéristique spéciale : si un programme utilise plusieurs objets Stringcontenant des séquences de caractères identiques, alors ces objets Stringpointent tous vers la même zone de mémoire (ce mécanisme est décrit dans l'annexe A). Il est donc sensé que le hashCode( ) produit par deux instances distinctes de new String(« hello ») soit identique. Vous pouvez le vérifier avec le programme suivant :
//: c11:StringHashCode.java
import com.bruceeckel.simpletest.*;
public class StringHashCode {
private static Test monitor = new Test();
public static void main(String[] args) {
System.out.println("Hello".hashCode());
System.out.println("Hello".hashCode());
monitor.expect(new String[] {
"69609650",
"69609650"
});
}
} ///:~Le hashCode( ) d'un String est clairement basé sur le contenu du String.
Aussi, pour qu'un hashCode( ) soit efficace, il faut qu'il soit rapide et chargé de sens ; ce qui veut dire qu'il doit générer une valeur basée sur le contenu de l'objet. Rappelons que cette valeur n'a pas à être unique - mieux vaut se pencher sur la vitesse que sur l'unicité -, mais l'identité d'un objet doit être complètement résolue entre hashCode( ) et equals( ).
Parce que hashCode( ) est retraité avant de produire un index pour les buckets, la plage de valeurs n'est pas importante ; il a juste besoin de générer un int.
Il y a un autre facteur : une méthode hashCode( ) bien conçue doit renvoyer des valeurs bien distribuées. Si les valeurs tendent à se regrouper, alors les HashMaps ou HashSets seront plus chargés dans certaines zones et donc moins rapides que ce qu'ils pourraient être avec une fonction de hachage mieux répartie.
Dans Effective Java (Addison-Wesley 2001), Joshua Bloch donne une recette basique pour générer une méthode hashCode( ) décente :
- Stocker une constante non nulle, disons 17, dans une variable int appelée result.
- Pour chaque champ f significatif dans votre objet (c'est-à-dire chaque champ pris en compte par la méthode equals( )), calculer un code de hachage entier c pour ce champ :
|
Type de champ |
Calcul |
|---|---|
|
boolean |
c = (f ? 0 : 1) |
|
byte, char, short, ou int |
c = (int)f |
|
long |
c = (int)(f ^ (f >>>32)) |
|
float |
c = Float.floatToIntBits(f); |
|
double |
long l = Double.doubleToLongBits(f); |
|
Object, où equals( ) appelle equals( ) pour ce champ |
c = f.hashCode( ) |
|
Tableau |
Appliquer les règles précédentes pour chaque élément |
- Combiner les codes de hachage calculé ci-dessus :
result = 37 * result + c; - Renvoyer result.
- Regardez le résultat de hashCode( ) et assurez-vous que des instances égales ont des codes de hachage égaux.
Voici un exemple qui suit ces conseils :
//: c11:CountedString.java
// Créer une bonne méthode hashCode().
import com.bruceeckel.simpletest.*;
import java.util.*;
public class CountedString {
private static Test monitor = new Test();
private static List created = new ArrayList();
private String s;
private int id = 0;
public CountedString(String str) {
s = str;
created.add(s);
Iterator it = created.iterator();
// id est le nombre total d'instances de cette
// chaîne utilisée par CountedString :
while(it.hasNext())
if(it.next().equals(s))
id++;
}
public String toString() {
return "String: " + s + " id: " + id +
" hashCode(): " + hashCode();
}
public int hashCode() {
// Approche très simple
// renvoyer s.hashCode() * id;
// en utilisant la recette de Joshua Bloch
int result = 17;
result = 37*result + s.hashCode();
result = 37*result + id;
return result;
}
public boolean equals(Object o) {
return (o instanceof CountedString)
&& s.equals(((CountedString)o).s)
&& id == ((CountedString)o).id;
}
public static void main(String[] args) {
Map map = new HashMap();
CountedString[] cs = new CountedString[10];
for(int i = 0; i < cs.length; i++) {
cs[i] = new CountedString("hi");
map.put(cs[i], new Integer(i));
}
System.out.println(map);
for(int i = 0; i < cs.length; i++) {
System.out.println("Looking up " + cs[i]);
System.out.println(map.get(cs[i]));
}
monitor.expect(new String[] {
"{String: hi id: 4 hashCode(): 146450=3," +
" String: hi id: 10 hashCode(): 146456=9," +
" String: hi id: 6 hashCode(): 146452=5," +
" String: hi id: 1 hashCode(): 146447=0," +
" String: hi id: 9 hashCode(): 146455=8," +
" String: hi id: 8 hashCode(): 146454=7," +
" String: hi id: 3 hashCode(): 146449=2," +
" String: hi id: 5 hashCode(): 146451=4," +
" String: hi id: 7 hashCode(): 146453=6," +
" String: hi id: 2 hashCode(): 146448=1}",
"Looking up String: hi id: 1 hashCode(): 146447",
"0",
"Looking up String: hi id: 2 hashCode(): 146448",
"1",
"Looking up String: hi id: 3 hashCode(): 146449",
"2",
"Looking up String: hi id: 4 hashCode(): 146450",
"3",
"Looking up String: hi id: 5 hashCode(): 146451",
"4",
"Looking up String: hi id: 6 hashCode(): 146452",
"5",
"Looking up String: hi id: 7 hashCode(): 146453",
"6",
"Looking up String: hi id: 8 hashCode(): 146454",
"7",
"Looking up String: hi id: 9 hashCode(): 146455",
"8",
"Looking up String: hi id: 10 hashCode(): 146456",
"9"
});
}
} ///:~CountedString inclut une String et un id qui représente le nombre d'objets CountedString qui contiennent une String identique. Le compte est réalisé dans le constructeur en itérant sur la static ArrayListoù tous les Strings sont stockés.
Les méthodes hashCode( ) et equals( ) renvoient toutes deux des résultats basés sur les deux champs ; si elles étaient basées seulement sur la String ou seulement sur l'id, il y aurait eu des doublons pour des valeurs distinctes.
Dans main( ), un ensemble d'objets CountedString est créé, en utilisant la même String pour montrer que les doublons créent des valeurs uniques grâce au compteur id. La HashMap est affichée afin de voir son organisation interne (aucun ordre n'est discernable) ; chaque clé est ensuite recherchée individuellement pour démontrer que le mécanisme de recherche fonctionne correctement.
Écrire des méthodes hashCode( ) et equals( ) convenables pour une nouvelle classe peut être difficile. Vous pouvez trouver des outils pour vous aider à le faire dans le projet « Jakarta Commons » d'Apache à jakarta.apache.org/commons, sous « lang » (ce projet a aussi beaucoup d'autres bibliothèques potentiellement utiles, et apparaît comme être la réponse de la communauté Java à la communauté C++ www.boost.org).
XI-J. Holding references▲
The java.lang.ref library contains a set of classes that allow greater flexibility in garbage collection. These classes are especially useful when you have large objects that may cause memory exhaustion. There are three classes inherited from the abstract class Reference: SoftReference,WeakReference, andPhantomReference. Each of these provides a different level of indirection for the garbage collector if the object in question is only reachable through one of these Reference objects.
If an object is reachable, it means that somewhere in your program the object can be found. This could mean that you have an ordinary reference on the stack that goes right to the object, but you might also have a reference to an object that has a reference to the object in question; there could be many intermediate links. If an object is reachable, the garbage collector cannot release it because it's still in use by your program. If an object isn't reachable, there's no way for your program to use it, so it's safe to garbage collect that object.
You use Reference objects when you want to continue to hold onto a reference to that object; you want to be able to reach that object, but you also want to allow the garbage collector to release that object. Thus, you have a way to go on using the object, but if memory exhaustion is imminent, you allow that object to be released.
You accomplish this by using a Reference object as an intermediary between you and the ordinary reference, and there must be no ordinary references to the object (ones that are not wrapped inside Reference objects). If the garbage collector discovers that an object is reachable through an ordinary reference, it will not release that object.
In the order of SoftReference, WeakReference, and PhantomReference, each one is « weaker » than the last and corresponds to a different level of reachability. Soft references are for implementing memory-sensitive caches. Weak references are for implementing « canonicalizing mappings »-where instances of objects can be simultaneously used in multiple places in a program, to save storage-that do not prevent their keys (or values) from being reclaimed. Phantom references are for scheduling premortem cleanup actions in a more flexible way than is possible with the Java finalization mechanism.
With SoftReferences and WeakReferences, you have a choice about whether to place them on a ReferenceQueue (the device used for premortem cleanup actions), but a PhantomReference can only be built on a ReferenceQueue. Here's a simple demonstration:
//: c11:References.java
// Demonstrates Reference objects
import java.lang.ref.*;
class VeryBig {
private static final int SZ = 10000;
private double[] d = new double[SZ];
private String ident;
public VeryBig(String id) { ident = id; }
public String toString() { return ident; }
public void finalize() {
System.out.println("Finalizing " + ident);
}
}
public class References {
private static ReferenceQueue rq = new ReferenceQueue();
public static void checkQueue() {
Object inq = rq.poll();
if(inq != null)
System.out.println("In queue: " +
(VeryBig)((Reference)inq).get());
}
public static void main(String[] args) {
int size = 10;
// Or, choose size via the command line:
if(args.length > 0)
size = Integer.parseInt(args[0]);
SoftReference[] sa = new SoftReference[size];
for(int i = 0; i < sa.length; i++) {
sa[i] = new SoftReference(
new VeryBig("Soft " + i), rq);
System.out.println("Just created: " +
(VeryBig)sa[i].get());
checkQueue();
}
WeakReference[] wa = new WeakReference[size];
for(int i = 0; i < wa.length; i++) {
wa[i] = new WeakReference(
new VeryBig("Weak " + i), rq);
System.out.println("Just created: " +
(VeryBig)wa[i].get());
checkQueue();
}
SoftReference s =
new SoftReference(new VeryBig("Soft"));
WeakReference w =
new WeakReference(new VeryBig("Weak"));
System.gc();
PhantomReference[] pa = new PhantomReference[size];
for(int i = 0; i < pa.length; i++) {
pa[i] = new PhantomReference(
new VeryBig("Phantom " + i), rq);
System.out.println("Just created: " +
(VeryBig)pa[i].get());
checkQueue();
}
}
} ///:~When you run this program (you'll want to pipe the output through a « more » utility so that you can view the output in pages), you'll see that the objects are garbage collected, even though you still have access to them through the Reference object (to get the actual object reference, you use get( )). You'll also see that the ReferenceQueue always produces a Reference containing a null object. To make use of this, you can inherit from the particular Reference class you're interested in and add more useful methods to the new type of Reference.
XI-J-1. La WeakHashMap▲
La bibliothèque de conteneurs contient une Map spéciale pour stocker les références faibles : la WeakHashMap. Cette classe est conçue pour faciliter la création de mappages canoniques. Dans de tels mappages, vous économisez sur l'espace de stockage en ne créant qu'une instance d'une valeur particulière. Quand le programme a besoin de cette valeur, il recherche l'objet existant dans le mappage et l'utilise (plutôt que d'en créer de zéro). Le mappage peut créer les valeurs comme partie de son initialisation, mais il est plus courant que les valeurs soient créées à la demande.
Puisqu'il s'agit d'une technique permettant d'économiser sur le stockage, il est très pratique que la WeakHashMap autorise le ramasse-miettes à nettoyer automatiquement les clefs et les valeurs. Aucune opération particulière n'est nécessaire sur les clés et les valeurs que l'on veut placer dans le WeakHashMap ; ils sont automatiquement encapsulés dans des WeakReferences par la map. Le déclenchement permettant le nettoyage survient lorsque la clef n'est plus utilisée, comme démontré ici :
//: c11:CanonicalMapping.java
// Illustre le WeakHashMap.
import java.util.*;
import java.lang.ref.*;
class Key {
private String ident;
public Key(String id) { ident = id; }
public String toString() { return ident; }
public int hashCode() { return ident.hashCode(); }
public boolean equals(Object r) {
return (r instanceof Key)
&& ident.equals(((Key)r).ident);
}
public void finalize() {
System.out.println("Finalizing Key "+ ident);
}
}
class Value {
private String ident;
public Value(String id) { ident = id; }
public String toString() { return ident; }
public void finalize() {
System.out.println("Finalizing Value " + ident);
}
}
public class CanonicalMapping {
public static void main(String[] args) {
int size = 1000;
// Ou choisir la taille via la ligne de commande :
if(args.length > 0)
size = Integer.parseInt(args[0]);
Key[] keys = new Key[size];
WeakHashMap map = new WeakHashMap();
for(int i = 0; i < size; i++) {
Key k = new Key(Integer.toString(i));
Value v = new Value(Integer.toString(i));
if(i % 3 == 0)
keys[i] = k; // Sauve comme des references « réelles »
map.put(k, v);
}
System.gc();
}
} ///:~La classe Key doit fournir les méthodes hashCode( ) et equals( ) puisqu'elle est utilisée comme clef dans une structure de données hachée, comme décrit précédemment dans ce chapitre.
Quand on lance le programme, on s'aperçoit que le ramasse miettes évite une clé sur trois, parce qu'une référence ordinaire sur cette clef a aussi été placée dans le tableau keys et donc ces objets ne peuvent être nettoyés par le ramasse miettes.
XI-K. Les itérateurs revisités▲
Nous pouvons maintenant démontrer la vraie puissance d'un Iterator : la capacité de séparer l'opération du parcours d'une séquence de la structure sous-jacente de cette séquence. La classe PrintData (définie précédemment dans le chapitre) utilise un Iterator pour se déplacer à travers une séquence et appelle la méthode toString( ) pour chaque objet. Dans l'exemple suivant, deux types de conteneurs différents sont créés -une ArrayList et une HashMap- et remplis, respectivement, avec des objets Mouse et Hamster . (ces classes ont été définies précédemment dans ce chapitre). Parce qu'un Iterator cache la structure sous-jacente du conteneur associé, Printer.printAll( ) ne sait pas et ne se soucie pas du type de conteneur dont l'Iterator provient :
//: c11:Iterators2.java
// Les itérateurs revisités.
import com.bruceeckel.simpletest.*;
import java.util.*;
public class Iterators2 {
private static Test monitor = new Test();
public static void main(String[] args) {
List list = new ArrayList();
for(int i = 0; i < 5; i++)
list.add(new Mouse(i));
Map m = new HashMap();
for(int i = 0; i < 5; i++)
m.put(new Integer(i), new Hamster(i));
System.out.println("List");
Printer.printAll(list.iterator());
System.out.println("Map");
Printer.printAll(m.entrySet().iterator());
monitor.expect(new String[] {
"List",
"This is Mouse #0",
"This is Mouse #1",
"This is Mouse #2",
"This is Mouse #3",
"This is Mouse #4",
"Map",
"4=This is Hamster #4",
"3=This is Hamster #3",
"2=This is Hamster #2",
"1=This is Hamster #1",
"0=This is Hamster #0"
}, Test.IGNORE_ORDER);
}
} ///:~Pour la HashMap, la méthode entrySet( ) renvoie un Set d'objets Map.entry, qui contient à la fois la clef et la valeur pour chaque entrée, ainsi vous pouvez voir les deux affichés.
Notez que PrintData.print( ) s'appuie sur le fait que les objets dans les conteneurs appartiennent à la classe Object et donc l'appel à toString( ) par System.out.println( ) est automatique. Il est toutefois plus courant de devoir assumer qu'un Iterator parcourt un conteneur d'un type spécifique. Par exemple, on peut assumer que tous les objets d'un conteneur sont une Shape avec une méthode draw( ). On doit alors effectuer un transtypage descendant depuis l'Object renvoyé par Iterator.next( ) pour produire une Shape.
XI-L. Choisir une implémentation▲
Vous devriez maintenant être conscient qu'il n'existe que trois types de conteneurs : Map, List, et Set, mais plus qu'une implémentation pour chaque interface. Si vous avez besoin d'utiliser la fonctionnalité offerte par une interface, comment choisir l'implémentation à utiliser ?
Pour comprendre la réponse, vous devez avoir conscience que chaque implémentation possède ses propres fonctionnalités, forces, et faiblesses. Par exemple, on peut voir dans le diagramme que la « fonctionnalité » de Hashtable, Vector, et Stack est là comme en héritage de ces classes, pour que le vieux code ne soit pas cassé. D'un autre côté, il vaut mieux ne pas les utiliser dans du nouveau code.
La distinction entre les autres conteneurs se ramène la plupart du temps à leur « support sous-jacent » ; c'est-à-dire la structure de données qui implémente physiquement l'interface désirée. Par exemple, ArrayList et LinkedList implémentent l'interface List, ainsi les opérations fondamentales sont les mêmes sans que vous vous souciiez de celle à utiliser. Cependant, une ArrayList est implémentée par un tableau, et une LinkedList est implémentée sous la forme d'une liste doublement chaînée, dont chaque objet individuel contient des données ainsi que des références sur les éléments précédents et suivants dans la liste. Pour cette raison, si vous voulez faire beaucoup d'insertions et de suppressions au milieu d'une liste, une LinkedList est un choix approprié (LinkedList propose aussi des fonctionnalités supplémentaires précisées dans AbstractSequentialList). Si ce n'est pas le cas, une ArrayList est généralement plus rapide.
Pour un autre exemple, un Set peut être implémenté soit par un TreeSet, un HashSet, ou un LinkedHashSet. Chacun a un comportement différent : HashSet est l'utilisation générale et fournit une vitesse totale pour la recherche, LinkedHashSet garde l'ordre d'insertion des paires, et TreeSet est implémenté par un TreeMap et est conçu pour fournir un ensemble toujours trié. L'idée est de choisir l'implémentation basée sur le comportement dont vous avez besoin. La plupart du temps, le HashSet a tout ce qui est nécessaire et devrait être votre choix de Set par défaut.
XI-L-1. Choisir entre les Lists▲
Un test de performance constitue la façon la plus convaincante de voir les différences entre les implémentations des Lists. Le code suivant crée une classe interne de base à utiliser comme structure de test, puis crée un tableau de classes internes anonymes, une pour chaque test différent. Chacune de ces classes internes est appelée par la méthode test( ). Cette approche permet d'ajouter et de supprimer facilement de nouveaux tests.
//: c11:ListPerformance.java
// Illustre les différences de performance entre les Lists.
// {Args: 500}
import java.util.*;
import com.bruceeckel.util.*;
public class ListPerformance {
private static int reps = 10000;
private static int quantity = reps / 10;
private abstract static class Tester {
private String name;
Tester(String name) { this.name = name; }
abstract void test(List a);
}
private static Tester[] tests = {
new Tester("get") {
void test(List a) {
for(int i = 0; i < reps; i++) {
for(int j = 0; j < quantity; j++)
a.get(j);
}
}
},
new Tester("iteration") {
void test(List a) {
for(int i = 0; i < reps; i++) {
Iterator it = a.iterator();
while(it.hasNext())
it.next();
}
}
},
new Tester("insert") {
void test(List a) {
int half = a.size()/2;
String s = "test";
ListIterator it = a.listIterator(half);
for(int i = 0; i < reps * 10; i++)
it.add(s);
}
},
new Tester("remove") {
void test(List a) {
ListIterator it = a.listIterator(3);
while(it.hasNext()) {
it.next();
it.remove();
}
}
},
};
public static void test(List a) {
// Enleve l'extension du nom de la classe :
System.out.println("Testing " +
a.getClass().getName().replaceAll("\\w+\\.", ""));
for(int i = 0; i < tests.length; i++) {
Collections2.fill(a, Collections2.countries.reset(),
quantity);
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(a);
long t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
}
}
public static void testArrayAsList(int reps) {
System.out.println("Testing array as List");
// On ne peut effectuer que les deux premiers tests sur un tableau :
for(int i = 0; i < 2; i++) {
String[] sa = new String[quantity];
Arrays2.fill(sa, Collections2.countries.reset());
List a = Arrays.asList(sa);
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(a);
long t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
}
}
public static void main(String[] args) {
// Le nombre de répétitions peut être spécifié
// via la ligne de commande :
if(args.length > 0)
reps = Integer.parseInt(args[0]);
System.out.println(reps + " repetitions");
testArrayAsList(reps);
test(new ArrayList());
test(new LinkedList());
test(new Vector());
}
} ///:~Pour fournir une classe de base aux tests spécifiques, la classe interne Tester est abstract. Elle contient une String à imprimer quand le test débute et une méthode abstract test( ) qui réalise le travail. Tous les types de tests sont regroupés à un seul endroit, le tableau tests, initialisé par différentes classes internes anonymes dérivées de Tester. Pour ajouter ou supprimer des tests, il suffit d'ajouter ou de supprimer la définition d'une classe interne dans le tableau, et le reste est géré automatiquement.
Pour comparer l'accès aux tableaux avec l'accès aux conteneurs (et particulièrement avec les ArrayList), un test spécial est créé pour les tableaux en les encapsulant dans des List en utilisant Arrays.asList( ). Notez que seuls les deux premiers tests peuvent être réalisés dans ce cas, parce qu'on ne peut pas insérer ou supprimer des éléments dans un tableau.
La List passée à test( ) est d'abord remplie avec des éléments, puis chaque test du tableau tests est chronométré. Les résultats dépendent bien entendu de la machine ; ils sont seulement conçus pour donner un ordre de comparaison entre les performances des différents conteneurs. Voici un résumé pour une exécution :
|
Type |
Get |
Itération |
Insert |
Remove |
|---|---|---|---|---|
|
tableau |
172 |
516 |
na |
na |
|
ArrayList |
281 |
1375 |
328 |
30484 |
|
LinkedList |
5828 |
1047 |
109 |
16 |
|
Vector |
422 |
1890 |
360 |
30781 |
Comme prévu, les tableaux sont plus rapides que n'importe quel conteneur pour les accès aléatoires et les itérations. On peut voir que les accès aléatoires (get( )) sont économiques pour les ArrayLists et chers pour les LinkedLists (bizarrement, l'itération est plus rapide pour une LinkedList qu'une ArrayList, ce qui est quelque peu contre-intuitif). D'un autre côté, les insertions et les suppressions au milieu d'une liste sont spectaculairement meilleur marché pour une LinkedList que pour une ArrayList -particulièrement les suppressions. Un Vector n'est généralement pas aussi rapide qu'une ArrayList, et il devrait être évité ; il n'est présent dans la bibliothèque que pour fournir une compatibilité ascendante avec le code existant (la seule raison pour laquelle il fonctionne dans ce programme est qu'il a été adapté pour être une List dans Java 2). La meilleure approche est de choisir une ArrayList par défaut et de changer pour une LinkedList si l'on découvre des problèmes de performance dus à de nombreuses insertions et suppressions au milieu de la liste. Bien sûr, si on utilise un ensemble d'éléments de taille fixe, il faut se tourner vers un tableau.
XI-L-2. Choisir entre les Sets▲
Vous pouvez choisir un TreeSet, un HashSet, ou un LinkedHashSet en fonction du comportement désiré. Le programme de test suivant donne une indication des performances entre les implémentations :
//: c11:SetPerformance.java
// {Args: 500}
import java.util.*;
import com.bruceeckel.util.*;
public class SetPerformance {
private static int reps = 50000;
private abstract static class Tester {
String name;
Tester(String name) { this.name = name; }
abstract void test(Set s, int size);
}
private static Tester[] tests = {
new Tester("add") {
void test(Set s, int size) {
for(int i = 0; i < reps; i++) {
s.clear();
Collections2.fill(s,
Collections2.countries.reset(),size);
}
}
},
new Tester("contains") {
void test(Set s, int size) {
for(int i = 0; i < reps; i++)
for(int j = 0; j < size; j++)
s.contains(Integer.toString(j));
}
},
new Tester("iteration") {
void test(Set s, int size) {
for(int i = 0; i < reps * 10; i++) {
Iterator it = s.iterator();
while(it.hasNext())
it.next();
}
}
},
};
public static void test(Set s, int size) {
// Enlève l'extension du nom de la classe :
System.out.println("Testing " +
s.getClass().getName().replaceAll("\\w+\\.", "") +
" size " + size);
Collections2.fill(s,
Collections2.countries.reset(), size);
for(int i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(s, size);
long t2 = System.currentTimeMillis();
System.out.println(": " +
((double)(t2 - t1)/(double)size));
}
}
public static void main(String[] args) {
// Choisir un nombre différent de
// répétitions via la ligne de commande :
if(args.length > 0)
reps = Integer.parseInt(args[0]);
System.out.println(reps + " repetitions");
// Petit :
test(new TreeSet(), 10);
test(new HashSet(), 10);
test(new LinkedHashSet(), 10);
// Moyen :
test(new TreeSet(), 100);
test(new HashSet(), 100);
test(new LinkedHashSet(), 100);
// Grand :
test(new TreeSet(), 1000);
test(new HashSet(), 1000);
test(new LinkedHashSet(), 1000);
}
} ///:~Le tableau suivant montre les résultats d'une exécution (bien sûr, vous obtiendrez des valeurs différentes suivant votre ordinateur et la JVM que vous utilisez ; lancez les tests vous-même pour vous faire une idée) :
|
Type |
Taille du test |
Ajout |
Contient |
Itération |
|---|---|---|---|---|
|
TreeSet |
10 |
25.0 |
23.4 |
39.1 |
|
100 |
17.2 |
27.5 |
45.9 |
|
|
1000 |
26.0 |
30.2 |
9.0 |
|
|
HashSet |
10 |
18.7 |
17.2 |
64.1 |
|
100 |
17.2 |
19.1 |
65.2 |
|
|
1000 |
8.8 |
16.6 |
12.8 |
|
|
LinkedHashSet |
10 |
20.3 |
18.7 |
64.1 |
|
100 |
18.6 |
19.5 |
49.2 |
|
|
1000 |
10.0 |
16.3 |
10.0 |
Les performances d'un HashSet sont généralement supérieures à celles d'un TreeSet pour toutes les opérations (mais en particulier l'ajout et la recherche, les deux opérations les plus importantes). La seule raison d'être du TreeSet est qu'il maintient ses éléments triés, on ne l'utilisera donc que lorsqu'on aura besoin d'un Set trié.
Notez qu'un LinkedHashSet est un peu plus cher pour les insertions qu'un HashSet ; cela s'explique par le coût supplémentaire du maintien de la liste chaînée avec le conteneur haché. Cependant, l'itération est meilleur marché avec un LinkedHashSet grâce à la liste chaînée.
XI-L-3. Choisir entre les Maps▲
Lorsqu'on doit choisir entre les différentes implémentations d'une Map, sa taille est le critère qui affecte le plus les performances, et le programme de test suivant donne une indication de ce compromis :
//: c11:MapPerformance.java
// Illustre les différences de performance entre les Maps.
// {Args: 500}
import java.util.*;
import com.bruceeckel.util.*;
public class MapPerformance {
private static int reps = 50000;
private abstract static class Tester {
String name;
Tester(String name) { this.name = name; }
abstract void test(Map m, int size);
}
private static Tester[] tests = {
new Tester("put") {
void test(Map m, int size) {
for(int i = 0; i < reps; i++) {
m.clear();
Collections2.fill(m,
Collections2.geography.reset(), size);
}
}
},
new Tester("get") {
void test(Map m, int size) {
for(int i = 0; i < reps; i++)
for(int j = 0; j < size; j++)
m.get(Integer.toString(j));
}
},
new Tester("iteration") {
void test(Map m, int size) {
for(int i = 0; i < reps * 10; i++) {
Iterator it = m.entrySet().iterator();
while(it.hasNext())
it.next();
}
}
},
};
public static void test(Map m, int size) {
// Enlève les qualifieurs du nom de classe :
System.out.println("Testing " +
m.getClass().getName().replaceAll("\\w+\\.", "") +
" size " + size);
Collections2.fill(m,
Collections2.geography.reset(), size);
for(int i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(m, size);
long t2 = System.currentTimeMillis();
System.out.println(": " +
((double)(t2 - t1)/(double)size));
}
}
public static void main(String[] args) {
// Le nombre de répétitions peut être changé
// via la ligne de commande :
if(args.length > 0)
reps = Integer.parseInt(args[0]);
System.out.println(reps + " repetitions");
// Petit :
test(new TreeMap(), 10);
test(new HashMap(), 10);
test(new LinkedHashMap(), 10);
test(new IdentityHashMap(), 10);
test(new WeakHashMap(), 10);
test(new Hashtable(), 10);
// Moyen :
test(new TreeMap(), 100);
test(new HashMap(), 100);
test(new LinkedHashMap(), 100);
test(new IdentityHashMap(), 100);
test(new WeakHashMap(), 100);
test(new Hashtable(), 100);
// Gros :
test(new TreeMap(), 1000);
test(new HashMap(), 1000);
test(new LinkedHashMap(), 1000);
test(new IdentityHashMap(), 1000);
test(new WeakHashMap(), 1000);
test(new Hashtable(), 1000);
}
} ///:~Parce que la taille de la Map constitue le facteur principal, on voit que les tests de chronométrage divisent le temps par la taille de la Map pour normaliser chaque mesure. Voici un ensemble de résultats (les vôtres différeront probablement) :
|
Type |
Test size |
Add |
Contains |
Iteration |
|---|---|---|---|---|
|
TreeMap |
10 |
26.6 |
20.3 |
43.7 |
|
100 |
34.1 |
27.2 |
45.8 |
|
|
1000 |
27.8 |
29.3 |
8.8 |
|
|
HashMap |
10 |
21.9 |
18.8 |
60.9 |
|
100 |
21.9 |
18.6 |
63.3 |
|
|
1000 |
11.5 |
18.8 |
12.3 |
|
|
LinkedHashMap |
10 |
23.4 |
18.8 |
59.4 |
|
100 |
24.2 |
19.5 |
47.8 |
|
|
1000 |
12.3 |
19.0 |
9.2 |
|
|
IdentityHashMap |
10 |
20.3 |
25.0 |
71.9 |
|
100 |
19.7 |
25.9 |
56.7 |
|
|
1000 |
13.1 |
24.3 |
10.9 |
|
|
WeakHashMap |
10 |
26.6 |
18.8 |
76.5 |
|
100 |
26.1 |
21.6 |
64.4 |
|
|
1000 |
14.7 |
19.2 |
12.4 |
|
|
Hashtable |
10 |
18.8 |
18.7 |
65.7 |
|
100 |
19.4 |
20.9 |
55.3 |
|
|
1000 |
13.1 |
19.9 |
10.8 |
Comme on pouvait s'y attendre, la performance d'une Hashtable est à peu près équivalente à celle d'une HashMap. (Vous pouvez aussi voir qu'une HashMap est généralement un peu plus rapide ; HashMap est destinée à remplacer Hashtable.) Le TreeMap étant généralement plus lent que le HashMap, pourquoi voudrait-on l'utiliser ? Comme un moyen de créer une liste ordonnée. Le comportement d'un arbre est tel qu'il est toujours ordonné et n'a pas besoin d'être spécifiquement trié. Une fois un TreeMap rempli, il est possible d'appeler keySet( ) pour récupérer un Set des clefs, puis toArray( ) pour produire un tableau de ces clefs. On peut alors utiliser la méthode static Arrays.binarySearch( ) (que nous étudierons plus loin) pour trouver rapidement des objets dans ce tableau trié. Bien sûr, on ne ferait ceci que si, pour une raison ou une autre, le comportement d'une HashMap ne convenait pas, puisqu'une HashMap est conçue justement pour retrouver rapidement des objets. De plus, on peut facilement créer une HashMap à partir d'un TreeMap avec une simple création d'objets. Pour résumer, votre premier réflexe si vous voulez utiliser une Map, devrait être de se tourner vers un HashMap, et n'utiliser un TreeMap que si vous avez besoin d'une Map constamment triée.
LinkedHashMap est légèrement plus lent que HashMap, car elle maintient la liste liée en plus de la structure de données de hachage. IdentityHashMap a des performances différentes car il utilise == plutôt que equals( ) pour les comparaisons.
XI-M. Trier et rechercher dans les Lists▲
Les fonctions effectuant des tris et des recherches dans les Lists ont les mêmes noms et signatures que celles réalisant ces opérations sur des tableaux d'objets, mais sont des méthodes static appartenant à la classe Collections au lieu de Arrays. En voici un exemple, adapté de ArraySearching.java :
//: c11:ListSortSearch.java
// Trier et rechercher dans les Lists avec 'Collections.'
import com.bruceeckel.util.*;
import java.util.*;
public class ListSortSearch {
public static void main(String[] args) {
List list = new ArrayList();
Collections2.fill(list, Collections2.capitals, 25);
System.out.println(list + "\n");
Collections.shuffle(list);
System.out.println("After shuffling: " + list);
Collections.sort(list);
System.out.println(list + "\n");
Object key = list.get(12);
int index = Collections.binarySearch(list, key);
System.out.println("Location of " + key +
" is " + index + ", list.get(" +
index + ") = " + list.get(index));
AlphabeticComparator comp = new AlphabeticComparator();
Collections.sort(list, comp);
System.out.println(list + "\n");
key = list.get(12);
index = Collections.binarySearch(list, key, comp);
System.out.println("Location of " + key +
" is " + index + ", list.get(" +
index + ") = " + list.get(index));
}
} ///:~L'utilisation de ces méthodes est identique à celles dans Arrays, mais une List est utilisée à la place d'un tableau. Comme pour rechercher et trier avec les tableaux, si on trie en utilisant un Comparator, il faut que binarySearch( ) utilise le même Comparator.
Ce programme illustre aussi la méthode shuffle( ) de la classe Collections, qui modifie aléatoirement l'ordre d'une List.
XI-N. Utilitaires▲
Il existe un certain nombre d'autres utilitaires bien pratiques dans la classe Collections :
|
max(Collection) |
Renvoie l'élément maximum ou minimum de l'argument en utilisant la méthode de comparaison naturelle des objets de la Collection. |
|
max(Collection, Comparator) |
Renvoie l'élément maximum ou minimum de la Collection en utilisant le Comparator. |
|
indexOfSubList(List source, List target) |
Renvoie l'index de départ de la première occurrence de target dans source. |
|
lastIndexOfSubList(List source, List target) |
Renvoie l'index de départ de la dernière occurrence de target dans source. |
|
replaceAll(List list, |
Remplace toute occurrence de oldVal par newVal. |
|
reverse( ) |
Inverse tous les éléments sur place. |
|
rotate(List list, int distance) |
Déplace tous les éléments de la liste à la distance spécifiée, déplaçant les éléments de fin au début (rotation). |
|
copy(List dest, List src) |
Copie les éléments de src vers dest. |
|
swap(List list, int i, int j) |
Permute les éléments aux positions i et j dans list. Probablement plus rapide que ce que vous auriez écrit à la main. |
|
fill(List list, Object o) |
Remplace tous les éléments de la liste par o. |
|
nCopies(int n, Object o) |
Renvoie une List non modifiable de taille n dont les références pointent toutes sur o. |
|
enumeration(Collection) |
Renvoie une Enumeration ancien style pour l'argument. |
|
list(Enumeration e) |
Renvoie une ArrayList générée à partir de l'Enumeration. Pour la conversion de code existant. |
Notez que comme min( ) et max( ) fonctionnent avec des objets Collection et non avec des Lists, il n'est pas nécessaire que la Collection soit triée (ainsi que nous l'avons déjà vu, il faut appliquer sort( ) à une List ou un tableau avant de leur appliquer binarySearch( ).)
//: c11:Utilities.java
// Simple demonstration des utilitaires de la classe Collections.
import com.bruceeckel.simpletest.*;
import java.util.*;
import com.bruceeckel.util.*;
public class Utilities {
private static Test monitor = new Test();
public static void main(String[] args) {
List list = Arrays.asList(
"one Two three Four five six one".split(" "));
System.out.println(list);
System.out.println("max: " + Collections.max(list));
System.out.println("min: " + Collections.min(list));
AlphabeticComparator comp = new AlphabeticComparator();
System.out.println("max w/ comparator: " +
Collections.max(list, comp));
System.out.println("min w/ comparator: " +
Collections.min(list, comp));
List sublist =
Arrays.asList("Four five six".split(" "));
System.out.println("indexOfSubList: " +
Collections.indexOfSubList(list, sublist));
System.out.println("lastIndexOfSubList: " +
Collections.lastIndexOfSubList(list, sublist));
Collections.replaceAll(list, "one", "Yo");
System.out.println("replaceAll: " + list);
Collections.reverse(list);
System.out.println("reverse: " + list);
Collections.rotate(list, 3);
System.out.println("rotate: " + list);
List source =
Arrays.asList("in the matrix".split(" "));
Collections.copy(list, source);
System.out.println("copy: " + list);
Collections.swap(list, 0, list.size() - 1);
System.out.println("swap: " + list);
Collections.fill(list, "pop");
System.out.println("fill: " + list);
List dups = Collections.nCopies(3, "snap");
System.out.println("dups: " + dups);
// Obtenir une Enumeration ancien style :
Enumeration e = Collections.enumeration(dups);
Vector v = new Vector();
while(e.hasMoreElements())
v.addElement(e.nextElement());
// Conversion d'un Vector ancien style
// en une List via une Enumeration:
ArrayList arrayList = Collections.list(v.elements());
System.out.println("arrayList: " + arrayList);
monitor.expect(new String[] {
"[one, Two, three, Four, five, six, one]",
"max: three",
"min: Four",
"max w/ comparator: Two",
"min w/ comparator: five",
"indexOfSubList: 3",
"lastIndexOfSubList: 3",
"replaceAll: [Yo, Two, three, Four, five, six, Yo]",
"reverse: [Yo, six, five, Four, three, Two, Yo]",
"rotate: [three, Two, Yo, Yo, six, five, Four]",
"copy: [in, the, matrix, Yo, six, five, Four]",
"swap: [Four, the, matrix, Yo, six, five, in]",
"fill: [pop, pop, pop, pop, pop, pop, pop]",
"dups: [snap, snap, snap]",
"arrayList: [snap, snap, snap]"
});
}
} ///:~La sortie explique le comportement de chaque méthode utilitaire. Notez la différence dans min( ) et max( ) dans AlphabeticComparator à cause des majuscules.
XI-N-1. Rendre une Collection ou une Map non modifiable▲
Il est souvent bien pratique de créer une version en lecture seule d'une Collection ou d'une Map. La classe Collections permet ceci en passant le conteneur original à une méthode qui en renvoie une version en lecture seule. Il existe quatre variantes de cette méthode, une pour les Collections (si on ne veut pas traiter une Collection comme un type plus spécifique), une pour les Lists, une pour les Sets, et une pour les Maps. Cet exemple montre la bonne manière pour construire des versions en lecture seule de chaque variante :
//: c11:ReadOnly.java
// Utilisation des méthodes Collections.unmodifiable.
import java.util.*;
import com.bruceeckel.util.*;
public class ReadOnly {
private static Collections2.StringGenerator gen =
Collections2.countries;
public static void main(String[] args) {
Collection c = new ArrayList();
Collections2.fill(c, gen, 25); // Insertion des données
c = Collections.unmodifiableCollection(c);
System.out.println(c); // L'accès en lecture est OK
//! c.add("one"); // Modification impossible
List a = new ArrayList();
Collections2.fill(a, gen.reset(), 25);
a = Collections.unmodifiableList(a);
ListIterator lit = a.listIterator();
System.out.println(lit.next()); // L'accès en lecture est OK
//! lit.add("one"); // Modification impossible
Set s = new HashSet();
Collections2.fill(s, gen.reset(), 25);
s = Collections.unmodifiableSet(s);
System.out.println(s); // L'accès en lecture est OK
//! s.add("one"); // Modification impossible
Map m = new HashMap();
Collections2.fill(m, Collections2.geography, 25);
m = Collections.unmodifiableMap(m);
System.out.println(m); // L'accès en lecture est OK
//! m.put("Ralph", "Howdy!");
}
} ///:~Appeler la méthode « unmodifiable » pour un type particulier n'implique pas de contrôle lors de la compilation, mais une fois la transformation effectuée, tout appel à une méthode tentant de modifier le contenu du conteneur provoquera une UnsupportedOperationException.
Dans chaque cas, le conteneur doit être rempli de données significatives avant de le rendre non modifiable. Une fois qu'il est rempli, la meilleure approche consiste à remplacer la référence existante par la référence renvoyée par l'appel à « unmodifiable ». De cette façon, on ne risque pas d'en altérer accidentellement le contenu une fois qu'on l'a rendu non modifiable. D'un autre côté, cet outil permet également de garder un conteneur modifiable private dans la classe et de renvoyer une référence en lecture seule sur ce conteneur à partir d'une méthode. Ainsi on peut le changer depuis la classe, tandis qu'on ne pourra y accéder qu'en lecture depuis l'extérieur de cette classe.
XI-N-2. Synchroniser une Collection ou une Map▲
Le mot-clé synchronized constitue une partie importante du multithreading, un sujet plus compliqué qui ne sera abordé qu'à partir du Chapitre 13. Ici, je noterai juste que la classe Collections permet de synchroniser automatiquement un conteneur entier. La syntaxe en est similaire aux méthodes « unmodifiable » :
//: c11:Synchronization.java
// Utilisation des méthodes Collections.synchronized.
import java.util.*;
public class Synchronization {
public static void main(String[] args) {
Collection c =
Collections.synchronizedCollection(new ArrayList());
List list =
Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());
}
} ///:~Dans ce cas, on passe directement le nouveau conteneur à la méthode « synchronised » appropriée ; ainsi la version non synchronisée ne peut être accédée de manière accidentelle.
XI-N-2-a. Echec rapide▲
Les conteneurs Java possèdent aussi un mécanisme qui permet d'empêcher que le contenu d'un conteneur ne soit modifié par plus d'un processus. Le problème survient si on itère à travers un conteneur, alors qu'un autre processus insère, supprime, ou change un objet de ce conteneur. Cet objet peut déjà avoir été passé, ou on ne l'a pas encore rencontré, peut-être que la taille du conteneur a diminué depuis qu'on a appelé size( ) - il existe de nombreux scénarios catastrophes. La bibliothèque de conteneurs Java incorpore un mécanisme d'échec-rapide qui traque tous les changements effectués sur le conteneur autre que ceux dont notre processus est responsable. S'il détecte que quelqu'un d'autre tente de modifier le conteneur, il produit immédiatement une ConcurrentModificationException. C'est l'aspect « échec-rapide » - il ne tente pas de détecter le problème plus tard en utilisant un algorithme plus complexe.
Il est relativement aisé de voir le mécanisme d'échec-rapide en action - tout ce qu'on a à faire est de créer un itérateur et d'ajouter alors un item à la collection sur laquelle l'itérateur pointe, comme ceci :
//: c11:FailFast.java
// Illustre la notion d'« échec rapide ».
// {ThrowsException}
import java.util.*;
public class FailFast {
public static void main(String[] args) {
Collection c = new ArrayList();
Iterator it = c.iterator();
c.add("An object");
// Génére une exception :
String s = (String)it.next();
}
} ///:~L'exception survient parce que quelque chose est stocké dans le conteneur après que l'itérateur ait été produit par le conteneur. La possibilité que deux parties du programme puissent modifier le même conteneur mène à un état incertain, l'exception notifie donc qu'il faut modifier le code - dans ce cas, récupérer l'itérateur après avoir ajouté tous les éléments au conteneur.
Notez qu'on ne peut bénéficier de ce genre de surveillance quand on accède aux éléments d'une List en utilisant get( ).
XI-O. Opérations non supportées▲
Il est possible de transformer un tableau en List grâce à la méthode Arrays.asList( ) :
//: c11:Unsupported.java
// Quelquefois les méthodes définies dans les
// interfaces Collection ne fonctionnent pas!
// {ThrowsException}
import java.util.*;
public class Unsupported {
static List a = Arrays.asList(
"one two three four five six seven eight".split(" "));
static List a2 = a.subList(3, 6);
public static void main(String[] args) {
System.out.println(a);
System.out.println(a2);
System.out.println("a.contains(" + a.get(0) + ") = " +
a.contains(a.get(0)));
System.out.println("a.containsAll(a2) = " +
a.containsAll(a2));
System.out.println("a.isEmpty() = " + a.isEmpty());
System.out.println("a.indexOf(" + a.get(5) + ") = " +
a.indexOf(a.get(5)));
// Traversée à reculons
ListIterator lit = a.listIterator(a.size());
while(lit.hasPrevious())
System.out.print(lit.previous() + " ");
System.out.println();
// Modification de la valeur des éléments :
for(int i = 0; i < a.size(); i++)
a.set(i, "47");
System.out.println(a);
// Compile, mais ne marche pas :
lit.add("X"); // Opération non supportée
a.clear(); // non supportée
a.add("eleven"); // non supportée
a.addAll(a2); // non supportée
a.retainAll(a2); // non supportée
a.remove(a.get(0)); // non supportée
a.removeAll(a2); // non supportée
}
} ///:~En fait, seule une partie des interfaces Collection et List est implémentée. Le reste des méthodes provoque l'apparition déplaisante d'une chose appelée UnsupportedOperationException. L'interface Collection, comme certaines autres interfaces de la bibliothèque de conteneurs Java, contient des méthodes « optionnelles », qui peuvent ou non être « supportées » dans la classe concrète qui implements cette interface. Appeler une méthode non supportée provoque une UnsupportedOperationException pour indiquer une erreur de programmation.
« Comment ?!? » vous exclamez-vous, incrédule. « Tout l'intérêt des interfaces et des classes de base provient du fait qu'elles promettent que ces méthodes feront quelque chose d'utile ! Cette affirmation rompt cette promesse ; non seulement ces méthodes ne réalisent pas d'opération intéressante, mais en plus elles arrêtent le programme ! La sécurité des types est donc jetée par la fenêtre ! »
Ce n'est pas si grave que ça. Avec une Collection, une List, un Set, ou une Map, le compilateur empêche toujours d'appeler des méthodes autres que celles présentes dans cette interface, ce n'est donc pas comme Smalltalk (qui permet d'appeler n'importe quelle méthode sur n'importe objet, appel dont on ne voit la pertinence que lors de l'exécution du programme). De plus, la plupart des méthodes acceptant une Collection comme argument ne font que lire cette Collection, toutes les méthodes de « lecture » de Collection ne sont pas optionnelles.
Cette approche empêche l'explosion du nombre d'interfaces dans la conception. Les autres conceptions de bibliothèques de conteneurs semblent toujours se terminer par une pléthore d'interfaces pour décrire chacune des variations sur le thème principal et sont donc difficiles à apprendre. Il n'est même pas possible de saisir tous les cas spéciaux dans les interfaces, car n'importe qui peut toujours créer une nouvelle interface. L'approche « opération non supportée » réalise l'un des buts fondamentaux de la bibliothèque de conteneurs Java : les conteneurs sont simples à apprendre et à utiliser ; les opérations non supportées sont des cas spéciaux qui peuvent être appris par la suite. Pour que cette approche fonctionne, cependant :
- L'UnsupportedOperationException doit être un événement rare. C'est-à-dire, que pour la majorité des classes toutes les opérations doivent fonctionner, et seulement des cas spéciaux devraient ne pas supporter une opération. Ceci est vrai dans la bibliothèque de conteneurs Java, puisque les classes que vous utiliserez dans 99 pour cent des cas, ArrayList, LinkedList, HashSet, et HashMap, de même que les autres implémentations concrètes, supportent toutes les opérations. Cette conception fournit une « porte dérobée » si on veut créer une nouvelle Collection sans fournir de définition sensée pour toutes les méthodes de l'interface Collection, et s'intègre tout de même dans la bibliothèque existante.
- Quand une opération n'est pas supportée, il faut une probabilité raisonnable qu'une UnsupportedOperationException apparaisse lors de l'implémentation plutôt qu'une fois le produit livré au client. Après tout, elle indique une erreur de programmation : une implémentation a été utilisée de manière incorrecte. Ce point est moins certain, et c'est là où la nature expérimentale de cette conception entre en jeu. Nous ne nous apercevrons de son intérêt qu'avec le temps.
Dans l'exemple précédent, Arrays.asList( ), produit une List, supportée par un tableau de taille fixe. Il est donc sensé que les seules opérations supportées soient celles qui ne changent pas la taille du tableau. D'un autre côté, si une nouvelle interface était requise pour exprimer ce différent type de comportement (peut-être appelée « FixedSizeList »), cela laisserait la porte ouverte à la complexité et bientôt on ne saurait par où commencer lorsque l'on voudrait utiliser la bibliothèque.
Notez que vous pouvez toujours passer le résultat de Arrays.asList( ) comme l'argument du constructeur d'une List ou d'un Set afin de créer un conteneur régulier qui permet l'utilisation de toutes les méthodes.
La documentation d'une méthode qui accepte une Collection, une List, un Set, ou une Map en argument doit spécifier quelles méthodes optionnelles doivent être implémentées. Par exemple, trier nécessite les méthodes set( ) et Iterator.set( ), mais pas add( ) et remove( ).
XI-P. Les conteneurs Java 1.0 / 1.1▲
Malheureusement, beaucoup de code a été écrit en utilisant les conteneurs Java 1.0 / 1.1, et même du nouveau code est quelquefois écrit en utilisant ces classes. Bien que vous ne devriez jamais utiliser les anciens conteneurs en écrivant du nouveau code, il faut toutefois être conscient qu'ils existent. Cependant, les anciens conteneurs étaient plutôt limités, il n'y a donc pas tellement à en dire sur eux (puisqu'ils appartiennent au passé, j'éviterais de trop me pencher sur certaines horribles décisions de conception).
XI-P-1. Vector & Enumeration▲
Le Vector, était la seule séquence autoredimensionnable dans Java 1.0 / 1.1, ce qui favorisa son utilisation. Ses défauts sont trop nombreux pour être décrits ici (se référer à la première version de ce livre, téléchargeable librement sur www.BruceEckel.com). Fondamentalement, il s'agit d'une ArrayList avec des noms de méthodes longs et maladroits. Dans la bibliothèque de conteneurs Java 2, la classe Vector a été adaptée afin de pouvoir s'intégrer comme une Collection et une List, et donc dans l'exemple suivant la méthode, la méthode Collections2.fill( ) est utilisée avec succès. Ceci peut mener à des effets pervers, car on pourrait croire que la classe Vector a été améliorée, alors qu'elle n'a été incluse que pour supporter du code préJava2.
La version Java 1.0 / 1.1 de l'itérateur a choisi d'inventer un nouveau nom, « énumération », au lieu d'utiliser un terme déjà familier pour tout le monde. L'interface Enumeration est plus petite qu'Iterator, avec seulement deux méthodes, et utilise des noms de méthodes plus longs : boolean hasMoreElements( ) renvoie true si l'énumération contient encore des éléments, et Object nextElement( ) renvoie l'élément suivant de cette énumération s’il y en a encore (autrement elle génère une exception).
Enumeration n'est qu'une interface, et non une implémentation, et même les nouvelles bibliothèques utilisent encore quelquefois l'ancienne Enumeration, ce qui est malheureux, mais généralement sans conséquence. Cependant vous devriez toujours utiliser Iterator quand vous le pouvez dans votre code, on peut encore rencontrer des bibliothèques qui renvoient des Enumerations.
De plus, toute Collection peut fournir une Enumeration en utilisant la méthode Collections.enumeration( ), comme le montre cet exemple :
//: c11:Enumerations.java
// Java 1.0/1.1 Vector and Enumeration.
import java.util.*;
import com.bruceeckel.util.*;
public class Enumerations {
public static void main(String[] args) {
Vector v = new Vector();
Collections2.fill(v, Collections2.countries, 100);
Enumeration e = v.elements();
while(e.hasMoreElements())
System.out.println(e.nextElement());
// Produit une Enumeration à partir d'une Collection :
e = Collections.enumeration(new ArrayList());
}
} ///:~La classe Vector de Java 1.0 / 1.1 ne dispose que d'une méthode addElement( ), mais fill( ) utilise la méthode add( ) qui a été copiée quand Vector a été transformé en List. Pour produire une Enumeration, il faut appeler elements( ), on peut alors l'utiliser pour réaliser une itération en avant.
La dernière ligne crée une ArrayList et utilise enumeration( ) pour adapter une Enumeration à partir de l'Iterator de l'ArrayList. Ainsi, si on a du vieux code qui requiert une Enumeration, on peut tout de même utiliser les nouveaux conteneurs.
XI-P-2. Hashtable▲
Comme on a pu le voir dans les tests de comparaison de performance de ce chapitre, la Hashtable de base est très similaire à la HashMap, et ce même jusqu'aux noms des méthodes. Il n'y a aucune raison d'utiliser une Hashtable au lieu d'une HashMap dans du nouveau code.
XI-P-3. Stack▲
Le concept de la pile a déjà été introduit plus tôt, avec la LinkedList. Ce qui est relativement étrange à propos de la classe Stack en Java 1.0 / 1.1 est qu'au lieu d'utiliser un Vector comme composant de base, Stack est dérivée de Vector. Elle possède donc tous les caractéristiques et comportements d'un Vector en plus des comportements additionnels d'une Stack. Il est difficile de savoir si les concepteurs ont choisi délibérément cette approche en la jugeant particulièrement pratique, ou si c'était juste une conception naïve ; de toute façon elle ne fut clairement pas revue avant d'être intégrée à la distribution, ainsi cette mauvaise conception est encore légèrement utilisée (mais ne devrait jamais l'être).
Voici une simple illustration de Stack qui « pousse » chaque ligne d'un tableau de String :
//: c11:Stacks.java
// Illustration de la classe Stack.
import com.bruceeckel.simpletest.*;
import java.util.*;
import c08.Month;
public class Stacks {
private static Test monitor = new Test();
public static void main(String[] args) {
Stack stack = new Stack();
for(int i = 0; i < Month.month.length; i++)
stack.push(Month.month[i] + " ");
System.out.println("stack = " + stack);
// Traiter une pile comme un Vector :
stack.addElement("The last line");
System.out.println("element 5 = " +
stack.elementAt(5));
System.out.println("popping elements:");
while(!stack.empty())
System.out.println(stack.pop());
monitor.expect(new String[] {
"stack = [January , February , March , April , May "+
", June , July , August , September , October , " +
"November , December ]",
"element 5 = June ",
"popping elements:",
"The last line",
"December ",
"November ",
"October ",
"September ",
"August ",
"July ",
"June ",
"May ",
"April ",
"March ",
"February ",
"January "
});
}
} ///:~Chaque ligne du tableau months est insérée dans la Stack avec push( ), et récupérée par la suite au sommet de la pile avec un pop( ). On peut aussi réaliser des opérations de Vector sur l'objet Stack. Ceci est possible, car, de par les propriétés de l'héritage, une Stack est un Vector. Ainsi, toutes les opérations qui peuvent être effectuées sur un Vector peuvent aussi être réalisées sur une Stack, comme elementAt( ).
Comme mentionné précédemment, vous devriez utiliser une LinkedList si vous voulez le comportement d'une pile.
XI-P-4. BitSet▲
Un BitSet est utile si on veut stocker efficacement un grand nombre d'informations on-off. Cette classe n'est efficace toutefois que sur le plan de la taille ; si le but recherché est un accès performant, elle est plus lente qu'un tableau de quelques types natifs.
De plus, la taille minimum d'un BitSet est celle d'un long : 64 bits. Ce qui implique que si on stocke n'importe quelle quantité plus petite, comme 8 bits, un BitSet introduira du gaspillage ; il vaudrait donc mieux créer sa propre classe, ou utiliser un tableau, pour stocker les drapeaux si la taille est un problème.
Un conteneur normal s'étend si on ajoute de nouveaux éléments, et le BitSet le fait aussi. L'exemple suivant montre comment le BitSet fonctionne :
//: c11:Bits.java
// Illustration de BitSet.
import java.util.*;
public class Bits {
public static void printBitSet(BitSet b) {
System.out.println("bits: " + b);
String bbits = new String();
for(int j = 0; j < b.size() ; j++)
bbits += (b.get(j) ? "1" : "0");
System.out.println("bit pattern: " + bbits);
}
public static void main(String[] args) {
Random rand = new Random();
// Récupère les LSB (Less Significant Bits - NDT: bit de poids fort) de nextInt() :
byte bt = (byte)rand.nextInt();
BitSet bb = new BitSet();
for(int i = 7; i >= 0; i--)
if(((1 << i) & bt) != 0)
bb.set(i);
else
bb.clear(i);
System.out.println("byte value: " + bt);
printBitSet(bb);
short st = (short)rand.nextInt();
BitSet bs = new BitSet();
for(int i = 15; i >= 0; i--)
if(((1 << i) & st) != 0)
bs.set(i);
else
bs.clear(i);
System.out.println("short value: " + st);
printBitSet(bs);
int it = rand.nextInt();
BitSet bi = new BitSet();
for(int i = 31; i >= 0; i--)
if(((1 << i) & it) != 0)
bi.set(i);
else
bi.clear(i);
System.out.println("int value: " + it);
printBitSet(bi);
// Teste les bitsets >= 64 bits:
BitSet b127 = new BitSet();
b127.set(127);
System.out.println("set bit 127: " + b127);
BitSet b255 = new BitSet(65);
b255.set(255);
System.out.println("set bit 255: " + b255);
BitSet b1023 = new BitSet(512);
b1023.set(1023);
b1023.set(1024);
System.out.println("set bit 1023: " + b1023);
}
} ///:~Le générateur de nombres aléatoires est utilisé pour générer un byte, un short, et un int aléatoires et chacun est transformé en motif de bits dans un BitSet. Ceci fonctionne bien puisque la taille d'un BitSet est 64 bits, et donc aucun de ces nombres ne nécessite une augmentation de taille. Ensuite un BitSet de 512 bits est créé. Le constructeur alloue de la place pour deux fois ce nombre de bits. Cependant, on peut tout de même positionner le bit 1024 ou même au-delà.
XI-Q. Résumé▲
Pour résumer les conteneurs fournis dans la bibliothèque standard Java :
- Un tableau associe des indices numériques à des objets.Il stocke des objets d'un type connu afin de ne pas avoir à transtyper le résultat quand on récupère un objet. Il peut être multidimensionnel, et peut stocker des types primitifs. Cependant, sa taille ne peut pas être modifiée une fois créé.
- Une Collection stocke des éléments, alors qu'une Map stocke des paires d'éléments associés.
- Comme un tableau, une List associe aussi des indices numériques à des objets - on peut penser aux tableaux et aux Lists comme à des conteneurs ordonnés. Une List se redimensionne automatiquement si on y ajoute des éléments. Mais une List ne peut stocker que des références sur des Objects, elle ne peut donc pas stocker des scalaires et il faut toujours transtyper le résultat quand on récupère une référence sur Object du conteneur.
- Utiliser une ArrayList si on doit effectuer un grand nombre d'accès aléatoires, mais une LinkedList si on doit réaliser un grand nombre d'insertions et de suppressions au milieu de la liste.
- Le comportement de files, files doubles et piles est fourni via les LinkedList.
- Une Map est une façon d'associer non pas des nombres, mais des objets avec d'autres objets. La conception d'une HashMap est focalisée sur un accès rapide, tandis qu'un TreeMap garde ses clés ordonnées, et n'est donc pas aussi rapide qu'une HashMap. Une LinkedHashMap garde ses éléments dans l'ordre d'insertion, mais peut aussi les réordonner par son algorithme LRU (NDT : moins récemment utilisé).
- Un Set accepte seulement une seule instance de chaque type d'objet. Les HashSets fournissent des temps d'accès optimaux, alors que les TreeSets gardent leurs éléments ordonnés. Les LinkedHashSets gardent les éléments dans l'ordre d'insertion.
- Il n'y a aucune raison d'utiliser les anciennes classes Vector, Hashtable, et Stack dans du nouveau code.
Les conteneurs sont des outils que l'on peut utiliser jour après jour pour rendre les programmes plus simples, plus puissants et plus efficaces.
XI-R. Exercices▲
Les solutions des exercices choisis se trouvent dans le document électronique The Thinking in Java Annotated Solution Guide, disponible pour une somme modique sur http://www.BruceEckel.com.
- Créer un tableau de double et le remplir en utilisant RandDoubleGenerator. Afficher le résultat.
- Créer une nouvelle classe appelée Gerbil avec un attribut int gerbilNumber initialisé dans le constructeur (de la même façon que dans l'exemple Mouse de ce chapitre). La doter d'une méthode appelée hop( ) qui affiche que la gerbille numéro gerbilNumber est en train de bondir. Créer une ArrayList et ajouter un ensemble d'objets de type Gerbil à la liste puis appeler la méthode hop( ) de chaque objet Gerbil.
- Modifier l'exercice 2 pour utiliser un Iterator pour parcourir la List tout en appelant hop( ).
- Prendre la classe Gerbil de l'exercice 2 et la mettre dans une Map , en associant le nom d'une Gerbil à un objet String (la clé) pour chaque Gerbil (la valeur) mises dans la table. Créer un Iterator sur le keySet( ) et l'utiliser pour parcourir la Map, en cherchant la Gerbil pour chaque clé. Afficher la clé et ordonner à la gerbil de bondir( ).
- Créer une List (essayer une ArrayList et une LinkedList)et la remplir en utilisant Collections2.countries. Trier la liste et l'afficher, puis appliquer Collections.shuffle( ) à la liste de façon répétée, l'afficher à chaque appel pour voir comment la méthode shuffle( ) mélange la liste différemment à chaque fois.
- Démontrer qu'on ne peut rien n'ajouter d'autre qu'une Mouse à une MouseList.
- Modifier MouseList.java pour qu'elle hérite d'une ArrayList au lieu d'utiliser une composition. Montrer le problème induit par cette approche.
- Réviser CatsAndDogs.java en créant un conteneur Cats (utilisant ArrayList) qui n'acceptera et ne retournera que des objets Cat.
- Remplir une HashMap avec des paires clé-valeur. Afficher le résultat pour montrer le tri par hash code. Extraire les paires triées par clé, et placer le résultat dans une LinkedHashMap. Montrer que l'ordre d'insertion est conservé.
- Reprendre l'exemple précédent avec un HashSet et un LinkedHashSet.
- Créer un nouveau type de conteneur qui utilise une ArrayList privée pour contenir les objets.En utilisant une référence Class , récupérer le type du premier objet mis à l'intérieur, puis ne permettre à l'utilisateur de n'insérer que des objets de ce type.
- Créer un conteneur qui encapsule un tableau de String, dans lequel on ajoute uniquement des String ou duquel on extrait uniquement des String, pour qu'il n'y ait pas de transtypage durant l'utilisation. Si le tableau interne n'est pas assez grand pour les ajouts suivants, le conteneur devra le redimensionner automatiquement. Dans le main( ), comparer les performances du conteneur avec celles d'une ArrayList contenant des String.
- Répéter l'exercice 12 pour un conteneur de int, et comparer ses performances avec celles d'une ArrayList contenant des objets Integer. Dans la comparaison de performance, inclure le processus d'incrémentation de chaque objet dans le conteneur.
- En utilisant les utilitaires de com.bruceeckel.util, créer un tableau pour chaque type primitif et pour les String, puis remplir chaque tableau en utilisant un générateur approprié et afficher chaque tableau en utilisant la méthode print( ) appropriée.
- Créer un générateur qui donne les noms de personnages de vos films préférés (vous pouvez utiliser Snow White ou Star Wars comme solution de repli) et boucler au début lorsqu'on arrive à la fin des noms. Utiliser les utilitaires de com.bruceeckel.util pour remplir un tableau, une ArrayList, une LinkedList et les deux types de Set, puis afficher chaque conteneur.
- Créer une classe contenant deux objets String et les rendre Comparable pour que la comparaison ne se fasse que sur le premier String. Remplir un tableau et une ArrayList avec des objets de cette classe en utilisant le générateur geography . Démontrer que le tri fonctionne correctement. Puis créer un Comparator qui ne considère que le second String et démontrer que le tri fonctionne correctement. Exécuter aussi une recherche binaire en utilisant le Comparator.
- Modifier l'exercice 16 pour qu'un tri alphabétique soit utilisé.
- Utiliser Arrays2.RandStringGenerator pour remplir un TreeSet, mais en utilisant un tri alphabétique. Afficher le TreeSet pour vérifier l'ordre du tri.
- Créer une ArrayList et une LinkedList, et les remplir en utilisant le générateur Collections2.capitals. Afficher chaque liste en utilisant un Iterator ordinaire, puis insérer l'une des listes dans l'autre en utilisant un ListIterator, faire l'insertion un élément sur deux. Ensuite, faire l'insertion en partant de la fin de la première liste et en remontant vers le début.
- Écrire une méthode qui utilise un Iterator pour se déplacer dans une Collection et afficher le hashCode( ) de chaque objet existant dans le conteneur.
- Corriger le problème existant dans InfiniteRecursion.java.
- Créer une classe, puis créer un tableau initialisé d'objets de cette classe. Remplir une List à partir de ce tableau. Créer un sous-ensemble de la liste en utilisant subList( ), puis retirer ce sous-ensemble de la List en utilisant removeAll( ).
- Modifier l'exercice 6 du Chapitre 7 de façon à utiliser une ArrayList qui contient des Rodent et un Iterator pour parcourir la séquence de Rodent. Se souvenir qu'une ArrayList ne contient que des Object, donc utiliser un transtypage lorsqu'on accède à un Rodent.
- En suivant l'exemple Queue.java, créer une classe Deque et la tester.
- Utiliser une TreeMap dans Statistics.java. Puis ajouter un test de performance entre une HashMap et une TreeMap dans ce programme.
- Créer une Map et une Set contenant tous les pays qui commencent par « A ».
- En utilisant Collections2.countries, remplir un Set de multiples fois avec les mêmes données et vérifier que le Set ne contient qu'une seule instance de chaque donnée. Essayer ceci avec les deux types de Set.
- En partant de Statistics.java, créer un programme qui exécute le test de façon répétitive et regarder si un nombre tend à apparaître plus que les autres dans les résultats.
- Réécrire Statistics.java en utilisant un HashSet d'objets Counter (Counter devra être modifié pour qu'il fonctionne avec HashSet). Quelle approche semble être la meilleure ?
- Remplir une LinkedHashMap avec des clés String et des objets de votre choix. Puis extraire les paires, les trier sur leur clé, et les réinsérer dans la Map.
- Modifier la classe de l'exercice 16 pour qu'elle classe fonctionne avec des HashSet et comme clé des HashMap.
- En vous inspirant de SlowMap.java, créer un SlowSet.
- Créer une FastTraversalLinkedList qui utilise en interne une LinkedList pour une insertion et une suppression rapides et une ArrayList pour un parcours rapide et des opérations get( ). Testez-la en modifiant ArrayPerformance.java.
- Appliquer les tests des Map1.java à SlowMap pour vérifier que cela fonctionne. Corriger dans SlowMap ce qui ne fonctionne pas correctement.
- Implémenter le reste de l'interface Map à SlowMap.
- Modifier MapPerformance.java pour y inclure les tests de SlowMap.
- Modifier SlowMap pour qu'au lieu de contenir deux ArrayList, elle contienne une seule ArrayList d'objets MPair. Vérifier que la version corrigée fonctionne correctement. En utilisant MapPerformance.java, tester la vitesse de la nouvelle Map. Puis modifier la méthode put( ) pour qu'elle exécute un tri( ) après l'insertion de chaque paire, et modifier get( ) pour qu'elle recherche une clé à l'aide de Collections.binarySearch( ). Comparer les performances de la nouvelle version à celles de l'ancienne.
- Ajouter un champ char à CountedString. Ce champ sera, lui aussi, initialisé dans le constructeur. Modifier les méthodes hashCode( ) et equals( ) pour y inclure la valeur de ce char.
- Modifier SimpleHashMap pour qu'il indique les collisions, et tester ceci en ajoutant le même ensemble de données deux fois pour constater une collision.
- Modifier SimpleHashMap pour qu'il indique le nombre de « recherches » nécessaires lorsque des collisions se produisent. C'est-à-dire, combien d'appels à next( ) doivent être faits sur les Iterator qui parcourent les LinkedList afin de trouver les correspondances ?
- Implémenter les méthodes clear( ) et remove( ) pour SimpleHashMap.
- Implémenter le reste de l'interface Map pour SimpleHashMap.
- Ajouter une méthode rehash( ) privée à SimpleHashMap qui est invoquée lorsque le taux de remplissage dépasse 0,75. Durant le rehachage, doubler le nombre de seaux, puis rechercher le premier nombre premier plus grand que ce nombre, afin de déterminer le nouveau nombre de seaux.
- En suivant l'exemple de SimpleHashMap.java, créer et tester un SimpleHashSet.
- Modifier SimpleHashMap pour qu'il utilise des ArrayList au lieu de LinkedList. Modifier MapPerformance.java pour comparer les performances des deux implémentations.
- En utilisant la documentation HTML du JDK (téléchargeable sur java.sun.com),rechercher la classe HashMap. Créer une HashMap, la remplir d'éléments et déterminer son taux de remplissage. Tester la vitesse de recherche de cette carte, puis essayer d'accroître la vitesse en créant une nouvelle HashMap de capacité initiale plus grande et copier l'ancienne carte dans la nouvelle, puis exécuter à nouveau le test de vitesse de recherche sur la nouvelle carte.
- Rechercher dans le chapitre 8 l'exemple GreenhouseController.java, qui est composé de quatre fichiers. Dans Controller.java, la classe Controller utilise une ArrayList. Modifier le code pour qu'elle utilise une LinkedList à la place, et utiliser un Iterator pour passer en revue l'ensemble des événements.
- (Difficile). Écrire votre propre classe de carte de hachage, réduite à un type particulier de : String par exemple. Ne pas la faire hériter de Map. Au contraire, dupliquer les méthodes pour que les méthodes put( ) et get( ) utilisent des objets String et non des objets Object comme clé. Tout élément qui invoque des clés ne doit pas utiliser de types génériques; à la place, travailler avec des String afin d'éviter les coûts de transtypage ascendant et descendant. Le but est de rendre cette implémentation particulière la plus rapide possible. Modifier MapPerformance.java pour tester votre implémentation par rapport à une HashMap.
- (Difficile). Trouver le code source de List dans la bibliothèque de code source Java qui est présente dans toutes les distributions de Java. Copier ce code et créer une version spéciale appelée intList qui contient seulement des int. Réfléchissez au travail requis pour créer une version spéciale de List pour tous les types primitifs. Réfléchissez ensuite à ce qu'il arrivera quand on voudra créer une classe de liste chaînée qui fonctionne avec tous les types primitifs.
- Modifier c08:Month.java pour qu'elle implémente l'interface Comparable.
- Modifier hashCode( ) dans CountedString.java en supprimant la multiplication par id et démontrer que CountedString fonctionne toujours comme clé. Quel est le problème induit par cette approche ?