Thinking in C++ - Volume 2
Thinking in C++ - Volume 2
Date de publication : 25/01/2007 , Date de mise à jour : 25/01/2007
3.2. Multiple Inheritance
3.2.1. Perspective
3.2.2. Interface inheritance
3.2.3. Implementation inheritance
3.2.4. Duplicate subobjects
3.2.5. Virtual base classes
3.2.6. Name lookup issues
3.2.7. Avoiding MI
3.2.8. Extending an interface
3.2.9. Summary
3.2. Multiple Inheritance
The basic concept of multiple
inheritance (MI) sounds simple enough: you create a new type by inheriting from
more than one base class. The syntax is exactly what you'd expect, and as long
as the inheritance diagrams are simple, MI can be simple as well.
However, MI can introduce a number of ambiguities and
strange situations, which are covered in this chapter. But first, it is helpful
to get some perspective on the subject.
3.2.1. Perspective
Before C++, the most successful object-oriented language was
Smalltalk. Smalltalk was created from the ground up as an object-oriented
language. It is often referred to as pure, whereas C++ is called a hybrid
language because it supports multiple programming paradigms, not just the object-oriented paradigm. One of the design decisions made with Smalltalk was that all
classes would be derived in a single hierarchy, rooted in a single base class
(called Object—this is the model for the object-based hierarchy).(120) You cannot
create a new class in Smalltalk without deriving it from an existing class,
which is why it takes a certain amount of time to become productive in
Smalltalk: you must learn the class library before you can start making new
classes. The Smalltalk class hierarchy is therefore a single monolithic tree.
Classes in Smalltalk usually have a number of things in
common, and they always have some things in common (the characteristics
and behaviors of Object), so you don't often run into a situation where
you need to inherit from more than one base class. However, with C++ you can create as many distinct inheritance trees as you want. So for logical completeness the language
must be able to combine more than one class at a time—thus the need for multiple
inheritance.
It was not obvious, however, that programmers required
multiple inheritance, and there was (and still is) a lot of disagreement about
whether it is essential in C++. MI was added in AT&T cfront release 2.0 in 1989 and was the first significant change to the language over
version 1.0.(121) Since
then, a number of other features have been added to Standard C++ (notably
templates) that change the way we think about programming and place MI in a
much less important role. You can think of MI as a “minor” language feature
that is seldom involved in your daily design decisions.
One of the most pressing arguments for MI involved
containers. Suppose you want to create a container that everyone can easily
use. One approach is to use void* as the type inside the container. The
Smalltalk approach, however, is to make a container that holds Objects,
since Object is the base type of the Smalltalk hierarchy. Because
everything in Smalltalk is ultimately derived from Object, a container
that holds Objects can hold anything.
Now consider the situation in C++. Suppose vendor A
creates an object-based hierarchy that includes a useful set of containers
including one you want to use called Holder. Next you come across vendor
B's class hierarchy that contains some other class that is important to
you, a BitImage class, for example, that holds graphic images. The only
way to make a Holder of BitImages is to derive a new class from
both Object, so it can be held in the Holder, and BitImage:
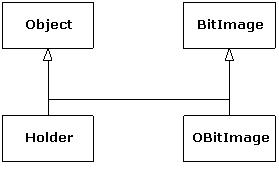
This was seen as an important reason for MI, and a number of
class libraries were built on this model. However, as you saw in Chapter 5, the
addition of templates has changed the way containers are created, so this
situation is no longer a driving issue for MI.
The other reason you may need MI is related to design. You
can intentionally use MI to make a design more flexible or useful (or at least
seemingly so). An example of this is in the original iostream library
design (which still persists in today's template design, as you saw in Chapter
4):
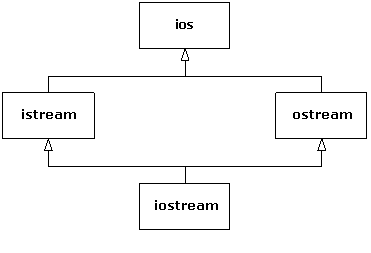
Both istream and ostream are useful classes by
themselves, but they can also be derived from simultaneously by a class that
combines both their characteristics and behaviors. The class ios
provides what is common to all stream classes, and so in this case MI is a
code-factoring mechanism.
Regardless of what motivates you to use MI, it's harder to
use than it might appear.
3.2.2. Interface inheritance
One use of multiple inheritance that is not controversial
pertains to interface inheritance. In C++, all inheritance is implementation
inheritance, because everything in a base class, interface and
implementation, becomes part of a derived class. It is not possible to inherit
only part of a class (the interface alone, say). As Chapter 14 of Volume 1
explains, private and protected inheritance make it possible to restrict access
to members inherited from base classes when used by clients of a derived class
object, but this doesn't affect the derived class; it still contains all base
class data and can access all non-private base class members.
Interface inheritance, on the other hand, only adds member
function declarations to a derived class interface and is not directly
supported in C++. The usual technique to simulate interface inheritance in C++
is to derive from an interface class, which is a class that contains
only declarations (no data or function bodies). These declarations will be pure
virtual functions, except for the destructor. Here is an example:
|
The class Able “implements” the interfaces Printable,
Intable, and Stringable because it provides implementations for
the functions they declare. Because Able derives from all three classes,
Able objects have multiple “is-a” relationships. For example, the object
a can act as a Printable object because its class, Able,
derives publicly from Printable and provides an implementation for print( ).
The test functions have no need to know the most-derived type of their
parameter; they just need an object that is substitutable for their parameter's
type.
As usual, a template solution is more compact:
|
The names Printable, Intable, and Stringable
are now just template parameters that assume the existence of the operations
indicated in their respective contexts. In other words, the test functions can
accept arguments of any type that provides a member function definition with
the correct signature and return type; deriving from a common base class in not
necessary. Some people are more comfortable with the first version because the
type names guarantee by inheritance that the expected interfaces are
implemented. Others are content with the fact that if the operations required
by the test functions are not satisfied by their template type arguments, the
error is still caught at compile time. The latter approach is technically a
“weaker” form of type checking than the former (inheritance) approach, but the
effect on the programmer (and the program) is the same. This is one form of weak typing that is acceptable to many of today's C++ programmers.
3.2.3. Implementation inheritance
As we stated earlier, C++ provides only implementation
inheritance, meaning that you always inherit everything from your base
classes. This can be good because it frees you from having to implement everything
in the derived class, as we had to do with the interface inheritance examples
earlier. A common use of multiple inheritance involves using mixin classes, which are classes that exist to add capabilities to other classes through
inheritance. Mixin classes are not intended to be instantiated by themselves.
As an example, suppose we are clients of a class that
supports access to a database. In this scenario, you only have a header file
available—part of the point here is that you don't have access to the source
code for the implementation. For illustration, assume the following
implementation of a Database class:
|
We're leaving out actual database functionality (storing,
retrieving, and so on), but that's not important here. Using this class
requires a database connection string and that you call Database::open( )
to connect and Database::close( ) to disconnect:
|
In a typical client-server situation, a client will have
multiple objects sharing a connection to a database. It is important that the
database eventually be closed, but only after access to it is no longer
required. It is common to encapsulate this behavior through a class that tracks
the number of client entities using the database connection and to
automatically terminate the connection when that count goes to zero. To add
reference counting to the Database class, we use multiple inheritance to
mix a class named Countable into the Database class to create a
new class, DBConnection. Here's the Countable mixin class:
|
It is evident that this is not a standalone class because
its constructor is protected; it requires a friend or a derived class to
use it. It is important that the destructor is virtual, because it is called
only from the delete this statement in detach( ), and we
want derived objects to be properly destroyed.(122)
The DBConnection class inherits both Database
and Countable and provides a static create( ) function that
initializes its Countable subobject. This is an example of the Factory
Method design pattern, discussed in the next chapter:
|
We now have a reference-counted database connection without
modifying the Database class, and we can safely assume that it will not
be surreptitiously terminated. The opening and closing is done using the Resource Acquisition Is Initialization (RAII) idiom mentioned in Chapter 1 via the DBConnection
constructor and destructor. This makes the DBConnection easy to use:
|
The call to DBConnection::create( ) calls attach( ),
so when we're finished, we must explicitly call detach( ) to
release the original hold on the connection. Note that the DBClient
class also uses RAII to manage its use of the connection. When the program
terminates, the destructors for the two DBClient objects will decrement
the reference count (by calling detach( ), which DBConnection
inherited from Countable), and the database connection will be closed (because
of Countable's virtual destructor) when the count reaches zero after the
object c1 is destroyed.
A template approach is commonly used for mixin inheritance,
allowing the user to specify at compile time which flavor of mixin is desired.
This way you can use different reference-counting approaches without explicitly
defining DBConnection twice. Here's how it's done:
|
The only change here is the template prefix to the class
definition (and renaming Countable to Counter for clarity). We
could also make the database class a template parameter (had we multiple
database access classes to choose from), but it is not a mixin since it is a
standalone class. The following example uses the original Countable as
the Counter mixin type, but we could use any type that implements the
appropriate interface (attach( ), detach( ), and so
on):
|
The general pattern for multiple parameterized mixins is
simply
|
3.2.4. Duplicate subobjects
When you inherit from a base class, you get a copy of all the data members of that base class in your derived class. The following
program shows how multiple base subobjects might be laid out in memory:(123)
|
As you can see, the B portion of the object c
is offset 4 bytes from the beginning of the entire object, suggesting the
following layout:

The object c begins with it's A subobject,
then the B portion, and finally the data from the complete type C
itself. Since a C is-an A and is-a B, it is possible to
upcast to either base type. When upcasting to an A, the resulting
pointer points to the A portion, which happens to be at the beginning of
the C object, so the address ap is the same as the expression &c.
When upcasting to a B, however, the resulting pointer must point to
where the B subobject actually resides because class B knows nothing
about class C (or class A, for that matter). In other words, the
object pointed to by bp must be able to behave as a standalone B
object (except for any required polymorphic behavior).
When casting bp back to a C*, since the
original object was a C in the first place, the location where the B
subobject resides is known, so the pointer is adjusted back to the original
address of the complete object. If bp had been pointing to a standalone B
object instead of a C object in the first place, the cast would be
illegal.(124) Furthermore,
in the comparison bp == cp, cp is implicitly converted to a B*,
since that is the only way to make the comparison meaningful (that is,
upcasting is always allowed), hence the true result. So when converting
back and forth between subobjects and complete types, the appropriate offset is
applied.
The null pointer requires special handling, obviously, since
blindly subtracting an offset when converting to or from a B subobject
will result in an invalid address if the pointer was zero to start with. For
this reason, when casting to or from a B*, the compiler generates logic
to check first to see if the pointer is zero. If it isn't, it applies the
offset; otherwise, it leaves it as zero.
With the syntax we've seen so far, if you have multiple base
classes, and if those base classes in turn have a common base class, you will
have two copies of the top-level base, as you can see in the following example:
|
Since the size of b is 20 bytes,(125) there are
five integers altogether in a complete Bottom object. A typical class
diagram for this scenario usually appears as:
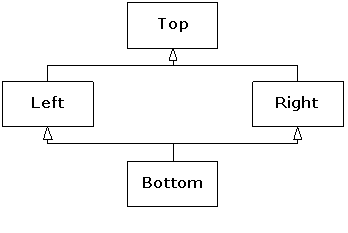
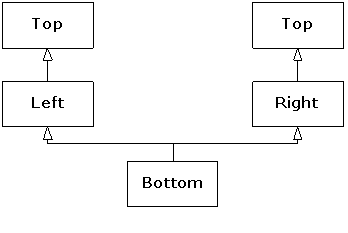
This is the so-called “diamond inheritance”, but in this case it would be better rendered as:
The awkwardness of this design surfaces in the constructor
for the Bottom class in the previous code. The user thinks that only
four integers are required, but which arguments should be passed to the two
parameters that Left and Right require? Although this design is
not inherently “wrong,” it is usually not what an application needs. It also
presents a problem when trying to convert a pointer to a Bottom object
to a pointer to Top. As we showed earlier, the address may need to be
adjusted, depending on where the subobject resides within the complete object,
but here there are two Top subobjects to choose from. The
compiler doesn't know which to choose, so such an upcast is ambiguous and is
not allowed. The same reasoning explains why a Bottom object would not
be able to call a function that is only defined in Top. If such a
function Top::f( ) existed, calling b.f( ) above would
need to refer to a Top subobject as an execution context, and there are
two to choose from.
3.2.5. Virtual base classes
What we usually want in such cases is true diamond
inheritance, where a single Top object is shared by both Left and
Right subobjects within a complete Bottom object, which is what
the first class diagram depicts. This is achieved by making Top a virtual
base class of Left and Right:
|
Each virtual base of a given type refers to the same object,
no matter where it appears in the hierarchy.(126) This
means that when a Bottom object is instantiated, the object layout may
look something like this:
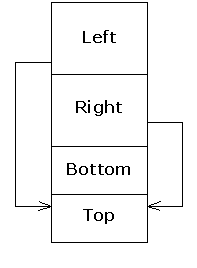
The Left and Right subobjects each have a
pointer (or some conceptual equivalent) to the shared Top subobject, and
all references to that subobject in Left and Right member
functions will go through those these pointers.(127) Here, there
is no ambiguity when upcasting from a Bottom to a Top object,
since there is only one Top object to convert to.
The output of the previous program is as follows:
|
The addresses printed suggest that this particular
implementation does indeed store the Top subobject at the end of the
complete object (although it's not really important where it goes). The result
of a dynamic_cast to void* always resolves to the address of the
complete object.
Although it is technically illegal to do so(128), if you
remove the virtual destructor (and the dynamic_cast statement, so the
program will compile), the size of Bottom decreases to 24 bytes. That
seems to be a decrease equivalent to the size of three pointers. Why?
It's important not to take these numbers too literally.
Other compilers we use manage only to increase the size by four bytes when the
virtual constructor is added. Not being compiler writers, we can't tell you
their secrets. We can tell you, however, that with multiple inheritance, a
derived object must behave as if it has multiple VPTRs, one for each of its
direct base classes that also have virtual functions. It's as simple as that.
Compilers make whatever optimizations their authors invent, but the behavior
must be the same.
The strangest thing in the previous code is the initializer
for Top in the Bottom constructor. Normally one doesn't worry
about initializing subobjects beyond direct base classes, since all classes
take care of initializing their own bases. There are, however, multiple paths
from Bottom to Top, so relying on the intermediate classes Left
and Right to pass along the necessary initialization data results in an
ambiguity—who is responsible for performing the initialization? For this
reason, the most derived class must initialize a virtual base. But what
about the expressions in the Left and Right constructors that
also initialize Top? They are certainly necessary when creating
standalone Left or Right objects, but must be ignored when
a Bottom object is created (hence the zeros in their initializers in the
Bottom constructor—any values in those slots are ignored when the Left
and Right constructors execute in the context of a Bottom
object). The compiler takes care of all this for you, but it's important to
understand where the responsibility lies. Always make sure that all concrete
(nonabstract) classes in a multiple inheritance hierarchy are aware of any
virtual bases and initialize them appropriately.
These rules of responsibility apply not only to
initialization, but to all operations that span the class hierarchy. Consider
the stream inserter in the previous code. We made the data protected so we
could “cheat” and access inherited data in operator<<(ostream&,
const Bottom&). It usually makes more sense to assign the work of
printing each subobject to its corresponding class and have the derived class
call its base class functions as needed. What would happen if we tried that
with operator<<( ), as the following code illustrates?
|
You can't just blindly share the responsibility upward in
the usual fashion, because the Left and Right stream inserters
each call the Top inserter, and again there will be duplication of data.
Instead you need to mimic what the compiler does with initialization. One
solution is to provide special functions in the classes that know about the virtual
base class, which ignore the virtual base when printing (leaving the job to the
most derived class):
|
The specialPrint( ) functions are protected
since they will be called only by Bottom. They print only their own data
and ignore their Top subobject because the Bottom inserter is in
control when these functions are called. The Bottom inserter must know
about the virtual base, just as a Bottom constructor needs to. This same
reasoning applies to assignment operators in a hierarchy with a virtual base,
as well as to any function, member or not, that wants to share the work
throughout all classes in the hierarchy.
Having discussed virtual base classes, we can now illustrate
the “full story” of object initialization. Since virtual bases give rise to shared subobjects, it makes sense that they should be available before the sharing
takes place. So the order of initialization of subobjects follows these rules,
recursively:
- All virtual base class subobjects are initialized, in top-down, left-to-right order according to where they appear in class definitions.
- Non-virtual base classes are then initialized in the usual order.
- All member objects are initialized in declaration order.
- The complete object's constructor executes.
The following program illustrates this behavior:
|
The classes in this code can be represented by the following
diagram:
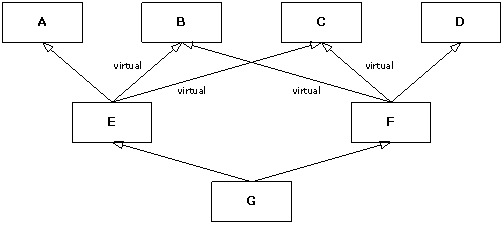
Each
class has an embedded member of type M. Note that only four derivations
are virtual: E from B and C, and F from B
and C. The output of this program is:
|
The initialization of g requires its E and F
part to first be initialized, but the B and C subobjects are
initialized first because they are virtual bases and are initialized from G's
initializer, G being the most-derived class. The class B has no
base classes, so according to rule 3, its member object m is initialized,
then its constructor prints “B from G”, and similarly for the C
subject of E. The E subobject requires A, B, and C
subobjects. Since B and C have already been initialized, the A
subobject of the E subobject is initialized next, and then the E
subobject itself. The same scenario repeats for g's F subobject,
but without duplicating the initialization of the virtual bases.
3.2.6. Name lookup issues
The ambiguities we have illustrated with subobjects apply to
any names, including function names. If a class has multiple direct base
classes that share member functions of the same name, and you call one of those
member functions, the compiler doesn't know which one to choose. The following
sample program would report such an error:
|
The class Bottom has inherited two functions of the
same name (the signature is irrelevant, since name lookup occurs before
overload resolution), and there is no way to choose between them. The usual
technique to disambiguate the call is to qualify the function call with the
base class name:
|
The name Left::f is now found in the scope of Bottom,
so the name Right::f is not even considered. To introduce extra
functionality beyond what Left::f( ) provides, you implement a Bottom::f( )
function that calls Left::f( ).
Functions with the same name occurring in different branches
of a hierarchy often conflict. The following hierarchy has no such problem:
|
Here, there is no explicit Right::f( ). Since Left::f( )
is the most derived, it is chosen. Why? Well, pretend that Right did not
exist, giving the single-inheritance hierarchy Top <= Left <= Bottom.
You would certainly expect Left::f( ) to be the function called by
the expression b.f( ) because of normal scope rules: a derived
class is considered a nested scope of a base class. In general, a name A::f
dominates the name B::f if A derives from B,
directly or indirectly, or in other words, if A is “more derived” in the
hierarchy than B.(129) Therefore,
in choosing between two functions with the same name, the compiler chooses the
one that dominates. If there is no dominant name, there is an ambiguity.
The following program further illustrates the dominance
principle:
|
The class diagram for this hierarchy is
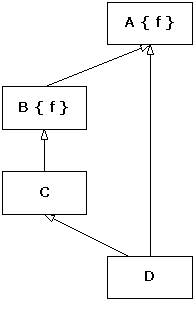
The class A is a (direct, in
this case) base class for B, and so the name B::f dominates A::f.
3.2.7. Avoiding MI
When the question of whether to use multiple inheritance
comes up, ask at least two questions:
- Do you need to show the public interfaces of both these classes through your new type? (See instead if one class can be contained within the other, with only some of its interface exposed in the new class.)
- Do you need to upcast to both of the base classes? (This also applies when you have more than two base classes.)
If you can answer “no” to either question, you can avoid
using MI and should probably do so.
Watch for the situation where one class needs to be upcast
only as a function argument. In that case, the class can be embedded and an
automatic type conversion function provided in your new class to produce a
reference to the embedded object. Any time you use an object of your new class
as an argument to a function that expects the embedded object, the type
conversion function is used.(130) However,
type conversion can't be used for normal polymorphic member function selection;
that requires inheritance. Preferring composition over inheritance is a good
overall design guideline.
3.2.8. Extending an interface
One of the best uses for multiple inheritance involves code that's out of your control. Suppose you've acquired a library that consists
of a header file and compiled member functions, but no source code for member
functions. This library is a class hierarchy with virtual functions, and it
contains some global functions that take pointers to the base class of the
library; that is, it uses the library objects polymorphically. Now suppose you
build an application around this library and write your own code that uses the
base class polymorphically.
Later in the development of the project or sometime during
its maintenance, you discover that the base-class interface provided by the
vendor doesn't provide what you need: a function may be non-virtual and you
need it to be virtual, or a virtual function is completely missing in the
interface, but essential to the solution of your problem. Multiple inheritance can
be the solution.
For example, here's the header file for a library you
acquire:
|
Assume the library is much bigger, with more derived classes
and a larger interface. Notice that it also includes the functions A( )
and B( ), which take a base reference and treat it polymorphically.
Here's the implementation file for the library:
|
In your project, this source code is unavailable to you.
Instead, you get a compiled file as Vendor.obj or Vendor.lib (or
with the equivalent file suffixes for your system).
The problem occurs in the use of this library. First, the
destructor isn't virtual.(131) In
addition, f( ) was not made virtual; we assume the library creator
decided it wouldn't need to be. You also discover that the interface to the
base class is missing a function essential to the solution of your problem.
Also suppose you've already written a fair amount of code using the existing
interface (not to mention the functions A( ) and B( ),
which are out of your control), and you don't want to change it.
To repair the problem, create your own class interface and
multiply inherit a new set of derived classes from your interface and from the
existing classes:
|
In MyBase (which does not use MI), both f( )
and the destructor are now virtual, and a new virtual function g( )
is added to the interface. Now each of the derived classes in the original
library must be re-created, mixing in the new interface with MI. The functions Paste1::v( )
and Paste1::f( ) need to call only the original base-class versions
of their functions. But now, if you upcast to MyBase as in main( ):
|
any function calls made through mp will be
polymorphic, including delete. Also, the new interface function g( )
can be called through mp. Here's the output of the program:
|
The original library functions A( ) and B( )
still work the same (assuming the new v( ) calls its base-class
version). The destructor is now virtual and exhibits the correct
behavior.
Although this is a messy example, it does occur in practice,
and it's a good demonstration of where multiple inheritance is clearly
necessary: You must be able to upcast to both base classes.
3.2.9. Summary
One reason MI exists in C++ is that it is a hybrid language
and couldn't enforce a single monolithic class hierarchy the way Smalltalk and
Java do. Instead, C++ allows many inheritance trees to be formed, so sometimes
you may need to combine the interfaces from two or more trees into a new class.
If no “diamonds” appear in your class hierarchy, MI is
fairly simple (although identical function signatures in base classes must
still be resolved). If a diamond appears, you may want to eliminate duplicate
subobjects by introducing virtual base classes. This not only adds confusion,
but the underlying representation becomes more complex and less efficient.
Multiple inheritance has been called the “goto of the '90s.”(132) This seems
appropriate because, like a goto, MI is best avoided in normal programming, but
can occasionally be very useful. It's a “minor” but more advanced feature of
C++, designed to solve problems that arise in special situations. If you find
yourself using it often, you might want to take a look at your reasoning. Ask
yourself, “Must I upcast to all the base classes?” If not, your life will be
easier if you embed instances of all the classes you don't need to
upcast to.
| (120) | This is also true of Java, and other object–oriented languages. |
| (121) | These version numbers are internal AT&T numberings. |
| (122) | Even more importantly, we don't want undefined behavior. It is an error for a base class not to have a virtual destructor. |
| (123) | The actual layout is implementation specific. |
| (124) | But not detected as an error. dynamic_cast, however, can solve this problem. See the previous chapter for details. |
| (125) | That is, 5*sizeof(int). Compilers can add arbitrary padding, so the size of an object must be at least as large as the sum of its parts, but can be larger. |
| (126) | We use the term hierarchy because everyone else does, but the graph representing multiple inheritance relationships is in general a directed acyclic graph (DAG), also called a lattice, for obvious reasons. |
| (127) | The presence of these pointers explains why the size of b is much larger than the size of four integers. This is (part of) the cost of virtual base classes. There is also VPTR overhead due to the virtual destructor. |
| (128) | Once again, base classes must have virtual destructors, but most compilers will let this experiment compile. |
| (129) | Note that virtual inheritance is crucial to this example. If Top were not a virtual base class, there would be multiple Top subobjects, and the ambiguity would remain. Dominance with multiple inheritance only comes into play with virtual base classes. |
| (130) | Jerry Schwarz, the author of iostreams, has remarked to both of us on separate occasions that if he had it to do over again, he would probably remove MI from the design of iostreams and use multiple stream buffers and conversion operators instead. |
| (131) | We've seen this in commercial C++ libraries, at least in some of the early ones. |
| (132) | A phrase coined by Zack Urlocker. |