


3. Special Topics▲
3-0. Introduction▲
The mark of a professional appears in his or her attention to the finer points of the craft. In this section of the book we discuss advanced features of C++ along with development techniques used by polished C++ professionals.
Sometimes you may need to depart from the conventional wisdom of sound object-oriented design by inspecting the runtime type of an object. Most of the time you should let virtual functions do that job for you, but when writing special-purpose software tools, such as debuggers, database viewers, or class browsers, you'll need to determine type information at runtime. This is where the runtime type identification (RTTI) mechanism becomes useful. RTTI is the topic of Chapter 8.
Multiple inheritance has taken abuse over the years, and some languages don't even support it. Nonetheless, when used properly, it can be a powerful tool for crafting elegant, efficient code. A number of standard practices involving multiple inheritance have evolved over the years, which we present in Chapter 9.
Perhaps the most notable innovation in software development since object-oriented techniques is the use of design patterns. A design pattern describes solutions for many of the common problems involved in designing software, and can be applied in many situations and implemented in any language. In chapter 10 we describe a selected number of design patterns and implement them in C++.
Chapter 11 explains the benefits and challenges of multithreaded programming. The current version of Standard C++ does not specify support for threads, even though most operating systems provide them. We use a portable, freely available threading library to illustrate how C++ programmers can take advantage of threads to build more usable and responsive applications.
3-1. Runtime Type Identification▲
Runtime type identification (RTTI) lets you find the dynamic type of an object when you have only a pointer or a reference to the base type.
This can be thought of as a “secondary” feature in C++, pragmatism to help out when you get into rare difficult situations. Normally, you'll want to intentionally ignore the exact type of an object and let the virtual function mechanism implement the correct behavior for that type. On occasion, however, it's useful to know the exact runtime (that is, most derived) type of an object for which you only have a base pointer. With this information, you may perform a special-case operation more efficiently or prevent a base-class interface from becoming ungainly. It happens enough that most class libraries contain virtual functions to produce runtime type information. When exception handling was added to C++, that feature required information about the runtime type of objects, so it became an easy next step to build in access to that information. This chapter explains what RTTI is for and how to use it.
3-1-1. Runtime casts▲
One way to determine the runtime type of an object through a pointer or reference is to employ a runtime cast, which verifies that the attempted conversion is valid. This is useful when you need to cast a base-class pointer to a derived type. Since inheritance hierarchies are typically depicted with base classes above derived classes, such a cast is called a downcast.
Consider the following class hierarchy:
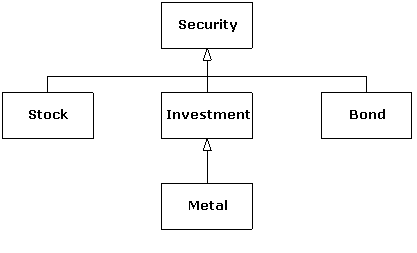
In the code that follows, the Investment class has an extra operation that the other classes do not, so it is important to be able to know at runtime whether a Security pointer refers to a Investment object or not. To implement checked runtime casts, each class keeps an integral identifier to distinguish it from other classes in the hierarchy.
//: C08:CheckedCast.cpp
// Checks casts at runtime.
#include <iostream>
#include <vector>
#include "../purge.h"
using namespace std;
class Security {
protected:
enum { BASEID = 0 };
public:
virtual ~Security() {}
virtual bool isA(int id) { return (id == BASEID); }
};
class Stock : public Security {
typedef Security Super;
protected:
enum { OFFSET = 1, TYPEID = BASEID + OFFSET };
public:
bool isA(int id) {
return id == TYPEID || Super::isA(id);
}
static Stock* dynacast(Security* s) {
return (s->isA(TYPEID)) ?
static_cast<Stock*>(s) : 0;
}
};
class Bond : public Security {
typedef Security Super;
protected:
enum { OFFSET = 2, TYPEID = BASEID + OFFSET };
public:
bool isA(int id) {
return id == TYPEID || Super::isA(id);
}
static Bond* dynacast(Security* s) {
return (s->isA(TYPEID)) ?
static_cast<Bond*>(s) : 0;
}
};
class Investment : public Security {
typedef Security Super;
protected:
enum { OFFSET = 3, TYPEID = BASEID + OFFSET };
public:
bool isA(int id) {
return id == TYPEID || Super::isA(id);
}
static Investment* dynacast(Security* s) {
return (s->isA(TYPEID)) ?
static_cast<Investment*>(s) : 0;
}
void special() {
cout << "special Investment
function" << endl;
}
};
class Metal : public Investment {
typedef Investment Super;
protected:
enum { OFFSET = 4, TYPEID = BASEID + OFFSET };
public:
bool isA(int id) {
return id == TYPEID || Super::isA(id);
}
static Metal* dynacast(Security* s) {
return (s->isA(TYPEID)) ?
static_cast<Metal*>(s) : 0;
}
};
int main() {
vector<Security*> portfolio;
portfolio.push_back(new Metal);
portfolio.push_back(new Investment);
portfolio.push_back(new Bond);
portfolio.push_back(new Stock);
for(vector<Security*>::iterator it =
portfolio.begin();
it != portfolio.end(); ++it) {
Investment* cm = Investment::dynacast(*it);
if(cm)
cm->special();
else
cout << "not an Investment"
<< endl;
}
cout << "cast from intermediate
pointer:" << endl;
Security* sp = new Metal;
Investment* cp = Investment::dynacast(sp);
if(cp) cout << " it's an Investment"
<< endl;
Metal* mp = Metal::dynacast(sp);
if(mp) cout << "
it's a Metal too!" << endl;
purge(portfolio);
} ///:~The polymorphic isA( ) function checks to see if its argument is compatible with its type argument (id), which means that either id matches the object's typeID exactly or it matches one of the object's ancestors (hence the call to Super::isA( ) in that case). The dynacast( ) function, which is static in each class, calls isA( ) for its pointer argument to check if the cast is valid. If isA( ) returns true, the cast is valid, and a suitably cast pointer is returned. Otherwise, the null pointer is returned, which tells the caller that the cast is not valid, meaning that the original pointer is not pointing to an object compatible with (convertible to) the desired type. All this machinery is necessary to be able to check intermediate casts, such as from a Security pointer that refers to a Metal object to a Investment pointer in the previous example program.(117)
For most programs downcasting is unnecessary, and is actually discouraged, since everyday polymorphism solves most problems in object-oriented application programs. However, the ability to check a cast to a more derived type is important for utility programs such as debuggers, class browsers, and databases. C++ provides such a checked cast with the dynamic_cast operator. The following program is a rewrite of the previous example using dynamic_cast:
//: C08:Security.h
#ifndef SECURITY_H
#define SECURITY_H
#include <iostream>
class Security {
public:
virtual ~Security() {}
};
class Stock : public Security {};
class Bond : public Security {};
class Investment : public Security {
public:
void special() {
std::cout << "special Investment
function” <<std::endl;
}
};
class Metal : public Investment {};
#endif // SECURITY_H ///:~//: C08:CheckedCast2.cpp
// Uses RTTI's dynamic_cast.
#include <vector>
#include "../purge.h"
#include "Security.h"
using namespace std;
int main() {
vector<Security*> portfolio;
portfolio.push_back(new Metal);
portfolio.push_back(new Investment);
portfolio.push_back(new Bond);
portfolio.push_back(new Stock);
for(vector<Security*>::iterator it =
portfolio.begin();
it != portfolio.end(); ++it) {
Investment* cm =
dynamic_cast<Investment*>(*it);
if(cm)
cm->special();
else
cout << "not a Investment"
<< endl;
}
cout << "cast from intermediate pointer:”
<< endl;
Security* sp = new Metal;
Investment* cp = dynamic_cast<Investment*>(sp);
if(cp) cout << " it's an Investment”
<< endl;
Metal* mp = dynamic_cast<Metal*>(sp);
if(mp) cout << " it's a Metal too!”
<< endl;
purge(portfolio);
} ///:~This example is much shorter, since most of the code in the original example was just the overhead for checking the casts. The target type of a dynamic_cast is placed in angle brackets, like the other new-style C++ casts (static_cast, and so on), and the object to cast appears as the operand. dynamic_cast requires that the types you use it with be polymorphic if you want safe downcasts.(118) This in turn requires that the class must have at least one virtual function. Fortunately, the Security base class has a virtual destructor, so we didn't have to invent an extra function to get the job done. Because dynamic_cast does its work at runtime, using the virtual table, it tends to be more expensive than the other new-style casts.
You can also use dynamic_cast with references instead of pointers, but since there is no such thing as a null reference, you need another way to know if the cast fails. That “other way” is to catch a bad_cast exception, as follows:
//: C08:CatchBadCast.cpp
#include <typeinfo>
#include "Security.h"
using namespace std;
int main() {
Metal m;
Security& s = m;
try {
Investment& c =
dynamic_cast<Investment&>(s);
cout << "It's an Investment"
<< endl;
} catch(bad_cast&) {
cout << "s is not an Investment
type" << endl;
}
try {
Bond& b = dynamic_cast<Bond&>(s);
cout << "It's a Bond" <<
endl;
} catch(bad_cast&) {
cout << "It's not a Bond type"
<< endl;
}
} ///:~The bad_cast class is defined in the <typeinfo> header, and, like most of the standard library, is declared in the std namespace.
3-1-2. The typeid operator▲
The other way to get runtime information for an object is through the typeid operator. This operator returns an object of class type_info, which yields information about the type of object to which it was applied. If the type is polymorphic, it gives information about the most derived type that applies (the dynamic type); otherwise it yields static type information. One use of the typeid operator is to get the name of the dynamic type of an object as a const char*, as you can see in the following example:
//: C08:TypeInfo.cpp
// Illustrates the typeid operator.
#include <iostream>
#include <typeinfo>
using namespace std;
struct PolyBase { virtual ~PolyBase() {} };
struct PolyDer : PolyBase { PolyDer() {} };
struct NonPolyBase {};
struct NonPolyDer : NonPolyBase { NonPolyDer(int) {} };
int main() {
// Test polymorphic Types
const PolyDer pd;
const PolyBase* ppb = &pd;
cout << typeid(ppb).name() << endl;
cout << typeid(*ppb).name() << endl;
cout << boolalpha << (typeid(*ppb) ==
typeid(pd))
<< endl;
cout << (typeid(PolyDer) == typeid(const
PolyDer))
<< endl;
// Test non-polymorphic Types
const NonPolyDer npd(1);
const NonPolyBase* nppb = &npd;
cout << typeid(nppb).name() << endl;
cout << typeid(*nppb).name() << endl;
cout << (typeid(*nppb) == typeid(npd)) <<
endl;
// Test a built-in type
int i;
cout << typeid(i).name() << endl;
} ///:~The output from this program using one particular compiler is
struct PolyBase const *
struct PolyDer
true
true
struct NonPolyBase const *
struct NonPolyBase
false
intThe first output line just echoes the static type of ppb because it is a pointer. To get RTTI to kick in, you need to look at the pointer or reference destination object, which is illustrated in the second line. Notice that RTTI ignores top-level const and volatile qualifiers. With non-polymorphic types, you just get the static type (the type of the pointer itself). As you can see, built-in types are also supported.
It turns out that you can't store the result of a typeid operation in a type_info object, because there are no accessible constructors and assignment is disallowed. You must use it as we have shown. In addition, the actual string returned by type_info::name( ) is compiler dependent. For a class named C, for example, some compilers return “class C” instead of just “C.” Applying typeid to an expression that dereferences a null pointer will cause a bad_typeid exception (also defined in <typeinfo>) to be thrown.
The following example shows that the class name that type_info::name( ) returns is fully qualified:
//: C08:RTTIandNesting.cpp
#include <iostream>
#include <typeinfo>
using namespace std;
class One {
class Nested {};
Nested* n;
public:
One() : n(new Nested) {}
~One() { delete n; }
Nested* nested() { return n; }
};
int main() {
One o;
cout << typeid(*o.nested()).name() <<
endl;
} ///:~Since Nested is a member type of the One class, the result is One::Nested.
You can also ask a type_info object if it precedes another type_info object in the implementation-defined “collation sequence” (the native ordering rules for text), using before(type_info&), which returns true or false. When you say,
if(typeid(me).before(typeid(you))) // ...you're asking if me occurs before you in the current collation sequence. This is useful if you use type_info objects as keys.
3-1-2-1. Casting to intermediate levels▲
As you saw in the earlier program that used the hierarchy of Security classes, dynamic_cast can detect both exact types and, in an inheritance hierarchy with multiple levels, intermediate types. Here is another example.
//: C08:IntermediateCast.cpp
#include <cassert>
#include <typeinfo>
using namespace std;
class B1 {
public:
virtual ~B1() {}
};
class B2 {
public:
virtual ~B2() {}
};
class MI : public B1, public B2 {};
class Mi2 : public MI {};
int main() {
B2* b2 = new Mi2;
Mi2* mi2 =
dynamic_cast<Mi2*>(b2);
MI* mi = dynamic_cast<MI*>(b2);
B1* b1 =
dynamic_cast<B1*>(b2);
assert(typeid(b2) != typeid(Mi2*));
assert(typeid(b2) == typeid(B2*));
delete b2;
} ///:~This example has the extra complication of multiple inheritance (you'll learn more about multiple inheritance later in this chapter, and in Chapter 9). If you create an Mi2 and upcast it to the root (in this case, one of the two possible roots is chosen), the dynamic_cast back to either of the derived levels MI or Mi2 is successful.
You can even cast from one root to the other:
B1* b1 = dynamic_cast<B1*>(b2);This is successful because B2 is actually pointing to a Mi2 object, which contains a subobject of type B1.
Casting to intermediate levels brings up an interesting difference between dynamic_cast and typeid. The typeid operator always produces a reference to a static type_info object that describes the dynamic type of the object. Thus, it doesn't give you intermediate-level information. In the following expression (which is true), typeid doesn't see b2 as a pointer to the derived type, like dynamic_cast does:
typeid(b2) != typeid(Mi2*)The type of b2 is simply the exact type of the pointer:
typeid(b2) == typeid(B2*)3-1-2-2. void pointers▲
RTTI only works for complete types, meaning that all class information must be available when typeid is used. In particular, it doesn't work with void pointers:
//: C08:VoidRTTI.cpp
// RTTI & void pointers.
//!include <iostream>
#include <typeinfo>
using namespace std;
class Stimpy {
public:
virtual void happy() {}
virtual void joy() {}
virtual ~Stimpy() {}
};
int main() {
void* v = new Stimpy;
// Error:
//! Stimpy* s = dynamic_cast<Stimpy*>(v);
// Error:
//! cout << typeid(*v).name() << endl;
} ///:~A void* truly means “no type information.”(119)
3-1-2-3. Using RTTI with templates▲
Class templates work well with RTTI, since all they do is generate classes. As usual, RTTI provides a convenient way to obtain the name of the class you're in. The following example prints the order of constructor and destructor calls:
//: C08:ConstructorOrder.cpp
// Order of constructor calls.
#include <iostream>
#include <typeinfo>
using namespace std;
template<int id> class Announce {
public:
Announce() {
cout << typeid(*this).name() << "
constructor" << endl;
}
~Announce() {
cout << typeid(*this).name() << "
destructor" << endl;
}
};
class X : public Announce<0> {
Announce<1> m1;
Announce<2> m2;
public:
X() { cout << "X::X()" << endl;
}
~X() { cout << "X::~X()" <<
endl; }
};
int main() { X x; } ///:~This template uses a constant int to differentiate one class from another, but type arguments would work as well. Inside both the constructor and destructor, RTTI information produces the name of the class to print. The class X uses both inheritance and composition to create a class that has an interesting order of constructor and destructor calls. The output is
Announce<0> constructor
Announce<1> constructor
Announce<2> constructor
X::X()
X::~X()
Announce<2> destructor
Announce<1> destructor
Announce<0> destructorOf course, you may get different output depending on how your compiler represents its name( ) information.
3-1-3. Multiple inheritance▲
The RTTI mechanisms must work properly with all the complexities of multiple inheritance, including virtual base classes (discussed in depth in the next chapter—you may want to come back here after reading Chapter 9):
//: C08:RTTIandMultipleInheritance.cpp
#include <iostream>
#include <typeinfo>
using namespace std;
class BB {
public:
virtual void f() {}
virtual ~BB() {}
};
class B1 : virtual public BB {};
class B2 : virtual public BB {};
class MI : public B1, public B2 {};
int main() {
BB* bbp = new MI; // Upcast
// Proper name detection:
cout << typeid(*bbp).name() << endl;
// Dynamic_cast works properly:
MI* mip = dynamic_cast<MI*>(bbp);
// Can't force old-style cast:
//! MI* mip2 = (MI*)bbp; // Compile error
} ///:~The typeid( ) operatorproperly detects the name of the actual object, even through the virtual base class pointer. The dynamic_cast also works correctly. But the compiler won't even allow you to try to force a cast the old way:
MI* mip = (MI*)bbp; // Compile-time errorThe compiler knows this is never the right thing to do, so it requires that you use a dynamic_cast.
3-1-4. Sensible uses for RTTI▲
Because you can discover type information from an anonymous polymorphic pointer, RTTI is ripe for misuse by the novice, because RTTI may make sense before virtual functions do. For many people coming from a procedural background, it's difficult not to organize programs into sets of switch statements. They could accomplish this with RTTI and thus lose the important value of polymorphism in code development and maintenance. The intent of C++ is that you use virtual functions throughout your code and that you only use RTTI when you must.
However, using virtual functions as they are intended requires that you have control of the base-class definition, because at some point in the extension of your program you may discover the base class doesn't include the virtual function you need. If the base class comes from a library or is otherwise controlled by someone else, one solution to the problem is RTTI; you can derive a new type and add your extra member function. Elsewhere in the code you can detect your particular type and call that member function. This doesn't destroy the polymorphism and extensibility of the program, because adding a new type will not require you to hunt for switch statements. However, when you add new code in the main body that requires your new feature, you'll have to detect your particular type.
Putting a feature in a base class might mean that, for the benefit of one particular class, all the other classes derived from that base require some meaningless stub for a pure virtual function. This makes the interface less clear and annoys those who must override pure virtual functions when they derive from that base class.
Finally, RTTI will sometimes solve efficiency problems. If your code uses polymorphism in a nice way, but it turns out that one of your objects reacts to this general-purpose code in a horribly inefficient way, you can pick that type out using RTTI and write case-specific code to improve the efficiency.
3-1-4-1. A trash recycler▲
To further illustrate a practical use of RTTI, the following program simulates a trash recycler. Different kinds of “trash” are inserted into a single container and then later sorted according to their dynamic types.
//: C08:Trash.h
// Describing trash.
#ifndef TRASH_H
#define TRASH_H
#include <iostream>
class Trash {
float _weight;
public:
Trash(float wt) : _weight(wt) {}
virtual float value() const = 0;
float weight() const { return _weight; }
virtual ~Trash() {
std::cout << "~Trash()" <<
std::endl;
}
};
class Aluminum : public Trash {
static float val;
public:
Aluminum(float wt) : Trash(wt) {}
float value() const { return val; }
static void value(float newval) {
val = newval;
}
};
class Paper : public Trash {
static float val;
public:
Paper(float wt) : Trash(wt) {}
float value() const { return val; }
static void value(float newval) {
val = newval;
}
};
class Glass : public Trash {
static float val;
public:
Glass(float wt) : Trash(wt) {}
float value() const { return val; }
static void value(float newval) {
val = newval;
}
};
#endif // TRASH_H ///:~The static values representing the price per unit of the trash types are defined in the implementation file:
//: C08:Trash.cpp {O}
// A Trash Recycler.
#include "Trash.h"
float Aluminum::val = 1.67;
float Paper::val = 0.10;
float Glass::val = 0.23;
///:~The sumValue( ) template iterates through a container, displaying and calculating results:
//: C08:Recycle.cpp
//{L} Trash
// A Trash Recycler.
#include <cstdlib>
#include <ctime>
#include <iostream>
#include <typeinfo>
#include <vector>
#include "Trash.h"
#include "../purge.h"
using namespace std;
// Sums up the value of the Trash in a bin:
template<class Container>
void sumValue(Container& bin, ostream& os) {
typename Container::iterator tally = bin.begin();
float val = 0;
while(tally != bin.end()) {
val += (*tally)->weight() *
(*tally)->value();
os << "weight of " <<
typeid(**tally).name()
<< " = " <<
(*tally)->weight() << endl;
++tally;
}
os << "Total value = " << val
<< endl;
}
int main() {
srand(time(0)); // Seed the random number generator
vector<Trash*> bin;
// Fill up the Trash bin:
for(int i = 0; i < 30; i++)
switch(rand() % 3) {
case 0 :
bin.push_back(new Aluminum((rand() %
1000)/10.0));
break;
case 1 :
bin.push_back(new Paper((rand() % 1000)/10.0));
break;
case 2 :
bin.push_back(new Glass((rand() % 1000)/10.0));
break;
}
// Note: bins hold exact type of object, not base
type:
vector<Glass*> glassBin;
vector<Paper*> paperBin;
vector<Aluminum*> alumBin;
vector<Trash*>::iterator sorter = bin.begin();
// Sort the Trash:
while(sorter != bin.end()) {
Aluminum* ap =
dynamic_cast<Aluminum*>(*sorter);
Paper* pp = dynamic_cast<Paper*>(*sorter);
Glass* gp = dynamic_cast<Glass*>(*sorter);
if(ap) alumBin.push_back(ap);
else if(pp) paperBin.push_back(pp);
else if(gp) glassBin.push_back(gp);
++sorter;
}
sumValue(alumBin, cout);
sumValue(paperBin, cout);
sumValue(glassBin, cout);
sumValue(bin, cout);
purge(bin);
} ///:~The trash is thrown unclassified into a single bin, so the specific type information is “lost.” But later the specific type information must be recovered to properly sort the trash, and so RTTI is used.
We can improve this solution by using a map that associates pointers to type_info objects with a vector of Trash pointers. Since a map requires an ordering predicate, we provide one named TInfoLess that calls type_info::before( ). As we insert Trash pointers into the map, they are automatically associated with their type_info key. Notice that sumValue( ) must be defined differently here:
//: C08:Recycle2.cpp
//{L} Trash
// Recyling with a map.
#include <cstdlib>
#include <ctime>
#include <iostream>
#include <map>
#include <typeinfo>
#include <utility>
#include <vector>
#include "Trash.h"
#include "../purge.h"
using namespace std;
// Comparator for type_info pointers
struct TInfoLess {
bool operator()(const type_info* t1, const type_info*
t2)
const { return t1->before(*t2); }
};
typedef map<const type_info*, vector<Trash*>,
TInfoLess>
TrashMap;
// Sums up the value of the Trash in a bin:
void sumValue(const TrashMap::value_type& p,
ostream& os) {
vector<Trash*>::const_iterator tally =
p.second.begin();
float val = 0;
while(tally != p.second.end()) {
val += (*tally)->weight() *
(*tally)->value();
os << "weight of "
<< p.first->name() //
type_info::name()
<< " = " <<
(*tally)->weight() << endl;
++tally;
}
os << "Total value = " << val
<< endl;
}
int main() {
srand(time(0)); // Seed the random number generator
TrashMap bin;
// Fill up the Trash bin:
for(int i = 0; i < 30; i++) {
Trash* tp;
switch(rand() % 3) {
case 0 :
tp = new Aluminum((rand() % 1000)/10.0);
break;
case 1 :
tp = new Paper((rand() % 1000)/10.0);
break;
case 2 :
tp = new Glass((rand() % 1000)/10.0);
break;
}
bin[&typeid(*tp)].push_back(tp);
}
// Print sorted results
for(TrashMap::iterator p = bin.begin();
p != bin.end(); ++p) {
sumValue(*p, cout);
purge(p->second);
}
} ///:~We've modified sumValue( ) to call type_info::name( ) directly, since the type_info object is now available as the first member of the TrashMap::value_type pair. This avoids the extra call to typeid to get the name of the type of Trash being processed that was necessary in the previous version of this program.
3-1-5. Mechanism and overhead of RTTI▲
Typically, RTTI is implemented by placing an additional pointer in a class's virtual function table. This pointer points to the type_info structure for that particular type. The effect of a typeid( ) expression is quite simple: the virtual function table pointer fetches the type_info pointer, and a reference to the resulting type_info structure is produced. Since this is just a two-pointer dereference operation, it is a constant time operation.
For a dynamic_cast<destination*>(source_pointer), most cases are quite straightforward: source_pointer's RTTI information is retrieved, and RTTI information for the type destination* is fetched. A library routine then determines whether source_pointer's type is of type destination* or a base class of destination*. The pointer it returns may be adjusted because of multiple inheritance if the base type isn't the first base of the derived class. The situation is more complicated with multiple inheritance because a base type may appear more than once in an inheritance hierarchy and virtual base classes are used.
Because the library routine used for dynamic_cast must check through a list of base classes, the overhead for dynamic_cast may be higher than typeid( ) (but you get different information, which may be essential to your solution), and it may take more time to discover a base class than a derived class. In addition, dynamic_cast compares any type to any other type; you aren't restricted to comparing types within the same hierarchy. This adds extra overhead to the library routine used by dynamic_cast.
3-1-6. Summary▲
Although normally you upcast a pointer to a base class and then use the generic interface of that base class (via virtual functions), occasionally you get into a corner where things can be more effective if you know the dynamic type of the object pointed to by a base pointer, and that's what RTTI provides. The most common misuse may come from the programmer who doesn't understand virtual functions and uses RTTI to do type-check coding instead. The philosophy of C++ seems to be to provide you with powerful tools and guard for type violations and integrity, but if you want to deliberately misuse or get around a language feature, there's nothing to stop you. Sometimes a slight burn is the fastest way to gain experience.
3-1-7. Exercises▲
Solutions to selected exercises can be found in the electronic document The Thinking in C++ Volume 2 Annotated Solution Guide, available for a small fee from www.MindView.net.
- Create a Base class with a virtual destructor and a Derived class that inherits from Base. Create a vector of Base pointers that point to Base and Derived objects randomly. Using the contents your vector, fill a second vector with all the Derived pointers. Compare execution times between typeid( ) and dynamic_cast to see which is faster.
- Modify C16:AutoCounter.h in Volume 1 of this book so that it becomes a useful debugging tool. It will be used as a nested member of each class that you are interested in tracing. Turn AutoCounter into a template that takes the class name of the surrounding class as the template argument, and in all the error messages use RTTI to print the name of the class.
- Use RTTI to assist in program debugging by printing out the exact name of a template using typeid( ). Instantiate the template for various types and see what the results are.
- Modify the Instrument hierarchy from Chapter 14 of Volume 1 by first copying Wind5.cpp to a new location. Now add a virtual clearSpitValve( ) function to the Wind class, and redefine it for all the classes inherited from Wind. Instantiate a vector to hold Instrument pointers, and fill it with various types of Instrument objects created using the new operator. Now use RTTI to move through the container looking for objects in class Wind, or derived from Wind. Call the clearSpitValve( ) function for these objects. Notice that it would unpleasantly confuse the Instrument base class if it contained a clearSpitValve( ) function.
- Modify the previous exercise to place a prepareInstrument( ) function in the base class, which calls appropriate functions (such as clearSpitValve( ), when it fits). Note that prepareInstrument( ) is a sensible function to place in the base class, and it eliminates the need for RTTI in the previous exercise.
- Create a vector of pointers to 10 random Shape objects (at least Squares and Circles, for example). The draw( ) member function should be overridden in each concrete class to print the dimensions of the object being drawn (the length or the radius, whichever applies). Write a main( ) program that draws all the Squares in your container first, sorted by length, and then draws all Circles, sorted by radius.
- Create a large vector of pointers to random Shape objects. Write a non-virtual draw( ) function in Shape that uses RTTI to determine the dynamic type of each object and executes the appropriate code to “draw” the object with a switch statement. Then rewrite your Shape hierarchy the “right way,” using virtual functions. Compare the code sizes and execution times of the two approaches.
- Create a hierarchy of Pet classes, including Dog, Cat, and Horse. Also create a hierarchy of Food classes: Beef, Fish, and Oats. The Dog class has a member function, eat( ), that takes a Beef parameter, likewise, Cat::eat( ) takes a Fish object, and Oats objects are passed to Horse::eat( ). Create a vector of pointers to random Pet objects, and visit each Pet, passing the correct type of Food object to its eat( ) function.
- Create a global function named drawQuad( ) that takes a reference to a Shape object. It calls the draw( ) function of its Shape parameter if it has four sides (that is, if it's a Square or Rectangle). Otherwise, it prints the message “Not a quadrilateral”. Traverse a vector of pointers to random Shapes, calling drawQuad( ) for each one. Place Squares, Rectangles, Circles and Triangles in your vector.
- Sort a vector of random Shape objects by class name. Use type_info::before( ) as the comparison function for sorting.
3-2. Multiple Inheritance▲
The basic concept of multiple inheritance (MI) sounds simple enough: you create a new type by inheriting from more than one base class. The syntax is exactly what you'd expect, and as long as the inheritance diagrams are simple, MI can be simple as well.
However, MI can introduce a number of ambiguities and strange situations, which are covered in this chapter. But first, it is helpful to get some perspective on the subject.
3-2-1. Perspective▲
Before C++, the most successful object-oriented language was Smalltalk. Smalltalk was created from the ground up as an object-oriented language. It is often referred to as pure, whereas C++ is called a hybrid language because it supports multiple programming paradigms, not just the object-oriented paradigm. One of the design decisions made with Smalltalk was that all classes would be derived in a single hierarchy, rooted in a single base class (called Object—this is the model for the object-based hierarchy).(120) You cannot create a new class in Smalltalk without deriving it from an existing class, which is why it takes a certain amount of time to become productive in Smalltalk: you must learn the class library before you can start making new classes. The Smalltalk class hierarchy is therefore a single monolithic tree.
Classes in Smalltalk usually have a number of things in common, and they always have some things in common (the characteristics and behaviors of Object), so you don't often run into a situation where you need to inherit from more than one base class. However, with C++ you can create as many distinct inheritance trees as you want. So for logical completeness the language must be able to combine more than one class at a time—thus the need for multiple inheritance.
It was not obvious, however, that programmers required multiple inheritance, and there was (and still is) a lot of disagreement about whether it is essential in C++. MI was added in AT&T cfront release 2.0 in 1989 and was the first significant change to the language over version 1.0.(121) Since then, a number of other features have been added to Standard C++ (notably templates) that change the way we think about programming and place MI in a much less important role. You can think of MI as a “minor” language feature that is seldom involved in your daily design decisions.
One of the most pressing arguments for MI involved containers. Suppose you want to create a container that everyone can easily use. One approach is to use void* as the type inside the container. The Smalltalk approach, however, is to make a container that holds Objects, since Object is the base type of the Smalltalk hierarchy. Because everything in Smalltalk is ultimately derived from Object, a container that holds Objects can hold anything.
Now consider the situation in C++. Suppose vendor A creates an object-based hierarchy that includes a useful set of containers including one you want to use called Holder. Next you come across vendor B's class hierarchy that contains some other class that is important to you, a BitImage class, for example, that holds graphic images. The only way to make a Holder of BitImages is to derive a new class from both Object, so it can be held in the Holder, and BitImage:
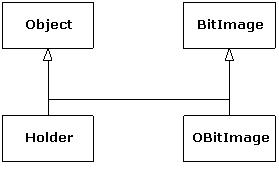
This was seen as an important reason for MI, and a number of class libraries were built on this model. However, as you saw in Chapter 5, the addition of templates has changed the way containers are created, so this situation is no longer a driving issue for MI.
The other reason you may need MI is related to design. You can intentionally use MI to make a design more flexible or useful (or at least seemingly so). An example of this is in the original iostream library design (which still persists in today's template design, as you saw in Chapter 4):
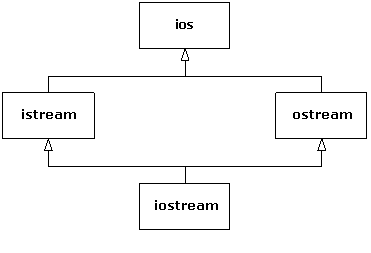
Both istream and ostream are useful classes by themselves, but they can also be derived from simultaneously by a class that combines both their characteristics and behaviors. The class ios provides what is common to all stream classes, and so in this case MI is a code-factoring mechanism.
Regardless of what motivates you to use MI, it's harder to use than it might appear.
3-2-2. Interface inheritance▲
One use of multiple inheritance that is not controversial pertains to interface inheritance. In C++, all inheritance is implementation inheritance, because everything in a base class, interface and implementation, becomes part of a derived class. It is not possible to inherit only part of a class (the interface alone, say). As Chapter 14 of Volume 1 explains, private and protected inheritance make it possible to restrict access to members inherited from base classes when used by clients of a derived class object, but this doesn't affect the derived class; it still contains all base class data and can access all non-private base class members.
Interface inheritance, on the other hand, only adds member function declarations to a derived class interface and is not directly supported in C++. The usual technique to simulate interface inheritance in C++ is to derive from an interface class, which is a class that contains only declarations (no data or function bodies). These declarations will be pure virtual functions, except for the destructor. Here is an example:
//: C09:Interfaces.cpp
// Multiple interface inheritance.
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
class Printable {
public:
virtual ~Printable() {}
virtual void print(ostream&) const = 0;
};
class Intable {
public:
virtual ~Intable() {}
virtual int toInt() const = 0;
};
class Stringable {
public:
virtual ~Stringable() {}
virtual string toString() const = 0;
};
class Able : public Printable, public Intable,
public Stringable {
int myData;
public:
Able(int x) { myData = x; }
void print(ostream& os) const { os <<
myData; }
int toInt() const { return myData; }
string toString() const {
ostringstream os;
os << myData;
return os.str();
}
};
void testPrintable(const Printable& p) {
p.print(cout);
cout << endl;
}
void testIntable(const Intable& n) {
cout << n.toInt() + 1 << endl;
}
void testStringable(const Stringable& s) {
cout << s.toString() + "th" <<
endl;
}
int main() {
Able a(7);
testPrintable(a);
testIntable(a);
testStringable(a);
} ///:~The class Able “implements” the interfaces Printable, Intable, and Stringable because it provides implementations for the functions they declare. Because Able derives from all three classes, Able objects have multiple “is-a” relationships. For example, the object a can act as a Printable object because its class, Able, derives publicly from Printable and provides an implementation for print( ). The test functions have no need to know the most-derived type of their parameter; they just need an object that is substitutable for their parameter's type.
As usual, a template solution is more compact:
//: C09:Interfaces2.cpp
// Implicit interface inheritance via templates.
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
class Able {
int myData;
public:
Able(int x) { myData = x; }
void print(ostream& os) const { os << myData;
}
int toInt() const { return myData; }
string toString() const {
ostringstream os;
os << myData;
return os.str();
}
};
template<class Printable>
void testPrintable(const Printable& p) {
p.print(cout);
cout << endl;
}
template<class Intable>
void testIntable(const Intable& n) {
cout << n.toInt() + 1 << endl;
}
template<class Stringable>
void testStringable(const Stringable& s) {
cout << s.toString() + "th" <<
endl;
}
int main() {
Able a(7);
testPrintable(a);
testIntable(a);
testStringable(a);
} ///:~The names Printable, Intable, and Stringable are now just template parameters that assume the existence of the operations indicated in their respective contexts. In other words, the test functions can accept arguments of any type that provides a member function definition with the correct signature and return type; deriving from a common base class in not necessary. Some people are more comfortable with the first version because the type names guarantee by inheritance that the expected interfaces are implemented. Others are content with the fact that if the operations required by the test functions are not satisfied by their template type arguments, the error is still caught at compile time. The latter approach is technically a “weaker” form of type checking than the former (inheritance) approach, but the effect on the programmer (and the program) is the same. This is one form of weak typing that is acceptable to many of today's C++ programmers.
3-2-3. Implementation inheritance▲
As we stated earlier, C++ provides only implementation inheritance, meaning that you always inherit everything from your base classes. This can be good because it frees you from having to implement everything in the derived class, as we had to do with the interface inheritance examples earlier. A common use of multiple inheritance involves using mixin classes, which are classes that exist to add capabilities to other classes through inheritance. Mixin classes are not intended to be instantiated by themselves.
As an example, suppose we are clients of a class that supports access to a database. In this scenario, you only have a header file available—part of the point here is that you don't have access to the source code for the implementation. For illustration, assume the following implementation of a Database class:
//: C09:Database.h
// A prototypical resource class.
#ifndef DATABASE_H
#define DATABASE_H
#include <iostream>
#include <stdexcept>
#include <string>
struct DatabaseError : std::runtime_error {
DatabaseError(const std::string& msg)
: std::runtime_error(msg) {}
};
class Database {
std::string dbid;
public:
Database(const std::string& dbStr) : dbid(dbStr)
{}
virtual ~Database() {}
void open() throw(DatabaseError) {
std::cout << "Connected to "
<< dbid << std::endl;
}
void close() {
std::cout << dbid << "
closed" << std::endl;
}
// Other database functions...
};
#endif // DATABASE_H ///:~We're leaving out actual database functionality (storing, retrieving, and so on), but that's not important here. Using this class requires a database connection string and that you call Database::open( ) to connect and Database::close( ) to disconnect:
//: C09:UseDatabase.cpp
#include "Database.h"
int main() {
Database db("MyDatabase");
db.open();
// Use other db functions...
db.close();
}
/* Output:
connected to MyDatabase
MyDatabase closed
*/ ///:~In a typical client-server situation, a client will have multiple objects sharing a connection to a database. It is important that the database eventually be closed, but only after access to it is no longer required. It is common to encapsulate this behavior through a class that tracks the number of client entities using the database connection and to automatically terminate the connection when that count goes to zero. To add reference counting to the Database class, we use multiple inheritance to mix a class named Countable into the Database class to create a new class, DBConnection. Here's the Countable mixin class:
//: C09:Countable.h
// A "mixin" class.
#ifndef COUNTABLE_H
#define COUNTABLE_H
#include <cassert>
class Countable {
long count;
protected:
Countable() { count = 0; }
virtual ~Countable() { assert(count == 0); }
public:
long attach() { return ++count; }
long detach() {
return (--count > 0) ? count : (delete this, 0);
}
long refCount() const { return count; }
};
#endif // COUNTABLE_H ///:~It is evident that this is not a standalone class because its constructor is protected; it requires a friend or a derived class to use it. It is important that the destructor is virtual, because it is called only from the delete this statement in detach( ), and we want derived objects to be properly destroyed.(122)
The DBConnection class inherits both Database and Countable and provides a static create( ) function that initializes its Countable subobject. This is an example of the Factory Method design pattern, discussed in the next chapter:
//: C09:DBConnection.h
// Uses a "mixin" class.
#ifndef DBCONNECTION_H
#define DBCONNECTION_H
#include <cassert>
#include <string>
#include "Countable.h"
#include "Database.h"
using std::string;
class DBConnection : public Database, public Countable
{
DBConnection(const DBConnection&); // Disallow
copy
DBConnection& operator=(const DBConnection&);
protected:
DBConnection(const string& dbStr)
throw(DatabaseError)
: Database(dbStr) { open(); }
~DBConnection() { close(); }
public:
static DBConnection*
create(const string& dbStr) throw(DatabaseError)
{
DBConnection* con = new DBConnection(dbStr);
con->attach();
assert(con->refCount() == 1);
return con;
}
// Other added functionality as desired...
};
#endif // DBCONNECTION_H ///:~We now have a reference-counted database connection without modifying the Database class, and we can safely assume that it will not be surreptitiously terminated. The opening and closing is done using the Resource Acquisition Is Initialization (RAII) idiom mentioned in Chapter 1 via the DBConnection constructor and destructor. This makes the DBConnection easy to use:
//: C09:UseDatabase2.cpp
// Tests the Countable "mixin" class.
#include <cassert>
#include "DBConnection.h"
class DBClient {
DBConnection* db;
public:
DBClient(DBConnection* dbCon) {
db = dbCon;
db->attach();
}
~DBClient() { db->detach(); }
// Other database requests using db…
};
int main() {
DBConnection* db =
DBConnection::create("MyDatabase");
assert(db->refCount() == 1);
DBClient c1(db);
assert(db->refCount() == 2);
DBClient c2(db);
assert(db->refCount() == 3);
// Use database, then release attach from original
create
db->detach();
assert(db->refCount() == 2);
} ///:~The call to DBConnection::create( ) calls attach( ), so when we're finished, we must explicitly call detach( ) to release the original hold on the connection. Note that the DBClient class also uses RAII to manage its use of the connection. When the program terminates, the destructors for the two DBClient objects will decrement the reference count (by calling detach( ), which DBConnection inherited from Countable), and the database connection will be closed (because of Countable's virtual destructor) when the count reaches zero after the object c1 is destroyed.
A template approach is commonly used for mixin inheritance, allowing the user to specify at compile time which flavor of mixin is desired. This way you can use different reference-counting approaches without explicitly defining DBConnection twice. Here's how it's done:
//: C09:DBConnection2.h
// A parameterized mixin.
#ifndef DBCONNECTION2_H
#define DBCONNECTION2_H
#include <cassert>
#include <string>
#include "Database.h"
using std::string;
template<class Counter>
class DBConnection : public Database, public Counter {
DBConnection(const DBConnection&); // Disallow
copy
DBConnection& operator=(const DBConnection&);
protected:
DBConnection(const string& dbStr)
throw(DatabaseError)
: Database(dbStr) { open(); }
~DBConnection() { close(); }
public:
static DBConnection* create(const string& dbStr)
throw(DatabaseError) {
DBConnection* con = new DBConnection(dbStr);
con->attach();
assert(con->refCount() == 1);
return con;
}
// Other added functionality as desired...
};
#endif // DBCONNECTION2_H ///:~The only change here is the template prefix to the class definition (and renaming Countable to Counter for clarity). We could also make the database class a template parameter (had we multiple database access classes to choose from), but it is not a mixin since it is a standalone class. The following example uses the original Countable as the Counter mixin type, but we could use any type that implements the appropriate interface (attach( ), detach( ), and so on):
//: C09:UseDatabase3.cpp
// Tests a parameterized "mixin" class.
#include <cassert>
#include "Countable.h"
#include "DBConnection2.h"
class DBClient {
DBConnection<Countable>* db;
public:
DBClient(DBConnection<Countable>* dbCon) {
db = dbCon;
db->attach();
}
~DBClient() { db->detach(); }
};
int main() {
DBConnection<Countable>* db =
DBConnection<Countable>::create("MyDatabase");
assert(db->refCount() == 1);
DBClient c1(db);
assert(db->refCount() == 2);
DBClient c2(db);
assert(db->refCount() == 3);
db->detach();
assert(db->refCount() == 2);
} ///:~The general pattern for multiple parameterized mixins is simply
template<class Mixin1, class Mixin2, … , class
MixinK>
class Subject : public Mixin1,
public Mixin2,
…
public MixinK {…};3-2-4. Duplicate subobjects▲
When you inherit from a base class, you get a copy of all the data members of that base class in your derived class. The following program shows how multiple base subobjects might be laid out in memory:(123)
//: C09:Offset.cpp
// Illustrates layout of subobjects with MI.
#include <iostream>
using namespace std;
class A { int x; };
class B { int y; };
class C : public A, public B { int z; };
int main() {
cout << "sizeof(A) == " <<
sizeof(A) << endl;
cout << "sizeof(B) == " <<
sizeof(B) << endl;
cout << "sizeof(C) == " <<
sizeof(C) << endl;
C c;
cout << "&c == " << &c
<< endl;
A* ap = &c;
B* bp = &c;
cout << "ap == " <<
static_cast<void*>(ap) << endl;
cout << "bp == " <<
static_cast<void*>(bp) << endl;
C* cp = static_cast<C*>(bp);
cout << "cp == " <<
static_cast<void*>(cp) << endl;
cout << "bp == cp? " <<
boolalpha << (bp == cp) << endl;
cp = 0;
bp = cp;
cout << bp << endl;
}
/* Output:
sizeof(A) == 4
sizeof(B) == 4
sizeof(C) == 12
&c == 1245052
ap == 1245052
bp == 1245056
cp == 1245052
bp == cp? true
0
*/ ///:~As you can see, the B portion of the object c is offset 4 bytes from the beginning of the entire object, suggesting the following layout:

The object c begins with it's A subobject, then the B portion, and finally the data from the complete type C itself. Since a C is-an A and is-a B, it is possible to upcast to either base type. When upcasting to an A, the resulting pointer points to the A portion, which happens to be at the beginning of the C object, so the address ap is the same as the expression &c. When upcasting to a B, however, the resulting pointer must point to where the B subobject actually resides because class B knows nothing about class C (or class A, for that matter). In other words, the object pointed to by bp must be able to behave as a standalone B object (except for any required polymorphic behavior).
When casting bp back to a C*, since the original object was a C in the first place, the location where the B subobject resides is known, so the pointer is adjusted back to the original address of the complete object. If bp had been pointing to a standalone B object instead of a C object in the first place, the cast would be illegal.(124) Furthermore, in the comparison bp == cp, cp is implicitly converted to a B*, since that is the only way to make the comparison meaningful (that is, upcasting is always allowed), hence the true result. So when converting back and forth between subobjects and complete types, the appropriate offset is applied.
The null pointer requires special handling, obviously, since blindly subtracting an offset when converting to or from a B subobject will result in an invalid address if the pointer was zero to start with. For this reason, when casting to or from a B*, the compiler generates logic to check first to see if the pointer is zero. If it isn't, it applies the offset; otherwise, it leaves it as zero.
With the syntax we've seen so far, if you have multiple base classes, and if those base classes in turn have a common base class, you will have two copies of the top-level base, as you can see in the following example:
//: C09:Duplicate.cpp
// Shows duplicate subobjects.
#include <iostream>
using namespace std;
class Top {
int x;
public:
Top(int n) { x = n; }
};
class Left : public Top {
int y;
public:
Left(int m, int n) : Top(m) { y = n; }
};
class Right : public Top {
int z;
public:
Right(int m, int n) : Top(m) { z = n; }
};
class Bottom : public Left, public Right {
int w;
public:
Bottom(int i, int j, int k, int m)
: Left(i, k), Right(j, k) { w = m; }
};
int main() {
Bottom b(1, 2, 3, 4);
cout << sizeof b << endl; // 20
} ///:~Since the size of b is 20 bytes,(125) there are five integers altogether in a complete Bottom object. A typical class diagram for this scenario usually appears as:
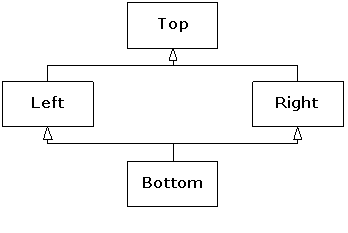
This is the so-called “diamond inheritance”, but in this case it would be better rendered as:
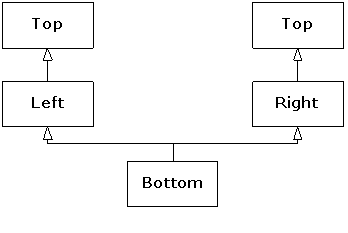
The awkwardness of this design surfaces in the constructor for the Bottom class in the previous code. The user thinks that only four integers are required, but which arguments should be passed to the two parameters that Left and Right require? Although this design is not inherently “wrong,” it is usually not what an application needs. It also presents a problem when trying to convert a pointer to a Bottom object to a pointer to Top. As we showed earlier, the address may need to be adjusted, depending on where the subobject resides within the complete object, but here there are two Top subobjects to choose from. The compiler doesn't know which to choose, so such an upcast is ambiguous and is not allowed. The same reasoning explains why a Bottom object would not be able to call a function that is only defined in Top. If such a function Top::f( ) existed, calling b.f( ) above would need to refer to a Top subobject as an execution context, and there are two to choose from.
3-2-5. Virtual base classes▲
What we usually want in such cases is true diamond inheritance, where a single Top object is shared by both Left and Right subobjects within a complete Bottom object, which is what the first class diagram depicts. This is achieved by making Top a virtual base class of Left and Right:
//: C09:VirtualBase.cpp
// Shows a shared subobject via a virtual base.
#include <iostream>
using namespace std;
class Top {
protected:
int x;
public:
Top(int n) { x = n; }
virtual ~Top() {}
friend ostream&
operator<<(ostream& os, const Top& t) {
return os << t.x;
}
};
class Left : virtual public Top {
protected:
int y;
public:
Left(int m, int n) : Top(m) { y = n; }
};
class Right : virtual public Top {
protected:
int z;
public:
Right(int m, int n) : Top(m) { z = n; }
};
class Bottom : public Left, public Right {
int w;
public:
Bottom(int i, int j, int k, int m)
: Top(i), Left(0, j), Right(0, k) { w = m; }
friend ostream&
operator<<(ostream& os, const Bottom&
b) {
return os << b.x << ',' << b.y
<< ',' << b.z
<< ',' << b.w;
}
};
int main() {
Bottom b(1, 2, 3, 4);
cout << sizeof b << endl;
cout << b << endl;
cout << static_cast<void*>(&b)
<< endl;
Top* p = static_cast<Top*>(&b);
cout << *p << endl;
cout << static_cast<void*>(p) <<
endl;
cout << dynamic_cast<void*>(p) <<
endl;
} ///:~Each virtual base of a given type refers to the same object, no matter where it appears in the hierarchy.(126) This means that when a Bottom object is instantiated, the object layout may look something like this:
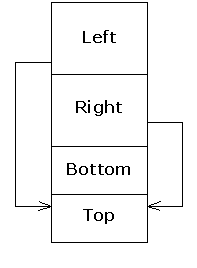
The Left and Right subobjects each have a pointer (or some conceptual equivalent) to the shared Top subobject, and all references to that subobject in Left and Right member functions will go through those these pointers.(127) Here, there is no ambiguity when upcasting from a Bottom to a Top object, since there is only one Top object to convert to.
The output of the previous program is as follows:
36
1,2,3,4
1245032
1
1245060
1245032The addresses printed suggest that this particular implementation does indeed store the Top subobject at the end of the complete object (although it's not really important where it goes). The result of a dynamic_cast to void* always resolves to the address of the complete object.
Although it is technically illegal to do so(128), if you remove the virtual destructor (and the dynamic_cast statement, so the program will compile), the size of Bottom decreases to 24 bytes. That seems to be a decrease equivalent to the size of three pointers. Why?
It's important not to take these numbers too literally. Other compilers we use manage only to increase the size by four bytes when the virtual constructor is added. Not being compiler writers, we can't tell you their secrets. We can tell you, however, that with multiple inheritance, a derived object must behave as if it has multiple VPTRs, one for each of its direct base classes that also have virtual functions. It's as simple as that. Compilers make whatever optimizations their authors invent, but the behavior must be the same.
The strangest thing in the previous code is the initializer for Top in the Bottom constructor. Normally one doesn't worry about initializing subobjects beyond direct base classes, since all classes take care of initializing their own bases. There are, however, multiple paths from Bottom to Top, so relying on the intermediate classes Left and Right to pass along the necessary initialization data results in an ambiguity—who is responsible for performing the initialization? For this reason, the most derived class must initialize a virtual base. But what about the expressions in the Left and Right constructors that also initialize Top? They are certainly necessary when creating standalone Left or Right objects, but must be ignored when a Bottom object is created (hence the zeros in their initializers in the Bottom constructor—any values in those slots are ignored when the Left and Right constructors execute in the context of a Bottom object). The compiler takes care of all this for you, but it's important to understand where the responsibility lies. Always make sure that all concrete (nonabstract) classes in a multiple inheritance hierarchy are aware of any virtual bases and initialize them appropriately.
These rules of responsibility apply not only to initialization, but to all operations that span the class hierarchy. Consider the stream inserter in the previous code. We made the data protected so we could “cheat” and access inherited data in operator<<(ostream&, const Bottom&). It usually makes more sense to assign the work of printing each subobject to its corresponding class and have the derived class call its base class functions as needed. What would happen if we tried that with operator<<( ), as the following code illustrates?
//: C09:VirtualBase2.cpp
// How NOT to implement operator<<.
#include <iostream>
using namespace std;
class Top {
int x;
public:
Top(int n) { x = n; }
virtual ~Top() {}
friend ostream& operator<<(ostream& os,
const Top& t) {
return os << t.x;
}
};
class Left : virtual public Top {
int y;
public:
Left(int m, int n) : Top(m) { y = n; }
friend ostream& operator<<(ostream& os,
const Left& l) {
return os << static_cast<const
Top&>(l) << ',' << l.y;
}
};
class Right : virtual public Top {
int z;
public:
Right(int m, int n) : Top(m) { z = n; }
friend ostream& operator<<(ostream& os,
const Right& r) {
return os << static_cast<const
Top&>(r) << ',' << r.z;
}
};
class Bottom : public Left, public Right {
int w;
public:
Bottom(int i, int j, int k, int m)
: Top(i), Left(0, j), Right(0, k) { w = m; }
friend ostream& operator<<(ostream& os,
const Bottom& b){
return os << static_cast<const
Left&>(b)
<< ',' << static_cast<const
Right&>(b)
<< ',' << b.w;
}
};
int main() {
Bottom b(1, 2, 3, 4);
cout << b << endl; // 1,2,1,3,4
} ///:~You can't just blindly share the responsibility upward in the usual fashion, because the Left and Right stream inserters each call the Top inserter, and again there will be duplication of data. Instead you need to mimic what the compiler does with initialization. One solution is to provide special functions in the classes that know about the virtual base class, which ignore the virtual base when printing (leaving the job to the most derived class):
//: C09:VirtualBase3.cpp
// A correct stream inserter.
#include <iostream>
using namespace std;
class Top {
int x;
public:
Top(int n) { x = n; }
virtual ~Top() {}
friend ostream& operator<<(ostream& os,
const Top& t) {
return os << t.x;
}
};
class Left : virtual public Top {
int y;
protected:
void specialPrint(ostream& os) const {
// Only print Left's part
os << ','<< y;
}
public:
Left(int m, int n) : Top(m) { y = n; }
friend ostream& operator<<(ostream& os,
const Left& l) {
return os << static_cast<const
Top&>(l) << ',' << l.y;
}
};
class Right : virtual public Top {
int z;
protected:
void specialPrint(ostream& os) const {
// Only print Right's part
os << ','<< z;
}
public:
Right(int m, int n) : Top(m) { z = n; }
friend ostream& operator<<(ostream& os,
const Right& r) {
return os << static_cast<const
Top&>(r) << ',' << r.z;
}
};
class Bottom : public Left, public Right {
int w;
public:
Bottom(int i, int j, int k, int m)
: Top(i), Left(0, j), Right(0, k) { w = m; }
friend ostream& operator<<(ostream& os,
const Bottom& b){
os << static_cast<const Top&>(b);
b.Left::specialPrint(os);
b.Right::specialPrint(os);
return os << ','
<< b.w;
}
};
int main() {
Bottom b(1, 2, 3, 4);
cout << b << endl; // 1,2,3,4
} ///:~The specialPrint( ) functions are protected since they will be called only by Bottom. They print only their own data and ignore their Top subobject because the Bottom inserter is in control when these functions are called. The Bottom inserter must know about the virtual base, just as a Bottom constructor needs to. This same reasoning applies to assignment operators in a hierarchy with a virtual base, as well as to any function, member or not, that wants to share the work throughout all classes in the hierarchy.
Having discussed virtual base classes, we can now illustrate the “full story” of object initialization. Since virtual bases give rise to shared subobjects, it makes sense that they should be available before the sharing takes place. So the order of initialization of subobjects follows these rules, recursively:
- All virtual base class subobjects are initialized, in top-down, left-to-right order according to where they appear in class definitions.
- Non-virtual base classes are then initialized in the usual order.
- All member objects are initialized in declaration order.
- The complete object's constructor executes.
The following program illustrates this behavior:
//: C09:VirtInit.cpp
// Illustrates initialization order with virtual bases.
#include <iostream>
#include <string>
using namespace std;
class M {
public:
M(const string& s) { cout << "M "
<< s << endl; }
};
class A {
M m;
public:
A(const string& s) : m("in A") {
cout << "A " << s <<
endl;
}
virtual ~A() {}
};
class B {
M m;
public:
B(const string& s) : m("in B") {
cout << "B " << s <<
endl;
}
virtual ~B() {}
};
class C {
M m;
public:
C(const string& s) : m("in C") {
cout << "C " << s <<
endl;
}
virtual ~C() {}
};
class D {
M m;
public:
D(const string& s) : m("in D") {
cout << "D " << s <<
endl;
}
virtual ~D() {}
};
class E : public A, virtual public B, virtual public C
{
M m;
public:
E(const string& s) : A("from E"),
B("from E"),
C("from E"), m("in
E") {
cout << "E "
<< s << endl;
}
};
class F : virtual public B, virtual public C, public D
{
M m;
public:
F(const string& s) : B("from F"),
C("from F"),
D("from F"), m("in F") {
cout << "F " << s <<
endl;
}
};
class G : public E, public F {
M m;
public:
G(const string& s) : B("from G"),
C("from G"),
E("from G"), F("from G"),
m("in G") {
cout << "G " << s <<
endl;
}
};
int main() {
G g("from main");
} ///:~The classes in this code can be represented by the following diagram:
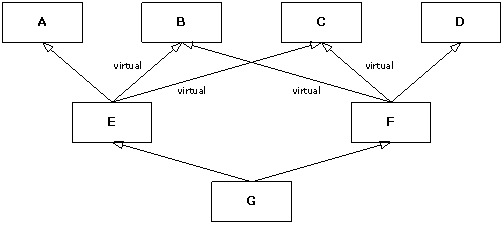
Each class has an embedded member of type M. Note that only four derivations are virtual: E from B and C, and F from B and C. The output of this program is:
M in B
B from G
M in C
C from G
M in A
A from E
M in E
E from G
M in D
D from F
M in F
F from G
M in G
G from mainThe initialization of g requires its E and F part to first be initialized, but the B and C subobjects are initialized first because they are virtual bases and are initialized from G's initializer, G being the most-derived class. The class B has no base classes, so according to rule 3, its member object m is initialized, then its constructor prints “B from G”, and similarly for the C subject of E. The E subobject requires A, B, and C subobjects. Since B and C have already been initialized, the A subobject of the E subobject is initialized next, and then the E subobject itself. The same scenario repeats for g's F subobject, but without duplicating the initialization of the virtual bases.
3-2-6. Name lookup issues▲
The ambiguities we have illustrated with subobjects apply to any names, including function names. If a class has multiple direct base classes that share member functions of the same name, and you call one of those member functions, the compiler doesn't know which one to choose. The following sample program would report such an error:
//: C09:AmbiguousName.cpp {-xo}
class Top {
public:
virtual ~Top() {}
};
class Left : virtual public Top {
public:
void f() {}
};
class Right : virtual public Top {
public:
void f() {}
};
class Bottom : public Left, public Right {};
int main() {
Bottom b;
b.f(); // Error here
} ///:~The class Bottom has inherited two functions of the same name (the signature is irrelevant, since name lookup occurs before overload resolution), and there is no way to choose between them. The usual technique to disambiguate the call is to qualify the function call with the base class name:
//: C09:BreakTie.cpp
class Top {
public:
virtual ~Top() {}
};
class Left : virtual public Top {
public:
void f() {}
};
class Right : virtual public Top {
public:
void f() {}
};
class Bottom : public Left, public Right {
public:
using Left::f;
};
int main() {
Bottom b;
b.f(); // Calls Left::f()
} ///:~The name Left::f is now found in the scope of Bottom, so the name Right::f is not even considered. To introduce extra functionality beyond what Left::f( ) provides, you implement a Bottom::f( ) function that calls Left::f( ).
Functions with the same name occurring in different branches of a hierarchy often conflict. The following hierarchy has no such problem:
//: C09:Dominance.cpp
class Top {
public:
virtual ~Top() {}
virtual void f() {}
};
class Left : virtual public Top {
public:
void f() {}
};
class Right : virtual public Top {};
class Bottom : public Left, public Right {};
int main() {
Bottom b;
b.f(); // Calls Left::f()
} ///:~Here, there is no explicit Right::f( ). Since Left::f( ) is the most derived, it is chosen. Why? Well, pretend that Right did not exist, giving the single-inheritance hierarchy Top <= Left <= Bottom. You would certainly expect Left::f( ) to be the function called by the expression b.f( ) because of normal scope rules: a derived class is considered a nested scope of a base class. In general, a name A::fdominates the name B::f if A derives from B, directly or indirectly, or in other words, if A is “more derived” in the hierarchy than B.(129) Therefore, in choosing between two functions with the same name, the compiler chooses the one that dominates. If there is no dominant name, there is an ambiguity.
The following program further illustrates the dominance principle:
//: C09:Dominance2.cpp
#include <iostream>
using namespace std;
class A {
public:
virtual ~A() {}
virtual void f() { cout << "A::f\n";
}
};
class B : virtual public A {
public:
void f() { cout << "B::f\n"; }
};
class C : public B {};
class D : public C, virtual public A {};
int main() {
B* p = new D;
p->f(); // Calls B::f()
delete p;
} ///:~The class diagram for this hierarchy is
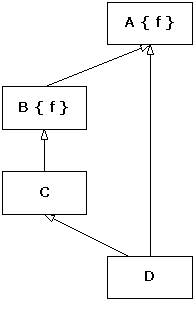
The class A is a (direct, in this case) base class for B, and so the name B::f dominates A::f.
3-2-7. Avoiding MI▲
When the question of whether to use multiple inheritance comes up, ask at least two questions:
- Do you need to show the public interfaces of both these classes through your new type? (See instead if one class can be contained within the other, with only some of its interface exposed in the new class.)
- Do you need to upcast to both of the base classes? (This also applies when you have more than two base classes.)
If you can answer “no” to either question, you can avoid using MI and should probably do so.
Watch for the situation where one class needs to be upcast only as a function argument. In that case, the class can be embedded and an automatic type conversion function provided in your new class to produce a reference to the embedded object. Any time you use an object of your new class as an argument to a function that expects the embedded object, the type conversion function is used.(130) However, type conversion can't be used for normal polymorphic member function selection; that requires inheritance. Preferring composition over inheritance is a good overall design guideline.
3-2-8. Extending an interface▲
One of the best uses for multiple inheritance involves code that's out of your control. Suppose you've acquired a library that consists of a header file and compiled member functions, but no source code for member functions. This library is a class hierarchy with virtual functions, and it contains some global functions that take pointers to the base class of the library; that is, it uses the library objects polymorphically. Now suppose you build an application around this library and write your own code that uses the base class polymorphically.
Later in the development of the project or sometime during its maintenance, you discover that the base-class interface provided by the vendor doesn't provide what you need: a function may be non-virtual and you need it to be virtual, or a virtual function is completely missing in the interface, but essential to the solution of your problem. Multiple inheritance can be the solution.
For example, here's the header file for a library you acquire:
//: C09:Vendor.h
// Vendor-supplied class header
// You only get this & the compiled Vendor.obj.
#ifndef VENDOR_H
#define VENDOR_H
class Vendor {
public:
virtual void v() const;
void f() const; // Might want this to be virtual...
~Vendor(); // Oops! Not virtual!
};
class Vendor1 : public Vendor {
public:
void v() const;
void f() const;
~Vendor1();
};
void A(const Vendor&);
void B(const Vendor&);
// Etc.
#endif // VENDOR_H ///:~Assume the library is much bigger, with more derived classes and a larger interface. Notice that it also includes the functions A( ) and B( ), which take a base reference and treat it polymorphically. Here's the implementation file for the library:
//: C09:Vendor.cpp {O}
// Assume this is compiled and unavailable to you.
#include "Vendor.h"
#include <iostream>
using namespace std;
void Vendor::v() const { cout <<
"Vendor::v()" << endl; }
void Vendor::f() const { cout <<
"Vendor::f()" << endl; }
Vendor::~Vendor() { cout << "~Vendor()"
<< endl; }
void Vendor1::v() const { cout <<
"Vendor1::v()" << endl; }
void Vendor1::f() const { cout <<
"Vendor1::f()" << endl; }
Vendor1::~Vendor1() { cout <<
"~Vendor1()" << endl; }
void A(const Vendor& v) {
// ...
v.v();
v.f();
// ...
}
void B(const Vendor& v) {
// ...
v.v();
v.f();
// ...
} ///:~In your project, this source code is unavailable to you. Instead, you get a compiled file as Vendor.obj or Vendor.lib (or with the equivalent file suffixes for your system).
The problem occurs in the use of this library. First, the destructor isn't virtual.(131) In addition, f( ) was not made virtual; we assume the library creator decided it wouldn't need to be. You also discover that the interface to the base class is missing a function essential to the solution of your problem. Also suppose you've already written a fair amount of code using the existing interface (not to mention the functions A( ) and B( ), which are out of your control), and you don't want to change it.
To repair the problem, create your own class interface and multiply inherit a new set of derived classes from your interface and from the existing classes:
//: C09:Paste.cpp
//{L} Vendor
// Fixing a mess with MI.
#include <iostream>
#include "Vendor.h"
using namespace std;
class MyBase { // Repair Vendor interface
public:
virtual void v() const = 0;
virtual void f() const = 0;
// New interface function:
virtual void g() const = 0;
virtual ~MyBase() { cout <<
"~MyBase()" << endl; }
};
class Paste1 : public MyBase, public Vendor1 {
public:
void v() const {
cout << "Paste1::v()" <<
endl;
Vendor1::v();
}
void f() const {
cout << "Paste1::f()" <<
endl;
Vendor1::f();
}
void g() const { cout << "Paste1::g()”
<< endl; }
~Paste1() { cout << "~Paste1()” <<
endl; }
};
int main() {
Paste1& p1p = *new Paste1;
MyBase& mp = p1p; // Upcast
cout << "calling f()” << endl;
mp.f(); // Right behavior
cout << "calling g()” << endl;
mp.g(); // New behavior
cout << "calling A(p1p)” << endl;
A(p1p); // Same old behavior
cout << "calling B(p1p)” << endl;
B(p1p); // Same old behavior
cout << "delete mp” << endl;
// Deleting a reference to a heap object:
delete ∓ // Right behavior
} ///:~In MyBase (which does not use MI), both f( ) and the destructor are now virtual, and a new virtual function g( ) is added to the interface. Now each of the derived classes in the original library must be re-created, mixing in the new interface with MI. The functions Paste1::v( ) and Paste1::f( ) need to call only the original base-class versions of their functions. But now, if you upcast to MyBase as in main( ):
MyBase* mp = p1p; // Upcastany function calls made through mp will be polymorphic, including delete. Also, the new interface function g( ) can be called through mp. Here's the output of the program:
calling f()
Paste1::f()
Vendor1::f()
calling g()
Paste1::g()
calling A(p1p)
Paste1::v()
Vendor1::v()
Vendor::f()
calling B(p1p)
Paste1::v()
Vendor1::v()
Vendor::f()
delete mp
~Paste1()
~Vendor1()
~Vendor()
~MyBase()The original library functions A( ) and B( ) still work the same (assuming the new v( ) calls its base-class version). The destructor is now virtual and exhibits the correct behavior.
Although this is a messy example, it does occur in practice, and it's a good demonstration of where multiple inheritance is clearly necessary: You must be able to upcast to both base classes.
3-2-9. Summary▲
One reason MI exists in C++ is that it is a hybrid language and couldn't enforce a single monolithic class hierarchy the way Smalltalk and Java do. Instead, C++ allows many inheritance trees to be formed, so sometimes you may need to combine the interfaces from two or more trees into a new class.
If no “diamonds” appear in your class hierarchy, MI is fairly simple (although identical function signatures in base classes must still be resolved). If a diamond appears, you may want to eliminate duplicate subobjects by introducing virtual base classes. This not only adds confusion, but the underlying representation becomes more complex and less efficient.
Multiple inheritance has been called the “goto of the '90s.”(132) This seems appropriate because, like a goto, MI is best avoided in normal programming, but can occasionally be very useful. It's a “minor” but more advanced feature of C++, designed to solve problems that arise in special situations. If you find yourself using it often, you might want to take a look at your reasoning. Ask yourself, “Must I upcast to all the base classes?” If not, your life will be easier if you embed instances of all the classes you don't need to upcast to.
3-2-10. Exercises▲
- Solutions to selected exercises can be found in the electronic document The Thinking in C++ Volume 2 Annotated Solution Guide, available for a small fee from www.MindView.net.
- Create a base class X with a single constructor that takes an int argument and a member function f( ), which takes no arguments and returns void. Now derive Y and Z from X, creating constructors for each of them that take a single int argument. Next, derive A from Y and Z. Create an object of class A, and call f( ) for that object. Fix the problem with explicit disambiguation.
- Starting with the results of Exercise 1, create a pointer to an X called px and assign to it the address of the object of type A you created before. Fix the problem using a virtual base class. Now fix X so you no longer have to call the constructor for X inside A.
- Starting with the results of Exercise 2, remove the explicit disambiguation for f( ) and see if you can call f( ) through px. Trace it to see which function gets called. Fix the problem so the correct function will be called in a class hierarchy.
- Make an Animal interface class with a makeNoise( ) function declaration. Make a SuperHero interface class with a savePersonFromFire( ) function declaration. Place a move( ) function declaration in both interface classes. (Remember to make your interface methods pure virtual.) Now define three separate classes: SuperlativeMan, Amoeba (a superhero of uncertain gender), and TarantulaWoman; SuperlativeMan implements the SuperHero interface while Amoeba and TarantulaWoman implement both Animal and SuperHero. Define two global functions animalSound(Animal*) and saveFromFire(SuperHero*). Invoke all the methods that are callable from each interface in both of these functions.
- Repeat the previous exercise, but use templates instead of inheritance to implement the interfaces, as we did in Interfaces2.cpp.
- Define some concrete mixin classes that represent superhero capabilities (such as StopTrain, BendSteel, ClimbBuilding, etc.). Redo exercise 4 so that your derived SuperHero classes derive from these mixins and call their member functions.
- Repeat the previous exercise using templates by making your superhero powers mixin template parameters. Use these powers to do some good in the community.
- Dropping the Animal interface from exercise 4, redefine Amoeba to only implement SuperHero. Now define a SuperlativeAmoeba class that inherits from both SuperlativeMan and Amoeba. Try to pass a SuperlativeAmoeba object to saveFromFire( ). What do you have to do to make this legal? How does using virtual inheritance change the size of your objects?
- Continuing with the previous exercise, add an integer strengthFactor data member to SuperHero from exercise 4, along with a constructor to initialize it. Add constructors in the three derived classes to initialize strengthFactor as well. What must you do differently in SuperlativeAmoeba?
- Continuing with the previous exercise, add an eatFood( ) member function to both SuperlativeMan and Amoeba (but not SuperlativeAmoeba), such that the two versions of eatFood( ) take different types of food objects (so the signatures of the two functions differ). What must you do in SuperlativeAmoeba to call either eatFood( ) function? Why?
- Define a well-behaved output stream inserter and assignment operator for SuperlativeAmoeba.
- Remove SuperlativeAmoeba from your hierarchy and modify Amoeba to derive from both SuperlativeMan (which still derives from SuperHero) and SuperHero. Implement a virtual workout( ) function in both SuperHero and SuperlativeMan (with identical signatures), and call it with a Amoeba object. Which function gets called?
- Redefine SuperlativeAmoeba to use composition instead of inheritance to act as a SuperlativeMan or Amoeba. Use conversion operators to provide implicit upcasting. Compare this approach to the inheritance approach.
- Suppose you are given a pre-compiled Person class (you only have the header and compiled object file). Suppose also that Person has a non-virtual work( ) function. Have SuperHero be able to act as a mild-mannered ordinary Person by deriving from Person and using the implementation of Person::work( ), but make SuperHero::work( ) virtual.
- Define a reference-counted error logging mixin class, ErrorLog, that holds a static file stream to which you can send messages. The class opens the stream when its reference count exceeds 0 and closes the stream when the count returns to 0 (and always appends to the file). Have objects of multiple classes send messages to the static log stream. Watch the stream open and close via trace statements in ErrorLog.
- Modify BreakTie.cpp by adding a class named VeryBottom that derives (non-virtually) from Bottom. VeryBottom should look just like Bottom except change “Left” to “Right” in the using declaration for f. Change main( ) to instantiate a VeryBottom instead of a Bottom object. Which f( ) gets called?
3-3. Design Patterns▲
“… describe a problem which occurs over and over again in our environment, and then describe the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice”—Christopher Alexander
This chapter introduces the important and yet nontraditional “patterns” approach to program design.
The most important recent step forward in object-oriented design is probably the “design patterns” movement, initially chronicled in Design Patterns, by Gamma, Helm, Johnson & Vlissides (Addison Wesley, 1995),(133) which is commonly called the “Gang of Four” book (GoF). GoF shows 23 solutions to particular classes of problems. In this chapter, we discuss the basic concepts of design patterns and provide code examples that illustrate selected patterns. This should whet your appetite for reading more about design patterns, a source of what has now become an essential, almost mandatory vocabulary for object-oriented programming.(134)
3-3-1. The pattern concept▲
Initially, you can think of a pattern as an especially clever and insightful way to solve a particular class of problem. It appears that a team of people have worked out all the angles of a problem and have come up with the most general, flexible solution for that type of problem. This problem could be one that you have seen and solved before, but your solution probably didn't have the kind of completeness you'll see embodied in a pattern. Furthermore, the pattern exists independently of any particular implementation and it can be implemented in a number of ways.
Although they're called “design patterns,” they really aren't tied to the realm of design. A pattern seems to stand apart from the traditional way of thinking about analysis, design, and implementation. Instead, a pattern embodies a complete idea within a program, and thus it might also span the analysis phase and high-level design phase. However, because a pattern often has a direct implementation in code, it might not show up until low-level design or implementation (and you might not realize that you need a particular pattern until you get to those phases).
The basic concept of a pattern can also be seen as the basic concept of program design in general: adding layers of abstraction. Whenever you abstract something, you're isolating particular details, and one of the most compelling motivations for this is to separate things that change from things that stay the same. Another way to put this is that once you find some part of your program that's likely to change, you'll want to keep those changes from propagating side effects throughout your code. If you achieve this, your code will not only be easier to read and understand, but also easier to maintain—which invariably results in lowered costs over time.
The most difficult part of developing an elegant and maintainable design is often discovering what we call “the vector of change.” (Here, “vector” refers to the maximum gradient as understood in the sciences, and not a container class.) This means finding the most important thing that changes in your system or, put another way, discovering where your greatest cost is. Once you discover the vector of change, you have the focal point around which to structure your design.
So the goal of design patterns is to encapsulate change. If you look at it this way, you've been seeing some design patterns already in this book. For example, inheritance could be thought of as a design pattern (albeit one implemented by the compiler). It expresses differences in behavior (that's the thing that changes) in objects that all have the same interface (that's what stays the same). Composition could also be considered a pattern, since you can change—dynamically or statically—the objects that implement your class, and thus the way that class works. Normally, however, features that are directly supported by a programming language have not been classified as design patterns.
You've also already seen another pattern that appears in GoF: the iterator. This is the fundamental tool used in the design of the STL, described earlier in this book. The iterator hides the particular implementation of the container as you're stepping through and selecting the elements one by one. Iterators allow you to write generic code that performs an operation on all the elements in a range without regard to the container that holds the range. Thus, your generic code can be used with any container that can produce iterators.
3-3-1-1. Prefer composition to inheritance▲
The most important contribution of GoF may not be a pattern, but rather a maxim that they introduce in Chapter 1: “Favor object composition over class inheritance.” Understanding inheritance and polymorphism is such a challenge that you may begin to assign undue importance to these techniques. We see many over-complicated designs (our own included) that result from “inheritance indulgence”— for example, many multiple inheritance designs evolve by insisting that inheritance be used everywhere.
One of the guidelines in Extreme Programming is “Do the simplest thing that could possibly work.” A design that seems to want inheritance can often be dramatically simplified by using composition instead, and you will also discover that the result is more flexible, as you will understand by studying some of the design patterns in this chapter. So when pondering a design, ask yourself: “Could this be simpler using composition? Do I really need inheritance here, and what is it buying me?”
3-3-2. Classifying patterns▲
GoF discusses 23 patterns, classified under three purposes (all of which revolve around the particular aspect that can vary):
- Creational: How an object can be created. This often involves isolating the details of object creation so your code isn't dependent on what types of objects there are and thus doesn't have to be changed when you add a new type of object. This chapter introduces Singleton, Factories, and Builder.
- Structural: These affect the way objects are connected with other objects to ensure that changes in the system don't require changes to those connections. Structural patterns are often dictated by project constraints. In this chapter you'll see Proxy and Adapter.
- Behavioral: Objects that handle particular types of actions within a program. These encapsulate processes that you want to perform, such as interpreting a language, fulfilling a request, moving through a sequence (as in an iterator), or implementing an algorithm. This chapter contains examples of Command, Template Method, State, Strategy, Chain of Responsibility, Observer, Multiple Dispatching, and Visitor.
GoF includes a section on each of its 23 patterns along with one or more examples of each, typically in C++ but sometimes in Smalltalk. This book will not repeat the details of the patterns shown in GoF since that book stands on its own and should be studied separately. The description and examples provided here are intended to give you a grasp of the patterns, so you can get a feel for what patterns are about and why they are important.
3-3-2-1. Features, idioms, patterns▲
Work continues beyond what is in the GoF book. Since its publication, there are more patterns and a more refined process for defining design patterns.(135) This is important because it is not easy to identify new patterns or to properly describe them. There is some confusion in the popular literature on what a design pattern is, for example. Patterns are not trivial, nor are they typically represented by features that are built into a programming language. Constructors and destructors, for example, could be called the “guaranteed initialization and cleanup design pattern.” These are important and essential constructs, but they're routine language features and are not rich enough to be considered design patterns.
Another non-example comes from various forms of aggregation. Aggregation is a completely fundamental principle in object-oriented programming: you make objects out of other objects. Yet sometimes this idea is erroneously classified as a pattern. This is unfortunate because it pollutes the idea of the design pattern and suggests that anything that surprises you the first time you see it should be made into a design pattern.
The Java language provides another misguided example: The designers of the JavaBeans specification decided to refer to the simple “get/set” naming convention as a design pattern (for example, getInfo( ) returns an Info property and setInfo( ) changes it). This is just a commonplace naming convention and in no way constitutes a design pattern.
3-3-3. Simplifying Idioms▲
Before getting into more complex techniques, it's helpful to look at some basic ways to keep code simple and straightforward.
3-3-3-1. Messenger▲
The most trivial of these is the messenger,(136) which packages information into an object which is passed around, instead of passing all the pieces around separately. Note that without the messenger, the code for translate( ) would be much more confusing to read:
//: C10:MessengerDemo.cpp
#include <iostream>
#include <string>
using namespace std;
class Point { // A messenger
public:
int x, y, z; // Since it's just a carrier
Point(int xi, int yi, int zi) : x(xi), y(yi), z(zi)
{}
Point(const Point& p) : x(p.x), y(p.y), z(p.z)
{}
Point& operator=(const Point& rhs) {
x = rhs.x;
y = rhs.y;
z = rhs.z;
return *this;
}
friend ostream&
operator<<(ostream& os, const Point& p)
{
return os << "x=" << p.x
<< " y=" << p.y
<< " z=" << p.z;
}
};
class Vector { // Mathematical vector
public:
int magnitude, direction;
Vector(int m, int d) : magnitude(m), direction(d) {}
};
class Space {
public:
static Point translate(Point p, Vector v) {
// Copy-constructor prevents modifying the
original.
// A dummy calculation:
p.x += v.magnitude + v.direction;
p.y += v.magnitude + v.direction;
p.z += v.magnitude + v.direction;
return p;
}
};
int main() {
Point p1(1, 2, 3);
Point p2 = Space::translate(p1, Vector(11, 47));
cout << "p1: " << p1 <<
" p2: " << p2 << endl;
} ///:~The code here is trivialized to prevent distractions.
Since the goal of a messenger is only to carry data, that data is made public for easy access. However, you may also have reasons to make the fields private.
3-3-3-2. Collecting Parameter▲
Messenger's big brother is the collecting parameter, whose job is to capture information from the function to which it is passed. Generally, this is used when the collecting parameter is passed to multiple functions, so it's like a bee collecting pollen.
A container makes an especially useful collecting parameter, since it is already set up to dynamically add objects:
//: C10:CollectingParameterDemo.cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class CollectingParameter : public vector<string>
{};
class Filler {
public:
void f(CollectingParameter& cp) {
cp.push_back("accumulating");
}
void g(CollectingParameter& cp) {
cp.push_back("items");
}
void h(CollectingParameter& cp) {
cp.push_back("as we go");
}
};
int main() {
Filler filler;
CollectingParameter cp;
filler.f(cp);
filler.g(cp);
filler.h(cp);
vector<string>::iterator it = cp.begin();
while(it != cp.end())
cout << *it++ << " ";
cout << endl;
} ///:~The collecting parameter must have some way to set or insert values. Note that by this definition, a messenger could be used as a collecting parameter. The key is that a collecting parameter is passed about and modified by the functions that receive it.
3-3-4. Singleton▲
Possibly the simplest GoF design pattern is the Singleton, which is a way to allow one and only one instance of a class. The following program shows how to implement a Singleton in C++:
//: C10:SingletonPattern.cpp
#include <iostream>
using namespace std;
class Singleton {
static Singleton s;
int i;
Singleton(int x) : i(x) { }
Singleton&
operator=(Singleton&); // Disallowed
Singleton(const Singleton&); // Disallowed
public:
static Singleton& instance() { return s; }
int getValue() { return i; }
void setValue(int x) { i = x; }
};
Singleton Singleton::s(47);
int main() {
Singleton& s = Singleton::instance();
cout << s.getValue() << endl;
Singleton& s2 = Singleton::instance();
s2.setValue(9);
cout << s.getValue() << endl;
} ///:~The key to creating a Singleton is to prevent the client programmer from having any control over the lifetime of the object. To do this, declare all constructors private, and prevent the compiler from implicitly generating any constructors. Note that the copy constructor and assignment operator (which intentionally have no implementations, since they will never be called) are declared private to prevent any sort of copies being made.
You must also decide how you're going to create the object. Here, it's created statically, but you can also wait until the client programmer asks for one and create it on demand. This is called lazy initialization, and it only makes sense if it is expensive to create your object, and if you don't always need it.
If you return a pointer instead of a reference, the user could inadvertently delete the pointer, so the implementation above is considered safest (the destructor can also be declared private or protected to alleviate that problem). In any case, the object should be stored privately.
You provide access through public member functions. Here, instance( ) produces a reference to the Singleton object. The rest of the interface (getValue( ) and setValue( )) is the regular class interface.
Note that you aren't restricted to creating only one object. This technique also supports the creation of a limited pool of objects. In that case, however, you can be confronted with the problem of sharing objects in the pool. If this is an issue, you can create a solution involving a check-out and check-in of the shared objects.
3-3-4-1. Variations on Singleton▲
Any static member object inside a class is an expression of Singleton: one and only one will be made. So in a sense, the language has direct support for the idea; we certainly use it on a regular basis. However, there's a problem with static objects (member or not): the order of initialization, as described in Volume 1 of this book. If one static object depends on another, it's important that the objects are initialized in the correct order.
In Volume 1, you were shown how to control initialization order by defining a static object inside a function. This delays the initialization of the object until the first time the function is called. If the function returns a reference to the static object, it gives you the effect of a Singleton while removing much of the worry of static initialization. For example, suppose you want to create a log file upon the first call to a function that returns a reference to that log file. This header file will do the trick:
//: C10:LogFile.h
#ifndef LOGFILE_H
#define LOGFILE_H
#include <fstream>
std::ofstream& logfile();
#endif // LOGFILE_H ///:~The implementation must not be inlined because that would mean that the whole function, including the static object definition within, could be duplicated in any translation unit where it's included, which violates C++'s one-definition rule.(137) This would most certainly foil the attempts to control the order of initialization (but potentially in a subtle and hard-to-detect fashion). So the implementation must be separate:
//: C10:LogFile.cpp {O}
#include "LogFile.h"
std::ofstream& logfile() {
static std::ofstream log("Logfile.log");
return log;
} ///:~Now the log object will not be initialized until the first time logfile( ) is called. So if you create a function:
//: C10:UseLog1.h
#ifndef USELOG1_H
#define USELOG1_H
void f();
#endif // USELOG1_H ///:~that uses logfile( ) in its implementation:
//: C10:UseLog1.cpp {O}
#include "UseLog1.h"
#include "LogFile.h"
void f() {
logfile() << __FILE__ << std::endl;
} ///:~And you use logfile( ) again in another file:
//: C10:UseLog2.cpp
//{L} LogFile UseLog1
#include "UseLog1.h"
#include "LogFile.h"
using namespace std;
void g() {
logfile() << __FILE__ << endl;
}
int main() {
f();
g();
} ///:~the log object doesn't get created until the first call to f( ).
You can easily combine the creation of the static object inside a member function with the Singleton class. SingletonPattern.cpp can be modified to use this approach:(138)
//: C10:SingletonPattern2.cpp
// Meyers' Singleton.
#include <iostream>
using namespace std;
class Singleton {
int i;
Singleton(int x) : i(x) { }
void operator=(Singleton&);
Singleton(const Singleton&);
public:
static Singleton& instance() {
static Singleton s(47);
return s;
}
int getValue() { return i; }
void setValue(int x) { i = x; }
};
int main() {
Singleton& s = Singleton::instance();
cout << s.getValue() << endl;
Singleton& s2 = Singleton::instance();
s2.setValue(9);
cout << s.getValue() << endl;
} ///:~An especially interesting case occurs if two Singletons depend on each other, like this:
//: C10:FunctionStaticSingleton.cpp
class Singleton1 {
Singleton1() {}
public:
static Singleton1& ref() {
static Singleton1 single;
return single;
}
};
class Singleton2 {
Singleton1& s1;
Singleton2(Singleton1& s) : s1(s) {}
public:
static Singleton2& ref() {
static Singleton2 single(Singleton1::ref());
return single;
}
Singleton1& f() { return s1; }
};
int main() {
Singleton1& s1 = Singleton2::ref().f();
} ///:~When Singleton2::ref( ) is called, it causes its sole Singleton2 object to be created. In the process of this creation, Singleton1::ref( ) is called, and that causes the sole Singleton1 object to be created. Because this technique doesn't rely on the order of linking or loading, the programmer has much better control over initialization, leading to fewer problems.
Yet another variation on Singleton separates the “Singleton-ness” of an object from its implementation. This is achieved using the Curiously Recurring Template Pattern mentioned in Chapter 5:
//: C10:CuriousSingleton.cpp
// Separates a class from its Singleton-ness (almost).
#include <iostream>
using namespace std;
template<class T> class Singleton {
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
protected:
Singleton() {}
virtual ~Singleton() {}
public:
static T& instance() {
static T theInstance;
return theInstance;
}
};
// A sample class to be made into a Singleton
class MyClass : public Singleton<MyClass> {
int x;
protected:
friend class Singleton<MyClass>;
MyClass() { x = 0; }
public:
void setValue(int n) { x = n; }
int getValue() const { return x; }
};
int main() {
MyClass& m = MyClass::instance();
cout << m.getValue() << endl;
m.setValue(1);
cout << m.getValue() << endl;
} ///:~MyClass is made a Singleton by:
1. Making its constructor private or protected.
2. Making Singleton<MyClass> a friend.
3. Deriving MyClass from Singleton<MyClass>.
The self-referencing in step 3 may sound implausible, but as we explained in Chapter 5, it works because there is only a static dependency on the template argument in the Singleton template. In other words, the code for the class Singleton<MyClass> can be instantiated by the compiler because it is not dependent on the size of MyClass. It's only later, when Singleton<MyClass>::instance( ) is first called, that the size of MyClass is needed, and by then MyClass has been compiled and its size is known.(139)
It's interesting how intricate such a simple pattern as Singleton can be, and we haven't even addressed issues of thread safety. Finally, Singleton should be used sparingly. True Singleton objects arise rarely, and the last thing a Singleton should be used for is to replace a global variable.(140)
3-3-5. Command: choosing the operation▲
The Command pattern is structurally very simple, but can have an important impact on decoupling—and thus cleaning up—your code.
In Advanced C++: Programming Styles And Idioms (Addison Wesley, 1992), Jim Coplien coins the term functor which is an object whose sole purpose is to encapsulate a function (since “functor” has a meaning in mathematics, we shall use the more explicit term function object). The point is to decouple the choice of function to be called from the site where that function is called.
This term is mentioned but not used in GoF. However, the theme of the function object is repeated in a number of patterns in that book.
A Command is a function object in its purest sense: a function that's an object. By wrapping a function in an object, you can pass it to other functions or objects as a parameter, to tell them to perform this particular operation in the process of fulfilling your request. You could say that a Command is a Messenger that carries behavior.
//: C10:CommandPattern.cpp
#include <iostream>
#include <vector>
using namespace std;
class Command {
public:
virtual void execute() = 0;
};
class Hello : public Command {
public:
void execute() { cout << "Hello "; }
};
class World : public Command {
public:
void execute() { cout << "World! "; }
};
class IAm : public Command {
public:
void execute() { cout << "I'm the command
pattern!"; }
};
// An object that holds commands:
class Macro {
vector<Command*> commands;
public:
void add(Command* c) { commands.push_back(c); }
void run() {
vector<Command*>::iterator it =
commands.begin();
while(it != commands.end())
(*it++)->execute();
}
};
int main() {
Macro macro;
macro.add(new Hello);
macro.add(new World);
macro.add(new IAm);
macro.run();
} ///:~The primary point of Command is to allow you to hand a desired action to a function or object. In the above example, this provides a way to queue a set of actions to be performed collectively. Here, you can dynamically create new behavior, something you can normally only do by writing new code but in the above example could be done by interpreting a script (see the Interpreter pattern if what you need to do gets very complex).
GoF says that “Commands are an object-oriented replacement for callbacks.”(141) However, we think that the word “back” is an essential part of the concept of callbacks—a callback reaches back to the creator of the callback. On the other hand, with a Command object you typically just create it and hand it to some function or object, and you are not otherwise connected over time to the Command object.
A common example of Command is the implementation of “undo” functionality in an application. Each time the user performs an operation, the corresponding “undo” Command object is placed into a queue. Each Command object that is executed backs up the state of the program by one step.
3-3-5-1. Decoupling event handling with Command▲
As you shall see in the next chapter, one of the reasons for employing concurrency techniques is to more easily manage event-driven programming, where the events can appear unpredictably in your program. For example, a user pressing a “quit” button while you're performing an operation expects the program to respond quickly.
An argument for using concurrency is that it prevents coupling across the pieces of your code. That is, if you're running a separate thread to watch the quit button, your program's “normal” operations don't need to know about the quit button or any of the other operations that need to be watched.
However, once you understand that coupling is the issue, you can avoid it using the Command pattern. Each “normal” operation must periodically call a function to check the state of the events, but with the Command pattern these normal operations don't need to know anything about what they are checking, and thus are decoupled from the event-handling code:
//: C10:MulticastCommand.cpp {RunByHand}
// Decoupling event management with the Command
pattern.
#include <iostream>
#include <vector>
#include <string>
#include <ctime>
#include <cstdlib>
using namespace std;
// Framework for running tasks:
class Task {
public:
virtual void operation() = 0;
};
class TaskRunner {
static vector<Task*> tasks;
TaskRunner() {} // Make it a Singleton
TaskRunner& operator=(TaskRunner&); //
Disallowed
TaskRunner(const TaskRunner&); // Disallowed
static TaskRunner tr;
public:
static void add(Task& t) {
tasks.push_back(&t); }
static void run() {
vector<Task*>::iterator it = tasks.begin();
while(it != tasks.end())
(*it++)->operation();
}
};
TaskRunner TaskRunner::tr;
vector<Task*> TaskRunner::tasks;
class EventSimulator {
clock_t creation;
clock_t delay;
public:
EventSimulator() : creation(clock()) {
delay = CLOCKS_PER_SEC/4 * (rand() % 20 + 1);
cout << "delay = " << delay
<< endl;
}
bool fired() {
return clock() > creation + delay;
}
};
// Something that can produce asynchronous events:
class Button {
bool pressed;
string id;
EventSimulator e; // For demonstration
public:
Button(string name) : pressed(false), id(name) {}
void press() { pressed = true; }
bool isPressed() {
if(e.fired()) press(); // Simulate the event
return pressed;
}
friend ostream&
operator<<(ostream& os, const Button&
b) {
return os << b.id;
}
};
// The Command object
class CheckButton : public Task {
Button& button;
bool handled;
public:
CheckButton(Button & b) : button(b),
handled(false) {}
void operation() {
if(button.isPressed() && !handled) {
cout << button << "
pressed" << endl;
handled = true;
}
}
};
// The procedures that perform the main processing.
These
// need to be occasionally "interrupted" in
order to
// check the state of the buttons or other events:
void procedure1() {
// Perform procedure1 operations here.
// ...
TaskRunner::run(); // Check all events
}
void procedure2() {
// Perform procedure2 operations here.
// ...
TaskRunner::run(); // Check all events
}
void procedure3() {
// Perform procedure3 operations here.
// ...
TaskRunner::run(); // Check all events
}
int main() {
srand(time(0)); // Randomize
Button b1("Button 1"), b2("Button
2"), b3("Button 3");
CheckButton cb1(b1), cb2(b2), cb3(b3);
TaskRunner::add(cb1);
TaskRunner::add(cb2);
TaskRunner::add(cb3);
cout << "Control-C to exit" <<
endl;
while(true) {
procedure1();
procedure2();
procedure3();
}
} ///:~Here, the Command object is represented by Tasks executed by the Singleton TaskRunner. EventSimulator creates a random delay time, so if you periodically call fired( ) the result will change from false to true at some random time. EventSimulator objects are used inside Buttons to simulate the act of a user event occurring at some unpredictable time. CheckButton is the implementation of the Task that is periodically checked by all the “normal” code in the program—you can see this happening at the end of procedure1( ), procedure2( ) and procedure3( ).
Although this requires a little bit of extra thought to set up, you'll see in Chapter 11 that threading requires a lot of thought and care to prevent the various difficulties inherent to concurrent programming, so the simpler solution may be preferable. You can also create a very simple threading scheme by moving the TaskRunner::run( ) calls into a multithreaded “timer” object. By doing this, you eliminate all coupling between the “normal operations” (procedures, in the above example) and the event code.
3-3-6. Object decoupling▲
Both Proxy and State provide a surrogate class. Your code talks to this surrogate class, and the real class that does the work is hidden behind this surrogate class. When you call a function in the surrogate, it simply turns around and calls the function in the implementing class. These two patterns are so similar that, structurally, Proxy is simply a special case of State. One is tempted to just lump the two together into a pattern called Surrogate, but the intent of the two patterns is different. It can be easy to fall into the trap of thinking that if the structure is the same, the patterns are the same. You must always look to the intent of the pattern in order to be clear about what it does.
The basic idea is simple: from a base class, the surrogate is derived along with the class or classes that provide the actual implementation:
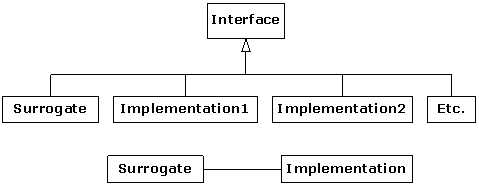
When a surrogate object is created, it is given an implementation to which it sends the function calls.
Structurally, the difference between Proxy and State is simple: a Proxy has only one implementation, while State has more than one. The application of the patterns is considered (in GoF) to be distinct: Proxy controls access to its implementation, while State changes the implementation dynamically. However, if you expand your notion of “controlling access to implementation” then the two seem to be part of a continuum.
3-3-6-1. Proxy: fronting for another object▲
If we implement Proxy using the above diagram, it looks like this:
//: C10:ProxyDemo.cpp
// Simple demonstration of the Proxy pattern.
#include <iostream>
using namespace std;
class ProxyBase {
public:
virtual void f() = 0;
virtual void g() = 0;
virtual void h() = 0;
virtual ~ProxyBase() {}
};
class Implementation : public ProxyBase {
public:
void f() { cout <<
"Implementation.f()" << endl; }
void g() { cout <<
"Implementation.g()" << endl; }
void h() { cout <<
"Implementation.h()" << endl; }
};
class Proxy : public ProxyBase {
ProxyBase* implementation;
public:
Proxy() { implementation = new Implementation(); }
~Proxy() { delete implementation; }
// Forward calls to the implementation:
void f() { implementation->f(); }
void g() { implementation->g(); }
void h() { implementation->h(); }
};
int main() {
Proxy p;
p.f();
p.g();
p.h();
} ///:~In some cases, Implementation doesn't need the same interface as Proxy—as long as Proxy is somehow “speaking for” the Implementation class and referring function calls to it, then the basic idea is satisfied (note that this statement is at odds with the definition for Proxy in GoF). However, with a common interface you are able to do a drop-in replacement of the proxy into the client code—the client code is written to talk to the original object, and it doesn't need to be changed in order to accept the proxy (This is probably the key issue with Proxy). In addition, Implementation is forced, through the common interface, to fulfill all the functions that Proxy needs to call.
The difference between Proxy and State is in the problems that are solved. The common uses for Proxy as described in GoF are:
- Remote proxy. This proxies for an object in a different address space. This is implemented by some remote object technologies.
- Virtual proxy. This provides “lazy initialization” to create expensive objects on demand.
- Protection proxy. Used when you don't want the client programmer to have full access to the proxied object.
- Smart reference. To add additional actions when the proxied object is accessed. Reference counting is an example: this keeps track of the number of references that are held for a particular object, in order to implement the copy-on-write idiom and prevent object aliasing.(142) A simpler example is counting the calls to a particular function.
3-3-6-2. State: changing object behavior▲
The State pattern produces an object that appears to change its class, and is useful when you discover that you have conditional code in most or all functions. Like Proxy, State is created by having a front-end object that uses a back-end implementation object to fulfill its duties. However, the State pattern switches from one implementation to another during the lifetime of the front-end object, in order to produce different behavior for the same function call(s). It's a way to improve the implementation of your code when you seem to be doing a lot of testing inside each of your functions before deciding what to do for that function. For example, the fairy tale of the frog-prince contains an object (the creature) that behaves differently depending on what state it's in. You could implement this by testing a bool:
//: C10:KissingPrincess.cpp
#include <iostream>
using namespace std;
class Creature {
bool isFrog;
public:
Creature() : isFrog(true) {}
void greet() {
if(isFrog)
cout << "Ribbet!" << endl;
else
cout << "Darling!"
<< endl;
}
void kiss() { isFrog = false; }
};
int main() {
Creature creature;
creature.greet();
creature.kiss();
creature.greet();
} ///:~However, the greet( ) function, and any other functions that must test isFrog before they perform their operations, end up with awkward code, especially if you find yourself adding additional states to the system. By delegating the operations to a State object that can be changed, this code is simplified.
//: C10:KissingPrincess2.cpp
// The State pattern.
#include <iostream>
#include <string>
using namespace std;
class Creature {
class State {
public:
virtual string response() = 0;
};
class Frog : public State {
public:
string response() { return "Ribbet!"; }
};
class Prince : public State {
public:
string response() { return "Darling!"; }
};
State* state;
public:
Creature() : state(new Frog()) {}
void greet() {
cout << state->response() << endl;
}
void kiss() {
delete state;
state = new Prince();
}
};
int main() {
Creature creature;
creature.greet();
creature.kiss();
creature.greet();
} ///:~It is not necessary to make the implementing classes nested or private, but if you can it creates cleaner code.
Note that changes to the State classes are automatically propagated throughout your code, rather than requiring an edit across the classes in order to effect changes.
3-3-7. Adapter▲
Adapter takes one type and produces an interface to some other type. This is useful when you're given a library or piece of code that has a particular interface, and you've got a second library or piece of code that uses the same basic ideas as the first piece, but expresses itself differently. If you adapt the forms of expression to each other, you can rapidly produce a solution.
Suppose you have a generator class that produces Fibonacci numbers:
//: C10:FibonacciGenerator.h
#ifndef FIBONACCIGENERATOR_H
#define FIBONACCIGENERATOR_H
class FibonacciGenerator {
int n;
int val[2];
public:
FibonacciGenerator() : n(0) { val[0] =
val[1] = 0; }
int operator()() {
int result = n > 2 ? val[0] +
val[1] : n > 0 ? 1 : 0;
++n;
val[0] = val[1];
val[1] = result;
return result;
}
int count() { return n; }
};
#endif // FIBONACCIGENERATOR_H
///:~Since it's a generator, you use it by calling the operator( ), like this:
//: C10:FibonacciGeneratorTest.cpp
#include <iostream>
#include "FibonacciGenerator.h"
using namespace std;
int main() {
FibonacciGenerator f;
for(int i =0; i < 20; i++)
cout << f.count() << ": "
<< f() << endl;
} ///:~Perhaps you would like to take this generator and perform STL numeric algorithm operations with it. Unfortunately, the STL algorithms only work with iterators, so you have an interface mismatch. The solution is to create an adapter that will take the FibonacciGenerator and produce an iterator for the STL algorithms to use. Since the numeric algorithms only require an input iterator, the Adapter is fairly straightforward (for something that produces an STL iterator, that is):
//: C10:FibonacciAdapter.cpp
// Adapting an interface to something you already have.
#include <iostream>
#include <numeric>
#include "FibonacciGenerator.h"
#include "../C06/PrintSequence.h"
using namespace std;
class FibonacciAdapter { // Produce an iterator
FibonacciGenerator f;
int length;
public:
FibonacciAdapter(int size) : length(size) {}
class iterator;
friend class iterator;
class iterator : public std::iterator<
std::input_iterator_tag, FibonacciAdapter,
ptrdiff_t> {
FibonacciAdapter& ap;
public:
typedef int value_type;
iterator(FibonacciAdapter& a) : ap(a) {}
bool operator==(const iterator&) const {
return ap.f.count() == ap.length;
}
bool operator!=(const iterator& x) const {
return !(*this == x);
}
int operator*() const { return ap.f(); }
iterator& operator++() { return *this; }
iterator operator++(int) { return *this; }
};
iterator begin() { return iterator(*this); }
iterator end() { return iterator(*this); }
};
int main() {
const int SZ = 20;
FibonacciAdapter a1(SZ);
cout << "accumulate: "
<< accumulate(a1.begin(), a1.end(), 0)
<< endl;
FibonacciAdapter a2(SZ), a3(SZ);
cout << "inner
product: "
<< inner_product(a2.begin(), a2.end(),
a3.begin(), 0)
<< endl;
FibonacciAdapter a4(SZ);
int r1[SZ] = {0};
int* end = partial_sum(a4.begin(), a4.end(), r1);
print(r1, end, "partial_sum", "
");
FibonacciAdapter a5(SZ);
int r2[SZ] = {0};
end = adjacent_difference(a5.begin(), a5.end(), r2);
print(r2, end, "adjacent_difference",
" ");
} ///:~You initialize a FibonacciAdapter by telling it how long the Fibonacci sequence can be. When an iterator is created, it simply captures a reference to the containing FibonacciAdapter so that it can access the FibonacciGenerator and length. Note that the equivalence comparison ignores the right-hand value because the only important issue is whether the generator has reached its length. In addition, the operator++( ) doesn't modify the iterator; the only operation that changes the state of the FibonacciAdapter is calling the generator function operator( ) on the FibonacciGenerator. We can get away with this extremely simple version of the iterator because the constraints on an Input Iterator are so strong; in particular, you can only read each value in the sequence once.
In main( ), you can see that all four different types of numeric algorithms are successfully tested with the FibonacciAdapter.
3-3-8. Template Method▲
An application framework allows you to inherit from a class or set of classes and create a new application, reusing most of the code in the existing classes and overriding one or more functions in order to customize the application to your needs. A fundamental concept in the application framework is the Template Method, which is typically hidden beneath the covers and drives the application by calling the various functions in the base class (some of which you have overridden in order to create the application).
An important characteristic of the Template Method is that it is defined in the base class (sometimes as a private member function) and cannot be changed—the Template Method is the “thing that stays the same.” It calls other base-class functions (the ones you override) in order to do its job, but the client programmer isn't necessarily able to call it directly, as you can see here:
//: C10:TemplateMethod.cpp
// Simple demonstration of Template Method.
#include <iostream>
using namespace std;
class ApplicationFramework {
protected:
virtual void customize1() = 0;
virtual void customize2() = 0;
public:
void templateMethod() {
for(int i = 0; i < 5; i++) {
customize1();
customize2();
}
}
};
// Create a new "application":
class MyApp : public ApplicationFramework {
protected:
void customize1() { cout << "Hello ";
}
void customize2() { cout << "World!"
<< endl; }
};
int main() {
MyApp app;
app.templateMethod();
} ///:~The “engine” that runs the application is the Template Method. In a GUI application, this “engine” would be the main event loop. The client programmer simply provides definitions for customize1( ) and customize2( ) and the “application” is ready to run.
3-3-9. Strategy: choosing the algorithm at runtime▲
Note that the Template Method is the “code that stays the same,” and the functions that you override are the “code that changes.” However, this change is fixed at compile time via inheritance. Following the maxim of “prefer composition to inheritance,” we can use composition to approach the problem of separating code that changes from code that stays the same, and produce the Strategy pattern. This approach has a distinct benefit: at runtime, you can plug in the code that changes. Strategy also adds a “Context” which can be a surrogate class that controls the selection and use of the particular strategy object—just like State!
“Strategy” means just that: you can solve a problem in a number of ways. Consider the situation where you've forgotten someone's name. Here are the different ways you can cope:
//: C10:Strategy.cpp
// The Strategy design pattern.
#include <iostream>
using namespace std;
class NameStrategy {
public:
virtual void greet() = 0;
};
class SayHi : public NameStrategy {
public:
void greet() {
cout << "Hi! How's it going?"
<< endl;
}
};
class Ignore : public NameStrategy {
public:
void greet() {
cout << "(Pretend I don't see you)"
<< endl;
}
};
class Admission : public NameStrategy {
public:
void greet() {
cout << "I'm sorry. I forgot your
name." << endl;
}
};
// The "Context" controls the strategy:
class Context {
NameStrategy& strategy;
public:
Context(NameStrategy& strat) : strategy(strat) {}
void greet() { strategy.greet(); }
};
int main() {
SayHi sayhi;
Ignore ignore;
Admission admission;
Context c1(sayhi), c2(ignore), c3(admission);
c1.greet();
c2.greet();
c3.greet();
} ///:~Context::greet( ) would normally be more complex; it's the analog of the Template Method because it contains the code that doesn't change. But you can see in main( ) that the choice of strategy can be made at runtime. If you go one step further you can combine this with the State pattern and change the Strategy during the lifetime of the Context object.
3-3-10. Chain of Responsibility: trying a sequence of strategies▲
Chain of Responsibility might be thought of as a “dynamic generalization of recursion” using Strategy objects. You make a call, and each Strategy in a linked sequence tries to satisfy the call. The process ends when one of the strategies is successful or the chain ends. In recursion, one function calls itself over and over until a termination condition is reached; with Chain of Responsibility, a function calls itself, which (by moving down the chain of Strategies) calls a different implementation of the function, etc., until a termination condition is reached. The termination condition is either that the bottom of the chain is reached (this returns a default object; you may or may not be able to provide a default result so you must be able to determine the success or failure of the chain) or one of the Strategies is successful.
Instead of calling a single function to satisfy a request, multiple functions in the chain have a chance to satisfy the request, so it has the flavor of an expert system. Since the chain is effectively a list, it can be dynamically created, so you could also think of it as a more general, dynamically-built switch statement.
In GoF, there's a fair amount of discussion of how to create the chain of responsibility as a linked list. However, when you look at the pattern it really shouldn't matter how the chain is created; that's an implementation detail. Since GoF was written before the STL containers were available in most C++ compilers, the reason for this is most likely (1) there was no built-in list and thus they had to create one and (2) data structures are often taught as a fundamental skill in academia, and the idea that data structures should be standard tools available with the programming language may not have occurred to the GoF authors. We maintain that the details of the container used to implement Chain of Responsibility as a chain (in GoF, a linked list) adds nothing to the solution and can just as easily be implemented using an STL container, as shown below.
Here you can see Chain of Responsibility automatically finding a solution using a mechanism to automatically recurse through each Strategy in the chain:
//: C10:ChainOfReponsibility.cpp
// The approach of the five-year-old.
#include <iostream>
#include <vector>
#include "../purge.h"
using namespace std;
enum Answer { NO, YES };
class GimmeStrategy {
public:
virtual Answer canIHave() = 0;
virtual ~GimmeStrategy() {}
};
class AskMom : public GimmeStrategy {
public:
Answer canIHave() {
cout << "Mooom? Can I have this?"
<< endl;
return NO;
}
};
class AskDad : public GimmeStrategy {
public:
Answer canIHave() {
cout << "Dad, I really need this!"
<< endl;
return NO;
}
};
class AskGrandpa : public GimmeStrategy {
public:
Answer canIHave() {
cout << "Grandpa, is it my birthday
yet?" << endl;
return NO;
}
};
class AskGrandma : public GimmeStrategy {
public:
Answer canIHave() {
cout << "Grandma, I really love
you!" << endl;
return YES;
}
};
class Gimme : public GimmeStrategy {
vector<GimmeStrategy*> chain;
public:
Gimme() {
chain.push_back(new AskMom());
chain.push_back(new AskDad());
chain.push_back(new AskGrandpa());
chain.push_back(new AskGrandma());
}
Answer canIHave() {
vector<GimmeStrategy*>::iterator it =
chain.begin();
while(it != chain.end())
if((*it++)->canIHave() == YES)
return YES;
// Reached end without success...
cout << "Whiiiiinnne!" <<
endl;
return NO;
}
~Gimme() { purge(chain); }
};
int main() {
Gimme chain;
chain.canIHave();
} ///:~Notice that the “Context” class Gimme and all the Strategy classes are all derived from the same base class, GimmeStrategy.
If you study the section on Chain of Responsibility in GoF, you'll find that the structure differs significantly from the one above because they focus on creating their own linked list. However, if you keep in mind that the essence of Chain of Responsibility is to try a number of solutions until you find one that works, you'll realize that the implementation of the sequencing mechanism is not an essential part of the pattern.
3-3-11. Factories: encapsulating object creation▲
When you discover that you need to add new types to a system, the most sensible first step is to use polymorphism to create a common interface to those new types. This separates the rest of the code in your system from the knowledge of the specific types that you are adding. New types can be added without disturbing existing code … or so it seems. At first it would appear that you need to change the code only in the place where you inherit a new type, but this is not quite true. You must still create an object of your new type, and at the point of creation you must specify the exact constructor to use. Thus, if the code that creates objects is distributed throughout your application, you have the same problem when adding new types—you must still chase down all the points of your code where type matters. It is the creation of the type that matters here, rather than the use of the type (which is taken care of by polymorphism), but the effect is the same: adding a new type can cause problems.
The solution is to force the creation of objects to occur through a common factory rather than to allow the creational code to be spread throughout your system. If all the code in your program must go to this factory whenever it needs to create one of your objects, all you must do when you add a new object is modify the factory. This design is a variation of the pattern commonly known as Factory Method. Since every object-oriented program creates objects, and since it's likely you will extend your program by adding new types, factories may be the most useful of all design patterns.
As an example, consider the commonly-used Shape example. One approach to implementing a factory is to define a static member function in the base class:
//: C10:ShapeFactory1.cpp
#include <iostream>
#include <stdexcept>
#include <cstddef>
#include <string>
#include <vector>
#include "../purge.h"
using namespace std;
class Shape {
public:
virtual void draw() = 0;
virtual void erase() = 0;
virtual ~Shape() {}
class BadShapeCreation : public logic_error {
public:
BadShapeCreation(string type)
: logic_error("Cannot create type " +
type) {}
};
static Shape* factory(const string& type)
throw(BadShapeCreation);
};
class Circle : public Shape {
Circle() {} // Private constructor
friend class Shape;
public:
void draw() { cout << "Circle::draw”
<< endl; }
void erase() { cout << "Circle::erase”
<< endl; }
~Circle() { cout << "Circle::~Circle”
<< endl; }
};
class Square : public Shape {
Square() {}
friend class Shape;
public:
void draw() { cout << "Square::draw”
<< endl; }
void erase() { cout << "Square::erase”
<< endl; }
~Square() { cout << "Square::~Square”
<< endl; }
};
Shape* Shape::factory(const string& type)
throw(Shape::BadShapeCreation) {
if(type == "Circle") return new Circle;
if(type == "Square") return new Square;
throw BadShapeCreation(type);
}
char* sl[] = { "Circle", "Square",
"Square",
"Circle", "Circle",
"Circle", "Square" };
int main() {
vector<Shape*> shapes;
try {
for(size_t i = 0; i < sizeof sl / sizeof sl[0];
i++)
shapes.push_back(Shape::factory(sl[i]));
} catch(Shape::BadShapeCreation e) {
cout << e.what() << endl;
purge(shapes);
return EXIT_FAILURE;
}
for(size_t i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
shapes[i]->erase();
}
purge(shapes);
} ///:~The factory( ) function takes an argument that allows it to determine what type of Shape to create. Here, the argument is a string, but it could be any set of data. The factory( ) is now the only other code in the system that needs to be changed when a new type of Shape is added. (The initialization data for the objects will presumably come from somewhere outside the system and will not be a hard-coded array as in this example.)
To ensure that the creation can only happen in the factory( ), the constructors for the specific types of Shape are made private, and Shape is declared a friend so that factory( ) has access to the constructors. (You could also declare only Shape::factory( ) to be a friend, but it seems reasonably harmless to declare the entire base class as a friend.) There is another important implication of this design—the base class, Shape, must now know the details about every derived class—a property that object-oriented designs try to avoid. For frameworks or any class library that should support extension, this can quickly become unwieldy, as the base class must be updated as soon as a new type is added to the hierarchy. Polymorphic factories, described in the next subsection, can be used to avoid this unfortunate circular dependency.
3-3-11-1. Polymorphic factories▲
The static factory( ) member function in the previous example forces all the creation operations to be focused in one spot, so that's the only place you need to change the code. This is certainly a reasonable solution, as it nicely encapsulates the process of creating objects. However, GoF emphasizes that the reason for the Factory Method pattern is so that different types of factories can be derived from the basic factory. Factory Method is in fact a special type of polymorphic factory. Here is ShapeFactory1.cpp modified so the Factory Methods are in a separate class as virtual functions:
//: C10:ShapeFactory2.cpp
// Polymorphic Factory Methods.
#include <iostream>
#include <map>
#include <string>
#include <vector>
#include <stdexcept>
#include <cstddef>
#include "../purge.h"
using namespace std;
class Shape {
public:
virtual void draw() = 0;
virtual void erase() = 0;
virtual ~Shape() {}
};
class ShapeFactory {
virtual Shape* create() = 0;
static map<string, ShapeFactory*> factories;
public:
virtual ~ShapeFactory() {}
friend class ShapeFactoryInitializer;
class BadShapeCreation : public logic_error {
public:
BadShapeCreation(string type)
: logic_error("Cannot create type " +
type) {}
};
static Shape*
createShape(const string& id) throw(BadShapeCreation)
{
if(factories.find(id) != factories.end())
return factories[id]->create();
else
throw BadShapeCreation(id);
}
};
// Define the static object:
map<string, ShapeFactory*>
ShapeFactory::factories;
class Circle : public Shape {
Circle() {} // Private constructor
friend class ShapeFactoryInitializer;
class Factory;
friend class Factory;
class Factory : public ShapeFactory {
public:
Shape* create() { return new Circle; }
friend class ShapeFactoryInitializer;
};
public:
void draw() { cout << "Circle::draw”
<< endl; }
void erase() { cout << "Circle::erase”
<< endl; }
~Circle() { cout << "Circle::~Circle”
<< endl; }
};
class Square : public Shape {
Square() {}
friend class ShapeFactoryInitializer;
class Factory;
friend class Factory;
class Factory : public ShapeFactory {
public:
Shape* create() { return new Square; }
friend class ShapeFactoryInitializer;
};
public:
void draw() { cout << "Square::draw”
<< endl; }
void erase() { cout << "Square::erase”
<< endl; }
~Square() { cout << "Square::~Square”
<< endl; }
};
// Singleton to initialize the ShapeFactory:
class ShapeFactoryInitializer {
static ShapeFactoryInitializer si;
ShapeFactoryInitializer() {
ShapeFactory::factories["Circle"]= new
Circle::Factory;
ShapeFactory::factories["Square"]= new
Square::Factory;
}
~ShapeFactoryInitializer() {
map<string, ShapeFactory*>::iterator it =
ShapeFactory::factories.begin();
while(it != ShapeFactory::factories.end())
delete it++->second;
}
};
// Static member definition:
ShapeFactoryInitializer ShapeFactoryInitializer::si;
char* sl[] = { "Circle", "Square",
"Square",
"Circle", "Circle",
"Circle", "Square" };
int main() {
vector<Shape*> shapes;
try {
for(size_t i = 0; i < sizeof sl / sizeof sl[0];
i++)
shapes.push_back(ShapeFactory::createShape(sl[i]));
} catch(ShapeFactory::BadShapeCreation e) {
cout << e.what() << endl;
return EXIT_FAILURE;
}
for(size_t i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
shapes[i]->erase();
}
purge(shapes);
} ///:~Now the Factory Method appears in its own class, ShapeFactory, as virtual create( ). This is a private member function, which means it cannot be called directly but can be overridden. The subclasses of Shape must each create their own subclasses of ShapeFactory and override the create( ) member function to create an object of their own type. These factories are private, so that they are only accessible from the main Factory Method. This way, all client code must go through the Factory Method in order to create objects.
The actual creation of shapes is performed by calling ShapeFactory::createShape( ), which is a static member function that uses the map in ShapeFactory to find the appropriate factory object based on an identifier that you pass it. The factory creates the shape object directly, but you could imagine a more complex problem where the appropriate factory object is returned and then used by the caller to create an object in a more sophisticated way. However, it seems that much of the time you don't need the intricacies of the polymorphic Factory Method, and a single static member function in the base class (as shown in ShapeFactory1.cpp) will work fine.
Notice that the ShapeFactory must be initialized by loading its map with factory objects, which takes place in the Singleton ShapeFactoryInitializer. So to add a new type to this design you must define the type, create a factory, and modify ShapeFactoryInitializer so that an instance of your factory is inserted in the map. This extra complexity again suggests the use of a static Factory Method if you don't need to create individual factory objects.
3-3-11-2. Abstract factories▲
The Abstract Factory pattern looks like the factories we've seen previously, but with several Factory Methods. Each of the Factory Methods creates a different kind of object. When you create the factory object, you decide how all the objects created by that factory will be used. The example in GoF implements portability across various graphical user interfaces (GUIs): you create a factory object appropriate to the GUI that you're working with, and from then on when you ask it for a menu, a button, a slider, and so on, it will automatically create the appropriate version of that item for the GUI. Thus, you're able to isolate, in one place, the effect of changing from one GUI to another.
As another example, suppose you are creating a general-purpose gaming environment and you want to be able to support different types of games. Here's how it might look using an Abstract Factory:
//: C10:AbstractFactory.cpp
// A gaming environment.
#include <iostream>
using namespace std;
class Obstacle {
public:
virtual void action() = 0;
};
class Player {
public:
virtual void interactWith(Obstacle*) = 0;
};
class Kitty: public Player {
virtual void interactWith(Obstacle* ob) {
cout << "Kitty has encountered a ";
ob->action();
}
};
class KungFuGuy: public Player {
virtual void interactWith(Obstacle* ob) {
cout << "KungFuGuy now battles against a
";
ob->action();
}
};
class Puzzle: public Obstacle {
public:
void action() { cout << "Puzzle"
<< endl; }
};
class NastyWeapon: public Obstacle {
public:
void action() { cout << "NastyWeapon"
<< endl; }
};
// The abstract factory:
class GameElementFactory {
public:
virtual Player* makePlayer() = 0;
virtual Obstacle* makeObstacle() = 0;
};
// Concrete factories:
class KittiesAndPuzzles : public GameElementFactory {
public:
virtual Player* makePlayer() { return new Kitty; }
virtual Obstacle* makeObstacle() { return new Puzzle;
}
};
class KillAndDismember : public GameElementFactory {
public:
virtual Player* makePlayer() { return new KungFuGuy;
}
virtual Obstacle* makeObstacle() {
return new NastyWeapon;
}
};
class GameEnvironment {
GameElementFactory* gef;
Player* p;
Obstacle* ob;
public:
GameEnvironment(GameElementFactory* factory)
: gef(factory), p(factory->makePlayer()),
ob(factory->makeObstacle()) {}
void play() { p->interactWith(ob); }
~GameEnvironment() {
delete p;
delete ob;
delete gef;
}
};
int main() {
GameEnvironment
g1(new KittiesAndPuzzles),
g2(new KillAndDismember);
g1.play();
g2.play();
}
/* Output:
Kitty has encountered a Puzzle
KungFuGuy now battles against a
NastyWeapon */ ///:~In this environment, Player objects interact with Obstacle objects, but the types of players and obstacles depend on the game. You determine the kind of game by choosing a particular GameElementFactory, and then the GameEnvironment controls the setup and play of the game. In this example, the setup and play are simple, but those activities (the initial conditions and the state change) can determine much of the game's outcome. Here, GameEnvironment is not designed to be inherited, although it could possibly make sense to do that.
This example also illustrates double dispatching, which will be explained later.
3-3-11-3. Virtual constructors▲
One of the primary goals of using a factory is to organize your code so you don't need to select the exact constructor type when creating an object. That is, you can tell a factory: “I don't know precisely what kind of object I need, but here's the information. Create the appropriate type.”
In addition, during a constructor call the virtual mechanism does not operate (early binding occurs). Sometimes this is awkward. For example, in the Shape program it seems logical that inside the constructor for a Shape object, you would want to set everything up and then draw( ) the Shape. The draw( ) function should be a virtual function, a message to the Shape that it should draw itself appropriately, depending on whether it is a Circle, a Square, a Line, and so on. However, this doesn't work inside the constructor because virtual functions resolve to the “local” function bodies when called in constructors.
If you want to be able to call a virtual function inside the constructor and have it do the right thing, you must use a technique to simulate a virtual constructor. This is a conundrum. Remember, the idea of a virtual function is that you send a message to an object and let the object figure out the right thing to do. But a constructor builds an object. So a virtual constructor would be like saying, “I don't know exactly what kind of object you are, but build the right type anyway.” In an ordinary constructor, the compiler must know which VTABLE address to bind to the VPTR, and even if it existed, a virtual constructor couldn't do this because it doesn't know all the type information at compile time. It makes sense that a constructor can't be virtual because it is the one function that absolutely must know everything about the type of the object.
And yet there are times when you want something approximating the behavior of a virtual constructor.
In the Shape example, it would be nice to hand the Shape constructor some specific information in the argument list and let the constructor create a specific type of Shape (a Circle or a Square) with no further intervention. Ordinarily, you'd have to make an explicit call to the Circle or Square constructor yourself.
Coplien(143) calls his solution to this problem “envelope and letter classes.” The “envelope” class is the base class, a shell that contains a pointer to an object, also of the base class type. The constructor for the “envelope” determines (at runtime, when the constructor is called, not at compile time, when the type checking is normally done) what specific type to make, creates an object of that specific type (on the heap), and then assigns the object to its pointer. All the function calls are then handled by the base class through its pointer. It's really just a slight variation of the State pattern, where the base class is acting as a surrogate for the derived class, and the derived class provides the variation in behavior:
//: C10:VirtualConstructor.cpp
#include <iostream>
#include <string>
#include <stdexcept>
#include <stdexcept>
#include <cstddef>
#include <vector>
#include "../purge.h"
using namespace std;
class Shape {
Shape* s;
// Prevent copy-construction & operator=
Shape(Shape&);
Shape operator=(Shape&);
protected:
Shape() { s = 0; }
public:
virtual void draw() { s->draw(); }
virtual void erase() { s->erase(); }
virtual void test() { s->test(); }
virtual ~Shape() {
cout << "~Shape" << endl;
if(s) {
cout << "Making virtual call: ";
s->erase(); // Virtual call
}
cout << "delete s: ";
delete s; // The polymorphic deletion
// (delete 0 is legal; it produces a no-op)
}
class BadShapeCreation : public logic_error {
public:
BadShapeCreation(string type)
: logic_error("Cannot create type " +
type) {}
};
Shape(string type) throw(BadShapeCreation);
};
class Circle : public Shape {
Circle(Circle&);
Circle operator=(Circle&);
Circle() {} // Private constructor
friend class Shape;
public:
void draw() { cout << "Circle::draw"
<< endl; }
void erase() { cout <<
"Circle::erase" << endl; }
void test() { draw(); }
~Circle() { cout << "Circle::~Circle"
<< endl; }
};
class Square : public Shape {
Square(Square&);
Square operator=(Square&);
Square() {}
friend class Shape;
public:
void draw() { cout << "Square::draw"
<< endl; }
void erase() { cout <<
"Square::erase" << endl; }
void test() { draw(); }
~Square() { cout << "Square::~Square"
<< endl; }
};
Shape::Shape(string type)
throw(Shape::BadShapeCreation) {
if(type == "Circle")
s = new Circle;
else if(type == "Square")
s = new Square;
else throw BadShapeCreation(type);
draw(); // Virtual call in the constructor
}
char* sl[] = { "Circle", "Square",
"Square",
"Circle", "Circle",
"Circle", "Square" };
int main() {
vector<Shape*> shapes;
cout << "virtual constructor calls:"
<< endl;
try {
for(size_t i = 0; i < sizeof sl / sizeof sl[0];
i++)
shapes.push_back(new Shape(sl[i]));
} catch(Shape::BadShapeCreation e) {
cout << e.what() << endl;
purge(shapes);
return EXIT_FAILURE;
}
for(size_t i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
cout << "test" << endl;
shapes[i]->test();
cout << "end test" << endl;
shapes[i]->erase();
}
Shape c("Circle"); // Create on the stack
cout << "destructor calls:" <<
endl;
purge(shapes);
} ///:~The base class Shape contains a pointer to an object of type Shape as its only data member. (When you create a “virtual constructor” scheme, exercise special care to ensure this pointer is always initialized to a live object.) This base class is effectively a proxy because it is the only thing the client code sees and interacts with.
Each time you derive a new subtype from Shape, you must go back and add the creation for that type in one place, inside the “virtual constructor” in the Shape base class. This is not too onerous a task, but the disadvantage is you now have a dependency between the Shape class and all classes derived from it.
In this example, the information you must hand the virtual constructor about what type to create is explicit: it's a string that names the type. However, your scheme can use other information—for example, in a parser the output of the scanner can be handed to the virtual constructor, which then uses that information to determine which token to create.
The virtual constructor Shape(type) cannot be defined until after all the derived classes have been declared. However, the default constructor can be defined inside class Shape, but it should be made protected so temporary Shape objects cannot be created. This default constructor is only called by the constructors of derived-class objects. You are forced to explicitly create a default constructor because the compiler will create one for you automatically only if there are no constructors defined. Because you must define Shape(type), you must also define Shape( ).
The default constructor in this scheme has at least one important chore—it must set the value of the s pointer to zero. This may sound strange at first, but remember that the default constructor will be called as part of the construction of the actual object—in Coplien's terms, the “letter,” not the “envelope.” However, the “letter” is derived from the “envelope,” so it also inherits the data member s. In the “envelope,” s is important because it points to the actual object, but in the “letter,” s is simply excess baggage. Even excess baggage should be initialized, however, and if s is not set to zero by the default constructor called for the “letter,” bad things happen (as you'll see later).
The virtual constructor takes as its argument information that completely determines the type of the object. Notice, though, that this type information isn't read and acted upon until runtime, whereas normally the compiler must know the exact type at compile time (one other reason this system effectively imitates virtual constructors).
The virtual constructor uses its argument to select the actual (“letter”) object to construct, which is then assigned to the pointer inside the “envelope.” At that point, the construction of the “letter” has been completed, so any virtual calls will be properly redirected.
As an example, consider the call to draw( ) inside the virtual constructor. If you trace this call (either by hand or with a debugger), you can see that it starts in the draw( ) function in the base class, Shape. This function calls draw( ) for the “envelope” s pointer to its “letter.” All types derived from Shape share the same interface, so this virtual call is properly executed, even though it seems to be in the constructor. (Actually, the constructor for the “letter” has already completed.) As long as all virtual calls in the base class simply make calls to identical virtual functions through the pointer to the “letter,” the system operates properly.
To understand how it works, consider the code in main( ). To fill the vector shapes, “virtual constructor” calls are made to Shape. Ordinarily in a situation like this, you would call the constructor for the actual type, and the VPTR for that type would be installed in the object. Here, however, the VPTR used in each case is the one for Shape, not the one for the specific Circle, Square, or Triangle.
In the for loop where the draw( ) and erase( ) functions are called for each Shape, the virtual function call resolves, through the VPTR, to the corresponding type. However, this is Shape in each case. In fact, you might wonder why draw( ) and erase( ) were made virtual. The reason shows up in the next step: the base-class version of draw( ) makes a call, through the “letter” pointer s, to the virtual function draw( ) for the “letter.” This time the call resolves to the actual type of the object, not just the base class Shape. Thus, the runtime cost of using virtual constructors is one extra virtual indirection every time you make a virtual function call.
To create any function that is overridden, such as draw( ), erase( ), or test( ), you must forward all calls to the s pointer in the base class implementation, as shown earlier. This is because, when the call is made, the call to the envelope's member function will resolve as being to Shape, and not to a derived type of Shape. Only when you forward the call to s will the virtual behavior take place. In main( ), you can see that everything works correctly, even when calls are made inside constructors and destructors.
Destructor operation
The activities of destruction in this scheme are also tricky. To understand, let's verbally walk through what happens when you call delete for a pointer to a Shape object—specifically, a Square—created on the heap. (This is more complicated than an object created on the stack.) This will be a delete through the polymorphic interface, and will happen via the call to purge( ).
The type of any pointer in shapes is of the base class Shape, so the compiler makes the call through Shape. Normally, you might say that it's a virtual call, so Square's destructor will be called. But with the virtual constructor scheme, the compiler is creating actual Shape objects, even though the constructor initializes the letter pointer to a specific type of Shape. The virtual mechanism is used, but the VPTR inside the Shape object is Shape's VPTR, not Square's. This resolves to Shape's destructor, which calls delete for the letter pointer s, which actually points to a Square object. This is again a virtual call, but this time it resolves to Square's destructor.
C++ guarantees, via the compiler, that all destructors in the hierarchy are called. Square's destructor is called first, followed by any intermediate destructors, in order, until finally the base-class destructor is called. This base-class destructor contains code that says delete s. When this destructor was called originally, it was for the “envelope” s, but now it's for the “letter” s, which is there because the “letter” was inherited from the “envelope,” and not because it contains anything. So this call to delete should do nothing.
The solution to the problem is to make the “letter” s pointer zero. Then when the “letter” base-class destructor is called, you get delete 0, which by definition does nothing. Because the default constructor is protected, it will be called only during the construction of a “letter,” so that's the only situation where s is set to zero.
Although it's interesting, you can see this is a complex approach, and the most common tool for hiding construction will generally be ordinary Factory Methods rather than something like this “virtual constructor” scheme.
3-3-12. Builder: creating complex objects▲
The goal of Builder (which is a Creational pattern, like the Factories we've just looked at) is to separate the construction of an object from its “representation.” This means that the construction process stays the same, but the resulting object has different possible representations. GoF points out that the main difference between Builder and Abstract Factory is that a Builder creates the object step-by-step, so the fact that the creation process is spread out in time seems to be important. In addition, the “director” gets a stream of pieces that it passes to the Builder, and each piece is used to perform one of the steps in the build process.
The following example models a bicycle that can have a choice of parts, according to its type (mountain bike, touring bike, or racing bike). A Builder class is associated with each type of bicycle, and each Builder implements the interface specified in the abstract class BicycleBuilder. A separate class, BicycleTechnician, represents the “director” object described in GoF, and uses a concrete BicycleBuilder object to construct a Bicycle object.
//: C10:Bicycle.h
// Defines classes to build bicycles;
// Illustrates the Builder design pattern.
#ifndef BICYCLE_H
#define BICYCLE_H
#include <iostream>
#include <string>
#include <vector>
#include <cstddef>
#include "../purge.h"
using std::size_t;
class BicyclePart {
public:
enum BPart { FRAME, WHEEL, SEAT, DERAILLEUR,
HANDLEBAR, SPROCKET, RACK, SHOCK, NPARTS };
private:
BPart id;
static std::string names[NPARTS];
public:
BicyclePart(BPart bp) { id = bp; }
friend std::ostream&
operator<<(std::ostream& os, const
BicyclePart& bp) {
return os << bp.names[bp.id];
}
};
class Bicycle {
std::vector<BicyclePart*> parts;
public:
~Bicycle() { purge(parts); }
void addPart(BicyclePart* bp) { parts.push_back(bp);
}
friend std::ostream&
operator<<(std::ostream& os, const
Bicycle& b) {
os << "{ ";
for(size_t i = 0; i < b.parts.size(); ++i)
os << *b.parts[i] << '
';
return os << '}';
}
};
class BicycleBuilder {
protected:
Bicycle* product;
public:
BicycleBuilder() { product = 0; }
void createProduct() { product = new Bicycle; }
virtual void buildFrame() = 0;
virtual void buildWheel() = 0;
virtual void buildSeat() = 0;
virtual void buildDerailleur() = 0;
virtual void buildHandlebar() = 0;
virtual void buildSprocket() = 0;
virtual void buildRack() = 0;
virtual void buildShock() = 0;
virtual std::string getBikeName() const = 0;
Bicycle* getProduct() {
Bicycle* temp = product;
product = 0; // Relinquish product
return temp;
}
};
class MountainBikeBuilder : public BicycleBuilder {
public:
void buildFrame();
void buildWheel();
void buildSeat();
void buildDerailleur();
void buildHandlebar();
void buildSprocket();
void buildRack();
void buildShock();
std::string getBikeName() const { return
"MountainBike";}
};
class TouringBikeBuilder : public BicycleBuilder {
public:
void buildFrame();
void buildWheel();
void buildSeat();
void buildDerailleur();
void buildHandlebar();
void buildSprocket();
void buildRack();
void buildShock();
std::string getBikeName() const { return
"TouringBike"; }
};
class RacingBikeBuilder : public BicycleBuilder {
public:
void buildFrame();
void buildWheel();
void buildSeat();
void buildDerailleur();
void buildHandlebar();
void buildSprocket();
void buildRack();
void buildShock();
std::string getBikeName() const { return
"RacingBike"; }
};
class BicycleTechnician {
BicycleBuilder* builder;
public:
BicycleTechnician() { builder = 0; }
void setBuilder(BicycleBuilder* b) { builder = b; }
void construct();
};
#endif // BICYCLE_H ///:~A Bicycle holds a vector of pointers to BicyclePart, representing the parts used to construct the bicycle. To initiate the construction of a bicycle, a BicycleTechnician (the “director” in this example) calls BicycleBuilder::createproduct( ) on a derived BicycleBuilder object. The BicycleTechnician::construct( ) function calls all the functions in the BicycleBuilder interface (since it doesn't know what type of concrete builder it has). The concrete builder classes omit (via empty function bodies) those actions that do not apply to the type of bicycle they build, as you can see in the following implementation file:
//: C10:Bicycle.cpp {O} {-mwcc}
#include "Bicycle.h"
#include <cassert>
#include <cstddef>
using namespace std;
std::string BicyclePart::names[NPARTS] = {
"Frame", "Wheel",
"Seat", "Derailleur",
"Handlebar", "Sprocket",
"Rack", "Shock" };
// MountainBikeBuilder implementation
void MountainBikeBuilder::buildFrame() {
product->addPart(new
BicyclePart(BicyclePart::FRAME));
}
void MountainBikeBuilder::buildWheel() {
product->addPart(new
BicyclePart(BicyclePart::WHEEL));
}
void MountainBikeBuilder::buildSeat() {
product->addPart(new
BicyclePart(BicyclePart::SEAT));
}
void MountainBikeBuilder::buildDerailleur() {
product->addPart(
new BicyclePart(BicyclePart::DERAILLEUR));
}
void MountainBikeBuilder::buildHandlebar() {
product->addPart(
new BicyclePart(BicyclePart::HANDLEBAR));
}
void MountainBikeBuilder::buildSprocket() {
product->addPart(new
BicyclePart(BicyclePart::SPROCKET));
}
void MountainBikeBuilder::buildRack() {}
void MountainBikeBuilder::buildShock() {
product->addPart(new BicyclePart(BicyclePart::SHOCK));
}
// TouringBikeBuilder implementation
void TouringBikeBuilder::buildFrame() {
product->addPart(new
BicyclePart(BicyclePart::FRAME));
}
void TouringBikeBuilder::buildWheel() {
product->addPart(new
BicyclePart(BicyclePart::WHEEL));
}
void TouringBikeBuilder::buildSeat() {
product->addPart(new
BicyclePart(BicyclePart::SEAT));
}
void TouringBikeBuilder::buildDerailleur() {
product->addPart(
new BicyclePart(BicyclePart::DERAILLEUR));
}
void TouringBikeBuilder::buildHandlebar() {
product->addPart(
new BicyclePart(BicyclePart::HANDLEBAR));
}
void TouringBikeBuilder::buildSprocket() {
product->addPart(new
BicyclePart(BicyclePart::SPROCKET));
}
void TouringBikeBuilder::buildRack() {
product->addPart(new BicyclePart(BicyclePart::RACK));
}
void TouringBikeBuilder::buildShock() {}
// RacingBikeBuilder implementation
void RacingBikeBuilder::buildFrame() {
product->addPart(new
BicyclePart(BicyclePart::FRAME));
}
void RacingBikeBuilder::buildWheel() {
product->addPart(new BicyclePart(BicyclePart::WHEEL));
}
void RacingBikeBuilder::buildSeat() {
product->addPart(new
BicyclePart(BicyclePart::SEAT));
}
void RacingBikeBuilder::buildDerailleur() {}
void RacingBikeBuilder::buildHandlebar() {
product->addPart(
new BicyclePart(BicyclePart::HANDLEBAR));
}
void RacingBikeBuilder::buildSprocket() {
product->addPart(new
BicyclePart(BicyclePart::SPROCKET));
}
void RacingBikeBuilder::buildRack() {}
void RacingBikeBuilder::buildShock() {}
// BicycleTechnician implementation
void BicycleTechnician::construct() {
assert(builder);
builder->createProduct();
builder->buildFrame();
builder->buildWheel();
builder->buildSeat();
builder->buildDerailleur();
builder->buildHandlebar();
builder->buildSprocket();
builder->buildRack();
builder->buildShock();
} ///:~The Bicycle stream inserter calls the corresponding inserter for each BicyclePart, and that prints its type name so that you can see what a Bicycle contains. Here is a sample program:
//: C10:BuildBicycles.cpp
//{L} Bicycle
// The Builder design pattern.
#include <cstddef>
#include <iostream>
#include <map>
#include <vector>
#include "Bicycle.h"
#include "../purge.h"
using namespace std;
// Constructs a bike via a concrete builder
Bicycle* buildMeABike(
BicycleTechnician& t, BicycleBuilder* builder) {
t.setBuilder(builder);
t.construct();
Bicycle* b = builder->getProduct();
cout << "Built a " <<
builder->getBikeName() << endl;
return b;
}
int main() {
// Create an order for some bicycles
map <string, size_t> order;
order["mountain"] = 2;
order["touring"] = 1;
order["racing"] = 3;
// Build bikes
vector<Bicycle*> bikes;
BicycleBuilder* m = new MountainBikeBuilder;
BicycleBuilder* t = new TouringBikeBuilder;
BicycleBuilder* r = new RacingBikeBuilder;
BicycleTechnician tech;
map<string, size_t>::iterator it =
order.begin();
while(it != order.end()) {
BicycleBuilder* builder;
if(it->first == "mountain")
builder = m;
else if(it->first == "touring")
builder = t;
else if(it->first == "racing")
builder = r;
for(size_t i = 0; i < it->second; ++i)
bikes.push_back(buildMeABike(tech, builder));
++it;
}
delete m;
delete t;
delete r;
// Display inventory
for(size_t i = 0; i < bikes.size(); ++i)
cout << "Bicycle: " <<
*bikes[i] << endl;
purge(bikes);
}
/* Output:
Built a MountainBike
Built a MountainBike
Built a RacingBike
Built a RacingBike
Built a RacingBike
Built a TouringBike
Bicycle: {
Frame Wheel Seat Derailleur Handlebar Sprocket Shock
}
Bicycle: {
Frame Wheel Seat Derailleur Handlebar Sprocket Shock
}
Bicycle: { Frame Wheel Seat Handlebar Sprocket }
Bicycle: { Frame Wheel Seat Handlebar Sprocket }
Bicycle: { Frame Wheel Seat Handlebar Sprocket }
Bicycle: {
Frame Wheel Seat Derailleur Handlebar Sprocket Rack }
*/ ///:~The power of this pattern is that it separates the algorithm for assembling parts into a complete product from the parts themselves and allows different algorithms for different products via different implementations of a common interface.
3-3-13. Observer▲
The Observer pattern solves a fairly common problem: what if a group of objects needs to update themselves when some other object changes state? This can be seen in the “model-view” aspect of Smalltalk's MVC (model-view-controller) or the almost-equivalent “Document-View Architecture.” Suppose that you have some data (the “document”) and two views: a plot view and a textual view. When you change the data, the views must be told to update themselves, and that's what the observer facilitates.
Two types of objects are used to implement the observer pattern in the following code. The Observable class keeps track of the objects that want to be informed when a change happens. The Observable class calls the notifyObservers( ) member function for each observer on the list. The notifyObservers( ) member function is part of the base class Observable.
There are two “things that change” in the observer pattern: the quantity of observing objects and the way an update occurs. That is, the observer pattern allows you to modify both of these without affecting the surrounding code.
You can implement the observer pattern in a number of ways, but the code shown here will create a framework from which you can build your own observer code, by following the example. First, this interface describes what an observer looks like:
//: C10:Observer.h
// The Observer interface.
#ifndef OBSERVER_H
#define OBSERVER_H
class Observable;
class Argument {};
class Observer {
public:
// Called by the observed object, whenever
// the observed object is changed:
virtual void update(Observable* o, Argument* arg) =
0;
virtual ~Observer() {}
};
#endif // OBSERVER_H ///:~Since Observer interacts with Observable in this approach, Observable must be declared first. In addition, the Argument class is empty and only acts as a base class for any type of argument you want to pass during an update. If you want, you can simply pass the extra argument as a void*. You'll have to downcast in either case.
The Observer type is an “interface” class that only has one member function, update( ). This function is called by the object that's being observed, when that object decides it's time to update all its observers. The arguments are optional; you could have an update( ) with no arguments, and that would still fit the observer pattern. However this is more general—it allows the observed object to pass the object that caused the update (since an Observer may be registered with more than one observed object) and any extra information if that's helpful, rather than forcing the Observer object to hunt around to see who is updating and to fetch any other information it needs.
The “observed object” will be of type Observable:
//: C10:Observable.h
// The Observable class.
#ifndef OBSERVABLE_H
#define OBSERVABLE_H
#include <set>
#include "Observer.h"
class Observable {
bool changed;
std::set<Observer*> observers;
protected:
virtual void setChanged() { changed = true; }
virtual void clearChanged() { changed = false; }
public:
virtual void addObserver(Observer& o) {
observers.insert(&o);
}
virtual void deleteObserver(Observer& o) {
observers.erase(&o);
}
virtual void deleteObservers() {
observers.clear();
}
virtual int countObservers() {
return observers.size();
}
virtual bool hasChanged() { return changed; }
// If this object has changed, notify all
// of its observers:
virtual void notifyObservers(Argument* arg = 0) {
if(!hasChanged()) return;
clearChanged(); // Not "changed" anymore
std::set<Observer*>::iterator it;
for(it = observers.begin();it != observers.end(); it++)
(*it)->update(this, arg);
}
virtual ~Observable() {}
};
#endif // OBSERVABLE_H ///:~Again, the design here is more elaborate than is necessary. As long as there's a way to register an Observer with an Observable and a way for the Observable to update its Observers, the set of member functions doesn't matter. However, this design is intended to be reusable. (It was lifted from the design used in the Java standard library.)(144)
The Observable object has a flag to indicate whether it's been changed. In a simpler design, there would be no flag; if something happened, everyone would be notified. Notice, however, that the control of the flag's state is protected so that only an inheritor can decide what constitutes a change, and not the end user of the resulting derived Observer class.
The collection of Observer objects is kept in a set<Observer*> to prevent duplicates; the set insert( ), erase( ), clear( ), and size( ) functions are exposed to allow Observers to be added and removed at any time, thus providing runtime flexibility.
Most of the work is done in notifyObservers( ). If the changed flag has not been set, this does nothing. Otherwise, it first clears the changed flag so that repeated calls to notifyObservers( ) won't waste time. This is done before notifying the observers in case the calls to update( ) do anything that causes a change back to this Observable object. It then moves through the set and calls back to the update( ) member function of each Observer.
At first it may appear that you can use an ordinary Observable object to manage the updates. But this doesn't work; to get any effect, you must derive from Observable and somewhere in your derived-class code call setChanged( ). This is the member function that sets the “changed” flag, which means that when you call notifyObservers( ) all the observers will, in fact, get notified. Where you call setChanged( ) depends on the logic of your program.
Now we encounter a dilemma. Objects that are being observed may have more than one such item of interest. For example, if you're dealing with a GUI item—a button, say—the items of interest might be the mouse clicked the button, the mouse moved over the button, and (for some reason) the button changed its color. So we'd like to be able to report all these events to different observers, each of which is interested in a different type of event.
The problem is that we would normally reach for multiple inheritance in such a situation: “I'll inherit from Observable to deal with mouse clicks, and I'll … er … inherit from Observable to deal with mouse-overs, and, well, … hmm, that doesn't work.”
3-3-13-1. The “inner class” idiom▲
Here's a situation where we must (in effect) upcast to more than one type, but in this case we need to provide several different implementations of the same base type. The solution is something we've lifted from Java, which takes C++'s nested class one step further. Java has a built-in feature called an inner class, which is like a nested class in C++, but it has access to the nonstatic data of its containing class by implicitly using the “this” pointer of the class object it was created within.(145)
To implement the inner class idiom in C++, we must obtain and use a pointer to the containing object explicitly. Here's an example:
//: C10:InnerClassIdiom.cpp
// Example of the "inner class" idiom.
#include <iostream>
#include <string>
using namespace std;
class Poingable {
public:
virtual void poing() = 0;
};
void callPoing(Poingable& p) {
p.poing();
}
class Bingable {
public:
virtual void bing() = 0;
};
void callBing(Bingable& b) {
b.bing();
}
class Outer {
string name;
// Define one inner class:
class Inner1;
friend class Outer::Inner1;
class Inner1 : public Poingable {
Outer* parent;
public:
Inner1(Outer* p) : parent(p) {}
void poing() {
cout << "poing called for "
<< parent->name << endl;
// Accesses data in the outer class object
}
} inner1;
// Define a second inner class:
class Inner2;
friend class Outer::Inner2;
class Inner2 : public Bingable {
Outer* parent;
public:
Inner2(Outer* p) : parent(p) {}
void bing() {
cout << "bing called for "
<< parent->name << endl;
}
} inner2;
public:
Outer(const string& nm)
: name(nm), inner1(this), inner2(this) {}
// Return reference to interfaces
// implemented by the inner classes:
operator Poingable&() { return inner1; }
operator Bingable&() { return inner2; }
};
int main() {
Outer x("Ping Pong");
// Like upcasting to multiple base types!:
callPoing(x);
callBing(x);
} ///:~The example (intended to show the simplest syntax for the idiom; you'll see a real use shortly) begins with the Poingable and Bingable interfaces, each containing a single member function. The services provided by callPoing( ) and callBing( ) require that the object they receive implements the Poingable and Bingable interfaces, respectively, but they put no other requirements on that object so as to maximize the flexibility of using callPoing( ) and callBing( ). Note the lack of virtual destructors in either interface—the intent is that you never perform object destruction via the interface.
The Outer constructor contains some private data (name), and it wants to provide both a Poingable interface and a Bingable interface so it can be used with callPoing( ) and callBing( ). (In this situation we could simply use multiple inheritance, but it is kept simple for clarity.) To provide a Poingable object without deriving Outer from Poingable, the inner class idiom is used. First, the declaration class Inner says that, somewhere, there is a nested class of this name. This allows the friend declaration for the class, which follows. Finally, now that the nested class has been granted access to all the private elements of Outer, the class can be defined. Notice that it keeps a pointer to the Outer which created it, and this pointer must be initialized in the constructor. Finally, the poing( ) function from Poingable is implemented. The same process occurs for the second inner class which implements Bingable. Each inner class has a single private instance created, which is initialized in the Outer constructor. By creating the member objects and returning references to them, issues of object lifetime are eliminated.
Notice that both inner class definitions are private, and in fact the client code doesn't have any access to details of the implementation, since the two access functions operator Poingable&( ) and operator Bingable&( ) only return a reference to the upcast interface, not to the object that implements it. In fact, since the two inner classes are private, the client code cannot even downcast to the implementation classes, thus providing complete isolation between interface and implementation.
We've taken the extra liberty here of defining the automatic type conversion functions operator Poingable&( ) and operator Bingable&( ). In main( ), you can see that these allow a syntax that looks as if Outer multiply inherits from Poingable and Bingable. The difference is that the “casts” in this case are one-way. You can get the effect of an upcast to Poingable or Bingable, but you cannot downcast back to an Outer. In the following example of observer, you'll see the more typical approach: you provide access to the inner class objects using ordinary member functions, not automatic type conversion functions.
3-3-13-2. The observer example▲
Armed with the Observer and Observable header files and the inner class idiom, we can look at an example of the Observer pattern:
//: C10:ObservedFlower.cpp
// Demonstration of "observer" pattern.
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
#include "Observable.h"
using namespace std;
class Flower {
bool isOpen;
public:
Flower() : isOpen(false),
openNotifier(this), closeNotifier(this) {}
void open() { // Opens its petals
isOpen = true;
openNotifier.notifyObservers();
closeNotifier.open();
}
void close() { // Closes its petals
isOpen = false;
closeNotifier.notifyObservers();
openNotifier.close();
}
// Using the inner class idiom:
class OpenNotifier;
friend class Flower::OpenNotifier;
class OpenNotifier : public Observable {
Flower* parent;
bool alreadyOpen;
public:
OpenNotifier(Flower* f) : parent(f),
alreadyOpen(false) {}
void notifyObservers(Argument* arg = 0) {
if(parent->isOpen && !alreadyOpen) {
setChanged();
Observable::notifyObservers();
alreadyOpen = true;
}
}
void close() { alreadyOpen = false; }
} openNotifier;
class CloseNotifier;
friend class Flower::CloseNotifier;
class CloseNotifier : public Observable {
Flower* parent;
bool alreadyClosed;
public:
CloseNotifier(Flower* f) : parent(f),
alreadyClosed(false) {}
void notifyObservers(Argument* arg = 0) {
if(!parent->isOpen && !alreadyClosed)
{
setChanged();
Observable::notifyObservers();
alreadyClosed = true;
}
}
void open() { alreadyClosed = false; }
} closeNotifier;
};
class Bee {
string name;
// An inner class for observing openings:
class OpenObserver;
friend class Bee::OpenObserver;
class OpenObserver : public Observer {
Bee* parent;
public:
OpenObserver(Bee* b) : parent(b) {}
void update(Observable*, Argument *) {
cout << "Bee " <<
parent->name
<< "'s breakfast time!” <<
endl;
}
} openObsrv;
// Another inner class for closings:
class CloseObserver;
friend class Bee::CloseObserver;
class CloseObserver : public Observer {
Bee* parent;
public:
CloseObserver(Bee* b) : parent(b) {}
void update(Observable*, Argument *) {
cout << "Bee " <<
parent->name
<< "'s bed time!” << endl;
}
} closeObsrv;
public:
Bee(string nm) : name(nm),
openObsrv(this), closeObsrv(this) {}
Observer& openObserver() { return openObsrv; }
Observer& closeObserver() { return closeObsrv;}
};
class Hummingbird {
string name;
class OpenObserver;
friend class Hummingbird::OpenObserver;
class OpenObserver : public Observer {
Hummingbird* parent;
public:
OpenObserver(Hummingbird* h) : parent(h) {}
void update(Observable*, Argument *) {
cout << "Hummingbird " <<
parent->name
<< "'s breakfast time!” <<
endl;
}
} openObsrv;
class CloseObserver;
friend class Hummingbird::CloseObserver;
class CloseObserver : public Observer {
Hummingbird* parent;
public:
CloseObserver(Hummingbird* h) : parent(h) {}
void update(Observable*, Argument *) {
cout << "Hummingbird " <<
parent->name
<< "'s bed time!” << endl;
}
} closeObsrv;
public:
Hummingbird(string nm) : name(nm),
openObsrv(this), closeObsrv(this) {}
Observer& openObserver() { return openObsrv; }
Observer& closeObserver() { return closeObsrv;}
};
int main() {
Flower f;
Bee ba("A"), bb("B");
Hummingbird ha("A"), hb("B");
f.openNotifier.addObserver(ha.openObserver());
f.openNotifier.addObserver(hb.openObserver());
f.openNotifier.addObserver(ba.openObserver());
f.openNotifier.addObserver(bb.openObserver());
f.closeNotifier.addObserver(ha.closeObserver());
f.closeNotifier.addObserver(hb.closeObserver());
f.closeNotifier.addObserver(ba.closeObserver());
f.closeNotifier.addObserver(bb.closeObserver());
// Hummingbird B decides to sleep in:
f.openNotifier.deleteObserver(hb.openObserver());
// Something changes that interests observers:
f.open();
f.open(); // It's already open, no change.
// Bee A doesn't want to go to bed:
f.closeNotifier.deleteObserver(
ba.closeObserver());
f.close();
f.close(); // It's already closed; no change
f.openNotifier.deleteObservers();
f.open();
f.close();
} ///:~The events of interest are that a Flower can open or close. Because of the use of the inner class idiom, both these events can be separately observable phenomena. The OpenNotifier and CloseNotifier classes both derive from Observable, so they have access to setChanged( ) and can be handed to anything that needs an Observable. You'll notice that, contrary to InnerClassIdiom.cpp, the Observable descendants are public. This is because some of their member functions must be available to the client programmer. There's nothing that says that an inner class must be private; in InnerClassIdiom.cpp we were simply following the design guideline “make things as private as possible.” You could make the classes private and expose the appropriate member functions by proxy in Flower, but it wouldn't gain much.
The inner class idiom also comes in handy to define more than one kind of Observer in Bee and Hummingbird, since both those classes may want to independently observe Flower openings and closings. Notice how the inner class idiom provides something that has most of the benefits of inheritance (the ability to access the private data in the outer class, for example).
In main( ), you can see one of the primary benefits of the Observer pattern: the ability to change behavior at runtime by dynamically registering and unregistering Observers with Observables. This flexibility is achieved at the cost of significant additional code—you will often see this kind of tradeoff in design patterns: more complexity in one place in exchange for increased flexibility and/or lowered complexity in another place.
If you study the previous example, you'll see that OpenNotifier and CloseNotifier use the basic Observable interface. This means that you could derive from other completely different Observer classes; the only connection the Observers have with Flowers is the Observer interface.
Another way to accomplish this fine granularity of observable phenomena is to use some form of tags for the phenomena, for example empty classes, strings, or enumerations that denote different types of observable behavior. This approach can be implemented using aggregation rather than inheritance, and the differences are mainly tradeoffs between time and space efficiency. For the client, the differences are negligible.
3-3-14. Multiple dispatching▲
When dealing with multiple interacting types, a program can get particularly messy. For example, consider a system that parses and executes mathematical expressions. You want to be able to say Number + Number, Number * Number, and so on, where Number is the base class for a family of numerical objects. But when you say a + b, and you don't know the exact type of either a or b, how can you get them to interact properly?
The answer starts with something you probably don't think about: C++ performs only single dispatching. That is, if you are performing an operation on more than one object whose type is unknown, C++ can invoke the dynamic binding mechanism on only one of those types. This doesn't solve the problem described here, so you end up detecting some types manually and effectively producing your own dynamic binding behavior.
The solution is called multiple dispatching (described in GoF in the context of the Visitor pattern, shown in the next section). Here, there will be only two dispatches, which is referred to as double dispatching. Remember that polymorphism can occur only via virtual function calls, so if you want multiple dispatching to occur, there must be a virtual function call to determine each unknown type. Thus, if you are working with two different type hierarchies that are interacting, you'll need a virtual call in each hierarchy. Generally, you'll set up a configuration such that a single member function call generates more than one virtual member function call and thus determines more than one type in the process: you'll need a virtual function call for each dispatch. The virtual functions in the following example are called compete( ) and eval( ) and are both members of the same type (this is not a requirement for multiple dispatching):(146)
//: C10:PaperScissorsRock.cpp
// Demonstration of multiple dispatching.
#include <algorithm>
#include <iostream>
#include <iterator>
#include <vector>
#include <ctime>
#include <cstdlib>
#include "../purge.h"
using namespace std;
class Paper;
class Scissors;
class Rock;
enum Outcome { WIN, LOSE, DRAW };
ostream& operator<<(ostream& os, const
Outcome out) {
switch(out) {
default:
case WIN: return os << "win";
case LOSE: return os << "lose";
case DRAW: return os << "draw";
}
}
class Item {
public:
virtual Outcome compete(const Item*) = 0;
virtual Outcome eval(const Paper*) const = 0;
virtual Outcome eval(const Scissors*) const= 0;
virtual Outcome eval(const Rock*) const = 0;
virtual ostream& print(ostream& os) const =
0;
virtual ~Item() {}
friend ostream& operator<<(ostream& os,
const Item* it) {
return it->print(os);
}
};
class Paper : public Item {
public:
Outcome compete(const Item* it) { return
it->eval(this);}
Outcome eval(const Paper*) const { return DRAW; }
Outcome eval(const Scissors*) const { return WIN; }
Outcome eval(const Rock*) const { return LOSE; }
ostream& print(ostream& os) const {
return os << "Paper ";
}
};
class Scissors : public Item {
public:
Outcome compete(const Item* it) { return
it->eval(this);}
Outcome eval(const Paper*) const { return LOSE; }
Outcome eval(const Scissors*) const { return DRAW; }
Outcome eval(const Rock*) const { return WIN; }
ostream& print(ostream& os) const {
return os << "Scissors";
}
};
class Rock : public Item {
public:
Outcome compete(const Item* it) { return
it->eval(this);}
Outcome eval(const Paper*) const { return WIN; }
Outcome eval(const Scissors*) const { return LOSE; }
Outcome eval(const Rock*) const { return DRAW; }
ostream& print(ostream& os) const {
return os << "Rock ";
}
};
struct ItemGen {
Item* operator()() {
switch(rand() % 3) {
default:
case 0: return new Scissors;
case 1: return new Paper;
case 2: return new Rock;
}
}
};
struct Compete {
Outcome operator()(Item* a, Item* b) {
cout << a << "\t" << b
<< "\t";
return a->compete(b);
}
};
int main() {
srand(time(0)); // Seed the random number generator
const int sz = 20;
vector<Item*> v(sz*2);
generate(v.begin(), v.end(), ItemGen());
transform(v.begin(), v.begin() + sz,
v.begin() + sz,
ostream_iterator<Outcome>(cout,
"\n"),
Compete());
purge(v);
} ///:~Outcome categorizes the different possible results of a compete( ), and the operator<< simplifies the process of displaying a particular Outcome.
Item is the base class for the types that will be multiply-dispatched. Compete::operator( ) takes two Item* (the exact type of both are unknown) and begins the double-dispatching process by calling the virtual Item::compete( ) function. The virtual mechanism determines the type a, so it wakes up inside the compete( ) function of a's concrete type. The compete( ) function performs the second dispatch by calling eval( ) on the remaining type. Passing itself (this) as an argument to eval( ) produces a call to the overloaded eval( ) function, thus preserving the type information of the first dispatch. When the second dispatch is completed, you know the exact types of both Item objects.
In main( ),the STL algorithm generate( ) populates the vector v, then transform( ) applies Compete::operator( ) to the two ranges. This version of transform( ) takes the start and end point of the first range (containing the left-hand Items used in the double dispatch); the starting point of the second range, which holds the right-hand Items; the destination iterator, which in this case is standard output; and the function object (a temporary of type Compete)to call for each object.
It requires a lot of ceremony to set up multiple dispatching, but keep in mind that the benefit is the syntactic elegance achieved when making the call—instead of writing awkward code to determine the type of one or more objects during a call, you simply say: “You two! I don't care what types you are, interact properly with each other!” Make sure this kind of elegance is important to you before embarking on multiple dispatching, however.
Note that multiple dispatching is, in effect, performing a table lookup. Here, the lookup is performed using virtual functions, but you could instead perform a literal table lookup. With more than a few dispatches (and if you are prone to making additions and changes), a table lookup may be a better solution to the problem.
3-3-14-1. Multiple dispatching with Visitor▲
The goal of Visitor (the final, and arguably most complex, pattern in GoF) is to separate the operations on a class hierarchy from the hierarchy itself. This is quite an odd motivation because most of what we do in object-oriented programming is to combine data and operations into objects, and to use polymorphism to automatically select the correct variation of an operation, depending on the exact type of an object.
With Visitor you extract the operations from inside your class hierarchy into a separate, external hierarchy. The “main” hierarchy then contains a visit( ) function that accepts any object from your hierarchy of operations. As a result, you get two class hierarchies instead of one. In addition, you'll see that your “main” hierarchy becomes very brittle—if you add a new class, you will force changes throughout the second hierarchy. GoF says that the main hierarchy should thus “rarely change.” This constraint is very limiting, and it further reduces the applicability of this pattern.
For the sake of argument, then, assume that you have a primary class hierarchy that is fixed; perhaps it's from another vendor and you can't make changes to that hierarchy. If you had the source code for the library, you could add new virtual functions in the base class, but this is, for some reason, not feasible. A more likely scenario is that adding new virtual functions is somehow awkward, ugly or otherwise difficult to maintain. GoF argues that “distributing all these operations across the various node classes leads to a system that's hard to understand, maintain, and change.” (As you'll see, Visitor can be much harder to understand, maintain and change.) Another GoF argument is that you want to avoid “polluting” the interface of the main hierarchy with too many operations (but if your interface is too “fat,” you might ask whether the object is trying to do too many things).
The library creator must have foreseen, however, that you will want to add new operations to that hierarchy, so that they can know to include the visit( ) function.
So (assuming you really need to do this) the dilemma is that you need to add member functions to the base class, but for some reason you can't touch the base class. How do you get around this?
Visitor builds on the double-dispatching scheme shown in the previous section. The Visitor pattern allows you to effectively extend the interface of the primary type by creating a separate class hierarchy of type Visitor to “virtualize” the operations performed on the primary type. The objects of the primary type simply “accept” the visitor and then call the visitor's dynamically bound member function. Thus, you create a visitor, pass it into the primary hierarchy, and you get the effect of a virtual function. Here's a simple example:
//: C10:BeeAndFlowers.cpp
// Demonstration of "visitor" pattern.
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
#include <ctime>
#include <cstdlib>
#include "../purge.h"
using namespace std;
class Gladiolus;
class Renuculus;
class Chrysanthemum;
class Visitor {
public:
virtual void visit(Gladiolus* f) = 0;
virtual void visit(Renuculus* f) = 0;
virtual void visit(Chrysanthemum* f) = 0;
virtual ~Visitor() {}
};
class Flower {
public:
virtual void accept(Visitor&) = 0;
virtual ~Flower() {}
};
class Gladiolus : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
class Renuculus : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
class Chrysanthemum : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
// Add the ability to produce a string:
class StringVal : public Visitor {
string s;
public:
operator const string&() { return s; }
virtual void visit(Gladiolus*) {
s = "Gladiolus";
}
virtual void visit(Renuculus*) {
s = "Renuculus";
}
virtual void visit(Chrysanthemum*) {
s = "Chrysanthemum";
}
};
// Add the ability to do "Bee" activities:
class Bee : public Visitor {
public:
virtual void visit(Gladiolus*) {
cout << "Bee and Gladiolus” <<
endl;
}
virtual void visit(Renuculus*) {
cout << "Bee and Renuculus” <<
endl;
}
virtual void visit(Chrysanthemum*) {
cout << "Bee and Chrysanthemum” <<
endl;
}
};
struct FlowerGen {
Flower* operator()() {
switch(rand() % 3) {
default:
case 0: return new Gladiolus;
case 1: return new Renuculus;
case 2: return new Chrysanthemum;
}
}
};
int main() {
srand(time(0)); // Seed the random number generator
vector<Flower*> v(10);
generate(v.begin(), v.end(), FlowerGen());
vector<Flower*>::iterator it;
// It's almost as if I added a virtual function
// to produce a Flower string representation:
StringVal sval;
for(it = v.begin(); it != v.end(); it++) {
(*it)->accept(sval);
cout << string(sval) << endl;
}
// Perform Bee operation on all Flowers:
Bee bee;
for(it = v.begin(); it != v.end(); it++)
(*it)->accept(bee);
purge(v);
} ///:~Flower is the primary hierarchy, and each subtype of Flower can accept( ) a Visitor. The Flower hierarchy has no operations other than accept( ), so all the functionality of the Flower hierarchy is contained in the Visitor hierarchy. Note that the Visitor classes must know about all the specific types of Flower, and if you add a new type of Flower the entire Visitor hierarchy must be reworked.
The accept( ) function in each Flower begins a double dispatch as described in the previous section. The first dispatch determines the exact type of Flower and the second determines the exact type of Visitor. Once you know the exact types you can perform an operation appropriate to both.
It's very unlikely that you'll use Visitor because its motivation is unusual and its constraints are stultifying. The GoF examples are not convincing—the first is a compiler (not many people write compilers, and it seems quite rare that Visitor is used within these compilers), and they apologize for the other examples, saying you wouldn't actually use Visitor for anything like this. You would need a stronger compulsion than that presented in GoF to abandon an ordinary OO structure for Visitor—what benefit does it really buy you in exchange for much greater complexity and constraint? Why can't you simply add more virtual functions in the base class when you discover you need them? Or, if you really need to paste new functions into an existing hierarchy and you are unable to modify that hierarchy, why not try multiple inheritance first? (Even then, the likelihood of “saving” the existing hierarchy this way is slim). Consider also that, to use Visitor, the existing hierarchy must incorporate a visit( ) function from the beginning, because to add it later would mean that you had permission to modify the hierarchy, so you could just add ordinary virtual functions as you need them. No, Visitor must be part of the architecture from the beginning, and to use it requires a motivation greater than that in GoF.(147)
We present Visitor here because we have seen it used when it shouldn't be, just as multiple inheritance and any number of other approaches have been used inappropriately. If you find yourself using Visitor, ask why. Are you really unable to add new virtual functions in the base class? Do you really want to be restricted from adding new types in your primary hierarchy?
3-3-15. Summary▲
The point of design patterns, like the point of any abstraction, is to make your life easier. Usually something in your system is changing—this could be code during the lifetime of the project, or objects during the lifetime of one program execution. Discover what is changing, and a design pattern may help you encapsulate that change, and thus bring it under control.
It's easy to get infatuated with a particular design, and to create trouble for yourself by applying it just because you know how. What's hard, ironically, is to follow the XP maxim of “do the simplest thing that could possibly work.” But by doing the simplest thing, you not only get a design that's faster to implement, but also easier to maintain. And if the simplest thing doesn't do the job, you'll find out a lot sooner than if you spend the time implementing something complex, and then find out that doesn't work.
3-3-16. Exercises▲
Solutions to selected exercises can be found in the electronic document The Thinking in C++ Volume 2 Annotated Solution Guide, available for a small fee from www.MindView.net.
- Create a variation of SingletonPattern.cpp where all functions are static. Is the instance( ) function still necessary in this case?
- Starting with SingletonPattern.cpp, create a class that provides a connection to a service that stores and retrieves data from a configuration file.
- Using SingletonPattern.cpp as a starting point, create a class that manages a fixed number of its own objects. Assume the objects are database connections and you only have a license to use a fixed quantity of these at any one time.
- Modify KissingPrincess2.cpp by adding another state to the system, so that each kiss cycles the creature to the next state.
- Find C16:TStack.h from Thinking in C++, Volume 1, 2nd Edition (downloadable from www. BruceEckel.com). Create an Adapter for this class such that you can apply the STL algorithm for_each( ) to the elements of the TStack, using your adapter. Create a TStack of string, fill it with strings and use for_each( ) to count all the letters in all the strings in the TStack.
- Create a framework (that is, use the Template Method pattern)
that takes a list of file names on the command line. It opens each file except
the last for reading, and the last file it opens for writing. The framework
will process each input file using an undetermined policy and write the output
to the last file. Inherit to customize this framework to create two separate
applications:
1) Converts all the letters in each file to uppercase.
2) Searches the files for words given in the first file. - Modify Exercise 6 to use Strategy instead of Template Method.
- Modify Strategy.cpp to include State behavior, so that the Strategy can be changed during the lifetime of the Context object.
- Modify Strategy.cpp to use a Chain of Responsibility approach, where you keep trying different ways to get someone to say their name without admitting you've forgotten it.
- Add a class Triangle to ShapeFactory1.cpp.
- Add a class Triangle to ShapeFactory2.cpp.
- Add a new type of GameEnvironment called GnomesAndFairies to AbstractFactory.cpp.
- Modify ShapeFactory2.cpp so that it uses an Abstract Factory to create different sets of shapes (for example, one particular type of factory object creates “thick shapes,” another creates “thin shapes,” but each factory object can create all the shapes: circles, squares, triangles, and so on).
- Modify VirtualConstructor.cpp to use a map instead of if-else statements inside Shape::Shape(string type).
- Break a text file up into an input stream of words (keep it simple: just break the input stream on white space). Create one Builder that puts the words into a set, and another that produces a map containing words and occurrences of those words (that is, it does a word count).
- Create a minimal Observer-Observable design in two classes, without base classes and without the extra arguments in Observer.h and the member functions in Observable.h. Just create the bare minimum in the two classes, and then demonstrate your design by creating one Observable and many Observers and cause the Observable to update the Observers.
- Change InnerClassIdiom.cpp so that Outer uses multiple inheritance instead of the inner class idiom.
- Modify PaperScissorsRock.java to replace the double
dispatch with a table lookup. The easiest way to do this is to create a map of
maps, with the key of each map the typeid(obj).name( )
information of each object. Then you can do the lookup by saying: map[typeid(obj1).name( )][typeid(obj2).name( )].
Notice how much easier it is to reconfigure the system. When is it more appropriate to use this approach vs. hard-coding the dynamic dispatches? Can you create a system that has the syntactic simplicity of use of the dynamic dispatch but uses a table lookup? - Create a business-modeling environment with three types of Inhabitant: Dwarf (for engineers), Elf (for marketers), and Troll (for managers). Now create a class called Project that instantiates the different inhabitants and causes them to interact( ) with each other using multiple dispatching.
- Modify the previous exercise to make the interactions more detailed. Each Inhabitant can randomly produce a Weapon using getWeapon( ): a Dwarf uses Jargon or Play, an Elf uses InventFeature or SellImaginaryProduct, and a Troll uses Edict and Schedule. You decide which weapons “win” and “lose” in each interaction (as in PaperScissorsRock.cpp). Add a battle( ) member function to Project that takes two Inhabitants and matches them against each other. Now create a meeting( ) member function for Project that creates groups of Dwarf, Elf, and Manager and battles the groups against each other until only members of one group are left standing. These are the “winners.”
- Add a Hummingbird Visitor to BeeAndFlowers.cpp.
- Add a Sunflower type to BeeAndFlowers.cpp and notice what you need to change to accommodate this new type.
- Modify BeeAndFlowers.cpp so that it does not use Visitor, but “reverts” to a regular class hierarchy instead. Turn Bee into a collecting parameter.
3-4. Concurrency▲
Objects provide a way to divide a program into independent sections. Often, you also need to partition a program into separate, independently running subtasks.
Using multithreading, each of these independent subtasks is driven by a thread of execution, and you program as if each thread has the CPU to itself. An underlying mechanism is dividing up the CPU time for you, but in general, you don't need to think about it, which helps to simplify programming with multiple threads.
A process is a self-contained program running within its own address space. A multitasking operating system can run more than one process (program) at a time, while making it look as if each one is chugging along on its own, by periodically switching the CPU from one task to another. A thread is a single sequential flow of control within a process. A single process can thus have multiple concurrently executing threads. Since the threads run within a single process, they share memory and other resources. The fundamental difficulty in writing multithreaded programs is coordinating the use of those resources between different threads.
There are many possible uses for multithreading, but you'll most often want to use it when you have some part of your program tied to a particular event or resource. To keep from holding up the rest of your program, you create a thread associated with that event or resource and let it run independently of the main program.
Concurrent programming is like stepping into an entirely new world and learning a new programming language, or at least a new set of language concepts. With the appearance of thread support in most microcomputer operating systems, extensions for threads have also been appearing in programming languages or libraries. In all cases, thread programming:
1. Seems mysterious and requires a shift in the way you think about programming.
2. Looks similar to thread support in other languages. When you understand threads, you understand a common tongue.
Understanding concurrent programming is on the same order of difficulty as understanding polymorphism. If you apply some effort, you can fathom the basic mechanism, but it generally takes deep study and understanding to develop a true grasp of the subject. The goal of this chapter is to give you a solid foundation in the basics of concurrency so that you can understand the concepts and write reasonable multithreaded programs. Be aware that you can easily become overconfident. If you are writing anything complex, you will need to study dedicated books on the topic.
3-4-1. Motivation▲
One of the most compelling reasons for using concurrency is to produce a responsive user interface. Consider a program that performs some CPU-intensive operation and thus ends up ignoring user input and being unresponsive. The program needs to continue performing its operations, and at the same time it needs to return control to the user interface so that the program can respond to the user. If you have a “quit” button, you don't want to be forced to poll it in every piece of code you write in your program. (This would couple your quit button across the program and be a maintenance headache.) Yet you want the quit button to be responsive, as if you were checking it regularly.
A conventional function cannot continue performing its operations and at the same time return control to the rest of the program. In fact, this sounds like an impossibility, as if the CPU must be in two places at once, but this is precisely the illusion that concurrency provides (in the case of multiprocessor systems, this may be more than an illusion).
You can also use concurrency to optimize throughput. For example, you might be able to do important work while you're stuck waiting for input to arrive on an I/O port. Without threading, the only reasonable solution is to poll the I/O port, which is awkward and can be difficult.
If you have a multiprocessor machine, multiple threads can be distributed across multiple processors, which can dramatically improve throughput. This is often the case with powerful multiprocessor web servers, which can distribute large numbers of user requests across CPUs in a program that allocates one thread per request.
A program that uses threads on a single-CPU machine is still just doing one thing at a time, so it must be theoretically possible to write the same program without using any threads. However, multithreading provides an important organizational benefit: The design of your program can be greatly simplified. Some types of problems, such as simulation—a video game, for example—are difficult to solve without support for concurrency.
The threading model is a programming convenience to simplify juggling several operations at the same time within a single program: The CPU will pop around and give each thread some of its time.(148) Each thread has the consciousness of constantly having the CPU to itself, but the CPU's time is actually sliced among all the threads. The exception is a program that is running on multiple CPU. But one of the great things about threading is that you are abstracted away from this layer, so your code does not need to know whether it is running on a single CPU or many.(149) Thus, using threads is a way to create transparently scalable programs—if a program is running too slowly, you can easily speed it up by adding CPUs to your computer. Multitasking and multithreading tend to be the most reasonable ways to utilize multiprocessor systems.
Threading can reduce computing efficiency somewhat, but the net improvement in program design, resource balancing, and user convenience is often quite valuable. In general, threads enable you to create a more loosely coupled design; otherwise, parts of your code would be forced to pay explicit attention to tasks that would normally be handled by threads.
3-4-2. Concurrency in C++▲
When the C++ Standards Committee was creating the initial C++ Standard, a concurrency mechanism was explicitly excluded because C didn't have one and also because there were a number of competing approaches to implementing concurrency. It seemed too much of a constraint to force programmers to use only one of these.
The alternative turned out to be worse, however. To use concurrency, you had to find and learn a library and deal with its idiosyncrasies and the uncertainties of working with a particular vendor. In addition, there was no guarantee that such a library would work on different compilers or across different platforms. Also, since concurrency was not part of the standard language, it was more difficult to find C++ programmers who also understood concurrent programming.
Another influence may have been the Java language, which included concurrency in the core language. Although multithreading is still complicated, Java programmers tend to start learning and using it from the beginning.
The C++ Standards Committee is considering the addition of concurrency support to the next iteration of C++, but at the time of this writing it is unclear what the library will look like. We decided to use the ZThread library as the basis for this chapter. We preferred the design, and it is open-source and freely available at http://zthread.sourceforge.net. Eric Crahen of IBM, the author of the ZThread library, was instrumental in creating this chapter.(150)
This chapter uses only a subset of the ZThread library, in order to convey the fundamental ideas of threading. The ZThread library contains significantly more sophisticated thread support than is shown here, and you should study that library further in order to fully understand its capabilities.
3-4-2-1. Installing ZThreads▲
Please note that the ZThread library is an independent project and is not supported by the authors of this book; we are simply using the library in this chapter and cannot provide technical support for installation issues. See the ZThread web site for installation support and error reports.
The ZThread library is distributed as source code. After downloading it (version 2.3 or greater) from the ZThread web site, you must first compile the library, and then configure your project to use the library.
The preferred method for compiling ZThreads for most flavors of UNIX (Linux, SunOS, Cygwin, etc.) is to use the configure script. After unpacking the files (using tar),simply execute:
./configure && make
installfrom the main directory of the ZThreads archive to compile and install a copy of the library in the /usr/local directory. You can customize a number of options when using this script, including the locations of files. For details, use this command:
./configure -helpThe ZThreads code is structured to simplify compilation for other platforms and compilers (such as Borland, Microsoft, and Metrowerks). To do this, create a new project and add all the .cxx files in the src directory of the ZThreads archive to the list of files to be compiled. Also, be sure to include the include directory of the archive in the header search path for your project. The exact details will vary from compiler to compiler so you'll need to be somewhat familiar with your toolset to be able to use this option.
Once the compilation has succeeded, the next step is to create a project that uses the newly compiled library. First, let the compiler know where the headers are located so that your #include statements will work properly. Typically, you will add an option such as the following to your project:
-I/path/to/installation/includeIf you used the configure script, the installation path will be whatever you selected for the prefix (which defaults to /usr/local). If you used one of the project files in the build directory, the installation path would simply be the path to the main directory of the ZThreads archive.
Next, you'll need to add an option to your project that will let the linker know where to find the library. If you used the configure script, this will look like:
-L/path/to/installation/lib
-lZThreadIf you used one of the project files provided, this will look like:
-L/path/to/installation/Debug
ZThread.libAgain, if you used the configure script, the installation path will be whatever you selected for the prefix. If you used a provided project file, the path will be the path to the main directory of the ZThreads archive.
Note that if you're using Linux, or if you are using Cygwin (www.cygwin.com) under Windows, you may not need to modify your include or library path; the installation process and defaults will often take care of everything for you.
Under Linux, you will probably need to add the following to your .bashrc so that the runtime system can find the shared library file LibZThread-x.x.so.O when it executes the programs in this chapter:
export LD_LIBRARY_PATH=/usr/local/lib:${LD_LIBRARY_PATH}
(Assuming you used the default installation process and the shared library ended up in /user/local/lib; otherwise, change the path to your location).
3-4-3. Defining Tasks▲
A thread carries out a task, so you need a way to describe that task. The Runnable class provides a common interface to execute any arbitrary task. Here is the core of the ZThread Runnable class, which you will find in Runnable.h in the include directory, after installing the ZThread library:
class Runnable {
public:
virtual void run() = 0;
virtual ~Runnable() {}
};By making this an abstract base class, Runnable is easily combinable with a base class and other classes.
To define a task, simply inherit from the Runnable class and override run( ) to make the task do your bidding.
For example, the following LiftOff task displays the countdown before liftoff:
//: C11:LiftOff.h
// Demonstration of the Runnable interface.
#ifndef LIFTOFF_H
#define LIFTOFF_H
#include <iostream>
#include "zthread/Runnable.h"
class LiftOff : public ZThread::Runnable {
int countDown;
int id;
public:
LiftOff(int count, int ident = 0) :
countDown(count), id(ident) {}
~LiftOff() {
std::cout << id << "
completed" << std::endl;
}
void run() {
while(countDown--)
std::cout << id << ":"
<< countDown << std::endl;
std::cout << "Liftoff!" <<
std::endl;
}
};
#endif // LIFTOFF_H ///:~The identifier id distinguishes between multiple instances of the task. If you only make a single instance, you can use the default value for ident. The destructor will allow you to see that a task is properly destroyed.
In the following example, the task's run( ) is not driven by a separate thread; it is simply called directly in main( ):
//: C11:NoThread.cpp
#include "LiftOff.h"
int main() {
LiftOff launch(10);
launch.run();
} ///:~When a class is derived from Runnable, it must have a run( ) function, but that's nothing special—it doesn't produce any innate threading abilities.
To achieve threading behavior, you must use the Thread class.
3-4-4. Using Threads▲
To drive a Runnable object with a thread, you create a separate Thread object and hand a Runnable pointer to the Thread'sconstructor. This performs the thread initialization and then calls the Runnable's run( ) as an interruptible thread. By driving LiftOff with a Thread, the example below shows how any task can be run in the context of another thread:
//: C11:BasicThreads.cpp
// The most basic use of the Thread class.
//{L} ZThread
#include <iostream>
#include "LiftOff.h"
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
int main() {
try {
Thread t(new LiftOff(10));
cout << "Waiting for LiftOff"
<< endl;
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Synchronization_Exception is part of the ZThread library and is the base class for all ZThread exceptions. It will be thrown if there is an error starting or using a thread.
A Thread constructor only needs a pointer to a Runnable object. Creating a Thread object will perform the necessary initialization for the thread and then call that Runnable's run( ) member function to start the task. Even though the Thread constructor is, in effect, making a call to a long-running function, that constructor quickly returns. In effect, you have made a member function call to LiftOff::run( ), and that function has not yet finished, but because LiftOff::run( ) is being executed by a different thread, you can still perform other operations in the main( ) thread. (This ability is not restricted to the main( ) thread—any thread can start another thread.) You can see this by running the program. Even though LiftOff::run( ) has been called, the “Waiting for LiftOff” message will appear before the countdown has completed. Thus, the program is running two functions at once—LiftOff::run( ) and main( ).
You can easily add more threads to drive more tasks. Here, you can see how all the threads run in concert with one another:
//: C11:MoreBasicThreads.cpp
// Adding more threads.
//{L} ZThread
#include <iostream>
#include "LiftOff.h"
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
int main() {
const int SZ = 5;
try {
for(int i = 0; i < SZ; i++)
Thread t(new LiftOff(10, i));
cout << "Waiting for LiftOff"
<< endl;
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The second argument for the LiftOff constructor identifies each task. When you run the program, you'll see that the execution of the different tasks is mixed together as the threads are swapped in and out. This swapping is automatically controlled by the thread scheduler. If you have multiple processors on your machine, the thread scheduler will quietly distribute the threads among the processors.
The for loop can seem a little strange at first because t is being created locally inside the for loop and then immediately goes out of scope and is destroyed. This makes it appear that the thread itself might be immediately lost, but you can see from the output that the threads are indeed running to conclusion. When you create a Thread object, the associated thread is registered with the threading system, which keeps it alive. Even though the stack-based Thread object is lost, the thread itself lives on until its associated task completes. Although this may be counterintuitive from a C++ standpoint, the concept of threads is a departure from the norm: a thread creates a separate thread of execution that persists after the function call ends. This departure is reflected in the persistence of the underlying thread after the object vanishes.
3-4-4-1. Creating responsive user interfaces▲
As stated earlier, one of the motivations for using threading is to create a responsive user interface. Although we don't cover graphical user interfaces in this book, you can still see a simple example of a console-based user interface.
The following example reads lines from a file and prints them to the console, sleeping (suspending the current thread) for a second after each line is displayed. (You'll learn more about sleeping later in the chapter.) During this process, the program doesn't look for user input, so the UI is unresponsive:
//: C11:UnresponsiveUI.cpp {RunByHand}
// Lack of threading produces an unresponsive UI.
//{L} ZThread
#include <iostream>
#include <fstream>
#include <string>
#include "zthread/Thread.h"
using namespace std;
using namespace ZThread;
int main() {
cout << "Press <Enter> to
quit:" << endl;
ifstream file("UnresponsiveUI.cpp");
string line;
while(getline(file, line)) {
cout << line << endl;
Thread::sleep(1000); // Time in milliseconds
}
// Read input from the console
cin.get();
cout << "Shutting down..." <<
endl;
} ///:~To make the program responsive, you can execute a task that displays the file in a separate thread. The main thread can then watch for user input so the program becomes responsive:
//: C11:ResponsiveUI.cpp {RunByHand}
// Threading for a responsive user interface.
//{L} ZThread
#include <iostream>
#include <fstream>
#include <string>
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
class DisplayTask : public Runnable {
ifstream in;
string line;
bool quitFlag;
public:
DisplayTask(const string& file) : quitFlag(false)
{
in.open(file.c_str());
}
~DisplayTask() { in.close(); }
void run() {
while(getline(in, line) && !quitFlag) {
cout << line << endl;
Thread::sleep(1000);
}
}
void quit() { quitFlag = true; }
};
int main() {
try {
cout << "Press <Enter> to
quit:" << endl;
DisplayTask* dt = new
DisplayTask("ResponsiveUI.cpp");
Thread t(dt);
cin.get();
dt->quit();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
cout << "Shutting down..." <<
endl;
} ///:~Now the main( ) thread can respond immediately when you press <Return> and call quit( ) on the DisplayTask.
This example also shows the need for communication between tasks—the task in the main( ) thread needs to tell the DisplayTask to shut down. Since we have a pointer to the DisplayTask, you might think of just calling delete on that pointer to kill the task, but this produces unreliable programs. The problem is that the task could be in the middle of something important when you destroy it, and so you are likely to put the program in an unstable state. Here, the task itself decides when it's safe to shut down. The easiest way to do this is by simply notifying the task that you'd like it to stop by setting a Boolean flag. When the task gets to a stable point it can check that flag and do whatever is necessary to clean up before returning from run( ). When the task returns from run( ), the Thread knows that the task has completed.
Although this program is simple enough that it should not have any problems, there are some small flaws regarding inter-task communication. This is an important topic that will be covered later in this chapter.
3-4-4-2. Simplifying with Executors▲
You can simplify your coding overhead by using ZThread Executors. Executors provide a layer of indirection between a client and the execution of a task; instead of a client executing a task directly, an intermediate object executes the task.
We can show this by using an Executor instead of explicitly creating Thread objects in MoreBasicThreads.cpp. A LiftOff object knows how to run a specific task; like the Command Pattern, it exposes a single function to be executed. An Executor object knows how build the appropriate context to execute Runnable objects. In the following example, the ThreadedExecutor creates one thread per task:
//: c11:ThreadedExecutor.cpp
//{L} ZThread
#include <iostream>
#include "zthread/ThreadedExecutor.h"
#include "LiftOff.h"
using namespace ZThread;
using namespace std;
int main() {
try {
ThreadedExecutor executor;
for(int i = 0; i < 5; i++)
executor.execute(new LiftOff(10, i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Note that in some cases a single Executor can be used to create and manage all the threads in your system. You must still place the threading code inside a try block because an Executor's execute( ) function may throw a Synchronization_Exception if something goes wrong. This is true for any function that involves changing the state of a synchronization object (starting threads, acquiring mutexes, waiting on conditions, etc.), as you will learn later in this chapter.
The program will exit as soon as all the tasks in the Executor complete.
In the previous example, the ThreadedExecutor creates a thread for each task that you want to run, but you can easily change the way these tasks are executed by replacing the ThreadedExecutor with a different type of Executor. In this chapter, using a ThreadedExecutor is fine, but in production code it might result in excessive costs from the creation of too many threads. In that case, you can replace it with a PoolExecutor, which will use a limited set of threads to execute the submitted tasks in parallel:
//: C11:PoolExecutor.cpp
//{L} ZThread
#include <iostream>
#include "zthread/PoolExecutor.h"
#include "LiftOff.h"
using namespace ZThread;
using namespace std;
int main() {
try {
// Constructor argument is minimum number of
threads:
PoolExecutor executor(5);
for(int i = 0; i < 5; i++)
executor.execute(new LiftOff(10, i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~With the PoolExecutor, you do expensive thread allocation once, up front, and the threads are reused when possible. This saves time because you aren't constantly paying for thread creation overhead for every single task. Also, in an event-driven system, events that require threads to handle them can be generated as quickly as you want by simply fetching them from the pool. You don't overrun the available resources because the PoolExecutor uses a bounded number of Thread objects. Thus, although this book will use ThreadedExecutors, consider using PoolExecutors in production code.
A ConcurrentExecutor is like a PoolExecutor with a fixed size of one thread. This is useful for anything you want to run in another thread continually (a long-lived task), such as a task that listens to incoming socket connections. It is also handy for short tasks that you want to run in a thread, for example, small tasks that update a local or remote log, or for an event-dispatching thread.
If more than one task is submitted to a ConcurrentExecutor, each task will run to completion before the next task is begun, all using the same thread. In the following example, you'll see each task completed, in the order that it was submitted, before the next one is begun. Thus, a ConcurrentExecutor serializes the tasks that are submitted to it.
//: C11:ConcurrentExecutor.cpp
//{L} ZThread
#include <iostream>
#include "zthread/ConcurrentExecutor.h"
#include "LiftOff.h"
using namespace ZThread;
using namespace std;
int main() {
try {
ConcurrentExecutor executor;
for(int i = 0; i < 5; i++)
executor.execute(new LiftOff(10, i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Like a ConcurrentExecutor, a SynchronousExecutor is used when you want only one task at a time to run, serially instead of concurrently. Unlike ConcurrentExecutor, a SynchronousExecutor doesn't create or manage threads on it own. It uses the thread that submits the task and thus only acts as a focal point for synchronization. If you have n threads submitting tasks to a SynchronousExecutor, no two tasks are ever run at once. Instead, each one is run to completion, then the next one in the queue is begun.
For example, suppose you have a number of threads running tasks that use the file system, but you are writing portable code so you don't want to use flock( ) or another OS-specific call to lock a file. You can run these tasks with a SynchronousExecutor to ensure that only one task at a time is running from any thread. This way, you don't need to deal with synchronizing on the shared resource (and you won't clobber the file system in the meantime). A better solution is to synchronize on the resource (which you'll learn about later in this chapter), but a SynchronousExecutor lets you skip the trouble of getting coordinated properly just to prototype something.
//: C11:SynchronousExecutor.cpp
//{L} ZThread
#include <iostream>
#include "zthread/SynchronousExecutor.h"
#include "LiftOff.h"
using namespace ZThread;
using namespace std;
int main() {
try {
SynchronousExecutor executor;
for(int i = 0; i < 5; i++)
executor.execute(new LiftOff(10, i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~When you run the program, you'll see that the tasks are executed in the order they are submitted, and each task runs to completion before the next one starts. What you don't see is that no new threads are created—the main( ) thread is used for each task, since in this example, that's the thread that submits all the tasks. Because SynchronousExecutor is primarily for prototyping, you may not use it much in production code.
3-4-4-3. Yielding▲
If you know that you've accomplished what you need to during one pass through a loop in your run( ) function (most run( ) functions involve a long-running loop), you can give a hint to the thread scheduling mechanism that you've done enough and that some other thread might as well have the CPU. This hint (and it is a hint—there's no guarantee your implementation will listen to it) takes the form of the yield( ) function.
We can make a modified version of the LiftOff examples by yielding after each loop:
//: C11:YieldingTask.cpp
// Suggesting when to switch threads with yield().
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
class YieldingTask : public Runnable {
int countDown;
int id;
public:
YieldingTask(int ident = 0) : countDown(5), id(ident)
{}
~YieldingTask() {
cout << id << " completed"
<< endl;
}
friend ostream&
operator<<(ostream& os, const
YieldingTask& yt) {
return os << "#" << yt.id
<< ": " << yt.countDown;
}
void run() {
while(true) {
cout << *this << endl;
if(--countDown == 0) return;
Thread::yield();
}
}
};
int main() {
try {
ThreadedExecutor executor;
for(int i = 0; i < 5; i++)
executor.execute(new YieldingTask(i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~You can see that the task's run( ) member function consists entirely of an infinite loop. By using yield( ), the output is evened up quite a bit over that without yielding. Try commenting out the call to Thread::yield( ) to see the difference. In general, however, yield( ) is useful only in rare situations, and you can't rely on it to do any serious tuning of your application.
3-4-4-4. Sleeping▲
Another way you can control the behavior of your threads is by calling sleep( ) to cease execution of a thread for a given number of milliseconds. In the preceding example, if you replace the call to yield( ) with a call to sleep( ), you get the following:
//: C11:SleepingTask.cpp
// Calling sleep() to pause for awhile.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
class SleepingTask : public Runnable {
int countDown;
int id;
public:
SleepingTask(int ident = 0) : countDown(5), id(ident)
{}
~SleepingTask() {
cout << id << " completed"
<< endl;
}
friend ostream&
operator<<(ostream& os, const
SleepingTask& st) {
return os << "#" << st.id
<< ": " << st.countDown;
}
void run() {
while(true) {
try {
cout << *this << endl;
if(--countDown == 0) return;
Thread::sleep(100);
} catch(Interrupted_Exception& e) {
cerr << e.what() << endl;
}
}
}
};
int main() {
try {
ThreadedExecutor executor;
for(int i = 0; i < 5; i++)
executor.execute(new SleepingTask(i));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Thread::sleep( ) can throw an Interrupted_Exception (you'll learn about interrupts later), and you can see that this is caught in run( ). But the task is created and executed inside a try block in main( ) that catches Synchronization_Exception (the base class for all ZThread exceptions), so wouldn't it be possible to just ignore the exception in run( ) and assume that it will propagate to the handler in main( )? This won't work because exceptions won't propagate across threads back to main( ). Thus, you must handle any exceptions locally that may arise within a task.
You'll notice that the threads tend to run in any order, which means that sleep( ) is also not a way for you to control the order of thread execution. It just stops the execution of the thread for awhile. The only guarantee that you have is that the thread will sleep at least 100 milliseconds (in this example), but it may take longer before the thread resumes execution because the thread scheduler still has to get back to it after the sleep interval expires.
If you must control the order of execution of threads, your best bet is to use synchronization controls (described later) or, in some cases, not to use threads at all, but instead to write your own cooperative routines that hand control to each other in a specified order.
3-4-4-5. Priority▲
The priority of a thread conveys the importance of a thread to the scheduler. Although the order that the CPU runs a set of threads is indeterminate, the scheduler will lean toward running the waiting thread with the highest priority first. However, this doesn't mean that threads with lower priority aren't run (that is, you can't get deadlocked because of priorities). Lower priority threads just tend to run less often.
Here's MoreBasicThreads.cpp modified so that the priority levels are demonstrated. The priorities are adjusting by using Thread's setPriority( ) function.
//: C11:SimplePriorities.cpp
// Shows the use of thread priorities.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
const double pi = 3.14159265358979323846;
const double e = 2.7182818284590452354;
class SimplePriorities : public Runnable {
int countDown;
volatile double d; // No optimization
int id;
public:
SimplePriorities(int ident=0): countDown(5),
id(ident) {}
~SimplePriorities() {
cout << id << " completed"
<< endl;
}
friend ostream&
operator<<(ostream& os, const
SimplePriorities& sp) {
return os << "#" << sp.id
<< " priority: "
<< Thread().getPriority()
<< " count: "<<
sp.countDown;
}
void run() {
while(true) {
// An expensive, interruptable operation:
for(int i = 1; i < 100000; i++)
d = d + (pi + e) / double(i);
cout << *this << endl;
if(--countDown == 0) return;
}
}
};
int main() {
try {
Thread high(new SimplePriorities);
high.setPriority(High);
for(int i = 0; i < 5; i++) {
Thread low(new SimplePriorities(i));
low.setPriority(Low);
}
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Here, operator<<( ) is overridden to display the identifier, priority, and countDown value of the task.
You can see that the priority level of thread high is at the highest level, and all the rest of the threads are at the lowest level. We are not using an Executor in this example because we need direct access to the threads in order to set their priorities.
Inside SimplePriorities::run( ), 100,000 repetitions of a rather expensive floating-point calculation are performed, involving double addition and division. The variable d is volatile to try to ensure that no compilers optimizations are performed. Without this calculation, you don't see the effect of setting the priority levels. (Try it: comment out the for loop containing the double calculations.) With the calculation, you see that thread high is given a higher preference by the thread scheduler. (At least, this was the behavior on a Windows machine.) The calculation takes long enough that the thread scheduling mechanism jumps in, changes threads, and pays attention to the priorities so that thread high gets preference.
You can also read the priority of an existing thread with getPriority( ) and change it at any time (not just before the thread is run, as in SimplePriorities.cpp) with setPriority( ).
Mapping priorities to operating systems is problematic. For example, Windows 2000 has seven priority levels, while Sun's Solaris has 231 levels. The only portable approach is to stick to very large priority granulations, such as the Low, Medium, and High used in the ZThread library.
3-4-5. Sharing limited resources▲
You can think of a single-threaded program as one lonely entity moving around through your problem space and doing one thing at a time. Because there's only one entity, you never have to think about the problem of two entities trying to use the same resource at the same time: problems such as two people trying to park in the same space, walk through a door at the same time, or even talk at the same time.
With multithreading things aren't lonely anymore, but you now have the possibility of two or more threads trying to use the same resource at once. This can cause two different kinds of problems. The first is that the necessary resources may not exist. In C++, the programmer has complete control over the lifetime of objects, and it's easy to create threads that try to use objects that get destroyed before those threads complete.
The second problem is that two or more threads may collide when they try to access the same resource at the same time. If you don't prevent such a collision, you'll have two threads trying to access the same bank account at the same time, print to the same printer, adjust the same valve, and so on.
This section introduces the problem of objects that vanish while tasks are still using them and the problem of tasks colliding over shared resources. You'll learn about the tools that are used to solve these problems.
3-4-5-1. Ensuring the existence of objects▲
Memory and resource management are major concerns in C++. When you create any C++ program, you have the option of creating objects on the stack or on the heap (using new). In a single-threaded program, it's usually easy to keep track of object lifetimes so that you don't try to use objects that are already destroyed.
The examples shown in this chapter create Runnable objects on the heap using new, but you'll notice that these objects are never explicitly deleted. However, you can see from the output when you run the programs that the thread library keeps track of each task and eventually deletes it, because the destructors for the tasks are called. This happens when the Runnable::run( ) member function completes—returning from run( ) indicates that the task is finished.
Burdening the thread with deleting a task is a problem. That thread doesn't necessarily know if another thread still needs to make a reference to that Runnable, and so the Runnable may be prematurely destroyed. To deal with this problem, tasks in ZThreads are automatically reference-counted by the ZThread library mechanism. A task is maintained until the reference count for that task goes to zero, at which point the task is deleted. This means that tasks must always be deleted dynamically, and so they cannot be created on the stack. Instead, tasks must always be created using new, as you see in all the examples in this chapter.
Often you must also ensure that non-task objects stay alive as long as tasks need them. Otherwise, it's easy for objects that are used by tasks to go out of scope before those tasks are completed. If this happens, the tasks will try to access illegal storage and will cause program faults. Here's a simple example:
//: C11:Incrementer.cpp {RunByHand}
// Destroying objects while threads are still
// running will cause serious problems.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
class Count {
enum { SZ = 100 };
int n[SZ];
public:
void increment() {
for(int i = 0; i < SZ; i++)
n[i]++;
}
};
class Incrementer : public Runnable {
Count* count;
public:
Incrementer(Count* c) : count(c) {}
void run() {
for(int n = 100; n > 0; n--) {
Thread::sleep(250);
count->increment();
}
}
};
int main() {
cout << "This will cause a segmentation
fault!" << endl;
Count count;
try {
Thread t0(new Incrementer(&count));
Thread t1(new Incrementer(&count));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The Count class may seem like overkill at first, but if n is only a single int (rather than an array), the compiler can put it into a register and that storage will still be available (albeit technically illegal) after the Count object goes out of scope. It's difficult to detect the memory violation in that case. Your results may vary depending on your compiler and operating system, but try making it n a single int and see what happens. In any event, if Count contains an array of ints as above, the compiler is forced to put it on the stack and not in a register.
Incrementer is a simple task that uses a Count object. In main( ), you can see that the Incrementer tasks are running for long enough that the Count object will go out of scope, and so the tasks try to access an object that no longer exists. This produces a program fault.
To fix the problem, we must guarantee that any objects shared between tasks will be around as long as those tasks need them. (If the objects were not shared, they could be composed directly into the task'sclass and thus tie their lifetime to that task.) Since we don't want the static program scope to control the lifetime of the object, we put the object on the heap. And to make sure that the object is not destroyed until there are no other objects (tasks, in this case) using it, we use reference counting.
Reference counting was explained thoroughly in volume one of this book and further revisited in this volume. The ZThread library includes a template called CountedPtr that automatically performs reference counting and deletes an object when the reference count goes to zero. Here's the above program modified to use CountedPtr to prevent the fault:
//: C11:ReferenceCounting.cpp
// A CountedPtr prevents too-early destruction.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/CountedPtr.h"
using namespace ZThread;
using namespace std;
class Count {
enum { SZ = 100 };
int n[SZ];
public:
void increment() {
for(int i = 0; i < SZ; i++)
n[i]++;
}
};
class Incrementer : public Runnable {
CountedPtr<Count> count;
public:
Incrementer(const CountedPtr<Count>& c ) : count(c)
{}
void run() {
for(int n = 100; n > 0; n--) {
Thread::sleep(250);
count->increment();
}
}
};
int main() {
CountedPtr<Count> count(new Count);
try {
Thread t0(new Incrementer(count));
Thread t1(new Incrementer(count));
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Incrementer now contains a CountedPtr object, which manages a Count. In main( ), the CountedPtr objects are passed into the two Incrementer objects by value, so the copy-constructor is called, increasing the reference count. As long as the tasks are still running, the reference count will be nonzero, and so the Count object managed by the CountedPtr will not be destroyed. Only when all the tasks using the Count are completed will delete be called (automatically) on the Count object by the CountedPtr.
Whenever you have objects that are used by more than one task, you'll almost always need to manage those objects using the CountedPtr template in order to prevent problems arising from object lifetime issues.
3-4-5-2. Improperly accessing resources▲
Consider the following example where one task generates even numbers and other tasks consume those numbers. Here, the only job of the consumer threads is to check the validity of the even numbers.
We'll first define EvenChecker,the consumer thread, since it will be reused in all the subsequent examples. To decouple EvenChecker from the various types of generators that we will experiment with, we'll create an interface called Generator, which contains the minimum necessary functions that EvenChecker must know about: that it has a nextValue( ) function and that it can be canceled.
//: C11:EvenChecker.h
#ifndef EVENCHECKER_H
#define EVENCHECKER_H
#include <iostream>
#include "zthread/CountedPtr.h"
#include "zthread/Thread.h"
#include "zthread/Cancelable.h"
#include "zthread/ThreadedExecutor.h"
class Generator : public ZThread::Cancelable {
bool canceled;
public:
Generator() : canceled(false) {}
virtual int nextValue() = 0;
void cancel() { canceled = true; }
bool isCanceled() { return canceled; }
};
class EvenChecker : public ZThread::Runnable {
ZThread::CountedPtr<Generator> generator;
int id;
public:
EvenChecker(ZThread::CountedPtr<Generator>&
g, int ident)
: generator(g), id(ident) {}
~EvenChecker() {
std::cout << "~EvenChecker "
<< id << std::endl;
}
void run() {
while(!generator->isCanceled()) {
int val = generator->nextValue();
if(val % 2 != 0) {
std::cout << val << " not
even!" << std::endl;
generator->cancel(); // Cancels all
EvenCheckers
}
}
}
// Test any type of generator:
template<typename GenType> static void test(int
n = 10) {
std::cout << "Press Control-C to
exit" << std::endl;
try {
ZThread::ThreadedExecutor executor;
ZThread::CountedPtr<Generator> gp(new
GenType);
for(int i = 0; i < n; i++)
executor.execute(new
EvenChecker(gp, i));
} catch(ZThread::Synchronization_Exception& e)
{
std::cerr << e.what() << std::endl;
}
}
};
#endif // EVENCHECKER_H ///:~The Generator class introduces the abstract Cancelable class, which is part of the ZThread library. The goal of Cancelable is to provide a consistent interface to change the state of an object via the cancel( ) function and to see whether the object has been canceled with the isCanceled( ) function. Here, we use the simple approach of a bool canceled flag, similar to the quitFlag previously seen in ResponsiveUI.cpp. Note that in this example the class that is Cancelable is not Runnable. Instead, all the EvenChecker tasks that depend on the Cancelable object (the Generator) test it to see if it's been canceled, as you can see in run( ). This way, the tasks that share the common resource (the Cancelable Generator) watch that resource for the signal to terminate. This eliminates the so-called race condition, where two or more tasks race to respond to a condition and thus collide or otherwise produce inconsistent results. You must be careful to think about and protect against all the possible ways a concurrent system can fail. For example, a task cannot depend on another task because task shutdown order is not guaranteed. Here, by making tasks depend on non-task objects (which are reference counted using CountedPtr) we eliminate the potential race condition.
In later sections, you'll see that the ZThread library contains more general mechanisms for termination of threads.
Since multiple EvenChecker objects may end up sharing a Generator, the CountedPtr template is used to reference count the Generator objects.
The last member function in EvenChecker is a static member template that sets up and performs a test of any type of Generator by creating one inside a CountedPtr and then starting a number of EvenCheckers that use that Generator. If the Generator causes a failure, test( ) will report it and return; otherwise, you must press Control-C to terminate it.
EvenChecker tasks constantly read and test the values from their associated Generator. Note that if generator->isCanceled( ) is true, run( ) returns, which tells the Executor in EvenChecker::test( ) that the task is complete. Any EvenChecker task can call cancel( ) on its associated Generator, which will cause all other EvenCheckers using that Generator to gracefully shut down.
The EvenGenerator is simple—nextValue( ) produces the next even value:
//: C11:EvenGenerator.cpp
// When threads collide.
//{L} ZThread
#include <iostream>
#include "EvenChecker.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
class EvenGenerator : public Generator {
unsigned int currentEvenValue; // Unsigned can't
overflow
public:
EvenGenerator() { currentEvenValue = 0; }
~EvenGenerator() { cout <<
"~EvenGenerator" << endl; }
int nextValue() {
++currentEvenValue; // Danger point here!
++currentEvenValue;
return currentEvenValue;
}
};
int main() {
EvenChecker::test<EvenGenerator>();
} ///:~It's possible for one thread to call nextValue( ) after the first increment of currentEvenValue and before the second (at the place in the code commented “Danger point here!”), which puts the value into an “incorrect” state. To prove that this can happen, EvenChecker::test( ) creates a group of EvenChecker objects to continually read the output of an EvenGenerator and test to see if each one is even. If not, the error is reported and the program is shut down.
This program may not detect the problem until the EvenGenerator has completed many cycles, depending on the particulars of your operating system and other implementation details. If you want to see it fail much faster, try putting a call to yield( ) between the first and second increments. In any event, it will eventually fail because the EvenChecker threads are able to access the information in EvenGenerator while it's in an “incorrect” state.
3-4-5-3. Controlling access▲
The previous example shows a fundamental problem when using threads: You never know when a thread might be run. Imagine sitting at a table with a fork, about to spear the last piece of food on a platter, and as your fork reaches for it, the food suddenly vanishes (because your thread was suspended and another diner came in and ate the food). That's the problem you're dealing with when writing concurrent programs.
Occasionally you don't care if a resource is being accessed at the same time you're trying to use it. But in most cases you do care, and for multithreading to work, you need some way to prevent two threads from accessing the same resource, at least during critical periods.
Preventing this kind of collision is simply a matter of putting a lock on a resource when one thread is using it. The first thread that accesses a resource locks it, and then the other threads cannot access that resource until it is unlocked, at which time another thread locks and uses it, and so on. If the front seat of the car is the limited resource, the child who shouts “Dibs!” acquires the lock.
Thus, we need to be able to prevent any other tasks from accessing the storage when that storage is not in a proper state. That is, we need to have a mechanism that excludes a second task from accessing the storage when a first task is already using it. This idea is fundamental to all multithreading systems and is called mutual exclusion; the mechanism used abbreviates this to mutex. The ZThread library contains a mutex mechanism declared in the header Mutex.h.
To solve the problem in the above program, we identify the critical sections where mutual exclusion must apply; then we acquire the mutex before entering the critical section and release it at the end of the critical section. Only one thread can acquire the mutex at any time, so mutual exclusion is achieved:
//: C11:MutexEvenGenerator.cpp {RunByHand}
// Preventing thread collisions with mutexes.
//{L} ZThread
#include <iostream>
#include "EvenChecker.h"
#include "zthread/ThreadedExecutor.h"
#include "zthread/Mutex.h"
using namespace ZThread;
using namespace std;
class MutexEvenGenerator : public Generator {
unsigned int currentEvenValue;
Mutex lock;
public:
MutexEvenGenerator() { currentEvenValue = 0; }
~MutexEvenGenerator() {
cout << "~MutexEvenGenerator"
<< endl;
}
int nextValue() {
lock.acquire();
++currentEvenValue;
Thread::yield(); // Cause failure faster
++currentEvenValue;
int rval = currentEvenValue;
lock.release();
return rval;
}
};
int main() {
EvenChecker::test<MutexEvenGenerator>();
} ///:~MutexEvenGenerator adds a Mutex called lock and uses acquire( ) and release( ) to create a critical section within nextValue( ). In addition, a call to Thread::yield( ) is inserted between the two increments, to raise the likelihood of a context switch while currentEvenValue is in an odd state. Because the mutex prevents more than one thread at a time in the critical section, this will not produce a failure, but calling yield( ) is a helpful way to promote a failure if it's going to happen.
Note that nextValue( ) must capture the return value inside the critical section because if you return from inside the critical section, you won't release the lock and will thus prevent it from being acquired again. (This usually leads to deadlock, which you'll learn about at the end of this chapter.)
The first thread that enters nextValue( ) acquires the lock, and any further threads that try to acquire the lock are blocked from doing so until the first thread releases the lock. At that point, the scheduling mechanism selects another thread that is waiting on the lock. This way, only one thread at a time can pass through the code that is guarded by the mutex.
3-4-5-4. Simplified coding with Guards▲
The use of mutexes rapidly becomes complicated when exceptions are introduced. To make sure that the mutex is always released, you must ensure that each possible exception path includes a call to release( ). In addition, any function that has multiple return paths must carefully ensure that it calls release( ) at the appropriate points.
These problems can be easily solved by using the fact that a stack-based (auto) object has a destructor that is always called regardless of how you exit from a function scope. In the ZThread library, this is implemented as the Guard template. The Guard template creates objects that acquire( ) a Lockable object when constructed and release( ) that lock when destroyed. Guard objects created on the local stack will automatically be destroyed regardless of how the function exits and will always unlock the Lockable object. Here's the above example reimplemented using Guards:
//: C11:GuardedEvenGenerator.cpp {RunByHand}
// Simplifying mutexes with the Guard template.
//{L} ZThread
#include <iostream>
#include "EvenChecker.h"
#include "zthread/ThreadedExecutor.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
using namespace ZThread;
using namespace std;
class GuardedEvenGenerator : public Generator {
unsigned int currentEvenValue;
Mutex lock;
public:
GuardedEvenGenerator() { currentEvenValue = 0; }
~GuardedEvenGenerator() {
cout << "~GuardedEvenGenerator"
<< endl;
}
int nextValue() {
Guard<Mutex> g(lock);
++currentEvenValue;
Thread::yield();
++currentEvenValue;
return currentEvenValue;
}
};
int main() {
EvenChecker::test<GuardedEvenGenerator>();
} ///:~Note that the temporary return value is no longer necessary in nextValue( ). In general, there is less code to write, and the opportunity for user error is greatly reduced.
An interesting feature of the Guard template is that it can be used to manipulate other guards safely. For example, a second Guard can be used to temporarily unlock a guard:
//: C11:TemporaryUnlocking.cpp
// Temporarily unlocking another guard.
//{L} ZThread
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
using namespace ZThread;
class TemporaryUnlocking {
Mutex lock;
public:
void f() {
Guard<Mutex> g(lock);
// lock is acquired
// ...
{
Guard<Mutex, UnlockedScope> h(g);
// lock is released
// ...
// lock is acquired
}
// ...
// lock is released
}
};
int main() {
TemporaryUnlocking t;
t.f();
} ///:~A Guard can also be used to try to acquire a lock for a certain amount of time and then give up:
//: C11:TimedLocking.cpp
// Limited time locking.
//{L} ZThread
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
using namespace ZThread;
class TimedLocking {
Mutex lock;
public:
void f() {
Guard<Mutex, TimedLockedScope<500> >
g(lock);
// ...
}
};
int main() {
TimedLocking t;
t.f();
} ///:~In this example, a Timeout_Exception will be thrown if the lock cannot be acquired within 500 milliseconds.
Synchronizing entire classes
The ZThread library also provides a GuardedClass template to automatically create a synchronized wrapper for an entire class. This means that every member function in the class will automatically be guarded:
//: C11:SynchronizedClass.cpp {-dmc}
//{L} ZThread
#include "zthread/GuardedClass.h"
using namespace ZThread;
class MyClass {
public:
void func1() {}
void func2() {}
};
int main() {
MyClass a;
a.func1(); // Not synchronized
a.func2(); // Not synchronized
GuardedClass<MyClass> b(new MyClass);
// Synchronized calls, only one thread at a time
allowed:
b->func1();
b->func2();
} ///:~Object a is a not synchronized, so func1( ) and func2( ) can be called at any time by any number of threads. Object b is protected by the GuardedClass wrapper, so each member function is automatically synchronized and only one function per object can be called any time.
The wrapper locks at a class level of granularity, which may affect performance.(151) If a class contains some unrelated functions, it may be better to synchronize those functions internally with two different locks. However, if you find yourself doing this, it means that one class contains groups of data that may not be strongly associated. Consider breaking the class into two classes.
Guarding all member functions of a class with a mutex does not automatically make that class thread-safe. You must carefully consider all threading issues in order to guarantee thread safety.
3-4-5-5. Thread local storage▲
A second way to eliminate the problem of tasks colliding over shared resources is to eliminate the sharing of variables, which can be done by creating different storage for the same variable, for each different thread that uses an object. Thus, if you have five threads using an object with a variable x, thread local storage automatically generates five different pieces of storage for x. Fortunately, the creation and management of thread local storage is taken care of automatically by ZThread's ThreadLocal template, as seen here:
//: C11:ThreadLocalVariables.cpp {RunByHand}
// Automatically giving each thread its own storage.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
#include "zthread/ThreadedExecutor.h"
#include "zthread/Cancelable.h"
#include "zthread/ThreadLocal.h"
#include "zthread/CountedPtr.h"
using namespace ZThread;
using namespace std;
class ThreadLocalVariables : public Cancelable {
ThreadLocal<int> value;
bool canceled;
Mutex lock;
public:
ThreadLocalVariables() : canceled(false) {
value.set(0);
}
void increment() { value.set(value.get() + 1); }
int get() { return value.get(); }
void cancel() {
Guard<Mutex> g(lock);
canceled = true;
}
bool isCanceled() {
Guard<Mutex> g(lock);
return canceled;
}
};
class Accessor : public Runnable {
int id;
CountedPtr<ThreadLocalVariables> tlv;
public:
Accessor(CountedPtr<ThreadLocalVariables>&
tl, int idn)
: id(idn), tlv(tl) {}
void run() {
while(!tlv->isCanceled()) {
tlv->increment();
cout << *this << endl;
}
}
friend ostream&
operator<<(ostream& os, Accessor& a)
{
return os << "#" << a.id
<< ": " << a.tlv->get();
}
};
int main() {
cout << "Press <Enter> to quit"
<< endl;
try {
CountedPtr<ThreadLocalVariables>
tlv(new ThreadLocalVariables);
const int SZ = 5;
ThreadedExecutor executor;
for(int i = 0; i < SZ; i++)
executor.execute(new
Accessor(tlv, i));
cin.get();
tlv->cancel(); // All Accessors will quit
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~When you create a ThreadLocal object by instantiating the template, you are only able to access the contents of the object using the get( ) and set( ) member functions. The get( ) function returns a copy of the object that is associated with that thread, and set( ) inserts its argument into the object stored for that thread, returning the old object that was in storage. You can see this is use in increment( ) and get( ) in ThreadLocalVariables.
Since tlv is shared by multiple Accessor objects, it is written as Cancelable so that the Accessors can be signaled when we want to shut the system down.
When you run this program, you'll see evidence that the individual threads are each allocated their own storage.
3-4-6. Terminating tasks▲
In previous examples, we have seen the use of a “quit flag” or the Cancelable interface in order to terminate a task. This is a reasonable approach to the problem. However, in some situations the task must be terminated more abruptly. In this section, you'll learn about the issues and problems of such termination.
First, let's look at an example that not only demonstrates the termination problem but is also an additional example of resource sharing. To present this example, we'll first need to solve the problem of iostream collision
3-4-6-1. Preventing iostream collision▲
You may have noticed in previous examples that the output is sometimes garbled. C++ iostreams were not created with threading in mind, so there's nothing to keep one thread's output from interfering with another thread's output. Thus, you must write your applications so that they synchronize the use of iostreams.
To solve the problem, we need to create the entire output packet first and then explicitly decide when to try to send it to the console. One simple solution is to write the information to an ostringstream and then use a single object with a mutex as the point of output among all threads, to prevent more than one thread from writing at the same time:
//: C11:Display.h
// Prevents ostream collisions.
#ifndef DISPLAY_H
#define DISPLAY_H
#include <iostream>
#include <sstream>
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
class Display { // Share one of these among all threads
ZThread::Mutex iolock;
public:
void output(std::ostringstream& os) {
ZThread::Guard<ZThread::Mutex> g(iolock);
std::cout << os.str();
}
};
#endif // DISPLAY_H ///:~This way, the standard operator<<( ) functions are predefined for us and the object can be built in memory using familiar ostream operators. When a task wants to display output, it creates a temporary ostringstream object that it uses to build up the desired output message. When it calls output( ), the mutex prevents multiple threads from writing to this Display object. (You must use only one Display object in your program, as you'll see in the following examples.)
This just shows the basic idea, but if necessary, you can build a more elaborate framework. For example, you could enforce the requirement that there be only one Display object in a program by making it a Singleton. (The ZThread library has a Singleton template to support Singletons.)
3-4-6-2. The ornamental garden▲
In this simulation, the garden committee would like to know how many people enter the garden each day through its multiple gates. Each gate has a turnstile or some other kind of counter, and after the turnstile count is incremented, a shared count is incremented that represents the total number of people in the garden.
//: C11:OrnamentalGarden.cpp {RunByHand}
//{L} ZThread
#include <vector>
#include <cstdlib>
#include <ctime>
#include "Display.h"
#include "zthread/Thread.h"
#include "zthread/FastMutex.h"
#include "zthread/Guard.h"
#include "zthread/ThreadedExecutor.h"
#include "zthread/CountedPtr.h"
using namespace ZThread;
using namespace std;
class Count : public Cancelable {
FastMutex lock;
int count;
bool paused, canceled;
public:
Count() : count(0), paused(false), canceled(false) {}
int increment() {
// Comment the following line to see counting fail:
Guard<FastMutex> g(lock);
int temp = count ;
if(rand() % 2 == 0) // Yield half the time
Thread::yield();
return (count = ++temp);
}
int value() {
Guard<FastMutex> g(lock);
return count;
}
void cancel() {
Guard<FastMutex> g(lock);
canceled = true;
}
bool isCanceled() {
Guard<FastMutex> g(lock);
return canceled;
}
void pause() {
Guard<FastMutex> g(lock);
paused = true;
}
bool isPaused() {
Guard<FastMutex> g(lock);
return paused;
}
};
class Entrance : public Runnable {
CountedPtr<Count> count;
CountedPtr<Display> display;
int number;
int id;
bool waitingForCancel;
public:
Entrance(CountedPtr<Count>& cnt,
CountedPtr<Display>& disp, int idn)
: count(cnt), display(disp), number(0), id(idn),
waitingForCancel(false) {}
void run() {
while(!count->isPaused()) {
++number;
{
ostringstream os;
os << *this << " Total: "
<< count->increment() <<
endl;
display->output(os);
}
Thread::sleep(100);
}
waitingForCancel = true;
while(!count->isCanceled()) // Hold here...
Thread::sleep(100);
ostringstream os;
os << "Terminating " << *this
<< endl;
display->output(os);
}
int getValue() {
while(count->isPaused() &&
!waitingForCancel)
Thread::sleep(100);
return number;
}
friend ostream&
operator<<(ostream& os, const Entrance&
e) {
return os << "Entrance " <<
e.id << ": " << e.number;
}
};
int main() {
srand(time(0)); // Seed the random number generator
cout << "Press <ENTER> to quit"
<< endl;
CountedPtr<Count> count(new Count);
vector<Entrance*> v;
CountedPtr<Display> display(new Display);
const int SZ = 5;
try {
ThreadedExecutor executor;
for(int i = 0; i < SZ; i++) {
Entrance* task = new
Entrance(count, display, i);
executor.execute(task);
// Save the pointer to the task:
v.push_back(task);
}
cin.get(); // Wait for user to press <Enter>
count->pause(); // Causes tasks to stop counting
int sum = 0;
vector<Entrance*>::iterator it = v.begin();
while(it != v.end()) {
sum += (*it)->getValue();
++it;
}
ostringstream os;
os << "Total: " <<
count->value() << endl
<< "Sum of Entrances: " <<
sum << endl;
display->output(os);
count->cancel(); // Causes threads to quit
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Count is the class that keeps the master count of garden visitors. The single Count object defined in main( ) as count is held as a CountedPtr in Entrance and thus is shared by all Entrance objects. A FastMutex called lock is used in this example instead of an ordinary Mutex because a FastMutex uses the native operating system mutex and will thus yield more interesting results.
A Guard is used with lock in increment( ) to synchronize access to count. This function uses rand( ) to cause a yield( ) roughly half the time, in between fetching count into temp and incrementing and storing temp back into count. Because of this, if you comment out the Guard object definition, you will rapidly see the program break because multiple threads will be accessing and modifying count simultaneously.
The Entrance class also keeps a local number with the number of visitors that have passed through this particular entrance. This provides a double-check against the count object to make sure that the proper number of visitors is being recorded. Entrance::run( ) simply increments number and the count object and sleeps for 100 milliseconds.
In main, a vector<Entrance*> is loaded with each Entrance that is created. After the user presses <Enter>, this vector is used to iterate over all the individual Entrance values and total them.
This program goes to quite a bit of extra trouble to shut everything down in a stable fashion. Part of the reason for this is to show just how careful you must be when terminating a multithreaded program, and part of the reason is to demonstrate the value of interrupt( ), which you will learn about shortly.
All the communication between the Entrance objects takes place through the single Count object. When the user presses <Enter>, main( ) sends the pause( ) message to count. Since each Entrance::run( ) is watching the count object to see whether it is paused, this causes each Entrance to move into the waitingForCancel state, where it is no longer counting, but it is still alive. This is essential because main( ) must still be able to safely iterate over the objects in the vector<Entrance*>. Note that because there is a slight possibility that the iteration might occur before an Entrance has finished counting and moved into the waitingForCancel state, the getValue( ) function cycles through calls to sleep( ) until the object moves into waitingForCancel. (This is one form of what is called a busy wait, which is undesirable. You'll see the preferred approach of using wait( ) later in the chapter.) Once main( ) completes its iteration through the vector<Entrance*>, the cancel( ) message is sent to the count object, and once again all the Entrance objects are watching for this state change. At this point, they print a termination message and exit from run( ), which causes each task to be destroyed by the threading mechanism.
As this program runs, you will see the total count and the count at each entrance displayed as people walk through a turnstile. If you comment out the Guard object in Count::increment( ),you'll notice that the total number of people is not what you expect it to be. The number of people counted by each turnstile will be different from the value in count. As long as the Mutex is there to synchronize access to the Counter, things work correctly. Keep in mind that Count::increment( ) exaggerates the potential for failure by using temp and yield( ). In real threading problems, the possibility for failure may be statistically small, so you can easily fall into the trap of believing that things are working correctly. Just as in the example above, there are likely to be hidden problems that haven't occurred to you, so be exceptionally diligent when reviewing concurrent code.
Atomic operations
Note that Count::value( ) returns the value of count using a Guard object for synchronization. This brings up an interesting point because this code will probably work fine with most compilers and systems without synchronization. The reason is that, in general, a simple operation such as returning an int will be an atomic operation, which means that it will probably happen in a single microprocessor instruction that will not get interrupted. (The multithreading mechanism is unable to stop a thread in the middle of a microprocessor instruction.) That is, atomic operations are not interruptible by the threading mechanism and thus do not need to be guarded.(152) In fact, if we removed the fetch of count into temp and removed the yield( ), and instead simply incremented count directly, we probably wouldn't need a lock because the increment operation is usually atomic, as well.(153)
The problem is that the C++ Standard doesn't guarantee atomicity for any of these operations. Although operations such as returning an int and incrementing an int are almost certainly atomic on most machines, there's no guarantee. And because there's no guarantee, you have to assume the worst. Sometimes you might investigate the atomicity behavior on a particular machine (usually by looking at assembly language) and write code based on those assumptions. That's always dangerous and ill-advised. It's too easy for that information to be lost or hidden, and the next person that comes along may assume that this code can be ported to another machine and then go mad tracking down the occasional glitch caused by thread collisions.
So, while removing the guard on Count::value( ) seems to work, it's not airtight, and thus on some machines you may see aberrant behavior.
3-4-6-3. Terminating when blocked▲
Entrance::run( ) in the previous example includes a call to sleep( ) in the main loop. We know that sleep( ) will eventually wake up and the task will reach the top of the loop where it has an opportunity to break out of that loop by checking the isPaused( ) status. However, sleep( ) is just one situation where a thread is blocked from executing, and sometimes you must terminate a task that's blocked.
Thread states
A thread can be in any one of four states:
- New: A thread remains in this state only momentarily, as it is being created. It allocates any necessary system resources and performs initialization. At this point it becomes eligible to receive CPU time. The scheduler will then transition this thread to the runnable or blocked state.
- Runnable: This means that a thread can be run when the time-slicing mechanism has CPU cycles available for the thread. Thus, the thread might or might not be running at any moment, but there's nothing to prevent it from being run if the scheduler can arrange it; it's not dead or blocked.
- Blocked: The thread could be run, but something prevents it. (It might be waiting for I/O to complete, for example.) While a thread is in the blocked state, the scheduler will simply skip it and not give it any CPU time. Until a thread reenters the runnable state, it won't perform any operations.
- Dead: A thread in the dead state is no longer schedulable and will not receive any CPU time. Its task is completed, and it is no longer runnable. The normal way for a thread to die is by returning from its run( ) function.
Becoming blocked
A thread is blocked when it cannot continue running. A thread can become blocked for the following reasons:
- You've put the thread to sleep by calling sleep(milliseconds), in which case it will not be run for the specified time.
- You've suspended the execution of the thread with wait( ). It will not become runnable again until the thread gets the signal( ) or broadcast( ) message. We'll examine these in a later section.
- The thread is waiting for some I/O to complete.
- The thread is trying to enter a block of code that is guarded by a mutex, and that mutex has already been acquired by another thread.
The problem we need to look at now is this: sometimes you want to terminate a thread that is in a blocked state. If you can't wait for it to get to a point in the code where it can check a state value and decide to terminate on its own, you have to force the thread out of its blocked state.
3-4-6-4. Interruption▲
As you might imagine, it's much messier to break out of the middle of a Runnable::run( ) function than it is to wait for that function to get to a test of isCanceled( ) (or some other place where the programmer is ready to leave the function). When you break out of a blocked task, you might need to destroy objects and clean up resources. Because of this, breaking out of the middle of a task's run( ) is more like throwing an exception than anything else, so in ZThreads, exceptions are used for this kind of abort. (This walks the fine edge of being an inappropriate use of exceptions, because it means you are often using them for control flow.)(154) To return to a known good state when terminating a task this way, carefully consider the execution paths of your code and properly clean up everything inside the catch clause. We'll look at these issues in this section.
To terminate a blocked thread, the ZThread library provides the Thread::interrupt( ) function. This sets the interrupted status for that thread. A thread with its interrupted status set will throw an Interrupted_Exception if it is already blocked or it attempts a blocking operation. The interrupted status will be reset when the exception is thrown or if the task calls Thread::interrupted( ). As you'll see, Thread::interrupted( ) provides a second way to leave your run( ) loop, without throwing an exception.
Here's an example that shows the basics of interrupt( ):
//: C11:Interrupting.cpp
// Interrupting a blocked thread.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
class Blocked : public Runnable {
public:
void run() {
try {
Thread::sleep(1000);
cout << "Waiting for get() in
run():";
cin.get();
} catch(Interrupted_Exception&) {
cout << "Caught
Interrupted_Exception" << endl;
// Exit the task
}
}
};
int main(int argc, char* argv[]) {
try {
Thread t(new Blocked);
if(argc > 1)
Thread::sleep(1100);
t.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~You can see that, in addition to the insertion into cout, run( ) contains two other points where blocking can occur: the call to Thread::sleep(1000) and the call to cin.get( ). By giving the program any command-line argument, you tell main( ) to sleep long enough that the task will finish its sleep( ) and call cin.get( ).(155) If you don't give the program an argument, the sleep( ) in main( ) is skipped. Here, the call to interrupt( ) will occur while the task is sleeping, and you'll see that this will cause Interrupted_Exception to be thrown. If you give the program a command-line argument, you'll discover that a task cannot be interrupted if it is blocked on IO. That is, you can interrupt out of any blocking operation except IO.(156)
This is a little disconcerting if you're creating a thread that performs IO because it means that I/O has the potential of locking your multithreaded program. The problem is that, again, C++ was not designed with threading in mind; quite the opposite, it effectively pretends that threading doesn't exist. Thus, the iostream library is not thread-friendly. If the new C++ Standard decides to add thread support, the iostream library may need to be reconsidered in the process.
Blocked by a mutex
If you try to call a function whose mutex has already been acquired, the calling task will be suspended until the mutex becomes available. The following example tests whether this kind of blocking is interruptible:
//: C11:Interrupting2.cpp
// Interrupting a thread blocked
// with a synchronization guard.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
using namespace ZThread;
using namespace std;
class BlockedMutex {
Mutex lock;
public:
BlockedMutex() {
lock.acquire();
}
void f() {
Guard<Mutex> g(lock);
// This will never be available
}
};
class Blocked2 : public Runnable {
BlockedMutex blocked;
public:
void run() {
try {
cout << "Waiting for f() in
BlockedMutex" << endl;
blocked.f();
} catch(Interrupted_Exception& e) {
cerr << e.what() << endl;
// Exit the task
}
}
};
int main(int argc, char* argv[]) {
try {
Thread t(new Blocked2);
t.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The class BlockedMutex has a constructor that acquires the object's own Mutex and never releases it. For that reason, if you try to call f( ), you will always be blocked because the Mutex cannot be acquired. In Blocked2, the run( ) function will be stopped at the call to blocked.f( ). When you run the program you'll see that, unlike the iostream call, interrupt( ) can break out of a call that's blocked by a mutex.(157)
Checking for an interrupt
Note that when you call interrupt( ) on a thread, the only time that the interrupt occurs is when the task enters, or is already inside, a blocking operation (except, as you've seen, in the case of IO, where you're just stuck). But what if you've written code that may or may not make such a blocking call, depending on the conditions in which it is run? If you can only exit by throwing an exception on a blocking call, you won't always be able to leave the run( ) loop. Thus, if you call interrupt( ) to stop a task, your task needs a second opportunity to exit in the event that your run( ) loop doesn't happen to be making any blocking calls.
This opportunity is presented by the interrupted status, which is set by the call to interrupt( ). You check for the interrupted status by calling interrupted( ). This not only tells you whether interrupt( ) has been called, it also clears the interrupted status. Clearing the interrupted status ensures that the framework will not notify you twice about a task being interrupted. You will be notified via either a single Interrupted_Exception, or a single successful Thread::interrupted( ) test. If you want to check again to see whether you were interrupted, you can store the result when you call Thread::interrupted( ).
The following example shows the typical idiom that you should use in your run( ) function to handle both blocked and non-blocked possibilities when the interrupted status is set:
//: C11:Interrupting3.cpp {RunByHand}
// General idiom for interrupting a task.
//{L} ZThread
#include <iostream>
#include "zthread/Thread.h"
using namespace ZThread;
using namespace std;
const double PI = 3.14159265358979323846;
const double E = 2.7182818284590452354;
class NeedsCleanup {
int id;
public:
NeedsCleanup(int ident) : id(ident) {
cout << "NeedsCleanup " << id
<< endl;
}
~NeedsCleanup() {
cout << "~NeedsCleanup " <<
id << endl;
}
};
class Blocked3 : public Runnable {
volatile double d;
public:
Blocked3() : d(0.0) {}
void run() {
try {
while(!Thread::interrupted()) {
point1:
NeedsCleanup n1(1);
cout << "Sleeping" <<
endl;
Thread::sleep(1000);
point2:
NeedsCleanup n2(2);
cout << "Calculating" <<
endl;
// A time-consuming, non-blocking operation:
for(int i = 1; i < 100000; i++)
d = d + (PI + E) / (double)i;
}
cout << "Exiting via while() test"
<< endl;
} catch(Interrupted_Exception&) {
cout << "Exiting via
Interrupted_Exception" << endl;
}
}
};
int main(int argc, char* argv[]) {
if(argc != 2) {
cerr << "usage: " << argv[0]
<< " delay-in-milliseconds"
<< endl;
exit(1);
}
int delay = atoi(argv[1]);
try {
Thread t(new Blocked3);
Thread::sleep(delay);
t.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The NeedsCleanup class emphasizes the necessity of proper resource cleanup if you leave the loop via an exception. Note that no pointers are defined in Blocked3::run( ) because, for exception safety, all resources must be enclosed in stack-based objects so that the exception handler can automatically clean them up by calling the destructor.
You must give the program a command-line argument which is the delay time in milliseconds before it calls interrupt( ). By using different delays, you can exit Blocked3::run( ) at different points in the loop: in the blocking sleep( ) call, and in the non-blocking mathematical calculation. You'll see that if interrupt( ) is called after the label point2 (during the non-blocking operation), first the loop is completed, then all the local objects are destructed, and finally the loop is exited at the top via the while statement. However, if interrupt( ) is called between point1 and point2 (after the while statement but before or during the blocking operation sleep( )), the task exits via the Interrupted_Exception. In that case, only the stack objects that have been created up to the point where the exception is thrown are cleaned up, and you have the opportunity to perform any other cleanup in the catch clause.
A class designed to respond to an interrupt( ) must establish a policy that ensures it will remain in a consistent state. This generally means that all resource acquisition should be wrapped inside stack-based objects so that the destructors will be called regardless of how the run( ) loop exits. Correctly done, code like this can be elegant. Components can be created that completely encapsulate their synchronization mechanisms but are still responsive to an external stimulus (via interrupt( )) without adding any special functions to an object's interface.
3-4-7. Cooperation between threads▲
As you've seen, when you use threads to run more than one task at a time, you can keep one task from interfering with another task's resources by using a mutex to synchronize the behavior of the two tasks. That is, if two tasks are stepping on each other over a shared resource (usually memory), you use a mutex to allow only one task at a time to access that resource.
With that problem solved, you can move on to the issue of getting threads to cooperate, so that multiple threads can work together to solve a problem. Now the issue is not about interfering with one another, but rather about working in unison, since portions of such problems must be solved before other portions can be solved. It's much like project planning: the footings for the house must be dug first, but the steel can be laid and the concrete forms can be built in parallel, and both of those tasks must be finished before the concrete foundation can be poured. The plumbing must be in place before the concrete slab can be poured, the concrete slab must be in place before you start framing, and so on. Some of these tasks can be done in parallel, but certain steps require all tasks to be completed before you can move ahead.
The key issue when tasks are cooperating is handshaking between those tasks. To accomplish this handshaking, we use the same foundation: the mutex, which in this case guarantees that only one task can respond to a signal. This eliminates any possible race conditions. On top of the mutex, we add a way for a task to suspend itself until some external state changes (“the plumbing is now in place”), indicating that it's time for that task to move forward. In this section, we'll look at the issues of handshaking between tasks, the problems that can arise, and their solutions.
3-4-7-1. Wait and signal▲
In ZThreads, the basic class that uses a mutex and allows task suspension is the Condition, and you can suspend a task by calling wait( ) on a Condition. When external state changes take place that might mean that a task should continue processing, you notify the task by calling signal( ), to wake up one task, or broadcast( ), to wake up all tasks that have suspended themselves on that Condition object.
There are two forms of wait( ). The first form takes an argument in milliseconds that has the same meaning as in sleep( ): “pause for this period of time.” The second form takes no arguments; this version is more commonly used. Both forms of wait( ) release the Mutex that is controlled by the Condition object and suspends the thread until that Condition object receives a signal( ) or broadcast( ). The first form may also terminate if it times out before a signal( ) or broadcast( ) is received.
Because wait( ) releases the Mutex, it means that the Mutex can be acquired by another thread. Thus, when you call wait( ) you're saying “I've done all I can right now so I'm going to wait right here, but I want to allow other synchronized operations to take place if they can.”
Typically, you use wait( ) when you're waiting for some condition to change that is under the control of forces outside the current function. (Often, this condition will be changed by another thread.) You don't want to idly loop while testing the condition inside your thread; this is called a “busy wait,” and it's usually a bad use of CPU cycles. Thus, wait( ) suspends the thread while waiting for the world to change, and only when a signal( ) or broadcast( ) occurs (suggesting that something of interest may have happened), does the thread wake up and check for changes. So wait( ) provides a way to synchronize activities between threads.
Let's look at a simple example. WaxOMatic.cpp has two processes: one to apply wax to a Car and one to polish it. The polishing process cannot do its job until the application process is finished, and the application process must wait until the polishing process is finished before it can put on another coat of wax. Both WaxOn and WaxOff use the Car object, which contains a Condition that it uses to suspend a thread inside waitForWaxing( ) or waitForBuffing( ):
//: C11:WaxOMatic.cpp {RunByHand}
// Basic thread cooperation.
//{L} ZThread
#include <iostream>
#include <string>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
#include "zthread/Condition.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
class Car {
Mutex lock;
Condition condition;
bool waxOn;
public:
Car() : condition(lock), waxOn(false) {}
void waxed() {
Guard<Mutex> g(lock);
waxOn = true; // Ready to buff
condition.signal();
}
void buffed() {
Guard<Mutex> g(lock);
waxOn = false; // Ready for another coat of wax
condition.signal();
}
void waitForWaxing() {
Guard<Mutex> g(lock);
while(waxOn == false)
condition.wait();
}
void waitForBuffing() {
Guard<Mutex> g(lock);
while(waxOn == true)
condition.wait();
}
};
class WaxOn : public Runnable {
CountedPtr<Car> car;
public:
WaxOn(CountedPtr<Car>& c) : car(c) {}
void run() {
try {
while(!Thread::interrupted()) {
cout << "Wax On!" <<
endl;
Thread::sleep(200);
car->waxed();
car->waitForBuffing();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Ending Wax On process"
<< endl;
}
};
class WaxOff : public Runnable {
CountedPtr<Car> car;
public:
WaxOff(CountedPtr<Car>& c) : car(c) {}
void run() {
try {
while(!Thread::interrupted()) {
car->waitForWaxing();
cout << "Wax Off!" <<
endl;
Thread::sleep(200);
car->buffed();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Ending Wax Off process"
<< endl;
}
};
int main() {
cout << "Press <Enter> to quit"
<< endl;
try {
CountedPtr<Car> car(new Car);
ThreadedExecutor executor;
executor.execute(new WaxOff(car));
executor.execute(new WaxOn(car));
cin.get();
executor.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~In Car's constructor, a single Mutex is wrapped in a Condition object so that it can be used to manage inter-task communication. However, the Condition object contains no information about the state of your process, so you need to manage additional information to indicate process state. Here, Car has a single bool waxOn, which indicates the state of the waxing-polishing process.
In waitForWaxing( ), the waxOn flag is checked, and if it is false, the calling thread is suspended by calling wait( ) on the Condition object. It's important that this occur inside a guarded clause, where the thread has acquired the lock (here, by creating a Guard object). When you call wait( ), the thread is suspended and the lock is released. It is essential that the lock be released because, to safely change the state of the object (for example, to change waxOn to true, which must happen if the suspended thread is to ever continue), that lock must be available to be acquired by some other task. In this example, when another thread calls waxed( ) to tell it that it's time to do something, the mutex must be acquired in order to change waxOn to true. Afterward, waxed( ) sends a signal( ) to the Condition object, which wakes up the thread suspended in the call to wait( ). Although signal( ) may be called inside a guarded clause—as it is here—you are not required to do this.(158)
In order for a thread to wake up from a wait( ), it must first reacquire the mutex that it released when it entered the wait( ). The thread will not wake up until that mutex becomes available.
The call to wait( ) is placed inside a while loop that checks the condition of interest. This is important for two reasons:(159)
- It is possible that when the thread gets a signal( ), some other condition has changed that is not associated with the reason that we called wait( ) here. If that is the case, this thread should be suspended again until its condition of interest changes.
- By the time this thread awakens from its wait( ), it's possible that some other task has changed things such that this thread is unable or uninterested in performing its operation at this time. Again, it should be re-suspended by calling wait( ) again.
Because these two reasons are always present when you are calling wait( ), always write your call to wait( ) inside a while loop that tests for your condition(s) of interest.
WaxOn::run( ) represents the first step in the process of waxing the car, so it performs its operation (a call to sleep( ) to simulate the time necessary for waxing). It then tells the car that waxing is complete, and calls waitForBuffing( ), which suspends this thread with a wait( ) until the WaxOff process calls buffed( ) for the car, changing the state and calling notify( ). WaxOff::run( ), on the other hand, immediately moves into waitForWaxing( ) and is thus suspended until the wax has been applied by WaxOn and waxed( ) is called. When you run this program, you can watch this two-step process repeat itself as control is handed back and forth between the two threads. When you press the <Enter> key, interrupt( ) halts both threads—when you call interrupt( ) for an Executor, it calls interrupt( ) for all the threads it is controlling.
3-4-7-2. Producer-consumer relationships▲
A common situation in threading problems is the producer-consumer relationship, where one task is creating objects and other tasks are consuming them. In such a situation, make sure that (among other things) the consuming tasks do not accidentally skip any of the produced objects.
To show this problem, consider a machine that has three tasks: one to make toast, one to butter the toast, and one to put jam on the buttered toast.
//: C11:ToastOMatic.cpp {RunByHand}
// Problems with thread cooperation.
//{L} ZThread
#include <iostream>
#include <cstdlib>
#include <ctime>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
#include "zthread/Condition.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
// Apply jam to buttered toast:
class Jammer : public Runnable {
Mutex lock;
Condition butteredToastReady;
bool gotButteredToast;
int jammed;
public:
Jammer() : butteredToastReady(lock) {
gotButteredToast = false;
jammed = 0;
}
void moreButteredToastReady() {
Guard<Mutex> g(lock);
gotButteredToast = true;
butteredToastReady.signal();
}
void run() {
try {
while(!Thread::interrupted()) {
{
Guard<Mutex> g(lock);
while(!gotButteredToast)
butteredToastReady.wait();
++jammed;
}
cout << "Putting jam on toast "
<< jammed << endl;
{
Guard<Mutex> g(lock);
gotButteredToast = false;
}
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Jammer off" << endl;
}
};
// Apply butter to toast:
class Butterer : public Runnable {
Mutex lock;
Condition toastReady;
CountedPtr<Jammer> jammer;
bool gotToast;
int buttered;
public:
Butterer(CountedPtr<Jammer>& j)
: toastReady(lock), jammer(j) {
gotToast = false;
buttered = 0;
}
void moreToastReady() {
Guard<Mutex> g(lock);
gotToast = true;
toastReady.signal();
}
void run() {
try {
while(!Thread::interrupted()) {
{
Guard<Mutex> g(lock);
while(!gotToast)
toastReady.wait();
++buttered;
}
cout << "Buttering toast "
<< buttered << endl;
jammer->moreButteredToastReady();
{
Guard<Mutex> g(lock);
gotToast = false;
}
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Butterer off" <<
endl;
}
};
class Toaster : public Runnable {
CountedPtr<Butterer> butterer;
int toasted;
public:
Toaster(CountedPtr<Butterer>& b) :
butterer(b) {
toasted = 0;
}
void run() {
try {
while(!Thread::interrupted()) {
Thread::sleep(rand()/(RAND_MAX/5)*100);
// ...
// Create new toast
// ...
cout << "New toast " <<
++toasted << endl;
butterer->moreToastReady();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Toaster off" <<
endl;
}
};
int main() {
srand(time(0)); // Seed the random number generator
try {
cout << "Press <Return> to
quit" << endl;
CountedPtr<Jammer> jammer(new Jammer);
CountedPtr<Butterer> butterer(new
Butterer(jammer));
ThreadedExecutor executor;
executor.execute(new Toaster(butterer));
executor.execute(butterer);
executor.execute(jammer);
cin.get();
executor.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The classes are defined in the reverse order that they operate to simplify forward-referencing issues.
Jammer and Butterer both contain a Mutex, a Condition, and some kind of internal state information that changes to indicate that the process should suspend or resume. (Toaster doesn't need these since it is the producer and doesn't have to wait on anything.) The two run( ) functions perform an operation, set a state flag, and then call wait( ) to suspend the task. The moreToastReady( ) and moreButteredToastReady( ) functions change their respective state flags to indicate that something has changed and the process should consider resuming and then call signal( ) to wake up the thread.
The difference between this example and the previous one is that, at least conceptually, something is being produced here: toast. The rate of toast production is randomized a bit, to add some uncertainty. And you'll see that when you run the program, things aren't going right because many pieces of toast appear to be getting dropped on the floor—not buttered, not jammed.
3-4-7-3. Solving threading problems with queues▲
Often, threading problems are based on the need for tasks to be serialized—that is, to take care of things in order. ToastOMatic.cpp must not only take care of things in order, it must be able to work on one piece of toast without worrying that toast is falling on the floor in the meantime. You can solve many threading problems by using a queue that synchronizes access to the elements within:
//: C11:TQueue.h
#ifndef TQUEUE_H
#define TQUEUE_H
#include <deque>
#include "zthread/Thread.h"
#include "zthread/Condition.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
template<class T> class TQueue {
ZThread::Mutex lock;
ZThread::Condition cond;
std::deque<T> data;
public:
TQueue() : cond(lock) {}
void put(T item) {
ZThread::Guard<ZThread::Mutex> g(lock);
data.push_back(item);
cond.signal();
}
T get() {
ZThread::Guard<ZThread::Mutex> g(lock);
while(data.empty())
cond.wait();
T returnVal = data.front();
data.pop_front();
return returnVal;
}
};
#endif // TQUEUE_H ///:~This builds on the Standard C++ Library deque by adding:
- Synchronization to ensure that no two threads add objects at the same time.
- wait( ) and signal( ) so that a consumer thread will automatically suspend if the queue is empty, and resume when more elements become available.
This relatively small amount of code can solve a remarkable number of problems.(160)
Here's a simple test that serializes the execution of LiftOff objects. The consumer is LiftOffRunner, which pulls each LiftOff object off the TQueue and runs it directly. (That is, it uses its own thread by calling run( ) explicitly rather than starting up a new thread for each task.)
//: C11:TestTQueue.cpp {RunByHand}
//{L} ZThread
#include <string>
#include <iostream>
#include "TQueue.h"
#include "zthread/Thread.h"
#include "LiftOff.h"
using namespace ZThread;
using namespace std;
class LiftOffRunner : public Runnable {
TQueue<LiftOff*> rockets;
public:
void add(LiftOff* lo) { rockets.put(lo); }
void run() {
try {
while(!Thread::interrupted()) {
LiftOff* rocket = rockets.get();
rocket->run();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Exiting LiftOffRunner"
<< endl;
}
};
int main() {
try {
LiftOffRunner* lor = new LiftOffRunner;
Thread t(lor);
for(int i = 0; i < 5; i++)
lor->add(new LiftOff(10, i));
cin.get();
lor->add(new LiftOff(10, 99));
cin.get();
t.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~The tasks are placed on the TQueue by main( ) and are taken off the TQueue by the LiftOffRunner. Notice that LiftOffRunner can ignore the synchronization issues because they are solved by the TQueue.
Proper toasting
To solve the ToastOMatic.cpp problem, we can run the toast through TQueues between processes. And to do this, we will need actual toast objects, which maintain and display their state:
//: C11:ToastOMaticMarkII.cpp {RunByHand}
// Solving the problems using TQueues.
//{L} ZThread
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
#include "zthread/Condition.h"
#include "zthread/ThreadedExecutor.h"
#include "TQueue.h"
using namespace ZThread;
using namespace std;
class Toast {
enum Status { DRY, BUTTERED, JAMMED };
Status status;
int id;
public:
Toast(int idn) : status(DRY), id(idn) {}
#ifdef __DMC__ // Incorrectly requires default
Toast() { assert(0); } // Should never be called
#endif
void butter() { status = BUTTERED; }
void jam() { status = JAMMED; }
string getStatus() const {
switch(status) {
case DRY: return "dry";
case BUTTERED: return "buttered";
case JAMMED: return "jammed";
default: return "error";
}
}
int getId() { return id; }
friend ostream& operator<<(ostream& os,
const Toast& t) {
return os << "Toast " << t.id
<< ": " << t.getStatus();
}
};
typedef CountedPtr< TQueue<Toast> >
ToastQueue;
class Toaster : public Runnable {
ToastQueue toastQueue;
int count;
public:
Toaster(ToastQueue& tq) : toastQueue(tq),
count(0) {}
void run() {
try {
while(!Thread::interrupted()) {
int delay = rand()/(RAND_MAX/5)*100;
Thread::sleep(delay);
// Make toast
Toast t(count++);
cout << t << endl;
// Insert into queue
toastQueue->put(t);
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Toaster off" <<
endl;
}
};
// Apply butter to toast:
class Butterer : public Runnable {
ToastQueue dryQueue, butteredQueue;
public:
Butterer(ToastQueue& dry, ToastQueue&
buttered)
: dryQueue(dry), butteredQueue(buttered) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until next piece of toast is
available:
Toast t = dryQueue->get();
t.butter();
cout << t << endl;
butteredQueue->put(t);
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Butterer off" <<
endl;
}
};
// Apply jam to buttered toast:
class Jammer : public Runnable {
ToastQueue butteredQueue, finishedQueue;
public:
Jammer(ToastQueue& buttered, ToastQueue&
finished)
: butteredQueue(buttered), finishedQueue(finished) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until next piece of toast is
available:
Toast t = butteredQueue->get();
t.jam();
cout << t << endl;
finishedQueue->put(t);
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Jammer off" << endl;
}
};
// Consume the toast:
class Eater : public Runnable {
ToastQueue finishedQueue;
int counter;
public:
Eater(ToastQueue& finished)
: finishedQueue(finished), counter(0) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until next piece of toast is
available:
Toast t = finishedQueue->get();
// Verify that the toast is coming in order,
// and that all pieces are getting jammed:
if(t.getId() != counter++ ||
t.getStatus() != "jammed") {
cout << ">>>> Error:
" << t << endl;
exit(1);
} else
cout << "Chomp! " << t
<< endl;
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Eater off" << endl;
}
};
int main() {
srand(time(0)); // Seed the random number generator
try {
ToastQueue dryQueue(new TQueue<Toast>),
butteredQueue(new TQueue<Toast>),
finishedQueue(new TQueue<Toast>);
cout << "Press <Return> to
quit" << endl;
ThreadedExecutor executor;
executor.execute(new Toaster(dryQueue));
executor.execute(new
Butterer(dryQueue,butteredQueue));
executor.execute(
new Jammer(butteredQueue, finishedQueue));
executor.execute(new Eater(finishedQueue));
cin.get();
executor.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Two things are immediately apparent in this solution: first, the amount and complexity of code within each Runnable class is dramatically reduced by the use of the TQueue because the guarding, communication, and wait( )/signal( ) operations are now taken care of by the TQueue. The Runnable classes don't have Mutexes or Condition objects anymore. Second, the coupling between the classes is eliminated because each class communicates only with its TQueues. Notice that the definition order of the classes is now independent. Less code and less coupling are always good things, which suggests that the use of the TQueue has a positive effect here, as it does on most problems.
3-4-7-4. Broadcast▲
The signal( ) function wakes up one thread that is waiting on a Condition object. However, multiple threads may be waiting on the same condition object, and in that case you might want to wake them all up using broadcast( ) instead of signal( ).
As an example that brings together many of the concepts in this chapter, consider a hypothetical robotic assembly line for automobiles. Each Car will be built in several stages, and in this example we'll look at a single stage: after the chassis has been created, at the time when the engine, drive train, and wheels are attached. The Cars are transported from one place to another via a CarQueue, which is a type of TQueue. A Director takes each Car (as a raw chassis) from the incoming CarQueue and places it in a Cradle, which is where all the work is done. At this point, the Director tells all the waiting robots (using broadcast( )) that the Car is in the Cradle ready for the robots to work on it. The three types of robots go to work, sending a message to the Cradle when they finish their tasks. The Director waits until all the tasks are complete and then puts the Car onto the outgoing CarQueue to be transported to the next operation. Here, the consumer of the outgoing CarQueue is a Reporter object, which just prints the Car to show that the tasks have been properly completed.
//: C11:CarBuilder.cpp {RunByHand}
// How broadcast() works.
//{L} ZThread
#include <iostream>
#include <string>
#include "zthread/Thread.h"
#include "zthread/Mutex.h"
#include "zthread/Guard.h"
#include "zthread/Condition.h"
#include "zthread/ThreadedExecutor.h"
#include "TQueue.h"
using namespace ZThread;
using namespace std;
class Car {
int id;
bool engine, driveTrain, wheels;
public:
Car(int idn) : id(idn), engine(false),
driveTrain(false), wheels(false) {}
// Empty Car object:
Car() : id(-1), engine(false),
driveTrain(false), wheels(false) {}
// Unsynchronized -- assumes atomic bool operations:
int getId() { return id; }
void addEngine() { engine = true; }
bool engineInstalled() { return engine; }
void addDriveTrain() { driveTrain = true; }
bool driveTrainInstalled() { return driveTrain; }
void addWheels() { wheels = true; }
bool wheelsInstalled() { return wheels; }
friend ostream& operator<<(ostream& os,
const Car& c) {
return os << "Car " << c.id
<< " ["
<< " engine: " << c.engine
<< " driveTrain: " <<
c.driveTrain
<< " wheels: " << c.wheels
<< " ]";
}
};
typedef CountedPtr< TQueue<Car> > CarQueue;
class ChassisBuilder : public Runnable {
CarQueue carQueue;
int counter;
public:
ChassisBuilder(CarQueue& cq) :
carQueue(cq),counter(0) {}
void run() {
try {
while(!Thread::interrupted()) {
Thread::sleep(1000);
// Make chassis:
Car c(counter++);
cout << c << endl;
// Insert into queue
carQueue->put(c);
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "ChassisBuilder off"
<< endl;
}
};
class Cradle {
Car c; // Holds current car being worked on
bool occupied;
Mutex workLock, readyLock;
Condition workCondition, readyCondition;
bool engineBotHired, wheelBotHired,
driveTrainBotHired;
public:
Cradle()
: workCondition(workLock), readyCondition(readyLock)
{
occupied = false;
engineBotHired = true;
wheelBotHired = true;
driveTrainBotHired = true;
}
void insertCar(Car chassis) {
c = chassis;
occupied = true;
}
Car getCar() { // Can only extract car once
if(!occupied) {
cerr << "No Car in Cradle for
getCar()" << endl;
return Car(); // "Null" Car object
}
occupied = false;
return c;
}
// Access car while in cradle:
Car* operator->() { return &c; }
// Allow robots to offer services to this cradle:
void offerEngineBotServices() {
Guard<Mutex> g(workLock);
while(engineBotHired)
workCondition.wait();
engineBotHired = true; // Accept the job
}
void offerWheelBotServices() {
Guard<Mutex> g(workLock);
while(wheelBotHired)
workCondition.wait();
wheelBotHired = true; // Accept the job
}
void offerDriveTrainBotServices() {
Guard<Mutex> g(workLock);
while(driveTrainBotHired)
workCondition.wait();
driveTrainBotHired = true; // Accept the job
}
// Tell waiting robots that work is ready:
void startWork() {
Guard<Mutex> g(workLock);
engineBotHired = false;
wheelBotHired = false;
driveTrainBotHired = false;
workCondition.broadcast();
}
// Each robot reports when their job is done:
void taskFinished() {
Guard<Mutex> g(readyLock);
readyCondition.signal();
}
// Director waits until all jobs are done:
void waitUntilWorkFinished() {
Guard<Mutex> g(readyLock);
while(!(c.engineInstalled() &&
c.driveTrainInstalled()
&& c.wheelsInstalled()))
readyCondition.wait();
}
};
typedef CountedPtr<Cradle> CradlePtr;
class Director : public Runnable {
CarQueue chassisQueue, finishingQueue;
CradlePtr cradle;
public:
Director(CarQueue& cq, CarQueue& fq,
CradlePtr cr)
: chassisQueue(cq), finishingQueue(fq), cradle(cr) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until chassis is available:
cradle->insertCar(chassisQueue->get());
// Notify robots car is ready for work
cradle->startWork();
// Wait until work completes
cradle->waitUntilWorkFinished();
// Put car into queue for further work
finishingQueue->put(cradle->getCar());
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Director off" <<
endl;
}
};
class EngineRobot : public Runnable {
CradlePtr cradle;
public:
EngineRobot(CradlePtr cr) : cradle(cr) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until job is offered/accepted:
cradle->offerEngineBotServices();
cout << "Installing engine"
<< endl;
(*cradle)->addEngine();
cradle->taskFinished();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "EngineRobot off" <<
endl;
}
};
class DriveTrainRobot : public Runnable {
CradlePtr cradle;
public:
DriveTrainRobot(CradlePtr cr) : cradle(cr) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until job is offered/accepted:
cradle->offerDriveTrainBotServices();
cout << "Installing DriveTrain"
<< endl;
(*cradle)->addDriveTrain();
cradle->taskFinished();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "DriveTrainRobot off"
<< endl;
}
};
class WheelRobot : public Runnable {
CradlePtr cradle;
public:
WheelRobot(CradlePtr cr) : cradle(cr) {}
void run() {
try {
while(!Thread::interrupted()) {
// Blocks until job is offered/accepted:
cradle->offerWheelBotServices();
cout << "Installing Wheels"
<< endl;
(*cradle)->addWheels();
cradle->taskFinished();
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "WheelRobot off" <<
endl;
}
};
class Reporter : public Runnable {
CarQueue carQueue;
public:
Reporter(CarQueue& cq) : carQueue(cq) {}
void run() {
try {
while(!Thread::interrupted()) {
cout << carQueue->get() << endl;
}
} catch(Interrupted_Exception&) { /* Exit */ }
cout << "Reporter off" <<
endl;
}
};
int main() {
cout << "Press <Enter> to quit"
<< endl;
try {
CarQueue chassisQueue(new TQueue<Car>),
finishingQueue(new TQueue<Car>);
CradlePtr cradle(new Cradle);
ThreadedExecutor assemblyLine;
assemblyLine.execute(new EngineRobot(cradle));
assemblyLine.execute(new DriveTrainRobot(cradle));
assemblyLine.execute(new WheelRobot(cradle));
assemblyLine.execute(
new Director(chassisQueue, finishingQueue,
cradle));
assemblyLine.execute(new Reporter(finishingQueue));
// Start everything running by producing chassis:
assemblyLine.execute(new
ChassisBuilder(chassisQueue));
cin.get();
assemblyLine.interrupt();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~You'll notice that Car takes a shortcut: it assumes that bool operations are atomic, which, as previously discussed, is sometimes a safe assumption but requires careful thought.(161) Each Car begins as an unadorned chassis, and different robots will attach different parts to it, calling the appropriate “add” function when they do.
A ChassisBuilder simply creates a new Car every second and places it into the chassisQueue. A Director manages the build process by taking the next Car off the chassisQueue, putting it into the Cradle, telling all the robots to startWork( ), and suspending itself by calling waitUntilWorkFinished( ). When the work is done, the Director takes the Car out of the Cradle and puts in into the finishingQueue.
The Cradle is the crux of the signaling operations. A Mutex and a Condition object control both the working of the robots and indicate whether all the operations are finished. A particular type of robot can offer its services to the Cradle by calling the “offer” function appropriate to its type. At this point, that robot thread is suspended until the Director calls startWork( ), which changes the hiring flags and calls broadcast( ) to tell all the robots to show up for work. Although this system allows any number of robots to offer their services, each one of those robots has its thread suspended by doing so. You could imagine a more sophisticated system where the robots register themselves with many different Cradles without being suspended by that registration process and then reside in a pool waiting for the first Cradle that needs a task completed.
After each robot finishes its task (changing the state of the Car in the process), it calls taskFinished( ), which sends a signal( ) to the readyCondition, which is what the Director is waiting on in waitUntilWorkFinished( ). Each time the director thread awakens, the state of the Car is checked, and if it still isn't finished, that thread is suspended again.
When the Director inserts a Car into the Cradle, you can perform operations on that Car via the operator->( ). To prevent multiple extractions of the same car, a flag causes an error report to be generated. (Exceptions don't propagate across threads in the ZThread library.)
In main( ), all the necessary objects are created and the tasks are initialized, with the ChassisBuilder begun last to start the process. (However, because of the behavior of the TQueue, it wouldn't matter if it were started first.) Note that this program follows all the guidelines regarding object and task lifetime presented in this chapter, and so the shutdown process is safe.
3-4-8. Deadlock▲
Because threads can become blocked and because objects can have mutexes that prevent threads from accessing that object until the mutex is released, it's possible for one thread to get stuck waiting for another thread, which in turn waits for another thread, and so on, until the chain leads back to a thread waiting on the first one. You get a continuous loop of threads waiting on each other, and no one can move. This is called deadlock.
If you try running a program and it deadlocks right away, you immediately know you have a problem, and you can track it down. The real problem is when your program seems to be working fine but has the hidden potential to deadlock. In this case, you may get no indication that deadlocking is a possibility, so it will be latent in your program until it unexpectedly happens to a customer. (And you probably won't be able to easily reproduce it.) Thus, preventing deadlock through careful program design is a critical part of developing concurrent programs.
Let's look at the classic demonstration of deadlock, invented by Edsger Dijkstra: the dining philosophers problem. The basic description specifies five philosophers (but the example shown here will allow any number). These philosophers spend part of their time thinking and part of their time eating. While they are thinking, they don't need any shared resources, but they eat using a limited number of utensils. In the original problem description, the utensils are forks, and two forks are required to get spaghetti from a bowl in the middle of the table, but it seems to make more sense to say that the utensils are chopsticks. Clearly, each philosopher will require two chopsticks in order to eat.
A difficulty is introduced into the problem: as philosophers, they have very little money, so they can only afford five chopsticks. These are spaced around the table between them. When a philosopher wants to eat, they must pick up the chopstick to the left and the one to the right. If the philosopher on either side is using a desired chopstick, our philosopher must wait until the necessary chopsticks become available.
//: C11:DiningPhilosophers.h
// Classes for Dining Philosophers.
#ifndef DININGPHILOSOPHERS_H
#define DININGPHILOSOPHERS_H
#include <string>
#include <iostream>
#include <cstdlib>
#include "zthread/Condition.h"
#include "zthread/Guard.h"
#include "zthread/Mutex.h"
#include "zthread/Thread.h"
#include "Display.h"
class Chopstick {
ZThread::Mutex lock;
ZThread::Condition notTaken;
bool taken;
public:
Chopstick() : notTaken(lock), taken(false) {}
void take() {
ZThread::Guard<ZThread::Mutex> g(lock);
while(taken)
notTaken.wait();
taken = true;
}
void drop() {
ZThread::Guard<ZThread::Mutex> g(lock);
taken = false;
notTaken.signal();
}
};
class Philosopher : public ZThread::Runnable {
Chopstick& left;
Chopstick& right;
int id;
int ponderFactor;
ZThread::CountedPtr<Display> display;
int randSleepTime() {
if(ponderFactor == 0) return 0;
return rand()/(RAND_MAX/ponderFactor) * 250;
}
void output(std::string s) {
std::ostringstream os;
os << *this << " " << s
<< std::endl;
display->output(os);
}
public:
Philosopher(Chopstick& l, Chopstick& r,
ZThread::CountedPtr<Display>& disp, int
ident,int ponder)
: left(l), right(r), id(ident), ponderFactor(ponder),
display(disp) {}
virtual void run() {
try {
while(!ZThread::Thread::interrupted()) {
output("thinking");
ZThread::Thread::sleep(randSleepTime());
// Hungry
output("grabbing right");
right.take();
output("grabbing left");
left.take();
output("eating");
ZThread::Thread::sleep(randSleepTime());
right.drop();
left.drop();
}
} catch(ZThread::Synchronization_Exception& e)
{
output(e.what());
}
}
friend std::ostream&
operator<<(std::ostream& os, const
Philosopher& p) {
return os << "Philosopher " <<
p.id;
}
};
#endif // DININGPHILOSOPHERS_H
///:~No two Philosophers can take( ) a Chopstick at the same time, since take( ) is synchronized with a Mutex. In addition, if the chopstick has already been taken by one Philosopher, another can wait( ) on the available Condition until the Chopstick becomes available when the current holder calls drop( ) (which must also be synchronized to prevent race conditions and ensure memory visibility in multiprocessor systems).
Each Philosopher holds references to their left and right Chopstick so they can attempt to pick those up. The goal of the Philosopher is to think part of the time and eat part of the time, and this is expressed in main( ). However, you will observe that if the Philosophers spend very little time thinking, they will all be competing for the Chopsticks while they try to eat, and deadlock will happen much more quickly. So you can experiment with this, the ponderFactor weights the length of time that a Philosopher tends to spend thinking and eating. A smaller ponderFactor will increase the probability of deadlock.
In Philosopher::run( ), each Philosopher just thinks and eats continuously. You see the Philosopher thinking for a randomized amount of time, then trying to take( ) the right and then the left Chopstick, eating for a randomized amount of time, and then doing it again. Output to the console is synchronized as seen earlier in this chapter.
This problem is interesting because it demonstrates that a program can appear to run correctly but actually be deadlock prone. To show this, the command-line argument adjusts a factor to affect the amount of time each philosopher spends thinking. If you have lots of philosophers or they spend a lot of time thinking, you may never see the deadlock even though it remains a possibility. A command-line argument of zero tends to make it deadlock fairly quickly:(162)
//: C11:DeadlockingDiningPhilosophers.cpp {RunByHand}
// Dining Philosophers with Deadlock.
//{L} ZThread
#include <ctime>
#include "DiningPhilosophers.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
int main(int argc, char* argv[]) {
srand(time(0)); // Seed the random number generator
int ponder = argc > 1 ? atoi(argv[1]) : 5;
cout << "Press <ENTER> to quit"
<< endl;
enum { SZ = 5 };
try {
CountedPtr<Display> d(new Display);
ThreadedExecutor executor;
Chopstick c[SZ];
for(int i = 0; i < SZ; i++) {
executor.execute(
new Philosopher(c[i], c[(i+1) % SZ], d,
i,ponder));
}
cin.get();
executor.interrupt();
executor.wait();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~Note that the Chopstick objects do not need internal identifiers; they are identified by their position in the array c.Each Philosopher is given a reference to a left and right Chopstick object when constructed; these are the utensils that must be picked up before that Philosopher can eat. Every Philosopher except the last one is initialized by situating that Philosopher between the next pair of Chopstick objects. The last Philosopher is given the zeroth Chopstick for its right Chopstick, so the round table is completed. That's because the last Philosopher is sitting right next to the first one, and they both share that zeroth chopstick. With this arrangement, it's possible at some point for all the philosophers to be trying to eat and waiting on the philosopher next to them to put down their chopstick, and the program will deadlock.
If your threads (philosophers) are spending more time on other tasks (thinking) than eating, then they have a much lower probability of requiring the shared resources (chopsticks), and thus you can convince yourself that the program is deadlock free (using a nonzero ponder value), even though it isn't.
To repair the problem, you must understand that deadlock can occur if four conditions are simultaneously met:
1. Mutual exclusion. At least one resource used by the threads must not be shareable. In this case, a chopstick can be used by only one philosopher at a time.
2. At least one process must be holding a resource and waiting to acquire a resource currently held by another process. That is, for deadlock to occur, a philosopher must be holding one chopstick and waiting for another one.
3. A resource cannot be preemptively taken away from a process. Processes only release resources as a normal event. Our philosophers are polite and they don't grab chopsticks from other philosophers.
4. A circular wait can happen, whereby a process waits on a resource held by another process, which in turn is waiting on a resource held by another process, and so on, until one of the processes is waiting on a resource held by the first process, thus gridlocking everything. In DeadlockingDiningPhilosophers.cpp, the circular wait happens because each philosopher tries to get the right chopstick first and then the left.
Because all these conditions must be met to cause deadlock, you need to stop only one of them from occurring to prevent deadlock. In this program, the easiest way to prevent deadlock is to break condition four. This condition happens because each philosopher is trying to pick up their chopsticks in a particular sequence: first right, then left. Because of that, it's possible to get into a situation where each of them is holding their right chopstick and waiting to get the left, causing the circular wait condition. However, if the last philosopher is initialized to try to get the left chopstick first and then the right, that philosopher will never prevent the philosopher on the immediate right from picking up their left chopstick. In this case, the circular wait is prevented. This is only one solution to the problem, but you could also solve it by preventing one of the other conditions (see advanced threading books for more details):
//: C11:FixedDiningPhilosophers.cpp {RunByHand}
// Dining Philosophers without Deadlock.
//{L} ZThread
#include <ctime>
#include "DiningPhilosophers.h"
#include "zthread/ThreadedExecutor.h"
using namespace ZThread;
using namespace std;
int main(int argc, char* argv[]) {
srand(time(0)); // Seed the random number generator
int ponder = argc > 1 ? atoi(argv[1]) : 5;
cout << "Press <ENTER> to quit"
<< endl;
enum { SZ = 5 };
try {
CountedPtr<Display> d(new Display);
ThreadedExecutor executor;
Chopstick c[SZ];
for(int i = 0; i < SZ; i++) {
if(i < (SZ-1))
executor.execute(
new Philosopher(c[i], c[i + 1], d, i,
ponder));
else
executor.execute(
new Philosopher(c[0], c[i], d, i, ponder));
}
cin.get();
executor.interrupt();
executor.wait();
} catch(Synchronization_Exception& e) {
cerr << e.what() << endl;
}
} ///:~By ensuring that the last philosopher picks up and puts down their left chopstick before their right, the deadlock is removed, and the program will run smoothly.
There is no language support to help prevent deadlock; it's up to you to avoid it by careful design. These are not comforting words to the person who's trying to debug a deadlocking program.
3-4-9. Summary▲
The goal of this chapter was to give you the foundations of concurrent programming with threads:
1. You can run multiple independent tasks.
2. You must consider all the possible problems when these tasks shut down. Objects or other tasks may disappear before tasks are finished with them.
3. Tasks can collide with each other over shared resources. The mutex is the basic tool used to prevent these collisions.
4. Tasks can deadlock if they are not carefully designed.
However, there are multiple additional facets of threading and tools to help you solve threading problems. The ZThreads library contains a number of these tools, such as semaphores and special types of queues, similar to the one you saw in this chapter. Explore that library as well as other resources on threading to gain more in-depth knowledge.
It is vital to learn when to use concurrency and when to avoid it. The main reasons to use it are:
- To manage a number of tasks whose intermingling use the computer more efficiently (including the ability to transparently distribute the tasks across multiple CPUs).
- To allow better code organization.
- To be more convenient for the user.
The classic example of resource balancing is to use the CPU during I/O waits. The classic example of user convenience is to monitor a “stop” button during long downloads.
An additional advantage to threads is that they provide “light” execution context switches (on the order of 100 instructions) rather than “heavy” process context switches (thousands of instructions). Since all threads in a given process share the same memory space, a light context switch changes only program execution and local variables. A process change—the heavy context switch—must exchange the full memory space.
The main drawbacks to multithreading are:
- Slowdown occurs while waiting for shared resources.
- Additional CPU overhead is required to manage threads.
- Unrewarded complexity arises from poor design decisions.
- Opportunities are created for pathologies such as starving, racing, deadlock, and livelock.
- Inconsistencies occur across platforms. When developing the original material (in Java) for this chapter, we discovered race conditions that quickly appeared on some computers but wouldn't appear on others. The C++ examples in this chapter behaved differently (but usually acceptably) under different operating systems. If you develop a program on a computer and things seem to work right, you might get an unwelcome surprise when you distribute it.
One of the biggest difficulties with threads occurs because more than one thread might be sharing a resource—such as the memory in an object—and you must make sure that multiple threads don't try to read and change that resource at the same time. This requires judicious use of synchronization tools, which must be thoroughly understood because they can quietly introduce deadlock situations.
In addition, there's a certain art to the application of threads. C++ is designed to allow you to create as many objects as you need to solve your problem—at least in theory. (Creating millions of objects for an engineering finite-element analysis, for example, might not be practical.) However, there is usually an upper bound to the number of threads you'll want to create, because at some number, threads may become balky. This critical point can be difficult to detect and will often depend on the OS and thread library; it could be fewer than a hundred or in the thousands. As you often create only a handful of threads to solve a problem, this is typically not much of a limit; but in a more general design it becomes a constraint.
Regardless of how simple threading can seem using a particular language or library, consider it a black art. There's always something you haven't considered that can bite you when you least expect it. (For example, note that because the dining philosophers problem can be adjusted so that deadlock rarely happens, you can get the impression that everything is OK.) An appropriate quote comes from Guido van Rossum, creator of the Python programming language:
In any project that is multithreaded, most bugs will come from threading issues. This is regardless of programming language—it's a deep, as yet un-understood property of threads.
For more advanced discussions of threading, see Parallel and Distributed Programming Using C++, by Cameron Hughes and Tracey Hughes, Addison Wesley 2004.
3-4-10. Exercises▲
Solutions to selected exercises can be found in the electronic document The Thinking in C++ Volume 2 Annotated Solution Guide, available for a small fee from www.MindView.net.
- Inherit a class from Runnable and override the run( ) function. Inside run( ), print a message, and then call sleep( ). Repeat this three times, and then return from run( ). Put a start-up message in the constructor and a shut-down message when the task terminates. Make several thread objects of this type, and run them to see what happens.
- Modify BasicThreads.cpp to make LiftOff threads start other LiftOff threads.
- Modify ResponsiveUI.cpp to eliminate any possible race conditions. (Assume bool operations are not atomic.)
- In Incrementer.cpp, modify the Count class to use a single int instead of an array of int. Explain the resulting behavior.
- In EvenChecker.h, correct the potential problem in the Generator class. (Assume bool operations are not atomic.)
- Modify EvenGenerator.cpp to use interrupt( ) instead of quit flags.
- In MutexEvenGenerator.cpp, change the code in MutexEvenGenerator::nextValue( ) so that the return expression precedes the release( ) statement and explain what happens.
- Modify ResponsiveUI.cpp to use interrupt( ) instead of the quitFlag approach.
- Look up the Singleton documentation in the ZThreads library. Modify OrnamentalGarden.cpp so that the Display object is controlled by a Singleton to prevent more than one Display from being accidentally created.
- In OrnamentalGarden.cpp, change the Count::increment( ) function so that it does a direct increment of count (that is, it just does a count++). Now remove the guard and see if that causes a failure. Is this safe and reliable?
- Modify OrnamentalGarden.cpp so that it uses interrupt( ) instead of the pause( ) mechanism. Make sure that your solution doesn't prematurely destroy objects.
- Modify WaxOMatic.cpp by adding more instances of the Process class so that it applies and polishes three coats of wax instead of just one.
- Create two Runnable subclasses, one with a run( ) that starts and calls wait( ). The other class's run( ) should capture the reference of the first Runnable object. Its run( ) should call signal( ) for the first thread after some number of seconds have passed so that first thread can print a message.
- Create an example of a “busy wait.” One thread sleeps for awhile and then sets a flag to true. The second thread watches that flag inside a while loop (this is the “busy wait”) and, when the flag becomes true, sets it back to false and reports the change to the console. Note how much wasted time the program spends inside the “busy wait,” and create a second version of the program that uses wait( ) instead of the “busy wait.” Extra: run a profiler to show the time used by the CPU in each case.
- Modify TQueue.h to add a maximum allowable element count. If the count is reached, further writes should be blocked until the count drops below the maximum. Write code to test this behavior.
- Modify ToastOMaticMarkII.cpp to create peanut-butter and jelly on toast sandwiches using two separate assembly lines and an output TQueue for the finished sandwiches. Use a Reporter object as in CarBuilder.cpp to display the results.
- Rewrite C07:BankTeller.cpp to use real threading instead of simulated threading.
- Modify CarBuilder.cpp to give identifiers to the robots, and add more instances of the different kinds of robots. Note whether all robots get utilized.
- Modify CarBuilder.cpp to add another stage to the car-building process, whereby you add the exhaust system, body, and fenders. As with the first stage, assume these processes can be performed simultaneously by robots.
- Modify CarBuilder.cpp so that Car has synchronized access to all the bool variables. Because Mutexes cannot be copied, this will require significant changes throughout the program.
- Using the approach in CarBuilder.cpp, model the house-building story that was given in this chapter.
- Create a Timer class with two options: (1) a one-shot timer that only goes off once (2) a timer that goes off at regular intervals. Use this class with C10:MulticastCommand.cpp to move the calls to TaskRunner::run( ) from the procedures into the timer.
- Change both of the dining philosophers examples so that the number of Philosophers is controlled on the command line, in addition to the ponder time. Try different values and explain the results.
- Change DiningPhilosophers.cpp so that the Philosophers just pick the next available chopstick. (When a Philosopher is done with their chopsticks, they drop them into a bin. When a Philosopher wants to eat, they take the next two available chopsticks from the bin.) Does this eliminate the possibility of deadlock? Can you reintroduce deadlock by simply reducing the number of available chopsticks?