Thinking in C++ - Volume 2
Thinking in C++ - Volume 2
Date de publication : 25/01/2007 , Date de mise à jour : 25/01/2007
3.3. Design Patterns
3.3.1. The pattern concept
3.3.1.1. Prefer composition to inheritance
3.3.2. Classifying patterns
3.3.2.1. Features, idioms, patterns
3.3.3. Simplifying Idioms
3.3.3.1. Messenger
3.3.3.2. Collecting Parameter
3.3.4. Singleton
3.3.4.1. Variations on Singleton
3.3.5. Command: choosing the operation
3.3.5.1. Decoupling event handling with Command
3.3.6. Object decoupling
3.3.6.1. Proxy: fronting for another object
3.3.6.2. State: changing object behavior
3.3.7. Adapter
3.3.8. Template Method
3.3.9. Strategy: choosing the algorithm at runtime
3.3.10. Chain of Responsibility: trying a sequence of strategies
3.3.11. Factories: encapsulating object creation
3.3.11.1. Polymorphic factories
3.3.11.2. Abstract factories
3.3.11.3. Virtual constructors
3.3.12. Builder: creating complex objects
3.3.13. Observer
3.3.13.1. The “inner class” idiom
3.3.13.2. The observer example
3.3.14. Multiple dispatching
3.3.14.1. Multiple dispatching with Visitor
3.3.15. Summary
3.3.16. Exercises
3.3. Design Patterns
“… describe a problem which occurs
over and over again in our environment, and then describe the core of the
solution to that problem, in such a way that you can use this solution a
million times over, without ever doing it the same way twice”—Christopher
Alexander
This chapter introduces the important
and yet nontraditional “patterns” approach to program design.
The most important recent step forward in object-oriented
design is probably the “design patterns” movement, initially chronicled in Design Patterns, by Gamma, Helm, Johnson & Vlissides (Addison Wesley,
1995),(133) which is
commonly called the “Gang of Four” book (GoF). GoF shows 23 solutions to
particular classes of problems. In this chapter, we discuss the basic concepts
of design patterns and provide code examples that illustrate selected patterns.
This should whet your appetite for reading more about design patterns, a source
of what has now become an essential, almost mandatory vocabulary for
object-oriented programming.(134)
3.3.1. The pattern concept
Initially, you can think of a pattern as an especially
clever and insightful way to solve a particular class of problem. It appears
that a team of people have worked out all the angles of a problem and have come
up with the most general, flexible solution for that type of problem. This
problem could be one that you have seen and solved before, but your solution
probably didn't have the kind of completeness you'll see embodied in a pattern.
Furthermore, the pattern exists independently of any particular implementation
and it can be implemented in a number of ways.
Although they're called “design patterns,” they really
aren't tied to the realm of design. A pattern seems to stand apart from the
traditional way of thinking about analysis, design, and implementation.
Instead, a pattern embodies a complete idea within a program, and thus it might
also span the analysis phase and high-level design phase. However, because a
pattern often has a direct implementation in code, it might not show up until
low-level design or implementation (and you might not realize that you need a
particular pattern until you get to those phases).
The basic concept of a pattern can also be seen as the basic
concept of program design in general: adding layers of abstraction. Whenever you abstract something, you're isolating particular details, and one of the most
compelling motivations for this is to separate things that change from
things that stay the same. Another way to put this is that once you find
some part of your program that's likely to change, you'll want to keep those
changes from propagating side effects throughout your code. If you achieve
this, your code will not only be easier to read and understand, but also easier
to maintain—which invariably results in lowered costs over time.
The most difficult part of developing an elegant and
maintainable design is often discovering what we call “the vector of change.” (Here, “vector” refers to the maximum gradient as understood in the sciences,
and not a container class.) This means finding the most important thing that
changes in your system or, put another way, discovering where your greatest
cost is. Once you discover the vector of change, you have the focal point
around which to structure your design.
So the goal of design patterns is to encapsulate change.
If you look at it this way, you've been seeing some design patterns already in
this book. For example, inheritance could be thought of as a design pattern
(albeit one implemented by the compiler). It expresses differences in behavior
(that's the thing that changes) in objects that all have the same interface
(that's what stays the same). Composition could also be considered a pattern,
since you can change—dynamically or statically—the objects that implement your
class, and thus the way that class works. Normally, however, features that are
directly supported by a programming language have not been classified as design
patterns.
You've also already seen another pattern that appears in
GoF: the iterator. This is the fundamental tool used in the design of
the STL, described earlier in this book. The iterator hides the particular
implementation of the container as you're stepping through and selecting the
elements one by one. Iterators allow you to write generic code that performs an
operation on all the elements in a range without regard to the container that
holds the range. Thus, your generic code can be used with any container that
can produce iterators.
3.3.1.1. Prefer composition to inheritance
The most important contribution of GoF may not be a pattern,
but rather a maxim that they introduce in Chapter 1: “Favor object composition
over class inheritance.” Understanding inheritance and polymorphism is such a
challenge that you may begin to assign undue importance to these techniques. We
see many over-complicated designs (our own included) that result from
“inheritance indulgence”— for example, many multiple inheritance designs evolve
by insisting that inheritance be used everywhere.
One of the guidelines in Extreme Programming is “Do the simplest thing that could possibly work.” A design that seems to want
inheritance can often be dramatically simplified by using composition instead,
and you will also discover that the result is more flexible, as you will
understand by studying some of the design patterns in this chapter. So when
pondering a design, ask yourself: “Could this be simpler using composition? Do
I really need inheritance here, and what is it buying me?”
3.3.2. Classifying patterns
GoF discusses 23 patterns, classified under three purposes
(all of which revolve around the particular aspect that can vary):
- Creational: How an object can be created. This often involves isolating the details of object creation so your code isn't dependent on what types of objects there are and thus doesn't have to be changed when you add a new type of object. This chapter introduces Singleton, Factories, and Builder.
- Structural: These affect the way objects are connected with other objects to ensure that changes in the system don't require changes to those connections. Structural patterns are often dictated by project constraints. In this chapter you'll see Proxy and Adapter.
- Behavioral: Objects that handle particular types of actions within a program. These encapsulate processes that you want to perform, such as interpreting a language, fulfilling a request, moving through a sequence (as in an iterator), or implementing an algorithm. This chapter contains examples of Command, Template Method, State, Strategy, Chain of Responsibility, Observer, Multiple Dispatching, and Visitor.
GoF includes a section on each of its 23 patterns along with
one or more examples of each, typically in C++ but sometimes in Smalltalk. This
book will not repeat the details of the patterns shown in GoF since that book
stands on its own and should be studied separately. The description and
examples provided here are intended to give you a grasp of the patterns, so you
can get a feel for what patterns are about and why they are important.
3.3.2.1. Features, idioms, patterns
Work continues beyond what is in the GoF book. Since its
publication, there are more patterns and a more refined process for defining
design patterns.(135) This
is important because it is not easy to identify new patterns or to properly
describe them. There is some confusion in the popular literature on what a
design pattern is, for example. Patterns are not trivial, nor are they
typically represented by features that are built into a programming language. Constructors and destructors, for example, could be called the “guaranteed
initialization and cleanup design pattern.” These are important and essential
constructs, but they're routine language features and are not rich enough to be
considered design patterns.
Another non-example comes from various forms of aggregation. Aggregation is a completely fundamental principle in object-oriented
programming: you make objects out of other objects. Yet sometimes this idea is
erroneously classified as a pattern. This is unfortunate because it pollutes
the idea of the design pattern and suggests that anything that surprises you
the first time you see it should be made into a design pattern.
The Java language provides another misguided example: The
designers of the JavaBeans specification decided to refer to the simple
“get/set” naming convention as a design pattern (for example, getInfo( )
returns an Info property and setInfo( ) changes it). This is
just a commonplace naming convention and in no way constitutes a design
pattern.
3.3.3. Simplifying Idioms
Before getting into more complex techniques, it's helpful to
look at some basic ways to keep code simple and straightforward.
3.3.3.1. Messenger
The most trivial of these is the messenger,(136) which
packages information into an object which is passed around, instead of passing
all the pieces around separately. Note that without the messenger, the code for
translate( ) would be much more confusing to read:
|
The code here is trivialized to prevent distractions.
Since the goal of a messenger is only to carry data, that
data is made public for easy access. However, you may also have reasons to make
the fields private.
3.3.3.2. Collecting Parameter
Messenger's big brother is the collecting parameter, whose job is to capture information from the function to which it is passed.
Generally, this is used when the collecting parameter is passed to multiple
functions, so it's like a bee collecting pollen.
A container makes an especially useful collecting parameter,
since it is already set up to dynamically add objects:
|
The collecting parameter must have some way to set or insert
values. Note that by this definition, a messenger could be used as a collecting
parameter. The key is that a collecting parameter is passed about and modified
by the functions that receive it.
3.3.4. Singleton
Possibly the simplest GoF design pattern is the Singleton, which is a way to allow one and only one instance of a class. The
following program shows how to implement a Singleton in C++:
|
The key to creating a Singleton is to prevent the client
programmer from having any control over the lifetime of the object. To do this,
declare all constructors private, and prevent the compiler from
implicitly generating any constructors. Note that the copy constructor and assignment operator (which intentionally have no implementations, since they
will never be called) are declared private to prevent any sort of copies being
made.
You must also decide how you're going to create the object.
Here, it's created statically, but you can also wait until the client
programmer asks for one and create it on demand. This is called lazy initialization, and it only makes sense if it is expensive to create your object,
and if you don't always need it.
If you return a pointer instead of a reference, the user
could inadvertently delete the pointer, so the implementation above is
considered safest (the destructor can also be declared private or protected to
alleviate that problem). In any case, the object should be stored privately.
You provide access through public member functions. Here, instance( )
produces a reference to the Singleton object. The rest of the interface
(getValue( ) and setValue( )) is the regular class
interface.
Note that you aren't restricted to creating only one object.
This technique also supports the creation of a limited pool of objects. In that
case, however, you can be confronted with the problem of sharing objects in the
pool. If this is an issue, you can create a solution involving a check-out and
check-in of the shared objects.
3.3.4.1. Variations on Singleton
Any static member object inside a class is an
expression of Singleton: one and only one will be made. So in a sense, the
language has direct support for the idea; we certainly use it on a regular
basis. However, there's a problem with static objects (member or not):
the order of initialization, as described in Volume 1 of this book. If one static
object depends on another, it's important that the objects are initialized in
the correct order.
In Volume 1, you were shown how to control initialization order by defining a static object inside a function. This delays the initialization
of the object until the first time the function is called. If the function
returns a reference to the static object, it gives you the effect of a
Singleton while removing much of the worry of static initialization. For
example, suppose you want to create a log file upon the first call to a
function that returns a reference to that log file. This header file will do
the trick:
|
The implementation must not be inlined because that
would mean that the whole function, including the static object definition
within, could be duplicated in any translation unit where it's included, which
violates C++'s one-definition rule.(137) This
would most certainly foil the attempts to control the order of initialization
(but potentially in a subtle and hard-to-detect fashion). So the implementation
must be separate:
|
Now the log object will not be initialized until the
first time logfile( ) is called. So if you create a function:
|
that uses logfile( ) in its implementation:
|
And you use logfile( ) again in another file:
|
the log object doesn't get created until the first
call to f( ).
You can easily combine the creation of the static object
inside a member function with the Singleton class. SingletonPattern.cpp can be modified to use this approach:(138)
|
An especially interesting case occurs if two Singletons
depend on each other, like this:
|
When Singleton2::ref( ) is called, it causes its
sole Singleton2 object to be created. In the process of this creation, Singleton1::ref( )
is called, and that causes the sole Singleton1 object to be created.
Because this technique doesn't rely on the order of linking or loading, the
programmer has much better control over initialization, leading to fewer
problems.
Yet another variation on Singleton separates the
“Singleton-ness” of an object from its implementation. This is achieved using
the Curiously Recurring Template Pattern mentioned in Chapter 5:
|
MyClass is made a Singleton by:
1. Making
its constructor private or protected.
2. Making
Singleton<MyClass> a friend.
3. Deriving
MyClass from Singleton<MyClass>.
The self-referencing in step 3 may sound implausible, but as
we explained in Chapter 5, it works because there is only a static dependency
on the template argument in the Singleton template. In other words, the
code for the class Singleton<MyClass> can be instantiated by the
compiler because it is not dependent on the size of MyClass. It's only
later, when Singleton<MyClass>::instance( ) is first called,
that the size of MyClass is needed, and by then MyClass has been
compiled and its size is known.(139)
It's interesting how intricate such a simple pattern as
Singleton can be, and we haven't even addressed issues of thread safety. Finally,
Singleton should be used sparingly. True Singleton objects arise rarely, and
the last thing a Singleton should be used for is to replace a global variable.(140)
3.3.5. Command: choosing the operation
The Command pattern is structurally very simple, but can
have an important impact on decoupling—and thus cleaning up—your code.
In Advanced C++: Programming Styles And Idioms (Addison Wesley,
1992), Jim Coplien coins the term functor which is an object whose
sole purpose is to encapsulate a function (since “functor” has a meaning in
mathematics, we shall use the more explicit term function object). The point is to decouple the choice of function to be called from the site
where that function is called.
This term is mentioned but not used in GoF. However, the
theme of the function object is repeated in a number of patterns in that book.
A Command is a function object in its purest sense: a
function that's an object. By wrapping a function in an object, you can pass it
to other functions or objects as a parameter, to tell them to perform this
particular operation in the process of fulfilling your request. You could say
that a Command is a Messenger that carries behavior.
|
The primary point of Command is to allow you to hand a
desired action to a function or object. In the above example, this provides a
way to queue a set of actions to be performed collectively. Here, you can dynamically
create new behavior, something you can normally only do by writing new code but
in the above example could be done by interpreting a script (see the Interpreter
pattern if what you need to do gets very complex).
GoF says that “Commands are an object-oriented replacement
for callbacks.”(141) However,
we think that the word “back” is an essential part of the concept of
callbacks—a callback reaches back to the creator of the callback. On the other
hand, with a Command object you typically just create it and hand it to some function
or object, and you are not otherwise connected over time to the Command object.
A common example of Command is the implementation of “undo”
functionality in an application. Each time the user performs an operation, the
corresponding “undo” Command object is placed into a queue. Each Command object
that is executed backs up the state of the program by one step.
3.3.5.1. Decoupling event handling with Command
As you shall see in the next chapter, one of the reasons for
employing concurrency techniques is to more easily manage event-driven programming, where the events can appear unpredictably in your
program. For example, a user pressing a “quit” button while you're performing
an operation expects the program to respond quickly.
An argument for using concurrency is that it prevents
coupling across the pieces of your code. That is, if you're running a separate
thread to watch the quit button, your program's “normal” operations don't need
to know about the quit button or any of the other operations that need to be
watched.
However, once you understand that coupling is the issue, you
can avoid it using the Command pattern. Each “normal” operation must
periodically call a function to check the state of the events, but with the
Command pattern these normal operations don't need to know anything about what
they are checking, and thus are decoupled from the event-handling code:
|
Here, the Command object is represented by Tasks
executed by the Singleton TaskRunner. EventSimulator creates a
random delay time, so if you periodically call fired( ) the result
will change from false to true at some random time. EventSimulator
objects are used inside Buttons to simulate the act of a user event
occurring at some unpredictable time. CheckButton is the implementation
of the Task that is periodically checked by all the “normal” code in the
program—you can see this happening at the end of procedure1( ), procedure2( )
and procedure3( ).
Although this requires a little bit of extra thought to set
up, you'll see in Chapter 11 that threading requires a lot of thought
and care to prevent the various difficulties inherent to concurrent
programming, so the simpler solution may be preferable. You can also create a
very simple threading scheme by moving the TaskRunner::run( ) calls
into a multithreaded “timer” object. By doing this, you eliminate all coupling
between the “normal operations” (procedures, in the above example) and the
event code.
3.3.6. Object decoupling
Both Proxy and State provide a surrogate class. Your code talks to this surrogate class, and the real class that does the work is
hidden behind this surrogate class. When you call a function in the surrogate,
it simply turns around and calls the function in the implementing class. These
two patterns are so similar that, structurally, Proxy is simply a special case
of State. One is tempted to just lump the two together into a pattern called Surrogate,
but the intent of the two patterns is different. It can be easy to fall
into the trap of thinking that if the structure is the same, the patterns are
the same. You must always look to the intent of the pattern in order to be
clear about what it does.
The basic idea is simple: from a base class, the surrogate
is derived along with the class or classes that provide the actual
implementation:
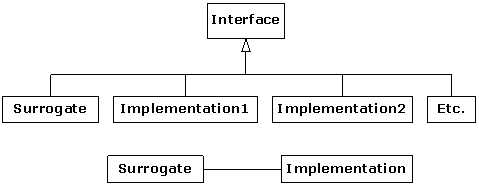
When a surrogate object is created, it is given an
implementation to which it sends the function calls.
Structurally, the difference between Proxy and State is
simple: a Proxy has only one implementation, while State has more than one. The
application of the patterns is considered (in GoF) to be distinct: Proxy
controls access to its implementation, while State changes the implementation
dynamically. However, if you expand your notion of “controlling access to
implementation” then the two seem to be part of a continuum.
3.3.6.1. Proxy: fronting for another object
If we implement Proxy using the above diagram, it looks like
this:
|
In some cases, Implementation doesn't need the same
interface as Proxy—as long as Proxy is somehow “speaking for” the
Implementation class and referring function calls to it, then the basic
idea is satisfied (note that this statement is at odds with the definition for
Proxy in GoF). However, with a common interface you are able to do a drop-in
replacement of the proxy into the client code—the client code is written to
talk to the original object, and it doesn't need to be changed in order to
accept the proxy (This is probably the key issue with Proxy). In addition, Implementation
is forced, through the common interface, to fulfill all the functions that Proxy
needs to call.
The difference between Proxy and State is in the problems
that are solved. The common uses for Proxy as described in GoF are:
- Remote proxy. This proxies for an object in a different address space. This is implemented by some remote object technologies.
- Virtual proxy. This provides “lazy initialization” to create expensive objects on demand.
- Protection proxy. Used when you don't want the client programmer to have full access to the proxied object.
- Smart reference. To add additional actions when the proxied object is accessed. Reference counting is an example: this keeps track of the number of references that are held for a particular object, in order to implement the copy-on-write idiom and prevent object aliasing.(142) A simpler example is counting the calls to a particular function.
3.3.6.2. State: changing object behavior
The State pattern produces an object that appears to change
its class, and is useful when you discover that you have conditional code in
most or all functions. Like Proxy, State is created by having a front-end
object that uses a back-end implementation object to fulfill its duties.
However, the State pattern switches from one implementation to another during
the lifetime of the front-end object, in order to produce different behavior
for the same function call(s). It's a way to improve the implementation of your
code when you seem to be doing a lot of testing inside each of your functions
before deciding what to do for that function. For example, the fairy tale of
the frog-prince contains an object (the creature) that behaves differently
depending on what state it's in. You could implement this by testing a bool:
|
However, the greet( ) function, and any other
functions that must test isFrog before they perform their operations,
end up with awkward code, especially if you find yourself adding additional
states to the system. By delegating the operations to a State object that can
be changed, this code is simplified.
|
It is not necessary to make the implementing classes nested
or private, but if you can it creates cleaner code.
Note that changes to the State classes are automatically
propagated throughout your code, rather than requiring an edit across the
classes in order to effect changes.
3.3.7. Adapter
Adapter takes one type and produces an interface to some
other type. This is useful when you're given a library or piece of code that
has a particular interface, and you've got a second library or piece of code
that uses the same basic ideas as the first piece, but expresses itself
differently. If you adapt the forms of expression to each other, you can
rapidly produce a solution.
Suppose you have a generator class that produces Fibonacci numbers:
|
Since it's a generator, you use it by calling the operator( ),
like this:
|
Perhaps you would like to take this generator and perform
STL numeric algorithm operations with it. Unfortunately, the STL algorithms
only work with iterators, so you have an interface mismatch. The solution is to
create an adapter that will take the FibonacciGenerator and produce an iterator for the STL algorithms to use. Since the numeric algorithms only require an
input iterator, the Adapter is fairly straightforward (for something that
produces an STL iterator, that is):
|
You initialize a FibonacciAdapter by telling it how
long the Fibonacci sequence can be. When an iterator is created, it
simply captures a reference to the containing FibonacciAdapter so that
it can access the FibonacciGenerator and length. Note that the
equivalence comparison ignores the right-hand value because the only important
issue is whether the generator has reached its length. In addition, the operator++( )
doesn't modify the iterator; the only operation that changes the state of the FibonacciAdapter
is calling the generator function operator( ) on the FibonacciGenerator.
We can get away with this extremely simple version of the iterator because the
constraints on an Input Iterator are so strong; in particular, you can only
read each value in the sequence once.
In main( ), you can see that all four different
types of numeric algorithms are successfully tested with the FibonacciAdapter.
3.3.8. Template Method
An application framework allows you to inherit from a class
or set of classes and create a new application, reusing most of the code in the
existing classes and overriding one or more functions in order to customize the
application to your needs. A fundamental concept in the application framework
is the Template Method, which is typically hidden beneath the covers and drives
the application by calling the various functions in the base class (some of
which you have overridden in order to create the application).
An important characteristic of the Template Method is that
it is defined in the base class (sometimes as a private member function) and
cannot be changed—the Template Method is the “thing that stays the same.” It
calls other base-class functions (the ones you override) in order to do its
job, but the client programmer isn't necessarily able to call it directly, as
you can see here:
|
The “engine” that runs the application is the Template
Method. In a GUI application, this “engine” would be the main event loop. The
client programmer simply provides definitions for customize1( ) and
customize2( ) and the “application” is ready to run.
3.3.9. Strategy: choosing the algorithm at runtime
Note that the Template Method is the “code that stays the
same,” and the functions that you override are the “code that changes.”
However, this change is fixed at compile time via inheritance. Following the
maxim of “prefer composition to inheritance,” we can use composition to
approach the problem of separating code that changes from code that stays the
same, and produce the Strategy pattern. This approach has a distinct benefit:
at runtime, you can plug in the code that changes. Strategy also adds a
“Context” which can be a surrogate class that controls the selection and use of
the particular strategy object—just like State!
“Strategy” means just that: you can solve a problem in a number
of ways. Consider the situation where you've forgotten someone's name. Here are
the different ways you can cope:
|
Context::greet( ) would normally be more complex;
it's the analog of the Template Method because it contains the code that
doesn't change. But you can see in main( ) that the choice of
strategy can be made at runtime. If you go one step further you can combine
this with the State pattern and change the Strategy during the lifetime of the Context
object.
3.3.10. Chain of Responsibility: trying a sequence of strategies
Chain of Responsibility might be thought of as a “dynamic
generalization of recursion” using Strategy objects. You make a call, and each Strategy
in a linked sequence tries to satisfy the call. The process ends when one of
the strategies is successful or the chain ends. In recursion, one function calls
itself over and over until a termination condition is reached; with Chain of
Responsibility, a function calls itself, which (by moving down the chain of Strategies)
calls a different implementation of the function, etc., until a termination
condition is reached. The termination condition is either that the bottom of
the chain is reached (this returns a default object; you may or may not be able
to provide a default result so you must be able to determine the success or
failure of the chain) or one of the Strategies is successful.
Instead of calling a single function to satisfy a request,
multiple functions in the chain have a chance to satisfy the request, so it has
the flavor of an expert system. Since the chain is effectively a list, it can
be dynamically created, so you could also think of it as a more general,
dynamically-built switch statement.
In GoF, there's a fair amount of discussion of how to create
the chain of responsibility as a linked list. However, when you look at the
pattern it really shouldn't matter how the chain is created; that's an
implementation detail. Since GoF was written before the STL containers were
available in most C++ compilers, the reason for this is most likely (1) there
was no built-in list and thus they had to create one and (2) data structures
are often taught as a fundamental skill in academia, and the idea that data
structures should be standard tools available with the programming language may
not have occurred to the GoF authors. We maintain that the details of the container
used to implement Chain of Responsibility as a chain (in GoF, a linked list)
adds nothing to the solution and can just as easily be implemented using an STL
container, as shown below.
Here you can see Chain of Responsibility automatically
finding a solution using a mechanism to automatically recurse through each
Strategy in the chain:
|
Notice that the “Context” class Gimme and all the
Strategy classes are all derived from the same base class, GimmeStrategy.
If you study the section on Chain of Responsibility in GoF,
you'll find that the structure differs significantly from the one above because
they focus on creating their own linked list. However, if you keep in mind that
the essence of Chain of Responsibility is to try a number of solutions until
you find one that works, you'll realize that the implementation of the
sequencing mechanism is not an essential part of the pattern.
3.3.11. Factories: encapsulating object creation
When you discover that you need to add new types to a
system, the most sensible first step is to use polymorphism to create a common
interface to those new types. This separates the rest of the code in your
system from the knowledge of the specific types that you are adding. New types
can be added without disturbing existing code … or so it seems. At first it
would appear that you need to change the code only in the place where you inherit
a new type, but this is not quite true. You must still create an object of your
new type, and at the point of creation you must specify the exact constructor
to use. Thus, if the code that creates objects is distributed throughout your
application, you have the same problem when adding new types—you must still
chase down all the points of your code where type matters. It is the creation
of the type that matters here, rather than the use of the type (which is
taken care of by polymorphism), but the effect is the same: adding a new type
can cause problems.
The solution is to force the creation of objects to occur
through a common factory rather than to allow the creational code to be
spread throughout your system. If all the code in your program must go to this
factory whenever it needs to create one of your objects, all you must do when
you add a new object is modify the factory. This design is a variation of the
pattern commonly known as Factory Method. Since every object-oriented program
creates objects, and since it's likely you will extend your program by adding
new types, factories may be the most useful of all design patterns.
As an example, consider the commonly-used Shape
example. One approach to implementing a factory is to define a static
member function in the base class:
|
The factory( ) function takes an argument that
allows it to determine what type of Shape to create. Here, the argument is
a string, but it could be any set of data. The factory( ) is
now the only other code in the system that needs to be changed when a new type
of Shape is added. (The initialization data for the objects will
presumably come from somewhere outside the system and will not be a hard-coded
array as in this example.)
To ensure that the creation can only happen in the factory( ),
the constructors for the specific types of Shape are made private,
and Shape is declared a friend so that factory( ) has
access to the constructors. (You could also declare only Shape::factory( )
to be a friend, but it seems reasonably harmless to declare the entire
base class as a friend.) There is another important implication of this
design—the base class, Shape, must now know the details about every
derived class—a property that object-oriented designs try to avoid. For
frameworks or any class library that should support extension, this can quickly
become unwieldy, as the base class must be updated as soon as a new type is
added to the hierarchy. Polymorphic factories, described in the next
subsection, can be used to avoid this unfortunate circular dependency.
3.3.11.1. Polymorphic factories
The static factory( ) member function in the
previous example forces all the creation operations to be focused in one spot,
so that's the only place you need to change the code. This is certainly a
reasonable solution, as it nicely encapsulates the process of creating objects.
However, GoF emphasizes that the reason for the Factory Method pattern is so
that different types of factories can be derived from the basic factory.
Factory Method is in fact a special type of polymorphic factory. Here is ShapeFactory1.cpp
modified so the Factory Methods are in a separate class as virtual functions:
|
Now the Factory Method appears in its own class, ShapeFactory,
as virtual create( ). This is a private member function, which
means it cannot be called directly but can be overridden. The subclasses of Shape
must each create their own subclasses of ShapeFactory and override the create( )
member function to create an object of their own type. These factories are
private, so that they are only accessible from the main Factory Method. This
way, all client code must go through the Factory Method in order to create
objects.
The actual creation of shapes is performed by calling ShapeFactory::createShape( ),
which is a static member function that uses the map in ShapeFactory
to find the appropriate factory object based on an identifier that you pass it.
The factory creates the shape object directly, but you could imagine a more
complex problem where the appropriate factory object is returned and then used
by the caller to create an object in a more sophisticated way. However, it
seems that much of the time you don't need the intricacies of the polymorphic
Factory Method, and a single static member function in the base class (as shown
in ShapeFactory1.cpp) will work fine.
Notice that the ShapeFactory must be initialized by
loading its map with factory objects, which takes place in the Singleton
ShapeFactoryInitializer. So to add a new type to this design you must
define the type, create a factory, and modify ShapeFactoryInitializer so
that an instance of your factory is inserted in the map. This extra complexity
again suggests the use of a static Factory Method if you don't need to
create individual factory objects.
3.3.11.2. Abstract factories
The Abstract Factory pattern looks like the factories we've
seen previously, but with several Factory Methods. Each of the Factory Methods
creates a different kind of object. When you create the factory object, you
decide how all the objects created by that factory will be used. The example in
GoF implements portability across various graphical user interfaces (GUIs): you
create a factory object appropriate to the GUI that you're working with, and
from then on when you ask it for a menu, a button, a slider, and so on, it will
automatically create the appropriate version of that item for the GUI. Thus,
you're able to isolate, in one place, the effect of changing from one GUI to
another.
As another example, suppose you are creating a
general-purpose gaming environment and you want to be able to support different
types of games. Here's how it might look using an Abstract Factory:
|
In this environment, Player objects interact with Obstacle
objects, but the types of players and obstacles depend on the game. You
determine the kind of game by choosing a particular GameElementFactory,
and then the GameEnvironment controls the setup and play of the game. In
this example, the setup and play are simple, but those activities (the initial
conditions and the state change) can determine much of the game's
outcome. Here, GameEnvironment is not designed to be inherited, although
it could possibly make sense to do that.
This example also illustrates double dispatching,
which will be explained later.
3.3.11.3. Virtual constructors
One of the primary goals of using a factory is to organize your code so you don't need to select the exact constructor type when
creating an object. That is, you can tell a factory: “I don't know precisely
what kind of object I need, but here's the information. Create the appropriate
type.”
In addition, during a constructor call the virtual mechanism
does not operate (early binding occurs). Sometimes this is awkward. For
example, in the Shape program it seems logical that inside the
constructor for a Shape object, you would want to set everything up and
then draw( ) the Shape. The draw( ) function
should be a virtual function, a message to the Shape that it should draw
itself appropriately, depending on whether it is a Circle, a Square,
a Line, and so on. However, this doesn't work inside the constructor
because virtual functions resolve to the “local” function bodies when called in constructors.
If you want to be able to call a virtual function inside the
constructor and have it do the right thing, you must use a technique to simulate
a virtual constructor. This is a conundrum. Remember, the idea of a virtual
function is that you send a message to an object and let the object figure out
the right thing to do. But a constructor builds an object. So a virtual
constructor would be like saying, “I don't know exactly what kind of object you
are, but build the right type anyway.” In an ordinary constructor, the compiler
must know which VTABLE address to bind to the VPTR, and even if it existed, a
virtual constructor couldn't do this because it doesn't know all the type
information at compile time. It makes sense that a constructor can't be virtual
because it is the one function that absolutely must know everything about the
type of the object.
And yet there are times when you want something
approximating the behavior of a virtual constructor.
In the Shape example, it would be nice to hand the Shape
constructor some specific information in the argument list and let the
constructor create a specific type of Shape (a Circle or a Square)
with no further intervention. Ordinarily, you'd have to make an explicit call
to the Circle or Square constructor yourself.
Coplien(143) calls
his solution to this problem “envelope and letter classes.” The “envelope” class is the base class, a shell that contains a pointer to an object,
also of the base class type. The constructor for the “envelope” determines (at
runtime, when the constructor is called, not at compile time, when the type
checking is normally done) what specific type to make, creates an object of
that specific type (on the heap), and then assigns the object to its pointer.
All the function calls are then handled by the base class through its pointer.
It's really just a slight variation of the State pattern, where the base class
is acting as a surrogate for the derived class, and the derived class provides
the variation in behavior:
|
The base class Shape contains a pointer to an object
of type Shape as its only data member. (When you create a “virtual
constructor” scheme, exercise special care to ensure this pointer is always
initialized to a live object.) This base class is effectively a proxy because
it is the only thing the client code sees and interacts with.
Each time you derive a new subtype from Shape, you
must go back and add the creation for that type in one place, inside the
“virtual constructor” in the Shape base class. This is not too onerous a
task, but the disadvantage is you now have a dependency between the Shape
class and all classes derived from it.
In this example, the information you must hand the virtual
constructor about what type to create is explicit: it's a string that
names the type. However, your scheme can use other information—for example, in
a parser the output of the scanner can be handed to the virtual constructor,
which then uses that information to determine which token to create.
The virtual constructor Shape(type) cannot be defined
until after all the derived classes have been declared. However, the default
constructor can be defined inside class Shape, but it should be made protected
so temporary Shape objects cannot be created. This default constructor
is only called by the constructors of derived-class objects. You are forced to
explicitly create a default constructor because the compiler will create one
for you automatically only if there are no constructors defined. Because
you must define Shape(type), you must also define Shape( ).
The default constructor in this scheme has at least one
important chore—it must set the value of the s pointer to zero. This may
sound strange at first, but remember that the default constructor will be
called as part of the construction of the actual object—in Coplien's
terms, the “letter,” not the “envelope.” However, the “letter” is derived from
the “envelope,” so it also inherits the data member s. In the
“envelope,” s is important because it points to the actual object, but
in the “letter,” s is simply excess baggage. Even excess baggage should
be initialized, however, and if s is not set to zero by the default
constructor called for the “letter,” bad things happen (as you'll see later).
The virtual constructor takes as its argument information
that completely determines the type of the object. Notice, though, that this
type information isn't read and acted upon until runtime, whereas normally the
compiler must know the exact type at compile time (one other reason this system
effectively imitates virtual constructors).
The virtual constructor uses its argument to select the
actual (“letter”) object to construct, which is then assigned to the pointer
inside the “envelope.” At that point, the construction of the “letter” has been
completed, so any virtual calls will be properly redirected.
As an example, consider the call to draw( )
inside the virtual constructor. If you trace this call (either by hand or with
a debugger), you can see that it starts in the draw( ) function in
the base class, Shape. This function calls draw( ) for the
“envelope” s pointer to its “letter.” All types derived from Shape
share the same interface, so this virtual call is properly executed, even
though it seems to be in the constructor. (Actually, the constructor for the
“letter” has already completed.) As long as all virtual calls in the base class
simply make calls to identical virtual functions through the pointer to the
“letter,” the system operates properly.
To understand how it works, consider the code in main( ).
To fill the vector shapes, “virtual constructor” calls are made to Shape.
Ordinarily in a situation like this, you would call the constructor for the
actual type, and the VPTR for that type would be installed in the object. Here,
however, the VPTR used in each case is the one for Shape, not the one
for the specific Circle, Square, or Triangle.
In the for loop where the draw( ) and erase( )
functions are called for each Shape, the virtual function call
resolves, through the VPTR, to the corresponding type. However, this is Shape
in each case. In fact, you might wonder why draw( ) and erase( )
were made virtual. The reason shows up in the next step: the
base-class version of draw( ) makes a call, through the “letter”
pointer s, to the virtual function draw( ) for the
“letter.” This time the call resolves to the actual type of the object, not
just the base class Shape. Thus, the runtime cost of using virtual
constructors is one extra virtual indirection every time you make a virtual
function call.
To create any function that is overridden, such as draw( ),
erase( ), or test( ), you must forward all calls to the
s pointer in the base class implementation, as shown earlier. This is
because, when the call is made, the call to the envelope's member function will
resolve as being to Shape, and not to a derived type of Shape.
Only when you forward the call to s will the virtual behavior take
place. In main( ), you can see that everything works correctly,
even when calls are made inside constructors and destructors.
Destructor operation
The activities of destruction in this scheme are also
tricky. To understand, let's verbally walk through what happens when you call delete
for a pointer to a Shape object—specifically, a Square—created on
the heap. (This is more complicated than an object created on the stack.) This
will be a delete through the polymorphic interface, and will happen via
the call to purge( ).
The type of any pointer in shapes is of the base
class Shape, so the compiler makes the call through Shape. Normally,
you might say that it's a virtual call, so Square's destructor will be
called. But with the virtual constructor scheme, the compiler is creating
actual Shape objects, even though the constructor initializes the letter
pointer to a specific type of Shape. The virtual mechanism is
used, but the VPTR inside the Shape object is Shape's VPTR, not Square's.
This resolves to Shape's destructor, which calls delete for the
letter pointer s, which actually points to a Square object. This
is again a virtual call, but this time it resolves to Square's
destructor.
C++ guarantees, via the compiler, that all destructors in
the hierarchy are called. Square's destructor is called first, followed
by any intermediate destructors, in order, until finally the base-class destructor
is called. This base-class destructor contains code that says delete s.
When this destructor was called originally, it was for the “envelope” s,
but now it's for the “letter” s, which is there because the “letter” was
inherited from the “envelope,” and not because it contains anything. So this
call to delete should do nothing.
The solution to the problem is to make the “letter” s
pointer zero. Then when the “letter” base-class destructor is called, you get delete
0, which by definition does nothing. Because the default constructor is
protected, it will be called only during the construction of a “letter,”
so that's the only situation where s is set to zero.
Although it's interesting, you can see this is a complex
approach, and the most common tool for hiding construction will generally be
ordinary Factory Methods rather than something like this “virtual constructor”
scheme.
3.3.12. Builder: creating complex objects
The goal of Builder (which is a Creational pattern, like the
Factories we've just looked at) is to separate the construction of an object
from its “representation.” This means that the construction process stays the
same, but the resulting object has different possible representations. GoF
points out that the main difference between Builder and Abstract Factory is
that a Builder creates the object step-by-step, so the fact that the creation
process is spread out in time seems to be important. In addition, the
“director” gets a stream of pieces that it passes to the Builder, and each
piece is used to perform one of the steps in the build process.
The following example models a bicycle that can have a
choice of parts, according to its type (mountain bike, touring bike, or racing
bike). A Builder class is associated with each type of bicycle, and each Builder
implements the interface specified in the abstract class BicycleBuilder.
A separate class, BicycleTechnician, represents the “director” object
described in GoF, and uses a concrete BicycleBuilder object to construct
a Bicycle object.
|
A Bicycle holds a vector of pointers to BicyclePart,
representing the parts used to construct the bicycle. To initiate the construction
of a bicycle, a BicycleTechnician (the “director” in this example) calls
BicycleBuilder::createproduct( ) on a derived BicycleBuilder
object. The BicycleTechnician::construct( ) function calls all the
functions in the BicycleBuilder interface (since it doesn't know what
type of concrete builder it has). The concrete builder classes omit (via empty
function bodies) those actions that do not apply to the type of bicycle they
build, as you can see in the following implementation file:
|
The Bicycle stream inserter calls the corresponding
inserter for each BicyclePart, and that prints its type name so that you
can see what a Bicycle contains. Here is a sample program:
|
The power of this pattern is that it separates the algorithm
for assembling parts into a complete product from the parts themselves and
allows different algorithms for different products via different implementations
of a common interface.
3.3.13. Observer
The Observer pattern solves a fairly common problem: what if
a group of objects needs to update themselves when some other object changes
state? This can be seen in the “model-view” aspect of Smalltalk's MVC (model-view-controller) or the almost-equivalent “Document-View Architecture.” Suppose that you have some data (the “document”) and two views: a plot view
and a textual view. When you change the data, the views must be told to update
themselves, and that's what the observer facilitates.
Two types of objects are used to implement the observer
pattern in the following code. The Observable class keeps track of the
objects that want to be informed when a change happens. The Observable
class calls the notifyObservers( ) member function for each
observer on the list. The notifyObservers( ) member function is
part of the base class Observable.
There are two “things that change” in the observer
pattern: the quantity of observing objects and the way an update occurs. That
is, the observer pattern allows you to modify both of these without affecting
the surrounding code.
You can implement the observer pattern in a number of ways,
but the code shown here will create a framework from which you can build your
own observer code, by following the example. First, this interface describes
what an observer looks like:
|
Since Observer interacts with Observable in
this approach, Observable must be declared first. In addition, the Argument
class is empty and only acts as a base class for any type of argument you want
to pass during an update. If you want, you can simply pass the extra argument
as a void*. You'll have to downcast in either case.
The Observer type is an “interface” class that only
has one member function, update( ). This function is called by the
object that's being observed, when that object decides it's time to update all
its observers. The arguments are optional; you could have an update( )
with no arguments, and that would still fit the observer pattern. However this
is more general—it allows the observed object to pass the object that caused
the update (since an Observer may be registered with more than one
observed object) and any extra information if that's helpful, rather than
forcing the Observer object to hunt around to see who is updating and to
fetch any other information it needs.
The “observed object” will be of type Observable:
|
Again, the design here is more elaborate than is necessary. As
long as there's a way to register an Observer with an Observable
and a way for the Observable to update its Observers, the set of
member functions doesn't matter. However, this design is intended to be
reusable. (It was lifted from the design used in the Java standard library.)(144)
The Observable object has a flag to indicate whether
it's been changed. In a simpler design, there would be no flag; if something
happened, everyone would be notified. Notice, however, that the control of the
flag's state is protected so that only an inheritor can decide what
constitutes a change, and not the end user of the resulting derived Observer
class.
The collection of Observer objects is kept in a set<Observer*>
to prevent duplicates; the set insert( ), erase( ), clear( ),
and size( ) functions are exposed to allow Observers to be
added and removed at any time, thus providing runtime flexibility.
Most of the work is done in notifyObservers( ).
If the changed flag has not been set, this does nothing. Otherwise, it
first clears the changed flag so that repeated calls to notifyObservers( )
won't waste time. This is done before notifying the observers in case the calls
to update( ) do anything that causes a change back to this Observable
object. It then moves through the set and calls back to the update( )
member function of each Observer.
At first it may appear that you can use an ordinary Observable
object to manage the updates. But this doesn't work; to get any effect, you must
derive from Observable and somewhere in your derived-class code call setChanged( ).
This is the member function that sets the “changed” flag, which means that when
you call notifyObservers( ) all the observers will, in fact, get
notified. Where you call setChanged( ) depends on the logic
of your program.
Now we encounter a dilemma. Objects that are being observed
may have more than one such item of interest. For example, if you're dealing
with a GUI item—a button, say—the items of interest might be the mouse clicked
the button, the mouse moved over the button, and (for some reason) the button
changed its color. So we'd like to be able to report all these events to
different observers, each of which is interested in a different type of event.
The problem is that we would normally reach for multiple
inheritance in such a situation: “I'll inherit from Observable to deal
with mouse clicks, and I'll … er … inherit from Observable to deal with
mouse-overs, and, well, … hmm, that doesn't work.”
3.3.13.1. The “inner class” idiom
Here's a situation where we must (in effect) upcast to more
than one type, but in this case we need to provide several different
implementations of the same base type. The solution is something we've lifted
from Java, which takes C++'s nested class one step further. Java has a built-in
feature called an inner class, which is like a nested class in C++, but
it has access to the nonstatic data of its containing class by implicitly using
the “this” pointer of the class object it was created within.(145)
To implement the inner class idiom in C++, we must obtain
and use a pointer to the containing object explicitly. Here's an example:
|
The example (intended to show the simplest syntax for the
idiom; you'll see a real use shortly) begins with the Poingable and Bingable
interfaces, each containing a single member function. The services provided
by callPoing( ) and callBing( ) require that the object
they receive implements the Poingable and Bingable interfaces,
respectively, but they put no other requirements on that object so as to
maximize the flexibility of using callPoing( ) and callBing( ).
Note the lack of virtual destructors in either interface—the intent is
that you never perform object destruction via the interface.
The Outer constructor contains some private data (name),
and it wants to provide both a Poingable interface and a Bingable interface
so it can be used with callPoing( ) and callBing( ). (In
this situation we could simply use multiple inheritance, but it is kept simple for clarity.) To provide a Poingable object without deriving Outer
from Poingable, the inner class idiom is used. First, the declaration class
Inner says that, somewhere, there is a nested class of this name. This
allows the friend declaration for the class, which follows. Finally, now
that the nested class has been granted access to all the private elements of Outer,
the class can be defined. Notice that it keeps a pointer to the Outer
which created it, and this pointer must be initialized in the constructor.
Finally, the poing( ) function from Poingable is
implemented. The same process occurs for the second inner class which
implements Bingable. Each inner class has a single private
instance created, which is initialized in the Outer constructor. By
creating the member objects and returning references to them, issues of object
lifetime are eliminated.
Notice that both inner class definitions are private,
and in fact the client code doesn't have any access to details of the
implementation, since the two access functions operator Poingable&( )
and operator Bingable&( ) only return a reference to the upcast
interface, not to the object that implements it. In fact, since the two inner
classes are private, the client code cannot even downcast to the
implementation classes, thus providing complete isolation between interface and
implementation.
We've taken the extra liberty here of defining the automatic
type conversion functions operator Poingable&( ) and operator
Bingable&( ). In main( ), you can see that these allow
a syntax that looks as if Outer multiply inherits from Poingable
and Bingable. The difference is that the “casts” in this case are one-way.
You can get the effect of an upcast to Poingable or Bingable, but
you cannot downcast back to an Outer. In the following example of observer,
you'll see the more typical approach: you provide access to the inner class
objects using ordinary member functions, not automatic type conversion
functions.
3.3.13.2. The observer example
Armed with the Observer and Observable header
files and the inner class idiom, we can look at an example of the Observer
pattern:
|
The events of interest are that a Flower can open or
close. Because of the use of the inner class idiom, both these events can be
separately observable phenomena. The OpenNotifier and CloseNotifier
classes both derive from Observable, so they have access to setChanged( )
and can be handed to anything that needs an Observable. You'll notice
that, contrary to InnerClassIdiom.cpp, the Observable descendants
are public. This is because some of their member functions must be
available to the client programmer. There's nothing that says that an inner
class must be private; in InnerClassIdiom.cpp we were simply
following the design guideline “make things as private as possible.” You could
make the classes private and expose the appropriate member functions by
proxy in Flower, but it wouldn't gain much.
The inner class idiom also comes in handy to define more
than one kind of Observer in Bee and Hummingbird, since
both those classes may want to independently observe Flower openings and
closings. Notice how the inner class idiom provides something that has most of
the benefits of inheritance (the ability to access the private data in the
outer class, for example).
In main( ), you can see one of the primary
benefits of the Observer pattern: the ability to change behavior at runtime by
dynamically registering and unregistering Observers with Observables.
This flexibility is achieved at the cost of significant additional code—you
will often see this kind of tradeoff in design patterns: more complexity in one
place in exchange for increased flexibility and/or lowered complexity in
another place.
If you study the previous example, you'll see that OpenNotifier
and CloseNotifier use the basic Observable interface. This
means that you could derive from other completely different Observer
classes; the only connection the Observers have with Flowers is
the Observer interface.
Another way to accomplish this fine granularity of
observable phenomena is to use some form of tags for the phenomena, for example
empty classes, strings, or enumerations that denote different types of
observable behavior. This approach can be implemented using aggregation rather
than inheritance, and the differences are mainly tradeoffs between time and
space efficiency. For the client, the differences are negligible.
3.3.14. Multiple dispatching
When dealing with multiple interacting types, a program can
get particularly messy. For example, consider a system that parses and executes
mathematical expressions. You want to be able to say Number + Number, Number
* Number, and so on, where Number is the base class for a family of
numerical objects. But when you say a + b, and you don't know the exact
type of either a or b, how can you get them to interact properly?
The answer starts with something you probably don't think
about: C++ performs only single dispatching. That is, if you are performing an
operation on more than one object whose type is unknown, C++ can invoke the
dynamic binding mechanism on only one of those types. This doesn't solve the
problem described here, so you end up detecting some types manually and
effectively producing your own dynamic binding behavior.
The solution is called multiple dispatching (described in GoF in the context of the Visitor pattern, shown in the next section). Here,
there will be only two dispatches, which is referred to as double dispatching. Remember that polymorphism can occur only via virtual function calls,
so if you want multiple dispatching to occur, there must be a virtual function
call to determine each unknown type. Thus, if you are working with two
different type hierarchies that are interacting, you'll need a virtual call in
each hierarchy. Generally, you'll set up a configuration such that a single
member function call generates more than one virtual member function call and
thus determines more than one type in the process: you'll need a virtual
function call for each dispatch. The virtual functions in the following example
are called compete( ) and eval( ) and are both members
of the same type (this is not a requirement for multiple dispatching):(146)
|
Outcome categorizes the different possible results of
a compete( ), and the operator<< simplifies the
process of displaying a particular Outcome.
Item is the base class for the types that will be
multiply-dispatched. Compete::operator( ) takes two Item*
(the exact type of both are unknown) and begins the double-dispatching process
by calling the virtual Item::compete( ) function. The virtual
mechanism determines the type a, so it wakes up inside the compete( )
function of a's concrete type. The compete( ) function
performs the second dispatch by calling eval( ) on the remaining
type. Passing itself (this) as an argument to eval( ) produces
a call to the overloaded eval( ) function, thus preserving the type
information of the first dispatch. When the second dispatch is completed, you
know the exact types of both Item objects.
In main( ),the STL algorithm generate( )
populates the vector v, then transform( ) applies Compete::operator( )
to the two ranges. This version of transform( ) takes the start and
end point of the first range (containing the left-hand Items used in the
double dispatch); the starting point of the second range, which holds the
right-hand Items; the destination iterator, which in this case is
standard output; and the function object (a temporary of type Compete)to call for each object.
It requires a lot of ceremony to set up multiple
dispatching, but keep in mind that the benefit is the syntactic elegance
achieved when making the call—instead of writing awkward code to determine the
type of one or more objects during a call, you simply say: “You two! I don't
care what types you are, interact properly with each other!” Make sure this
kind of elegance is important to you before embarking on multiple dispatching,
however.
Note that multiple dispatching is, in effect, performing a
table lookup. Here, the lookup is performed using virtual functions, but you
could instead perform a literal table lookup. With more than a few dispatches
(and if you are prone to making additions and changes), a table lookup may be a
better solution to the problem.
3.3.14.1. Multiple dispatching with Visitor
The goal of Visitor (the final, and arguably most complex,
pattern in GoF) is to separate the operations on a class hierarchy from the
hierarchy itself. This is quite an odd motivation because most of what we do in
object-oriented programming is to combine data and operations into objects, and
to use polymorphism to automatically select the correct variation of an
operation, depending on the exact type of an object.
With Visitor you extract the operations from inside your
class hierarchy into a separate, external hierarchy. The “main” hierarchy then
contains a visit( ) function that accepts any object from your
hierarchy of operations. As a result, you get two class hierarchies instead of
one. In addition, you'll see that your “main” hierarchy becomes very brittle—if
you add a new class, you will force changes throughout the second hierarchy. GoF
says that the main hierarchy should thus “rarely change.” This constraint is
very limiting, and it further reduces the applicability of this pattern.
For the sake of argument, then, assume that you have a
primary class hierarchy that is fixed; perhaps it's from another vendor and you
can't make changes to that hierarchy. If you had the source code for the
library, you could add new virtual functions in the base class, but this is,
for some reason, not feasible. A more likely scenario is that adding new
virtual functions is somehow awkward, ugly or otherwise difficult to maintain. GoF
argues that “distributing all these operations across the various node classes
leads to a system that's hard to understand, maintain, and change.” (As you'll
see, Visitor can be much harder to understand, maintain and change.) Another
GoF argument is that you want to avoid “polluting” the interface of the main
hierarchy with too many operations (but if your interface is too “fat,” you
might ask whether the object is trying to do too many things).
The library creator must have foreseen, however, that you
will want to add new operations to that hierarchy, so that they can know to include
the visit( ) function.
So (assuming you really need to do this) the dilemma is that
you need to add member functions to the base class, but for some reason you
can't touch the base class. How do you get around this?
Visitor builds on the double-dispatching scheme shown in the
previous section. The Visitor pattern allows you to effectively extend the
interface of the primary type by creating a separate class hierarchy of type Visitor
to “virtualize” the operations performed on the primary type. The objects
of the primary type simply “accept” the visitor and then call the visitor's
dynamically bound member function. Thus, you create a visitor, pass it into the
primary hierarchy, and you get the effect of a virtual function. Here's a
simple example:
|
Flower is the primary hierarchy, and each subtype of Flower
can accept( ) a Visitor. The Flower hierarchy has no
operations other than accept( ), so all the functionality of the Flower
hierarchy is contained in the Visitor hierarchy. Note that the Visitor
classes must know about all the specific types of Flower, and if you add
a new type of Flower the entire Visitor hierarchy must be
reworked.
The accept( ) function in each Flower
begins a double dispatch as described in the previous section. The first
dispatch determines the exact type of Flower and the second determines
the exact type of Visitor. Once you know the exact types you can perform
an operation appropriate to both.
It's very unlikely that you'll use Visitor because its
motivation is unusual and its constraints are stultifying. The GoF examples are
not convincing—the first is a compiler (not many people write compilers, and it
seems quite rare that Visitor is used within these compilers), and they
apologize for the other examples, saying you wouldn't actually use Visitor for
anything like this. You would need a stronger compulsion than that presented in
GoF to abandon an ordinary OO structure for Visitor—what benefit does it really
buy you in exchange for much greater complexity and constraint? Why can't you
simply add more virtual functions in the base class when you discover you need
them? Or, if you really need to paste new functions into an existing hierarchy
and you are unable to modify that hierarchy, why not try multiple inheritance
first? (Even then, the likelihood of “saving” the existing hierarchy this way
is slim). Consider also that, to use Visitor, the existing hierarchy must
incorporate a visit( ) function from the beginning, because to add
it later would mean that you had permission to modify the hierarchy, so you
could just add ordinary virtual functions as you need them. No, Visitor must be
part of the architecture from the beginning, and to use it requires a
motivation greater than that in GoF.(147)
We present Visitor here because we have seen it used when it
shouldn't be, just as multiple inheritance and any number of other approaches
have been used inappropriately. If you find yourself using Visitor, ask why.
Are you really unable to add new virtual functions in the base class? Do
you really want to be restricted from adding new types in your primary
hierarchy?
3.3.15. Summary
The point of design patterns, like the point of any
abstraction, is to make your life easier. Usually something in your system is
changing—this could be code during the lifetime of the project, or objects
during the lifetime of one program execution. Discover what is changing, and a
design pattern may help you encapsulate that change, and thus bring it under
control.
It's easy to get infatuated with a particular design, and to
create trouble for yourself by applying it just because you know how. What's
hard, ironically, is to follow the XP maxim of “do the simplest thing that
could possibly work.” But by doing the simplest thing, you not only get a
design that's faster to implement, but also easier to maintain. And if the
simplest thing doesn't do the job, you'll find out a lot sooner than if you
spend the time implementing something complex, and then find out that
doesn't work.
3.3.16. Exercises
Solutions
to selected exercises can be found in the electronic document The Thinking
in C++ Volume 2 Annotated Solution Guide, available for a small fee from www.MindView.net.
- Create a variation of SingletonPattern.cpp where all functions are static. Is the instance( ) function still necessary in this case?
- Starting with SingletonPattern.cpp, create a class that provides a connection to a service that stores and retrieves data from a configuration file.
- Using SingletonPattern.cpp as a starting point, create a class that manages a fixed number of its own objects. Assume the objects are database connections and you only have a license to use a fixed quantity of these at any one time.
- Modify KissingPrincess2.cpp by adding another state to the system, so that each kiss cycles the creature to the next state.
- Find C16:TStack.h from Thinking in C++, Volume 1, 2nd Edition (downloadable from www. BruceEckel.com). Create an Adapter for this class such that you can apply the STL algorithm for_each( ) to the elements of the TStack, using your adapter. Create a TStack of string, fill it with strings and use for_each( ) to count all the letters in all the strings in the TStack.
- Create a framework (that is, use the Template Method pattern)
that takes a list of file names on the command line. It opens each file except
the last for reading, and the last file it opens for writing. The framework
will process each input file using an undetermined policy and write the output
to the last file. Inherit to customize this framework to create two separate
applications:
1) Converts all the letters in each file to uppercase.
2) Searches the files for words given in the first file. - Modify Exercise 6 to use Strategy instead of Template Method.
- Modify Strategy.cpp to include State behavior, so that the Strategy can be changed during the lifetime of the Context object.
- Modify Strategy.cpp to use a Chain of Responsibility approach, where you keep trying different ways to get someone to say their name without admitting you've forgotten it.
- Add a class Triangle to ShapeFactory1.cpp.
- Add a class Triangle to ShapeFactory2.cpp.
- Add a new type of GameEnvironment called GnomesAndFairies to AbstractFactory.cpp.
- Modify ShapeFactory2.cpp so that it uses an Abstract Factory to create different sets of shapes (for example, one particular type of factory object creates “thick shapes,” another creates “thin shapes,” but each factory object can create all the shapes: circles, squares, triangles, and so on).
- Modify VirtualConstructor.cpp to use a map instead of if-else statements inside Shape::Shape(string type).
- Break a text file up into an input stream of words (keep it simple: just break the input stream on white space). Create one Builder that puts the words into a set, and another that produces a map containing words and occurrences of those words (that is, it does a word count).
- Create a minimal Observer-Observable design in two classes, without base classes and without the extra arguments in Observer.h and the member functions in Observable.h. Just create the bare minimum in the two classes, and then demonstrate your design by creating one Observable and many Observers and cause the Observable to update the Observers.
- Change InnerClassIdiom.cpp so that Outer uses multiple inheritance instead of the inner class idiom.
- Modify PaperScissorsRock.java to replace the double
dispatch with a table lookup. The easiest way to do this is to create a map of
maps, with the key of each map the typeid(obj).name( )
information of each object. Then you can do the lookup by saying: map[typeid(obj1).name( )][typeid(obj2).name( )].
Notice how much easier it is to reconfigure the system. When is it more appropriate to use this approach vs. hard-coding the dynamic dispatches? Can you create a system that has the syntactic simplicity of use of the dynamic dispatch but uses a table lookup? - Create a business-modeling environment with three types of Inhabitant: Dwarf (for engineers), Elf (for marketers), and Troll (for managers). Now create a class called Project that instantiates the different inhabitants and causes them to interact( ) with each other using multiple dispatching.
- Modify the previous exercise to make the interactions more detailed. Each Inhabitant can randomly produce a Weapon using getWeapon( ): a Dwarf uses Jargon or Play, an Elf uses InventFeature or SellImaginaryProduct, and a Troll uses Edict and Schedule. You decide which weapons “win” and “lose” in each interaction (as in PaperScissorsRock.cpp). Add a battle( ) member function to Project that takes two Inhabitants and matches them against each other. Now create a meeting( ) member function for Project that creates groups of Dwarf, Elf, and Manager and battles the groups against each other until only members of one group are left standing. These are the “winners.”
- Add a Hummingbird Visitor to BeeAndFlowers.cpp.
- Add a Sunflower type to BeeAndFlowers.cpp and notice what you need to change to accommodate this new type.
- Modify BeeAndFlowers.cpp so that it does not use Visitor, but “reverts” to a regular class hierarchy instead. Turn Bee into a collecting parameter.
| (133) | Conveniently, the examples are in C++; unfortunately, the dialect is pre–Standard C++ which suffers from the lack of more modern language features like STL containers. |
| (134) | Much of this material was derived from Thinking in Patterns: Problem–Solving Techniques using Java, available at www.MindView.net. |
| (135) | For up–to–date information, visit http://hillside.net/patterns. |
| (136) | Bill Venners' name for it; you may see it named differently elsewhere. |
| (137) | The C++ Standard states: “No translation unit shall contain more than one definition of any variable, function, class type, enumeration type or template… Every program shall contain exactly one definition of every non–inline function or object that is used in that program.” |
| (138) | This is known as Meyers' Singleton, after its creator, Scott Meyers. |
| (139) | Andrei Alexandrescu develops a superior, policy–based solution to implementing the Singleton pattern in Modern C++ Design. |
| (140) | For more information, see the article “Once is Not Enough” by Hyslop and Sutter in the March 2003 issue of CUJ. |
| (141) | Page 235. |
| (142) | See Thinking in C++, Volume 1 for more details about reference counting. |
| (143) | James O. Coplien, Advanced C++ Programming Styles and Idioms, Addison Wesley, 1992. |
| (144) | It differs from Java in that java.util.Observable.notifyObservers( ) doesn't call clearChanged( ) until after notifying all the observers |
| (145) | There is some similarity between inner classes and subroutine closures, which save the reference environment of a function call so it can be reproduced later. |
| (146) | This example existed for a number of years in both C++ and Java on www.MindView.net before it appeared, without attribution, in a recent book by other authors. |
| (147) | The motivation for including Visitor in GoF was probably excessive cleverness. At a workshop, one of the GoF authors told one of us that “Visitor was his favorite pattern.” |