


15. Polymorphisme & Fonctions Virtuelles▲
Le polymorphism (implémenté en C++ avec les fonctions virtual) est le troisième aspect essentiel d'un langage de programmation orienté objet, après l'abstraction des données et l'héritage.
Cela fournit une autre dimension de la séparation de l'interface et de l'implémentation, pour découpler quoi de comment. Le polymorphisme permet d'améliorer l'organisation et la lisibilité du code aussi bien que la création de programmes extensibles que l'on peut faire croître non seulement pendant la création originelle du projet, mais également quand de nouvelles caractéristiques sont souhaitées.
L'encapsulation crée de nouveaux types de données en combinant caractéristiques et comportements. Le contrôle d'accès sépare l'interface de l'implémentation en rendant les détails private. Ce genre d'organisation mécanique est rapidement claire pour quelqu'un qui a un passé en programmation procédurale. Mais les fonctions virtuelles traitent de découplage en terme de types. Au chapitre 14, vous avez vu comment l'héritage permettait le traitement d'un objet comme de son type propre ou comme son type de base. Cette capacité est critique parce qu'elle autorise à beaucoup de types (dérivés du même type de base) d'être traités comme s'ils étaient un seul type, et à un morceau de code unique de fonctionner indifféremment avec tous ces types. La fonction virtuelle permet à un type d'exprimer sa différence par rapport à un autre, similaire, pourvu qu'ils soient dérivés du même type de base. Cette distinction est exprimée par des différences de comportement des fonctions que vous pouvez appeler via la classe de base.
Dans ce chapitre vous étudierez les fonctions virtuelles, en partant des bases avec des exemples simples qui écartent tous les aspects sauf la “virtualité” au sein du programme.
15.1. Evolution des programmeurs C++▲
Les programmeurs en C semblent acquérir le C++ en trois étapes. Premièrement, simplement comme un “C amélioré”, parce que le C++ vous force à déclarer toutes les fonctions avant de les utiliser et se montre plus pointilleux sur la façon d'utiliser des variables. Vous pouvez souvent trouver les erreurs dans un programme C simplement en le compilant avec un compilateur C++.
La deuxième étape est le C++ “basé sur les objets”. Cela signifie que vous voyez facilement les bénéfices en terme d'organisation de code qui résultent du regroupement de structures de données avec les fonctions qui agissent dessus, la valeur des constructeurs et des destructeurs, et peut-être un peu d'héritage simple. La plupart des programmeurs qui ont travaillé en C pendant quelques temps voit rapidement l'utilité de tout cela parce que, à chaque fois qu'ils créent une bibliothèque, c'est exactement ce qu'ils essayent de faire. Avec le C++, vous avez l'assistance du compilateur.
Vous pouvez rester coincé au niveau basé sur les objets parce qu'on y arrive vite et qu'on en retire beaucoup de bénéfices sans trop d'effort intellectuel. Vous pouvez également avoir l'impression de créer des types de données – vous fabriquez des classes et des objets, vous envoyez des messages à ces objets, et tout est beau et clair.
Mais ne vous laissez pas avoir. Si vous vous arrêtez ici, vous manquez la plus grande partie du langage, qui est le saut vers la vraie programmation orientée objet. Vous ne pouvez le faire qu'avec les fonctions virtuelles.
Les fonctions virtuelles renforcent le concept de type au lieu de simplement encapsuler du code dans des structures et derrière des murs, elles sont ainsi sans aucun doute le concept le plus difficile à comprendre pour le nouveau programmeur C++. Toutefois, elles sont également la charnière dans la compréhension de la programmation orientée objet. Si vous n'utilisez pas les fonctions virtuelles, vous ne comprenez pas encore la POO.
Parce que la fonction virtuelle est intimement liée au concept de type, et que le type est au coeur de la programmation orientée objet, il n'y a pas d'analogue aux fonctions virtuelles dans un langage procédural classique. Comme programmeur procédural, vous n'avez aucune référence à laquelle vous ramener pour penser aux fonctions virtuelles, contrairement à pratiquement toutes les autres caractéristiques du langage. Les caractéristiques d'un langage procédural peuvent être comprises à un niveau algorithmique, mais les fonctions virtuelles ne peuvent être comprises que du point de vue de la conception.
15.2. Transtypage ascendant (upcasting)▲
Dans le chapitre 14 vous avez vu comment un objet peut être utilisé comme son propre type ou comme un objet de son type de base. En outre, il peut être manipulé via une adresse du type de base. Prendre l'adresse d'un objet (par un pointeur ou par une référence) et la traiter comme l'adresse du type de base est appelé transtypage ascendant( upcasting en anglais, ndt) à cause de la façon dont les arbres d'héritage sont dessinés, avec la classe de base en haut.
Vous avez également vu un problème se dessiner, qui est incarné dans le code ci-dessous :
//: C15:Instrument2.cpp
// Héritage & transtypage ascendant
#include <iostream>
using namespace std;
enum note { middleC, Csharp, Eflat }; // Etc.
class Instrument {
public:
void play(note) const {
cout << "Instrument::play" << endl;
}
};
// Les objets Wind sont des Instruments
// parce qu'ils ont la même interface :
class Wind : public Instrument {
public:
// Redéfinit la fonction interface :
void play(note) const {
cout << "Wind::play" << endl;
}
};
void tune(Instrument& i) {
// ...
i.play(middleC);
}
int main() {
Wind flute;
tune(flute); // transtypage ascendant
} ///:~La fonction tune( ) accepte (par référence) un Instrument, mais également, sans se plaindre, tout dérivé d' Instrument. Dans main( ), vous pouvez voir cela se produire quand un objet Wind est passé à tune( ), sans nécessiter de transtypage. C'est acceptable ; l'interface qui se trouve dans Instrument doit exister dans Wind, parce que Wind hérite publiquement d' Instrument. Faire un transtypage ascendant de Wind vers Instrument peut “rétrécir” cette interface, mais jamais la ramener à moins que l'interface complète d' Instrument.
Les mêmes arguments sont vrais quand on traite des pointeurs ; la seule différence est que l'utilisateur doit prendre explicitement les adresses des objets quand ils sont passés dans la fonction.
15.3. Le problème▲
Le problème avec Instrument2.cpp peut être vu en exécutant le programme. La sortie est Instrument::play. Ceci n'est clairement pas la sortie désirée, parce qu'il se trouve que vous savez que l'objet est en fait un Wind et pas juste un Instrument. L'appel devrait produire Wind::play. A ce sujet, n'importe quel objet d'une classe dérivée de Instrument devrait avoir sa version de play( ) utilisé, indépendamment de la situation.
Le comportement de Instrument2.cpp n'est pas surprenant, étant donné l'approche du C pour les fonctions. Pour comprendre ces questions, vous devez être conscient du concept de liaison.
15.3.1. Liaison d'appel de fonction▲
Connecter un appel de fonction à un corps de fonction est appelé liaison( binding en anglais ndt). Quand la liaison est effectuée avant que le programme ne soit exécuté (par le compilateur et le linker), elle est appelée liaison précoce( early binding ndt). Vous n'avez peut être jamais entendu ce terme auparavant parce qu'il n'a jamais été une option dans les langages procéduraux : les compilateurs C n'ont qu'un seul genre d'appels de fonctions, et il s'agit de la liaison précoce.
Le problème dans le programme précédent est causé par la liaison précoce parce que le compilateur ne peut pas savoir quelle est la fonction correcte qu'il doit appeler quand il ne dispose que de l'adresse d'un Instrument.
La solution est appelée liaison tardive( late binding ndt), ce qui signifie que la liaison se produit au moment de l'exécution, en fonction du type de l'objet. La liaison tardive est aussi appelée liaison dynamique( dynamic binding ndt) ou liaison à l'exécution( runtime binding ndt). Quand un langage implémente la liaison tardive, il doit posséder un mécanisme afin de déterminer le type de l'objet au moment de l'exécution et appeler la fonction membre appropriée. Dans le cas d'un langage compilé, le compilateur ne sait toujours pas le type réel de l'objet, mais il insert du code qui trouve et appelle le corps de la fonction qui convient. Le mécanisme de liaison tardive varie d'un langage à l'autre, mais vous vous doutez qu'une sorte d'information de type doit être installée dans les objets. Vous verrez comment cela fonctionne plus tard.
15.4. Fonctions virtuelles▲
Pour provoquer une liaison tardive pour une fonction particulière, le C++ impose que vous utilisiez le mot-clef virtual quand vous déclarez la fonction dans la classe de base. La liaison tardive n'a lieu que pour les fonctions virtuelles, et seulement lorsque vous utilisez une adresse de la classe de base où ces fonctions virtuelles existent, bien qu'elles puissent être également définies dans une classe de base antérieure.
Pour créer une fonction membre virtual, vous n'avez qu'à faire précéder la déclaration de la fonction du mot-clef virtual. Seule, la déclaration nécessite ce mot-clef, pas la définition. Si une fonction est déclarée virtual dans la classe de base, elle est virtual dans toutes les classes dérivées. La redéfinition d'une fonction virtuelle dans une classe dérivée est généralement appelée redéfinition(overriding, ndt).
Remarquez que vous n'avez à déclarer une fonction virtual que dans la classe de base. Toutes les fonctions des classes dérivées dont signature correspond à celle de la déclaration dans la classe de base seront appelées en utilisant le mécanisme virtuel. Vous pouvez utiliser le mot-clef virtual dans les déclarations des classes dérivées (cela ne fait aucun mal), mais c'est redondant et cela peut prêter à confusion.
Pour obtenir de Instrument2.cpp le comportement désiré, ajoutez simplement le mot-clef virtual dans la classe de base avant play( ):
//: C15:Instrument3.cpp
// liaison tardive avec le mot-clef virtual
#include <iostream>
using namespace std;
enum note { middleC, Csharp, Cflat }; // Etc.
class Instrument {
public:
virtual void play(note) const {
cout << "Instrument::play" << endl;
}
};
// Les objets Wind sont des Instruments
// parce qu'ils ont la même interface :
class Wind : public Instrument {
public:
// Redéfinit la fonction d'interface :
void play(note) const {
cout << "Wind::play" << endl;
}
};
void tune(Instrument& i) {
// ...
i.play(middleC);
}
int main() {
Wind flute;
tune(flute); // Upcasting
} ///:~Mise à part l'ajout du mot-clef virtual, ce fichier est identique à Instrument2.cpp, et pourtant le comportement est significativement différent : à présent la sortie est Wind::play.
15.4.1. Extensibilité▲
play( ) étant défini virtual dans la classe de base, vous pouvez ajouter autant de nouveaux types que vous le désirez sans changer la fonction tune( ). Dans un programme orienté objet bien conçu, la plupart voire toutes vos fonctions suivront le modèle de tune( ) et communiqueront uniquement avec l'interface de la classe de base. Un tel programme est extensible parce que vous pouvez ajouter de nouvelles fonctionnalités en faisant hériter de nouveaux types à partir de la classe de base commune. Les fonctions qui manipulent l'interface de la classe de base n'auront pas besoin d'être modifiées pour s'adapter aux nouvelles classes.
Voici l'exemple d' Instrument avec davantage de fonctions virtuelles et quelques nouvelles classes, qui fonctionnent toutes correctement avec la vieille version, non modifiée, de la fonction tune( ):
//: C15:Instrument4.cpp
// Extensibilité dans la POO
#include <iostream>
using namespace std;
enum note { middleC, Csharp, Cflat }; // Etc.
class Instrument {
public:
virtual void play(note) const {
cout << "Instrument::play" << endl;
}
virtual char* what() const {
return "Instrument";
}
// Supposez que ceci modifiera l'objet :
virtual void adjust(int) {}
};
class Wind : public Instrument {
public:
void play(note) const {
cout << "Wind::play" << endl;
}
char* what() const { return "Wind"; }
void adjust(int) {}
};
class Percussion : public Instrument {
public:
void play(note) const {
cout << "Percussion::play" << endl;
}
char* what() const { return "Percussion"; }
void adjust(int) {}
};
class Stringed : public Instrument {
public:
void play(note) const {
cout << "Stringed::play" << endl;
}
char* what() const { return "Stringed"; }
void adjust(int) {}
};
class Brass : public Wind {
public:
void play(note) const {
cout << "Brass::play" << endl;
}
char* what() const { return "Brass"; }
};
class Woodwind : public Wind {
public:
void play(note) const {
cout << "Woodwind::play" << endl;
}
char* what() const { return "Woodwind"; }
};
// Fonction identique à précédemment :
void tune(Instrument& i) {
// ...
i.play(middleC);
}
// Nouvelle fonction :
void f(Instrument& i) { i.adjust(1); }
// Upcasting pendant l'initialisation du tableau :
Instrument* A[] = {
new Wind,
new Percussion,
new Stringed,
new Brass,
};
int main() {
Wind flute;
Percussion drum;
Stringed violin;
Brass flugelhorn;
Woodwind recorder;
tune(flute);
tune(drum);
tune(violin);
tune(flugelhorn);
tune(recorder);
f(flugelhorn);
} ///:~Vous pouvez voir qu'un niveau d'héritage nouveau a été ajouté en dessous de Wind, mais le mécanisme virtual fonctionne correctement indépendamment du nombre de niveaux. La fonction adjust( ) n'est pas redéfinie pour Brass et Woodwind. Quand c'est le cas, la définition “la plus proche” dans la hiérarchie de l'héritage est utilisée automatiquement – le compilateur garantit qu'il y a toujours une définition pour une fonction virtuelle, afin que vous ne vous retrouviez jamais avec un appel qui ne soit pas associé à un corps de fonction. (Ce qui serait désastreux.)
Le tableau A[ ] contient des pointeurs vers la classe de base Instrument, ainsi l'upcasting se produit pendant le processus d'initialisation du tableau. Ce tableau et la fonction f( ) seront utilisés dans des discussions ultérieures.
Dans l'appel à tune( ), l'upcasting est réalisé sur chaque type d'objet différent, et pourtant, le comportement désiré a toujours lieu. On peut décrire cela comme “envoyer un message à un objet et laisser l'objet se préoccuper de ce qu'il doit faire avec”. La fonction virtual est la lentille à utiliser quand vous essayez d'analyser un projet : où les classes de base devraient-elle se trouver, et comment pourriez-vous vouloir étendre le programme ? Toutefois, même si vous ne trouvez pas les bonnes interfaces de classes de base et les fonctions virtuelles satisfaisantes lors de la création initiale du programme, vous les découvrirez souvent plus tard, même beaucoup plus tard, quand vous vous mettrez à étendre ou sinon à maintenir le programme. Ce n'est pas une erreur d'analyse ou de conception ; cela veut juste dire que vous ne connaissiez ou ne pouviez pas connaître toutes les informations au début. A cause de la modularité serrée des classes en C++, ce n'est pas un gros problème quand cela se produit, parce que les modifications que vous effectuez dans une partie d'un système n'ont pas tendance à se propager à d'autres comme elles le font en C.
15.5. Comment le C++ implémente la liaison tardive▲
Comment la liaison tardive peut-elle se produire ? Tout le travail est effectué discrètement par le compilateur, qui installe le mécanisme de liaison tardive nécessaire quand vous le lui demandez (ce que vous réalisez en créant des fonctions virtuelles). Comme les programmeurs tirent souvent profit d'une bonne compréhension du mécanisme des fonctions virtuelles en C++, cette section va détailler la façon dont le compilateur implémente ce mécanisme.
Le mot-clef virtual dit au compilateur qu'il ne doit pas réaliser la liaison trop tôt. Au lieu de cela, il doit installer automatiquement tous les mécanismes nécessaires pour réaliser la liaison tardive. Ceci signifie que si vous appelez play( ) pour un objet Brassgrâce à une adresse pour la classe de baseInstrument, vous obtiendrez la bonne fonction.
Pour ce faire, le compilateur typique (55)crée une table unique (appelée VTABLE)pour chaque classe qui contient des fonctions virtual. Le compilateur place les adresses des fonctions virtuelles pour cette classe particulière dans la VTABLE. Dans chaque classe dotée de fonctions virtuelles, il place secrètement un pointeur, appelé le vpointeur(abrégé en VPTR), qui pointe vers la VTABLE de cet objet. Quand vous faites un appel à une fonction virtuelle à travers un pointeur vers la classe de base (c'est-a-dire, quand vous faites un appel polymorphe), le compilateur insère discrètement du code pour aller chercher le VPTR et trouver l'adresse de la fonction dans la VTABLE, appelant ainsi la fonction correcte et réalisant ainsi la liaison tardive.
Tout cela – créer la VTABLE pour chaque classe, initialiser le VPTR, insérer le code pour l'appel à la fonction virtuelle – a lieu automatiquement, et vous n'avez donc pas à vous en inquiéter. Avec les fonctions virtuelles, la fonction qui convient est appelée pour un objet, même si le compilateur ne peut pas connaître le type de l'objet.
Les sections qui suivent analysent plus en détails ce processus.
15.5.1. Stocker l'information de type▲
Vous pouvez constater qu'il n'y a aucune information explicite de type stockée dans aucune des classes. Mais les exemples précédents, et la simple logique, vous disent qu'il doit y avoir un genre d'information de type stockée dans les objets ; autrement le type ne pourrait être déterminé à l'exécution. Ceci est vrai, mais l'information de type est dissimulée. Pour la voir, voici un exemple permettant d'examiner la taille des classes qui utilisent les fonctions virtuelles comparée à celles des classes qui ne s'en servent pas :
//: C15:Sizes.cpp
// Taille des objets avec ou sans fonctions virtuelles
#include <iostream>
using namespace std;
class NoVirtual {
int a;
public:
void x() const {}
int i() const { return 1; }
};
class OneVirtual {
int a;
public:
virtual void x() const {}
int i() const { return 1; }
};
class TwoVirtuals {
int a;
public:
virtual void x() const {}
virtual int i() const { return 1; }
};
int main() {
cout << "int: " << sizeof(int) << endl;
cout << "NoVirtual: "
<< sizeof(NoVirtual) << endl;
cout << "void* : " << sizeof(void*) << endl;
cout << "OneVirtual: "
<< sizeof(OneVirtual) << endl;
cout << "TwoVirtuals: "
<< sizeof(TwoVirtuals) << endl;
} ///:~Sans fonction virtuelle, la taille de l'objet est exactement ce à quoi vous pouvez vous attendre : la taille d'un int unique (56). Avec une seule fonction virtuelle dans OneVirtual, la taille de l'objet est la taille de NoVirtual plus la taille d'un pointeur void. Il s'avère que le compilateur insère un unique pointeur (le VPTR) dans la structure si vous avez une ou plusieurs fonctions virtuelles. Il n'y a pas de différence de taille entre OneVirtual et TwoVirtuals. C'est parce que le VPTR pointe vers une table d'adresses de fonctions. Il n'y a besoin que d'une seule table parce que toutes les adresses des fonctions virtuelles sont contenues dans cette unique table.
Cet exemple nécessitait au moins une donnée membre. S'il n'y en avait eu aucune, le C++ aurait forcé les objets à avoir une taille non nulle parce que chaque objet doit avoir une adresse différente. Si vous imaginez l'indexation dans un tableau d'objets de taille nulle, vous comprendrez pourquoi. Un membre “factice” est inséré dans les objets qui autrement seraient de taille nulle. Quand l'information de type est insérée dans les objets via le mot-clef virtual, elle prend la place du membre “factice”. Essayez de passer le int a en commentaire dans les classes de l'exemple ci-dessus pour le voir.
15.5.2. Représenter les fonntions virtuelles▲
Pour comprendre exactement ce qu'il se passe quand vous utilisez une fonction virtuelle, il est pratique de visualiser ce qu'il se passe derrière la scène. Voici un schéma du tableau des pointeurs A[ ] dans Instrument4.cpp:

Le tableau de pointeurs vers Instrument n'a pas d'information de type spécifique ; ils pointent tous vers un objet de type Instrument. Wind, Percussion, Stringed, et Brass rentrent tous dans cette catégorie parce qu'ils sont dérivés d' Instrument(et ont donc la même interface qu' Instrument, et peuvent répondre aux mêmes messages), et leur adresse peut donc également être placée dans le tableau. Toutefois, le compilateur ne sait pas qu'ils sont quelque chose de plus que des objets Instrument, et donc si on le laissait autonome il appellerait normalement pour toutes les fonctions leur version de la classe de base. Mais dans ce cas, toutes ces fonctions ont été déclarées avec le mot-clef virtual, si bien que quelque chose de différent se produit.
A chaque fois que vous créez une classe qui contient des fonctions virtuelles, ou que vous dérivez d'une classe qui en contient, le compilateur crée une VTABLE unique pour cette classe, visible sur la droite du diagramme. Dans cette table il place les adresses de toutes les fonctions qui ont été déclarés virtuelles dans cette classe ou dans la classe de base. Si vous ne surchargez pas une fonction qui a été déclarée virtual dans la classe de base, le compilateur utilise l'adresse de la version de la classe de base dans la classe dérivée. (Vous pouvez le voir dans l'entrée adjust dans la VTABLE de Brass.) Puis il positionne le VPTR (découvert dans Sizes.cpp) au sein de la classe. Il n'y a qu'un seul VPTR pour chaque objet quand on utilise l'héritage simple comme ceci. Le VPTR doit être initialisé pour pointer vers l'adresse de début de la VTABLE appropriée. (Ceci se produit dans le constructeur, ce que vous verrez de manière plus détaillée ci-dessous.)
Une fois que le VPTR est initialisé à la bonne VTABLE, l'objet actuel “sait” de quel type il est. Mais cette connaissance de soi est sans valeur à moins d'être utilisée au moment de l'appel d'une fonction virtuelle.
Quand vous appelez une fonction virtuelle via l'adresse d'une classe de base (ce qui correspond à la situation où le compilateur ne dispose pas de toutes les informations nécessaires pour réaliser la liaison plus tôt), quelque chose de particulier se produit. Au lieu de réaliser un appel typique à une fonction, qui est simplement un CALL en langage assembleur vers une adresse particulière, le compilateur génère un code différent pour réaliser l'appel. Voici à quoi ressemble un appel à adjust( ) pour un objet Brass, s'il est réalisé via un pointeur vers Instrument(Une référence vers Instrument produit le même résultat) :

Le compilateur commence avec le pointeur vers Instrument, qui pointe vers l'adresse de début de l'objet. Tous les objets Instrument ou dérivés d' Instrument ont leur VPTR au même endroit (souvent au début de l'objet), afin que le compilateur puisse le repérer dans l'objet. Le VPTR pointe vers l'adresse de début de la VTABLE. Toutes les adresses de fonction de la VTABLE sont disposées dans le même ordre, indépendamment du type spécifique de l'objet : en premier, play( ), puis what( ) et enfin adjust( ). Le compilateur sait que, indépendamment du type spécifique d'objet, la fonction adjust( ) est à l'emplacement VPTR+2. Ainsi, au lieu de dire : “Appelle la fonction à l'emplacement absolu Instrument::adjust” (liaison précoce; mauvaise démarche), il génère du code qui dit : “Appelle la fonction à VPTR+2”. Comme la recherche du VPTR et la détermination de la vraie adresse de la fonction a lieu à l'exécution, vous obtenez la liaison tardive désirée. Vous envoyer un message à l'objet, qui devine ce qu'il doit en faire.
15.5.3. Sous le capot▲
Il peut être utile de voir le code assembleur généré par un appel à une fonction virtuelle, afin que vous voyiez que la liaison tardive a bien lieu. Voici la sortie d'un compilateur pour l'appel
i.adjust(1);dans la fonction f(Instrument& i):
push 1
push si
mov bx, word ptr [si]
call word ptr [bx+4]
add sp, 4Les arguments d'un appel à une fonction en C++, comme en C, sont poussés sur la pile depuis la droite vers la gauche (cet ordre est requis pour supporter les listes d'arguments variables du C), si bien que l'argument 1 est poussé sur la pile en premier. A ce point de la fonction, le registre si(élément de l'architecture des processeurs Intel X86) contient l'adresse de i, qui est également poussé sur la pile parce que c'est l'adresse du début de l'objet qui nous intéresse. Rappelez vous que l'adresse du début correspond à la valeur de this, et this est discrètement poussé sur la pile comme un argument avant tout appel à fonction, afin que la fonction membre sache sur quel objet particulier elle travaille. Ainsi, vous verrez toujours un argument de plus que la liste des arguments de la fonction poussés sur la pile avant un appel à une fonction membre (sauf pour les fonctions membres static, qui n'ont pas de this).
A présent, le vrai appel à la fonction virtuelle doit être réalisé. Tout d'abord, le VPTR doit être produit, afin que la VTABLE puisse être trouvée. Pour ce compilateur, le VPTR est inséré au début de l'objet, si bien que le contenu de this correspond au VPTR. La ligne
mov bx, word ptr [si]cherche le mot vers lequel pointe si(c'est-à-dire this), qui est le VPTR. Il place le VPTR dans le registre bx.
Le VPTR contenu dans bx pointe vers l'adresse du début de la VTABLE, mais le pointeur de la fonction à appeler n'est pas à l'meplacement zéro de la VTABLE, mais à l'emplacement deux (parce que c'est la troisième fonction dans la liste). Pour ce modèle de mémoire, chaque pointeur de fonction mesure deux octets, et donc le compilateur ajoute quatre au VPTR pour calculer où se trouve l'adresse de la fonction appropriée. Remarquez que c'est une valeur constante, établie à la compilation, et donc la seule chose qui importe est que le pointeur de fonction à l'emplacement numéro deux est celui d' adjust( ). Heureusement, le compilateur prend soin de toute la comptabilité pour vous et garantit que tous les pointeurs de fonction dans toutes les VTABLEs d'une hiérarchie de classe particulière apparaissent dans le même ordre, indépendamment de l'ordre dans lequel vous pouvez les surcharger dans les classes dérivées.
Une fois que le bon pointeur de fonction de la VTABLE est calculé, cette fonction est appelée. Ainsi, l'adresse est-elle cherchée et l'appel effectué simultanément dans l'instruction
call word ptr [bx+4]Finalement, le pointeur vers la pile est repoussé vers le haut pour nettoyer les arguments qui ont été poussés avant l'appel. Dans le cide assembleur du C et du C++ vous verrez souvent l'appelant nettoyer les arguments mais cela peut varier selon les processeurs et les implémentations des compilateurs.
15.5.4. Installer le vpointeur▲
Puisque le VPTR détermine le comportement de la fonction virtuelle de l'objet, vous voyez à quel point il est important que le VPTR pointe toujours vers la VTABLE appropriée. Vous n'avez jamais intérêt à être capable de réaliser un appel à une fonction virtuelle avant que le VPTR ne soit proprement initialisé. Bien sûr, l'endroit où l'initialisation peut être garantie est dans le constructeur, mais aucun des exemples d' Instrument n'en a.
C'est ici que la création d'un constructeur par défaut est essentielle. Dans les exemples d' Instrument, le compilateur crée un constructeur par défaut qui ne fait rien sauf initialiser le VPTR. Ce constructeur, bien sûr, est automatiquement appelé pour tous les objets Instrument avant que vous ne puissiez faire quoi que ce soit avec eux, et vous savez ainsi qu'il est toujours sûr d'appeler des fonctions virtuelles.
Les implications de l'initialisation automatique du VPTR dans le constructeur sont discutées dans une section ultérieure.
15.5.5. Les objets sont différents▲
Il est important de réaliser que l'upcasting traite seulement des adresses. Si le compilateur dispose d'un objet, il en connaît le type exact et ainsi (en C++) n'utilisera pas de liaison tardive pour les appels de fonction – ou tout au moins, le compilateur n'a pas besoin d'utiliser la liaison tardive. Par souci d'efficacité, la plupart des compilateurs réaliseront une liaison précoce quand ils réalisent un appel à une fonction virtuelle pour un objet parce qu'ils en connaissent le type exact. Voici un exemple :
//: C15:Early.cpp
// Liaison précoce & fonctions virtuelles
#include <iostream>
#include <string>
using namespace std;
class Pet {
public:
virtual string speak() const { return ""; }
};
class Dog : public Pet {
public:
string speak() const { return "Bark!"; }
};
int main() {
Dog ralph;
Pet* p1 = &ralph;
Pet& p2 = ralph;
Pet p3;
// Liaison tardive pour les deux :
cout << "p1->speak() = " << p1->speak() <<endl;
cout << "p2.speak() = " << p2.speak() << endl;
// Liaison précoce (probable):
cout << "p3.speak() = " << p3.speak() << endl;
} ///:~Dans p1–>speak( ) et p2.speak( ), les adresses sont utilisées, ce qui signifie que l'information est incomplète : p1 et p2 peuvent représenter l'adresse d'un Petou de quelque chose qui en dérive, et le mécanisme virtuel doit donc être utilisé. L'appel de p3.speak( ) est sans ambiguïté. Le compilateur connaît le type exact et sait que que c'est un objet, si bienqu'il ne peut en aucun cas être un objet dérivé de Pet– c'est exactement un Pet. Ainsi, la liaison précoce est ici probablement utilisée. Toutefois, si le compilateur ne veut pas travailler autant, il peut toujours utiliser la liaison tardive et le même comportement en découlera.
15.6. Pourquoi les fonctions virtuelles ?▲
A ce point de la discussion vous pouvez avoir une question : “Si cette technique est si importante, et si elle réalise le ‘bon' appel de fonction à chaque fois, pourquoi n'est-ce qu'une option ? Pourquoi ai-je même besoin de le connaître ?”
C'est une bonne question, et la réponse fait partie la philosophie fondamentale du C++ : “Parce que ce n'est pas aussi efficace”. Vous pouvez constater d'après les sorties en langage assembleur vues ci-dessus qu'au lieu d'un simple CALL à une adresse absolue, cela requiert deux instructions assembleur – plus sophistiquées – pour préparer l'appel à une fonction virtuelle. Cela demande à la fois du code et du temps d'exécution supplémentaire.
Certains langages orientés objet ont adopté l'approche qui considère que la liaison tardive est tellement intrinsèque à la programmation orientée objet qu'elle devrait toujours avoir lieu, que cela ne devrait pas être une option, et l'utilisateur ne devrait pas avoir à en entendre parler. C'est une décision de conception à prendre à la création d'un langage, et cette approche particulière est appropriée pour beaucoup de langages (57). Toutefois, le C++ provient de l'héritage du C, où l'efficacité est critique. Après tout, le C a été créé pour remplacer le langage assembleur pour l'implémentation d'un système d'exploitation (rendant ainsi ce système d'exploitation – Unix – largement plus portable que ses prédécesseurs). Une des raisons principales de l'invention du C++ était de rendre les programmeurs C plus efficaces (58). Et la première question posée quand les programmeurs C rencontrent le C++ est : “Quel type d'impact obtiendrais-je sur la taille et la vitesse ? “ Si la réponse était : ”Tout est parfait sauf pour les appels de fonctions où vous aurez toujours un petit temps de surcharge supplémentaire” beaucoup de monde serait resté au C plutôt que de passer au C++. En outre, les fonctions inline n'auraient pas été possibles, parce que les focntions virtuelles doivent disposer d'une adresse à mettre dans la VTABLE. Ainsi donc, la fonction virtuelle est une option, et le langage utilise par défaut les non virtuelles, ce qui est la configuration la plus rapide. Stroustrup affirmait que sa ligne de conduite était : “si vous ne vous en servez pas, vous n'en payez pas le prix.”
Ainsi, le mot-clef virtual est fourni pour moduler l'efficacité. Quand vous concevez vos classes, toutefois, vous ne devriez pas vous inquiéter de régler l'efficacité. Si vous allez utiliser le polymorphisme, utilisez des fonctions virtuelles partout. Vous devez seulement chercher des fonctions qui peuvent être rendues non virtuelles quand vous cherchez des manières d'accélérer votre code (et il y a le plus souvent de bien plus grands gains à réaliser dans d'autres domaines – un bon profileur réalisera un meilleur travail pour trouver les goulets d'étranglement que vous en faisant des conjectures).
Le retour d'expérience suggère que les impacts sur la taille et la vitesse quand on passe au C++ est inférieure à 10 pour cent de la taille et de la vitesse en C, et sont souvent plus prôches de l'égalité. La raison pour laquelle vous pourriez obtenir une plus petite taille et une plus grande vitesse est que vous pouvez concevoir un programme en C++ plus petit et plus rapide que vous ne le feriez en C.
15.7. Classes de base abstraites et fonctions virtuelles pures▲
Souvent dans une conception, vous désirez que la classe de base présente uniquement une interface pour ses classes dérivées. C'est-à-dire que vous ne voulez pas que quiconque crée un objet de la classe de base, mais seulement d'upcaster vers celle-ci afin que son interface puisse être utilisée. Ceci est réalisé en rendant cette classe abstraite, ce qui se produit si vous lui donnez au moins une fonction virtuelle pure. Vous pouvez reconnaître une fonction virtuelle pure parce qu'elle utilise le mot-clef virtual et est suivie par = 0. Si quelqu'un essaie de créer un objet d'une classe abstraite, le compilateur l'en empêche. C'est un outil qui vous permet d'imposer une conception donnée.
Quand une classe abstraite est héritée, toutes les fonctions virtuelles pures doivent être implémentées, sinon la classe qui hérite devient également abstraite. Créer une fonction virtuelle pure vous permet de mettre une fonction membre dans une interface sans avoir à fournir un code potentiellement dénué de sens pour cette fonction membre. En même temps, une fonction virtuelle pure force les classes qui en héritent à fournir pour elle une définition.
Dans tous les exemples d' Instrument, les fonctions de la classe de base Instrument étaient toujours des fonctions “factices”. Si jamais ces fonctions sont appelées, quelque chose cloche. C'est parce que le but de Instrument est de créer une interface commune pour toutes les classes qui en dérivent.
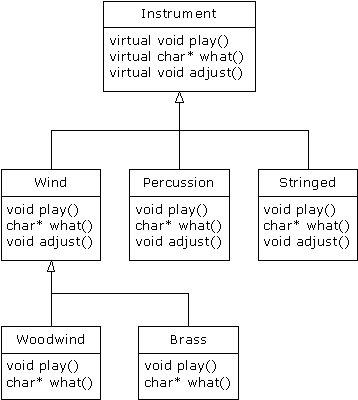
La seule raison d'établir une interface commune est afin qu'elle puisse être exprimée différemment pour chaque sous-type. Cela crée une forme élémentaire qui détermine ce qui est commun à toutes les classes dérivées – rien d'autre. Ainsi Instrument est un candidat approprié pour devenir une classe abstraite. Vous créez une classe abstraite quand vous voulez seulement manipuler un ensemble de classes à travers une interface commune, mais il n'est pas nécessaire que l'interface commune possède une implémentation (ou tout au moins, une implémentation complète).
Si vous disposez d'un concept comme Instrument qui fonctionne comme une classe abstraite, les objets de cette classe n'ont presque jamais de signification. C'est-à-dire que Instrument a pour but d'exprimer uniquement l'interface, et pas une implémentation particulière, et donc créer un objet qui soit uniquement Instrument n'a aucun sens, et vous voudrez sans doute empêcher l'utilisateur de le faire. Ceci peut être accompli en faisant imprimer un message d'erreur par toutes les fonctions virtuelles d' Instrument, mais cela repousse l'apparition de l'information d'erreur jusqu'au moment de l'exécution et requiert un test fiable et exhaustif de la part de l'utilisateur. Il vaut beaucoup mieux traiter le problème à la compilation.
Voici la syntaxe utilisée pour une déclaration virtuelle pure :
virtual void f() = 0;Ce faisant, vous dites au compilateur de réserver un emplacement pour une fonction dans la VTABLE, mais pas de mettre une adresse dans cet emplacement particulier. Dans une classe, même si une seule fonction est déclarée virtuelle pure, la VTABLE est incomplète.
Si la VTABLE d'une classe est incomplète, qu'est-ce que le compilateur est censé faire quand quelqu'un essaie de créer un objet de cette classe ? Il ne peut pas créer sans risque un objet d'une classe abstraite, donc vous recevez un message d'erreur du compilateur. Ainsi, le compilateur garantit la pureté de la classe abstraite. En rendant une classe abstraite, vous vous assurez que le programmeur client ne peut pas en mésuser.
Voici Instrument4.cpp, modifié afin d'utiliser les fonctions virtuelles pures. Comme la classe n'a rien d'autre que des fonctions virtuelles pures, on l'appelle une classe abstraite pure:
//: C15:Instrument5.cpp
// Classes de base abstraites pures
#include <iostream>
using namespace std;
enum note { middleC, Csharp, Cflat }; // Etc.
class Instrument {
public:
// Fonctions virtuelles pures :
virtual void play(note) const = 0;
virtual char* what() const = 0;
// Suppose que cela modifiera l'objet :
virtual void adjust(int) = 0;
};
// Le reste du fichier est similaire...
class Wind : public Instrument {
public:
void play(note) const {
cout << "Wind::play" << endl;
}
char* what() const { return "Wind"; }
void adjust(int) {}
};
class Percussion : public Instrument {
public:
void play(note) const {
cout << "Percussion::play" << endl;
}
char* what() const { return "Percussion"; }
void adjust(int) {}
};
class Stringed : public Instrument {
public:
void play(note) const {
cout << "Stringed::play" << endl;
}
char* what() const { return "Stringed"; }
void adjust(int) {}
};
class Brass : public Wind {
public:
void play(note) const {
cout << "Brass::play" << endl;
}
char* what() const { return "Brass"; }
};
class Woodwind : public Wind {
public:
void play(note) const {
cout << "Woodwind::play" << endl;
}
char* what() const { return "Woodwind"; }
};
// Fonctions identiques à précédemment :
void tune(Instrument& i) {
// ...
i.play(middleC);
}
// Nouvelle fonction :
void f(Instrument& i) { i.adjust(1); }
int main() {
Wind flute;
Percussion drum;
Stringed violin;
Brass flugelhorn;
Woodwind recorder;
tune(flute);
tune(drum);
tune(violin);
tune(flugelhorn);
tune(recorder);
f(flugelhorn);
} ///:~Les fonctions virtuelles pures sont utiles parce qu'elles rendent explicite le caractère abstrait d'une classe et disent à la fois au compilateur et à l'utilisateur comment il était prévu de l'utiliser.
Remarquez que les fonctions virtuelles pures empêchent qu'une classe abstraite soit passée dans une fonction par valeur. Ainsi, c'est également un moyen d'éviter le découpage d'objet(qui sera bientôt décrit). En rendant abstraite une classe, vous pouvez garantir qu'un pointeur ou une référence est toujours utilisé pendant l'upcasting vers cette classe.
Le simple fait qu'une seule fonction virtuelle pure empêche la VTABLE d'être complètée ne signifie pas que vous ne voulez pas de corps pour certaines autres fonctions. Souvent, vous aurez envie d'appeler la version de la classe de base d'une fonction, même si elle est virtuelle. C'est toujours une bonne idée de placer le code commun aussi près que possible de la racine de votre hiérarchie. Non seulement cela économise du code, mais cela permet également une propagation facile des modifications.
15.7.1. Définitions virtuelles pures▲
Il est possible de fournir une définition pour une fonction virtuelle pure dans la classe de base. Vous dites toujours au compilateur de ne pas permettre d'objets de cette classe de base abstraite, et les fonctions virtuelles pures doivent toujours être définies dans les classes dérivées afin de créer des objets. Toutefois, il pourrait y avoir une portion de code commune que vous désirez voir appelée par certaines ou toutes les définitions des classes dérivées plutôt que de dupliquer ce code dans chaque fonction.
Voici à quoi ressemble la définition d'une fonction virtuelle pure :
//: C15:PureVirtualDefinitions.cpp
// Définition de base virtuelles pures
#include <iostream>
using namespace std;
class Pet {
public:
virtual void speak() const = 0;
virtual void eat() const = 0;
// Les définitions virtuelles pures inline sont prohibées :
//! virtual void sleep() const = 0 {}
};
// OK, pas définie inline
void Pet::eat() const {
cout << "Pet::eat()" << endl;
}
void Pet::speak() const {
cout << "Pet::speak()" << endl;
}
class Dog : public Pet {
public:
// Utilise le code Pet commun :
void speak() const { Pet::speak(); }
void eat() const { Pet::eat(); }
};
int main() {
Dog simba; // Le chien (Dog, ndt) de Richard
simba.speak();
simba.eat();
} ///:~L'emplacement dans la VTABLE de Pet est toujours vide, mais il se trouve qu'il y a une fonction de ce nom que vous pouvez appeler dans la classe dérivée.
L'autre bénéfice de cette fonctionnalité est qu'elle vous permet de passer de virtuel ordinaire à pur virtuel sans perturber le code existant. (C'est un moyen pour vous de détecter les classes qui ne surchargent pas cette fonction virtuelle.)
15.8. L'héritage et la VTABLE▲
Vous pouvez imaginer ce qu'il se passe quand vous faites hériter et que vous surchargez certaines fonctions virtuelles. Le compilateur crée une nouvelle VTABLE pour votre nouvelle classe, et il insère les adresses de vos nouvelles fonctions en utilisant les adresses des fonctions de la classe de base pour les fonctions virtuelles que nous ne surchargez pas. D'une manière ou d'une autre, pour tout objet qui peut être créé (c'est-à-dire que sa classe ne contient pas de virtuelle pure) il y a toujours un ensemble complet d'adresses de fonctions dans la VTABLE, si bien que vous ne pourrez jamais faire un appel à une adresse qui n'existe pas (ce qui serait un désastre).
Mais que se passe-t-il quand vous faites hériter et ajoutez de nouvelles fonctions virtuelles dans la classe dérivée? Voici un exemple simple :
//: C15:AddingVirtuals.cpp
// Ajouter des virtuels dans la dérivation
#include <iostream>
#include <string>
using namespace std;
class Pet {
string pname;
public:
Pet(const string& petName) : pname(petName) {}
virtual string name() const { return pname; }
virtual string speak() const { return ""; }
};
class Dog : public Pet {
string name;
public:
Dog(const string& petName) : Pet(petName) {}
// Nouvelle fonction virtuelle dans la clase Dog :
virtual string sit() const {
return Pet::name() + " sits";
}
string speak() const { // Surcharge
return Pet::name() + " says 'Bark!'";
}
};
int main() {
Pet* p[] = {new Pet("generic"),new Dog("bob")};
cout << "p[0]->speak() = "
<< p[0]->speak() << endl;
cout << "p[1]->speak() = "
<< p[1]->speak() << endl;
//! cout << "p[1]->sit() = "
//! << p[1]->sit() << endl; // Illegal
} ///:~La classe Pet contient deux fonctions virtuelles : speak( ) et name( ). Dog ajoute une troisième fonction virtuelle appelée sit( ), tout en surchargeant le sens de speak( ). Un diagramme vous aidera à visualiser ce qu'il se passe. Voici les VTABLE créées par le compilateur pour Pet et Dog:
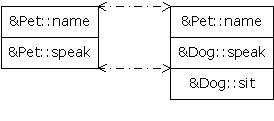
Notez que le compilateur indexe la localisation de l'adresse de speak( ) exactement au même endroit dans la VTABLE de Dog que dans celle de Pet. De même, si une classe Pug héritait de Dog, sa version de sit( ) serait placée dans sa VTABLE exactement à la même position que dans Dog. C'est parce que (comme vous l'avez vu avec l'exemple en langage assembleur) le compilateur génère du code qui utilise un simple décalage numérique dans la VTABLE pour sélectionner la fonction virtuelle. Indépendamment du sous-type spécifique auquel appartient l'objet, sa VTABLE est organisée de la même façon, donc les appels aux fonctions virtuelles seront toujours réalisés de manière similaire.
Dans ce cas, toutefois, le compilateur travaille seulement avec un pointeur vers un objet de la classe de base. La classe de base contient seulement les fonctions speak( ) et name( ), ainsi elles sont les seules fonctions que le compilateur vous autorisera à appeler. Comment pourrait-il bien savoir que vous travaillez avec un objet Dog, s'il a seulement un pointeur vers un objet de la classe de base ? Ce pointeur pourrait pointer vers quelqu'autre type, qui n'a pas de fonction sit( ). Il peut avoir ou ne pas avoir une autre adresse de fonction à cet endroit de la VTABLE, mais dans tous ces cas, faire un appel virtuel à cette adresse de la VTABLE n'est pas ce que vous voulez faire. Aussi, le compilateur fait son travail en vous empêchant de faire des appels virtuels à des fonctions qui n'existent que dans les classes dérivées.
Il y a des cas moins courants pour lesquels vous pouvez savoir que le pointeur pointe en fait vers un objet d'une sous-classe spécifique. Si vous voulez appeler une fonction qui n'existe que dans cette sous-classe, alors vous devez transtyper le pointeur. Vous pouvez supprimer le message d'erreur produit par le programme précédent de cette façon :
((Dog*)p[1])->sit()Ici, il se trouve que vous savez que p[1] pointe vers un objet Dog, mais en général vous ne savez pas cela. Si votre problème est tel que vous devez savoir le type exact de tous les objets, vous devriez le repenser, parce vous n'utilisez probablement pas les fonctions virtuelles correctement. Toutefois, il y a certaines situations dans lesquelles la conception fonctionne mieux (ou bien où vous n'avez pas le choix) si vous connaissez le type exact de tous les objets conservés dans un conteneur générique. C'est le problème de l' identification de type à l'exécution(RTTI : run-time type identification, ndt).
RTTI est entièrement basé sur le transtypage de pointeurs de la classe de base vers le bas en des pointeurs vers la classe dérivée (“vers le haut” ou “vers le bas” sont relatives à un diagramme de classe typique, avec la classe de base au sommet). Transtyper vers le haut a lieu automatiquement, sans forcer, parce que c'est complètement sûr. Transtyper vers le bas n'est pas sûr parce qu'il n'y a pas d'information à la compilation sur les types réels, si bien que vous devez savoir exactement de quel type est l'objet. Si vous le transtypez dans le mauvais type, vous aurez des problèmes.
La RTTI est décrite plus tard dans ce chapitre, et le Volume 2 de cet ouvrage contient un chapitre consacré à ce sujet.
15.8.1. Découpage d'objets en tranches▲
Il y a une différence réelle entre passer les adresses des objets et passer les objets par valeur quand on utilise le polymorphisme. Tous les exemples que vous avez vus ici, et à peu près tous les exemples que vous devriez voir, passent des adresses et non des valeurs. C'est parce que les adresses ont toutes la même taille (59), si bien que passer l'adresse d'un objet d'un type dérivé (qui est généralement un objet plus gros) revient au même que passer l'adresse d'un objet du type de base (qui est généralement un objet plus petit). Comme on l'a expliqué auparavant, c'est le but quand on utilise le polymorphisme – du code qui manipule un type de base peut manipuler également de manière transparente des objets de type dérivé.
Si vous upcastez vers un objet au lieu de le faire vers un pointeur ou une référence, il va se produire quelque chose qui peut vous surprendre : l'objet est “tranché” jusqu'à que les restes soient le sous-objet qui correspond au type de destination de votre transtypage. Dans l'exemple suivant vous pouvez voir ce qui arrive quand un objet est tranché :
//: C15:ObjectSlicing.cpp
#include <iostream>
#include <string>
using namespace std;
class Pet {
string pname;
public:
Pet(const string& name) : pname(name) {}
virtual string name() const { return pname; }
virtual string description() const {
return "This is " + pname;
}
};
class Dog : public Pet {
string favoriteActivity;
public:
Dog(const string& name, const string& activity)
: Pet(name), favoriteActivity(activity) {}
string description() const {
return Pet::name() + " likes to " +
favoriteActivity;
}
};
void describe(Pet p) { // Tranche l'objet
cout << p.description() << endl;
}
int main() {
Pet p("Alfred");
Dog d("Fluffy", "sleep");
describe(p);
describe(d);
} ///:~La fonction describe( ) reçoit un objet de type Petpar valeur. Elle appelle ensuite la fonction virtuelle description( ) pour l'objet Pet. Dans main( ), vous pouvez vous attendre à ce que le premier appel produise “This is Alfred”, et le second “Fluffy likes to sleep”. En fait, les deux appels utilisent la version de description( ) de la classe de base.
Deux choses se produisent dans ce programme. Premièrement, ârce que describe( ) accepte un objetPet(plutôt qu'un pointeur ou une référence), tous les appels à describe( ) vont causer la poussée d'un objet de la taille de Pet sur la pile et son nettoyage après l'appel. Cela veut dire que si un objet d'une classe dérivée de Pet est passé à describe( ), le compilateur l'accepte, mais il copie uniquement la portion Pet de l'objet. Il découpe la portion dérivée de l'objet, comme ceci :
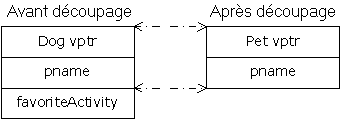
A présent, vous pouvez vous poser des questions concernant l'appel de la fonction virtuelle. Dog::description( ) utilise des éléments à la fois de Pet(qui existe toujours) et de Dog, qui n'existe plus parce qu'il a été découpé ! Alors que se passe-t-il quand la fonction virtuelle est appelée ?
Vous êtes sauvés du désastre parce que l'objet est passé par valeur. A cause de cela, le compilateur connaît le type précis de l'objet puisque l'objet dérivé a été contraint de devenir un objet de base. Quand on passe par valeur, le constructeur par recopie pour un objet Pet est utilisé, et il initialise le VPTR avec la VTABLE de Pet et ne copie que la portion Pet de l'objet. Il n'y a pas de constructeur par recopie explicite ici, donc le compilateur en synthétise un. A tout point de vue, l'objet devient vraiment un Pet pendant la durée de son découpage.
Le découpage d'objet supprime vraiment des parties de l'objet existant alors qu'il le copie dans le nouvel objet, plutôt que de changer simplement le sens d'une adresse comme quand on utilise un pointeur ou une référence. A cause de cela, upcaster vers un objet n'est pas une opération fréquente ; en fait, c'est généralement quelque chose à surveiller et éviter. Remarquez que dans cet exemple, si description( ) était une fonction virtuelle pure dans la classe de base (ce qui n'est pas absurde, puisqu'en fait elle ne fait rien dans la classe de base), alors le compilateur empêcherait le découpage de l'objet en tranches, parce que cela ne vous permettrait pas de “créer” un objet du type de base (ce qui se produit quand vous upcastez par valeur). C'est peut-être le plus grand intérêt des fonctions virtuelles pures : éviter le découpage d'objet en générant un message d'erreur à la compilation si quelqu'un essaie de le faire.
15.9. Surcharge & redéfinition▲
Dans le chapitre 14, vous avez vu que redéfinir une fonction surchargée dans la classe de base cache toutes les autres versions de cette fonction dans la classe de base. Quand il s'agit de fonctions virtual ce comportement est légerèment différent. Considérez une version modifiée de l'exemple NameHiding.cpp du chapitre 14 :
//: C15:NameHiding2.cpp
// Les fonctions virtuelles restreignent la redéfinition
#include <iostream>
#include <string>
using namespace std;
class Base {
public:
virtual int f() const {
cout << "Base::f()\n";
return 1;
}
virtual void f(string) const {}
virtual void g() const {}
};
class Derived1 : public Base {
public:
void g() const {}
};
class Derived2 : public Base {
public:
// Redéfinition d'une function virtuelle :
int f() const {
cout << "Derived2::f()\n";
return 2;
}
};
class Derived3 : public Base {
public:
// Ne peut pas changer le type de retour:
//! void f() const{ cout << "Derived3::f()\n";}
};
class Derived4 : public Base {
public:
// Changer la liste d'arguments :
int f(int) const {
cout << "Derived4::f()\n";
return 4;
}
};
int main() {
string s("hello");
Derived1 d1;
int x = d1.f();
d1.f(s);
Derived2 d2;
x = d2.f();
//! d2.f(s); // version string cachée
Derived4 d4;
x = d4.f(1);
//! x = d4.f(); // version f() cachée
//! d4.f(s); // version string cachée
Base& br = d4; // Upcast
//! br.f(1); // version dérivée non disponible
br.f(); // version de base disponible
br.f(s); // version de base disponible
} ///:~La première chose à noter est que dans Derived3, le compilateur ne vous autorisera pas à changer le type de retour d'une fonction surchargée (il le ferait si f( ) n'était pas virtuelle). Ceci est une restriction importante parce que le compilateur doit garantir que vous pouvez appeler polymorphiquement la fonction depuis la classe de base, car si la classe de base s'attend à ce que f( ) retourne un int, alors la version de f( ) dans la classe dérivée doit respecter ce contrat autrement il y aura des problèmes.
La règle présentée dans le chapitre 14 fonctionne toujours : si vous redéfinissez un des membres surchargés de la classe de base, les autres versions surchargées deviennent invisibles dans la classe dérivée. Dans main( ) le code qui teste Derived4 montre que ceci se produit même si la nouvelle version de f( ) ne redéfinit pas vraiment l'interface d'une fonction virtuelle existante – les deux versions de f( ) dans la classe de base sont masquées par f(int). Cependant, si vous transtypez d4 en Base, alors seulement les versions de la classe de base sont disponibles (parce que c'est ce que promet le contrat de la classe de base) et la version de la classe dérivée n'est pas disponible (parce qu'elle n'est pas spécifiée dans la classe de base).
15.9.1. Type de retour covariant▲
La classe Derived3 précédente suggère que vous ne pouvez pas modifier le type de retour d'une fonction virtuelle lors d'une redéfinition. Ceci est généralement vrai, mais il existe un cas particulier pour lequel vous pouvez légèrement modifier le type de retour. Si vous retournez un pointeur ou une référence sur une classe de base, alors la version redéfinie de cette fonction peut retourner un pointeur ou une référence sur une classe dérivée de celle retournée par la base. Par exemple :
//: C15:VariantReturn.cpp
// Reenvoyer un pointeur ou une référence vers un type derivé
// pendant la redéfiniton
#include <iostream>
#include <string>
using namespace std;
class PetFood {
public:
virtual string foodType() const = 0;
};
class Pet {
public:
virtual string type() const = 0;
virtual PetFood* eats() = 0;
};
class Bird : public Pet {
public:
string type() const { return "Bird"; }
class BirdFood : public PetFood {
public:
string foodType() const {
return "Bird food";
}
};
// Upcast vers le type de base :
PetFood* eats() { return &bf; }
private:
BirdFood bf;
};
class Cat : public Pet {
public:
string type() const { return "Cat"; }
class CatFood : public PetFood {
public:
string foodType() const { return "Birds"; }
};
// Renvoie le type exact à la place :
CatFood* eats() { return &cf; }
private:
CatFood cf;
};
int main() {
Bird b;
Cat c;
Pet* p[] = { &b, &c, };
for(int i = 0; i < sizeof p / sizeof *p; i++)
cout << p[i]->type() << " eats "
<< p[i]->eats()->foodType() << endl;
// peut renvoyer le type exact :
Cat::CatFood* cf = c.eats();
Bird::BirdFood* bf;
// ne peut pas renvoyer le type exact :
//! bf = b.eats();
// On doit transtyper :
bf = dynamic_cast<Bird::BirdFood*>(b.eats());
} ///:~La fonction membre Pet::eats( ) retourne un pointeur sur un PetFood. Dans Bird, cette fonction membre est surchargée exactement comme dans la classe de base, y compris au niveau du type de retour. Pour cette raison, Bird::eats( ) effectue un transtypage de BirdFood en un PetFood.
Mais dans Cat, le type de retour de eats( ) est un pointeur sur CatFood, un type dérivé de PetFood. Le fait que le type de retour soit hérité du type de retour de la fonction de la classe de base est l'unique raison qui permet à ce code de compiler. Car ce faisant, le contrat est toujours respecté; eats( ) continue de retourner un pointeur sur PetFood.
Si vous pensez polymorphiquement, ceci ne semble pas nécessaire. Pourquoi ne pas simplement transtyper tous les types de retour en PetFood*, comme l'a fait Bird::eats( )? C'est généralement une bonne solution, mais à la fin du main( ), vous pouvez voir la différence : Cat::eats( ) peut retourner le type exact de PetFood, alors que la valeur de retour de Bird::eats( ) doit être transtypée vers son type exact.
Ainsi, être capable de retourner le type exact est un petit peu plus général, et évite de perdre l'information sur le type exact à cause de transtypage automatique. Cependant, retourner le type de base va en général résoudre vos problèmes donc ceci est un dispositif plutôt spécialisé.
15.10. Fonctions virtuelles & constructeurs▲
Quand un objet contenant des fonctions virtuelles est créé, son VPTR doit être initialisé pour pointer vers la VTABLE adaptée. Ceci doit être fait avant qu'il n'y ait la moindre possibilité d'appeler une fonction virtuelle. Comme vous pouvez l'imaginer, comme le constructeur a la charge d'amener un objet à l'existence, c'est également le travail du constructeur d'initialiser le VPTR. Le compilateur insère secrètement du code au début du constructeur qui initialise le VPTR. Et, comme décrit au Chapitre 14, si vous ne créez pas explicitement un constructeur pour une classe, le compilateur en synthétisera un pour vous. Si la classe contient des fonctions virtuelles, le constructeur synthétisé incluera le code approprié d'initialisation du VPTR. Ceci a plusieurs implications.
La première concerne l'efficacité. La raison pour l'existence des fonctions inline est de réduire le surcoût de temps système de l'appel pour les petites fonctions. Si le C++ ne fournissait pas les fonctions inline, le préprocesseur pourrait être utilisé pour créer ces “macros”. Toutefois, le préprocesseur ne dispose pas des concepts d'accès ou de classes, et ainsi ne pourrait pas être utilisé pour créer des macros de fonctions membres. En outre, avec des constructeurs qui doivent avoir du code caché inséré par le compilateur, une macro du préprocesseur ne fonctionnerait pas du tout.
Vous devez être conscient, quand vous chassez des trous d'efficacité, que le compilateur insère du code caché dans votre fonction constructeur. Non seulement il doit initialiser le VPTR, mais il doit aussi vérifier la valeur de this(au cas où operator new retourne zéro) et appeler les constructeurs des classes de base. Le tout peut avoir un impact sur ce que vous pensiez être un petit appel à une fonction inline. En particulier, la taille du constructeur peut annihiler les économies que vous faisiez en réduisant le surcoût de temps de l'appel de la fonction. Si vous faites beaucoup d'appels inline au constructeur, la taille de votre code peut s'accroître sans aucun bénéfice de vitesse.
Bien sûr, vous ne rendrez probablement tous les petits constructeurs non-inline immédiatement, parce qu'il sont beaucoup plus faciles à écrire quand ils sont inline. Mais quand vous réglez votre code, souvenez-vous d'envisager à supprimer les constructeurs inline.
15.10.1. Ordre des appels au constructeur▲
La deuxième facette intéressante des constructeurs et fonctions virtuelles concerne l'ordre des appels au constructeur et la façon dont les appels virtuels sont réalisés au sein des constructeurs.
Tous les constructeurs des classes de base sont toujours appelés dans le constructeur pour une classe héritée. C'est logique parce que le constructeur a un travail spécial : s'assurer que l'objet est construit correctement. Une classe dérivée a uniquement accès à ses propres membres, et pas à ceux de la classe de base. Seul, le constructeur de la classe de base peut initialiser proprement ses propres éléments. De ce fait, il est essentiel que tous les constructeurs soient appelés ; autrement, l'objet dans son ensemble ne serait pas correctement construit. C'est pourquoi le compilateur impose un appel au constructeur pour chaque portion d'une classe dérivée. Il appellera le constructeur par défaut si vous n'appelez pas explicitement un constructeur de la classe de base dans la liste d'initialisation du constructeur. S'il n'y a pas de constructeur par défaut, le compilateur se plaindra.
L'ordre des appels au constructeur est important. Quand vous héritez, vous savez tout ce qui concerne la classe de base et vous pouvez accéder à tout membre public et protected de la classe de base. Ceci signifie que vous devez pouvoir émettre l'hypothèse que tous les membres de la classe de base sont valides quand vous vous trouvez dans la classe dérivée. Dans une fonction membre normale, la construction a déjà eu lieu, si bien que tous les membres de toutes les parties de l'objet ont été construits. Dans le constructeur, toutefois, vous devez pouvoir supposer que tous les membres que vous utilisez ont été construits. La seule façon de le garantir est que le constructeur de la classe de base soit appelé en premier. Ainsi, quand vous vous trouvez dans le constructeur de la classe dérivée, tous les membres de classe de base auxquels vous pouvez accéder ont été initialisés. “Savoir que tous les membres sont valides” au sein du constructeur est également la raison pour laquelle, à chaque fois que c'est possible, vous devriez initialiser tous les objets membres (c'est-à-dire, les objets placés dans la classe en utilisant la composition) dans la liste d'initialisation du constructeur. Si vous suivez cette pratique, vous pouvez faire l'hypothèse que tous les membres des classes de base et les objets membres de l'objet courant ont été initialisés.
15.10.2. Comportement des fonctions virtuelles dans les constructeurs▲
La hiérarchie des appels de constructeurs soulève un dilemme intéressant. Que se passe-t-il si vous vous trouvez dans un constructeur et que vous appelez une fonction virtuelle ? Dans une fonction membre ordinaire vous pouvez imaginer ce qui va se produire – l'appel virtuel est résolu à l'exécution parce que l'objet ne peut pas savoir s'il appartient à la classe dans laquelle se trouve la fonction membre, ou bien à une classe dérivée de celle-ci. Pour des raisons de cohérence, vous pourriez penser que c'est ce qui devrait se produire dans les constructeurs.
Ce n'est pas le cas. Si vous appelez une fonction virtuelle dans un constructeur, seule la version locale de la fonction est utilisée. C'est-à-dire que le mécanisme virtuel ne fonctionne pas au sein du constructeur.
Ce comportement est logique pour deux raisons. Conceptuellement, le travail du constructeur est d'amener l'objet à l'existence (ce qui est à peine un exploit ordinaire). Dans tout constructeur, l'objet peut être seulement partiellement formé – tout ce que vous pouvez savoir c'est que les objets de la classe de base ont été initialisés, mais vous ne pouvez pas savoir quelles classes héritent de vous. Un appel à une fonction virtuelle, toutefois, porte “au-delà” ou “en dehors” dans la hiérarchie d'héritage. Il appelle une fonction située dans une classe dérivée. Si pouviez faire cela dans un constructeur, vous pourriez appeler une fonction qui risquerait de manipuler des membres qui n'ont pas encore été initialisés, recette qui garantit le désastre.
La deuxième raison est mécanique. Quand un constructeur est appelé, une des premières choses qu'il fait est d'initialiser son VPTR. Toutefois, tout ce qu'il peut savoir c'est qu'il est du type “courant” – le type pour lequel le constructeur a été écrit. Le code du constructeur est incapable de savoir si l'objet est à la base d'une autre classe ou pas. Quand le compilateur génère le code pour ce constructeur, il génère le code pour un constructeur de cette classe, pas une classe de base ni une classe dérivée de celle-ci (parce qu'une classe ne peut pas savoir qui hérite d'elle). Ainsi, le VPTR qu'il utilise doit être pour la VTABLE de cette classe. Le VPTR demeure initialisé à cette VTABLE pour le reste de la vie de cet objet à moins que ce ne soit pas le dernier appel au constructeur. Si un constructeur plus dérivé est appelé par la suite, ce constructeur initialise le VPTR à sa VTABLE, et ainsi de suite, jusqu'à ce que le dernier constructeur se termine. L'état du VPTR est déterminé par le constructeur qui est appelé en dernier. C'est une autre raison pour laquelle les constructeurs sont appelés dans l'ordre de la base vers le plus dérivé.
Mais pendant que cette série d'appels aux constructeurs a lieu, chaque constructeur a initialisé le VPTR à sa propre VTABLE. S'il utilise le mécanisme virtuel pour les appels de fonctions, il ne produira qu'un appel à travers sa propre VTABLE, pas la VTABLE la plus dérivée (comme ce serait le cas après que tous les constructeurs aient été appelés). En outre, beaucoup de compilateurs reconnaissent quand une fonction virtuelle est appelée dans un constructeur, et réalisent une liaison précoce parce qu'ils savent qu'une liaison tardive produira seulement un appel vers la fonction locale. Dans un cas comme dans l'autre, vous n'obtiendrez pas le résultat que vous pouviez attendre initialement d'un appel à une fonction virtuelle dans un constructeur.
15.11. Destructeurs et destructeurs virtuels▲
Vous ne pouvez pas utiliser le mot-clef virtual avec les constructeurs, mais les destructeurs, eux, peuvent et souvent doivent être virtuels.
Au constructeur incombe la tâche particulière d'assembler un objet morceau par morceau, d'abord en appelant le constructeur de base, puis les constructeurs dérivés dans l'ordre d'héritage (il doit également appeler les constructeurs des objets membres dans le même temps). De la même façon, le destructeur a un travail spécial : il doit désassembler un objet qui peut appartenir à une hiérarchie de classes. Pour ce faire, le compilateur génère du code qui appelle les destructeurs, mais dans l'ordre inverse de l'appel des constructeurs lors de la création. C'est-à-dire que le destructeur démarre par la classe la plus dérivée et trace sa route vers le bas de la hiérarchie, jusqu'à la classe de base. C'est la démarche fiable et donc désirable parce que le constructeur courant peut toujours savoir que les membres de la classe de base sont vivants et actifs. Si vous avez besoin d'appeler une fonction membre de la classe de base dans votre destructeur, cette façon de procéder est sûre. Ainsi, le destructeur peut réaliser son propre nettoyage, puis appeler le destructeur sous-jacent, qui réalisera son propre nettoyage, etc. Chaque destructeur sait de quoi dérive sa classe, mais pas ce qui dérive d'elle.
Vous devriez toujours garder à l'esprit que les constructeurs et les destructeurs sont les seuls endroits où cette hiérarchie d'appels doit se produire (et de ce fait, la hiérarchie appropriée est générée par le compilateur). Dans toutes les autres fonctions, seule cette fonction sera appelée (et pas les versions de la classe de base), qu'elle soit virtuelle ou non. La seule façon de provoquer un appel à la version de la classe de base d'une fonction (virtuelle ou non) est que vous appeliez explicitement cette fonction.
Normalement, l'action du destructeur est assez adéquate. Mais que se passe-t-il si vous voulez manipuler un objet via un pointeur vers sa classe de base (c'est-à-dire que vous manipulez l'objet via son interface générique) ? Cette activité est un objetctif majeur en programmation orientée objet. Le problème apparaît quand vous voulez détruire ( delete, ndt) un pointeur de ce type pour un objet qui a été créé sur le tas avec new. Si le pointeur pointe vers la classe de base, le compilateur ne peut avoir conscience que de la nécessité d'appeler la version de la classe de base du destructeur pendant la destruction par delete. Cela a l'air familier ? C'est le même problème que les fonctions virtuelles ont permis de résoudre dans le cas général. Heureusement, les fonctions virtuelles fonctionnent pour les destructeurs comme elles le font pour toutes les autres fonctions, excepté les constructeurs.
//: C15:VirtualDestructors.cpp
// Comportement du destructeur virtuel vs. non-virtuel
#include <iostream>
using namespace std;
class Base1 {
public:
~Base1() { cout << "~Base1()\n"; }
};
class Derived1 : public Base1 {
public:
~Derived1() { cout << "~Derived1()\n"; }
};
class Base2 {
public:
virtual ~Base2() { cout << "~Base2()\n"; }
};
class Derived2 : public Base2 {
public:
~Derived2() { cout << "~Derived2()\n"; }
};
int main() {
Base1* bp = new Derived1; // Upcast
delete bp;
Base2* b2p = new Derived2; // Upcast
delete b2p;
} ///:~Quand vous exécuterez le programme, vous verrez que delete bp appelle seulement le destructeur de la classe de base, alors que delete b2p appelle le destructeur de la classe dérivée suivi par le destucteur de la classe de base, qui est le comportement que nous recherchons. Oublier de rendre un destructeur virtual constitue un bug insidieux parce que souvent il n'affecte pas directement le comportement de votre programme, mais peut introduire discrètement une fuite de mémoire. En outre, le fait qu'un peu de destruction ait lieu peut encore plus masquer le problème.
Même si le destructeur, comme le constructeur, est une fonction “exceptionnelle”, il est possible que le destructeur soit virtuel parce que l'objet sait déjà de quel type il est (alors qu'il ne le sait pas durant la construction). Une fois qu'un objet a été construit, sont VPTR est initialisé, et les appels aux fonctions virtuelles peuvent avoir lieu.
15.11.1. Destructeurs virtuels purs▲
Alors que les destructeurs virtuels purs sont licites en C++ standard, il y a une contrainte supplémentaire quand on les utilise : il faut fournir un corps de fonction pour le destructeur virtuel pur. Ceci a l'air contre intuitif ; comment une fonction virtuelle peut-elle être “pure” si elle a besoin d'un corps de fonction ? Mais si vous gardez à l'esprit que les destructeurs et les constructeurs sont des fonctions spéciales cela paraît plus logique, spécialement si vous vous souvenez que tous les destructeurs dans une hiérarchie de classe sont toujours appelés. Si vous pouviez ne pas donner une définition pour un destructeur virtuel pur, quel corps de fonction serait appelé pendant la destruction ? Ainsi, il est absolument nécessaire que le compilateur et l'éditeur de liens imposent l'existence d'un corps de fonction pour un destructeur virtuel pur.
S'il est pur, mais doit avoir un corps de fonction, quel est l'avantage ? La seule différence que vous verrez entre un destructeur virtuel pur ou non pur est que le destructeur virtuel pur rend la classe de base abstraite pure, si bien que vous ne pouvez pas créer un objet de la classe de base (ceci-dit, ce serait également vrai si n'importe quelle autre fonction membre de la classe de base était virtuelle pure).
Les choses deviennent un peu confuses, toutefois, quand une classe hérite d'une classe qui contient un destructeur virtuel pur. Contrairement à toute autre fonction virtuelle pure, il ne vous est pas imposé de fournir la définition d'un destructeur virtuel pur dans la classe dérivée. Le fait que ce qui suit peut être compilé et lié le démontre :
//: C15:UnAbstract.cpp
// Destructeurs virtuels purs
// semble se comporter étrangement
class AbstractBase {
public:
virtual ~AbstractBase() = 0;
};
AbstractBase::~AbstractBase() {}
class Derived : public AbstractBase {};
// Pas de redéfinition nécessaire du destructeur ?
int main() { Derived d; } ///:~Normalement, une fonction virtuelle pure dans une classe de base rendrait la classe dérivée abstraite à moins qu'elle (et toutes les autres fonctions virtuelles pures) reçoive une définition. Mais ici, cela ne semble pas être le cas. Toutefois, rappelez-vous que le compilateur crée automatiquement une définition du destructeur pour chaque classe si vous n'en créez pas un vous-même. C'est ce qu'il se produit ici – le destructeur de la classe de base est discrètement redéfini, et ainsi la définition se trouve fournie par le compilateur et Derived n'est de fait pas abstraite.
Ceci soulève une question intéressante : quel est l'intérêt d'un destructeur virtuel pur ? Contrairement à une fonction virtuelle pure ordinaire, vous devez lui donner un corps de fonction. Dans une classe dérivée, vous n'êtes pas obligés de fournir une définition puisque le compilateur synthétise le destructeur pour vous. Quelle est donc la différence entre un destructeur virtuel ordinaire et un destructeur virtuel pur ?
La seule différence se manifeste quand vous avez une classe qui n'a qu'une seule fonction virtuelle pure : le destructeur. Dans ce cas, le seul effet de la pureté du destructeur est d'éviter l'instanciation de la classe de base. Si n'importe quelle autre fonction virtuelle était pure, elle éviterait l'instanciation de la classe de base, mais s'il n'y en a pas d'autre, alors le destructeur virtuel pur le fera. Ainsi, alors que l'addition d'un destructeur virtuel est essentielle, qu'il soit pur ou non n'est pas tellement important.
Quand vous exécutez l'exemple suivant, vous pouvez constater que le corps de la fonction virtuelle pure est appelé après la version de la classe dérivée, exactement comme avec tout autre destructeur :
//: C15:PureVirtualDestructors.cpp
// Destructeurs virtuels purs
// requiert un corps de fonction
#include <iostream>
using namespace std;
class Pet {
public:
virtual ~Pet() = 0;
};
Pet::~Pet() {
cout << "~Pet()" << endl;
}
class Dog : public Pet {
public:
~Dog() {
cout << "~Dog()" << endl;
}
};
int main() {
Pet* p = new Dog; // Transtypage ascendant
delete p; // Appel au destructeur virtuel
} ///:~Comme principe général, à chaque fois que vous avez une fonction virtuelle dans une classe, vous devriez ajouter immédiatement un destructeur virtuel (même s'il ne fait rien). De cette façon, vous vous immunisez contre des surprises ultérieures.
15.11.2. Les virtuels dans les destructeurs▲
Il y a quelque chose qui se produit pendant la destruction à laquelle vous pouvez ne pas vous attendre immédiatement. Si vous êtes dans une fonction membre ordinaire et que vous appelez une fonction virtuelle, cette fonction est appelée en utilisant le mécanisme de liaison tardive. Ce n'est pas vrai avec les destructeurs, virtuels ou non. Dans un destructeur, seule, la version “locale” de la fonction membre est appelée ; le mécanisme virtuel est ignoré.
//: C15:VirtualsInDestructors.cpp
// Appels virtuels dans les destructeurs
#include <iostream>
using namespace std;
class Base {
public:
virtual ~Base() {
cout << "Base1()\n";
f();
}
virtual void f() { cout << "Base::f()\n"; }
};
class Derived : public Base {
public:
~Derived() { cout << "~Derived()\n"; }
void f() { cout << "Derived::f()\n"; }
};
int main() {
Base* bp = new Derived; // Transtypage ascendant
delete bp;
} ///:~Pendant l'appel au destructeur, Derived::f( )n' est pas appelée, même si f( ) est virtuelle.
Pourquoi cela ? Supposez que le mécanisme virtuel soit utilisé dans le destructeur. Il serait alors possible pour l'appel virtuel de résoudre vers une fonction qui se trouvait “plus bas” (plus dérivée) dans la hiérarchie de l'héritage que le destructeur courant. Mais les destructeurs sont appelés depuis “plus haut” (depuis le destructeur le plus dérivé vers le destructeur de base), si bien que la fonction réellement appelée reposerait sur des portions d'objet qui ont déjà été détruites! Au lieu de cela, le compilateur résoud les appels à la compilation et n'appelle que la version “locale” de la fonction. Notez que c'est la même chose pour le constructeur (comme cela a été décrit ci-dessus), mais dans le cas du constructeur l'information de type n'était pas disponible, alors que dans le destructeur l'information (c'est-à-dire le VPTR) est présente, mais n'est pas fiable.
15.11.3. Créer une hiérarchie basée sur objet▲
Un problème récurrent dans ce livre pendant la démonstration des classes de conteneurs Stack et Stash est celui de la “propriété”. Le “propriétaire” fait référence ce qui est responsable de l'appel de delete pour les objets qui ont été créés dynamiquement (en utilisant new). Le problème quand on utilise des conteneurs est qu'ils doivent être suffisamment flexibles pour contenir différents types d'objets. Pour ce faire, les conteneurs contiennent des pointeurs void et ne connaissent donc pas le type de l'objet qu'ils ont contenu. Effacer un pointeur void n'appelle pas le destructeur, et le conteneur ne peut donc pas être responsable du nettoyage de ses objets.
Une solution a été présentée dans l'exemple C14:InheritStack.cpp, dans lequel la Stack était héritée dans une nouvelle classe qui acceptait et produisait uniquement des pointeurs string. Comme elle savait qu'elle ne pouvait contenir que des pointeurs vers des objets string, elle pouvait les effacer proprement. C'était une bonne solution, mais qui vous imposait d'hériter une nouvelle classe de conteneur pour chaque type que vous voulez contenir dans le conteneur. (Bien que cela semble fastidieux pour le moment, cela fonctionnera plutôt bien au Chapitre 16, quand les templates seront introduits.)
Le problème est que vous voulez que le conteneur contienne plus d'un type, mais vous ne voulez pas utiliser des pointeurs void. Une autre solution consiste à utiliser le polymorphisme en forçant tous les objets inclus dans le conteneur à être hérités de la même classe de base. C'est-à-dire que le conteneur contient les objets de la classe de base, et qu'ensuite vous pouvez appeler les fonctions virtuelles – notamment, vous pouvez appeler les destructeurs virtuels pour résoudre le problème de la propriété.
Cette solution utilise ce que l'on appelle une hiérarchie à racine unique ou une hiérarchie basée sur objet(parce que la classe racine de la hiérarchie est généralement appelée “Object”). Il s'avère qu'il y a beaucoup d'autres avantages à utiliser une hiérarchie à racine unique ; en fait, tous les autres langages orientés objet sauf le C++ imposent l'utilisation d'une telle hiérarchie – quand vous créez une classe, vous l'héritez automatiquement soit directement soit indirectement d'une classe commune, classe de base qui a été établie par le créateur du langage. En C++, on a considéré que l'usage imposé de cette classe de base commune coûterait trop de temps système, et elle a été abandonnée. Toutefois, vous pouvez choisir d'utiliser une classe de base comune dans vos propres projets, et ce sujet sera examiné plus en détails dans le Volume 2 de ce livre.
Pour résoudre le problème de la propriété, nous pouvons créer un Object extrêmement simple pour la classe de base, qui contient uniquement un destructeur virtuel. La Stack peut alors contenir des classes héritées d' Object:
//: C15:OStack.h
// Utiliser une hiérarchie à racine unique
#ifndef OSTACK_H
#define OSTACK_H
class Object {
public:
virtual ~Object() = 0;
};
// Définition requise :
inline Object::~Object() {}
class Stack {
struct Link {
Object* data;
Link* next;
Link(Object* dat, Link* nxt) :
data(dat), next(nxt) {}
}* head;
public:
Stack() : head(0) {}
~Stack(){
while(head)
delete pop();
}
void push(Object* dat) {
head = new Link(dat, head);
}
Object* peek() const {
return head ? head->data : 0;
}
Object* pop() {
if(head == 0) return 0;
Object* result = head->data;
Link* oldHead = head;
head = head->next;
delete oldHead;
return result;
}
};
#endif // OSTACK_H ///:~Pour simplifier les choses en conservant tout dans le fichier d'en-tête, la définition (requise)du destructeur virtuel pur est inlinée dans le fichier d'en-tête, et pop( )(qui peut être considérée trop grande pour être inline) est également inlinée.
Les objets Link contiennent maintenant des pointeurs vers Objet plutôt que des pointeurs void, et la Stack acceptera et retournera uniquement des pointeurs Object. Maintenant, Stack est bien plus flexible, puisqu'elle contiendra beaucoup de types différents mais détruira également tout objet qui sont laissés dans la Stack. La nouvelle limitation (qui sera finalement dépassée quand les templates seront appliqués au problème dans le Chapitre 16) est que tout ce qui est placé dans Stack doit hériter d' Object. C'est valable si vous créer votre classe à partir de zéro, mais que faire si vous disposez déjà d'une classe telle que string que vous voulez être capable de mettre dans Stack? Dans ce cas, la nouvelle classe doit être les deux : string et Object, ce qui signifie qu'elle doit hériter des deux classes. On appelle cela l' héritage multiple et c'est le sujet d'un chapitre entier dans le Volume 2 de ce livre (téléchargeable depuis www.BruceEckel.com). Quand vous lirez ce chapitre, vous verrez que l'héritage multiple peut être très complexe, et c'est une fonctionnalité que vous devriez utiliser avec parcimonie. Dans cette situation, toutefois, tout est suffisamment simple pour que nous ne tombions dans aucun piège de l'héritage multiple :
//: C15:OStackTest.cpp
//{T} OStackTest.cpp
#include "OStack.h"
#include "../require.h"
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
// Utilise l'héritage multiple. Nous voulons à la fois
// un string et un Object :
class MyString: public string, public Object {
public:
~MyString() {
cout << "deleting string: " << *this << endl;
}
MyString(string s) : string(s) {}
};
int main(int argc, char* argv[]) {
requireArgs(argc, 1); // Le nom de fichier (File Name) est un argument
ifstream in(argv[1]);
assure(in, argv[1]);
Stack textlines;
string line;
// Lit le fichier et stocke les lignes dans la stack :
while(getline(in, line))
textlines.push(new MyString(line));
// Dépile des lignes de la stack :
MyString* s;
for(int i = 0; i < 10; i++) {
if((s=(MyString*)textlines.pop())==0) break;
cout << *s << endl;
delete s;
}
cout << "Letting the destructor do the rest:"
<< endl;
} ///:~Bien que ce soit similaire à la version précédente du programme test pour Stack, vous remarquerez que seuls 10 éléments sont dépilés de la pile (stack, ndt), ce qui signifie qu'il y a probablement des objets qui restent dedans. Comme la Stack sait qu'elle contient des Object, le destructeur peut nettoyer les choses proprement, et vous le verrez dans la sortie du programme, puisque les objets MyString impriment des messages lorsqu'ils sont détruits.
Créer des conteneurs qui contiennt des Object n'est pas une approche déraisonnable – si vous avez une hiérarchie à racine unique (imposée soit par le langage ou par la condition que toute classe hérite d' Object). Dans ce cas, il est garantit que tout soit un Object et il n'est donc pas très compliqué d'utiliser les conteneurs. En C++, toutefois, vous ne pouvez pas vous attendre à ce que ce soit le cas pour toutes les classes, et vous êtes donc obligés d'affronter l'héritage multiple si vous prenez cette approche. Vous verrez au Chapitre 16 que les templates résolvent ce problème d'une manière beaucoup plus simple et plus élégante.
15.12. Surcharge d'opérateur▲
Vous pouvez rendre les opérateurs virtuels exactement comme les autres fonctions membres. Implémenter des opérateurs virtuels devient souvent déroutant, toutefois, parce que vous pouvez manipuler deux objets, chacun d'un type inconnu. C'est généralement le cas avec les composants mathématiques (pour lesquels vous surchargez souvent les opérateurs). Par exemple, considérez un système qui traite de matrices, de vecteurs et de valeurs scalaires, toutes les trois étant dérivées de la classe Math:
//: C15:OperatorPolymorphism.cpp
// Polymorphisme avec des opérateurs surchargés
#include <iostream>
using namespace std;
class Matrix;
class Scalar;
class Vector;
class Math {
public:
virtual Math& operator*(Math& rv) = 0;
virtual Math& multiply(Matrix*) = 0;
virtual Math& multiply(Scalar*) = 0;
virtual Math& multiply(Vector*) = 0;
virtual ~Math() {}
};
class Matrix : public Math {
public:
Math& operator*(Math& rv) {
return rv.multiply(this); // 2ème répartition
}
Math& multiply(Matrix*) {
cout << "Matrix * Matrix" << endl;
return *this;
}
Math& multiply(Scalar*) {
cout << "Scalar * Matrix" << endl;
return *this;
}
Math& multiply(Vector*) {
cout << "Vector * Matrix" << endl;
return *this;
}
};
class Scalar : public Math {
public:
Math& operator*(Math& rv) {
return rv.multiply(this); // 2ème répartition
}
Math& multiply(Matrix*) {
cout << "Matrix * Scalar" << endl;
return *this;
}
Math& multiply(Scalar*) {
cout << "Scalar * Scalar" << endl;
return *this;
}
Math& multiply(Vector*) {
cout << "Vector * Scalar" << endl;
return *this;
}
};
class Vector : public Math {
public:
Math& operator*(Math& rv) {
return rv.multiply(this); // 2ème répartition
}
Math& multiply(Matrix*) {
cout << "Matrix * Vector" << endl;
return *this;
}
Math& multiply(Scalar*) {
cout << "Scalar * Vector" << endl;
return *this;
}
Math& multiply(Vector*) {
cout << "Vector * Vector" << endl;
return *this;
}
};
int main() {
Matrix m; Vector v; Scalar s;
Math* math[] = { &m, &v, &s };
for(int i = 0; i < 3; i++)
for(int j = 0; j < 3; j++) {
Math& m1 = *math[i];
Math& m2 = *math[j];
m1 * m2;
}
} ///:~Pour simplifier, seul operator* a été surchargé. Le but est d'être capable de multiplier n'importe quel couple d'objets Math et de produire le résultat désiré – et notez que multiplier un vecteur par une matrice est une opération très différente de la multiplication d'une matrice par un vecteur.
Le problème est que, dans main( ), l'expression m1 * m2 contient deux références vers Math upcastées, et donc deux objets de type inconnu. Une fonction virtuelle n'est capable de réaliser qu'une seule répartition – c'est-à-dire déterminer le type d'un seul objet inconnu. Pour déterminer le type des deux objets une technique baptisée répartition multiple est utilisée dans cet exemple, par laquelle ce qui semble être un appel unique à une fonction virtuelle résulte en un deuxième appel à une fonction virtuelle. Lorsque ce deuxième appel est effectué, vous avez déterminé le type des deux objets, et pouvez accomplir l'action appropriée. Ce n'est pas transparent à première vue, mais si vous examinez cet exemple quelque temps cela devrait commencer à prendre du sens. Ce sujet est exploré plus en profondeur dans le chapitre sur les Design Pattern dans le Volume 2, que vous pouvez télécharger sur www.BruceEckel.com(et bientôt www.developpez.com, ndt).
15.13. Transtypage descendant▲
Vous pouvez le deviner, comme il existe une chose telle que le transtypage ascendant – monter d'un degré dans la hiérarchie de l'héritage – il devait également y avoir un transtypage descendant pour descendre cette même hiérarchie. Mais le transtypage ascendant est facile puisque comme vous remontez la hiérarchie d'héritage les classes convergent toujours vers des classes plus générales. C'est-à-dire que quand vous réalisez un transtypage ascendant vous êtes toujours clairement dérivé d'une classe ancestrale (typiquement une seule, sauf dans le cas de l'héritage multiple)mais quand vous transtypez de manière descendante il y a généralement plusieurs possibilités vers lesquelles vous pouvez transtyper. Plus précisément, un Circle(cercle, ndt) est un type de Shape(forme, ndt) (transtypage ascendant), mais si vous essayez de transtyper un Shape en descendant cela pourrait être un Circle, un Square(carré, ndt), un Triangle, etc. Le dilemme est alors de trouver une manière sûre de réaliser le transtypage descendant. (Mais un problème encore plus important est de vous demander avant tout pourquoi vous avez besoin de le faire au lieu d'utiliser simplement le polymorphisme pour deviner automatiquement le type correct. La manière d'éviter le transtypage descendant est abordé dans le Volume 2 de ce livre.)
Le C++ fournit un transtypage explicite spécial (introduit au Chapitre 3) appelé dynamic_cast qui est une opération de transtypage descendant fiable. Quand vous utilisez le dynamic_cast pour essayer de transtyper de manière descendante vers un type particulier, la valeur de retour sera un pointeur vers le type désiré uniquement si le transtypage est propre et a réussi, autrement cela retournera un zéro pour indiquer que ce n'était pas le type correct. Voici un petit exemple :
//: C15:DynamicCast.cpp
#include <iostream>
using namespace std;
class Pet { public: virtual ~Pet(){}};
class Dog : public Pet {};
class Cat : public Pet {};
int main() {
Pet* b = new Cat; // Transtypage ascendant
// Essaye de le transtyper en Dog* :
Dog* d1 = dynamic_cast<Dog*>(b);
// Essaye de le transtyper en Cat* :
Cat* d2 = dynamic_cast<Cat*>(b);
cout << "d1 = " << (long)d1 << endl;
cout << "d2 = " << (long)d2 << endl;
} ///:~Quand vous utilisez dynamic_cast, vous devez travailler ave une hiérarchie polymorphique vraie – qui contient des fonctions virtuelles – parce que le dynamic_cast utilise des informations stockées dans la VTABLE pour déterminer le type réel. Ici, la classe de base contient un destructeur virtuel et cela suffit. Dans main( ), un pointeur Cat est transtypé en un Pet(transtypage ascendant), puis on tente un transtypage descendant vers un pointeur Dog et un pointeur Cat. Les deux pointeurs sont imprimés, et vous verrez quand vous exécuterez le programme que le transtypage descendant incorrect produit un résultat nul. Bien sûr, à chaque fois que vous réalisez un transtypage descendant vous avez la charge de vérifier que le résultat de l'opération n'est pas nul. Vous ne deriez également pas supposer que le pointeur sera exactement identique, parce qu'il arrive que des ajustements de pointeur se réalisent pendant les transtypages ascendant et descendant (en particulier avec l'héritage multiple).
Un dynamic_cast requiert un peu de temps système supplémentaire pour s'exécuter ; pas beaucoup, mais si vous réalisez de nombreux dynamic_cast(auquel cas vous devriez sérieusement remettre en cause votre conception) cela peut devenir un probème en terme de performance. Dans certains cas, vous pouvez savoir quelque chose de précis pendant le transtypage descendant qui vous permette de dire à coup sûr à quel type vous avez à faire, et dans ce cas le temps supplémentaire du dynamic_cast n'est plus nécessaire et vous pouvez utiliser un static_cast à sa place. Voici un exemple montrant comment cela peut marcher :
//: C15:StaticHierarchyNavigation.cpp
// Naviguer dans la hiérarchie de classe avec static_cast
#include <iostream>
#include <typeinfo>
using namespace std;
class Shape { public: virtual ~Shape() {}; };
class Circle : public Shape {};
class Square : public Shape {};
class Other {};
int main() {
Circle c;
Shape* s = &c; // Transtypage ascendant : normal et OK
// Plus explicite mais pas nécessaire :
s = static_cast<Shape*>(&c);
// (Comme le transtypage ascendant est un opération sûre et
// courante, le transtypage devient encombrant)
Circle* cp = 0;
Square* sp = 0;
// Navgation statique dans les hiérarchies de classes
// requiert un type d'information supplémentaire :
if(typeid(s) == typeid(cp)) // RTTI C++
cp = static_cast<Circle*>(s);
if(typeid(s) == typeid(sp))
sp = static_cast<Square*>(s);
if(cp != 0)
cout << "It's a circle!" << endl;
if(sp != 0)
cout << "It's a square!" << endl;
// La navigation statique est SEULEMENT un hack d'efficacité ;
// le dynamic_cast est toujours plus sûr. Toutefois :
// Other* op = static_cast<Other*>(s);
// Donne de manière appropriée un message d'erreur, alors que
Other* op2 = (Other*)s;
// ne le fait pas
} ///:~Dans ce programme, une nouvelle fonctionnalité est utilisée que l'on ne décrira pas complètement avant le Volume 2 de ce livre, où un chapitre est consacré au sujet du mécanisme d' information de type à l'exécution( run-time type information, ndt, ou RTTI) du C++. Le RTTI vous permet de découvrir une information de type qui a été perdu par le transtypage ascendant. Le dynamic_cast est en fait une forme de RTTI. Ici, le mot-clef typeid(déclaré dans le fichier d'en-tête <typeinfo>) est utilisé pour détecter les types des pointeurs. Vous pouvez constater que le type du pointeur Shape transtypé vers le haut est successivement comparé à un pointeur Circle et à un pointeur Square pour voir s'il y a correspondance. Le RTTI contient plus de choses que seulement typeid, et vous pouvez aussi imaginer qu'il serait relativement facile d'implémenter votre propre système d'information de type en utilisant une fonction virtuelle.
Un objet Circle est créé et une opération de transtypage ascendant est réalisée vers un pointeur Shape; la deuxième version de l'expression montre comment utiliser static_cast pour être plus explicite en ce qui concerne le transtypage ascendant. Toutefois, comme un transtypage ascendant est toujours fiable et que c'est une opération courante, je considère qu'un transtypage explicite n'est dans ce cas pas nécessaire et se révèle encombrant.
Le RTTI est utilisé pour déterminer le type, puis static_cast est utilisé pour réaliser le transtypage descendant. Remarquez toutefois quand dans cette approche le processus est en fait le même que quand on utilise dynamic_cast, et le programmeur client doit faire des tests pour découvrir le transtypage qui a vraiment réussi. Typiquement, vous aurez intérêt à vous trouver dans une situation plus déterministe que l'exemple ci-dessus avant d'utiliser static_cast de préférence à dynamic_cast(et, encore une fois, vous avez intérêt à examiner soigneusement votre conception avant d'utiliser dynamic_cast).
Si une hiérarchie de classes n'a pas de fonctions virtuelles (ce qui est une conception discutable) ou si vous avez une autre information qui vous permet de réaliser un transtypage descendant fiable, il est un peu plus rapide de réaliser le transtypage avec static_cast plutôt qu'avec dynamic_cast. En outre, static_cast ne vous permettra pas de transtyper hors de la hiérarchie, comme le transtypage traditionnel laisserait faire, et est donc plus sûr. Toutefois, naviguer dans la hiérarchie des classes en statique est toujours risqué et vous devriez utiliser dynamic_cast à moins que vous ne vous trouviez dans une situation spéciale.
15.14. Résumé▲
Le polymorphisme – implémenté en C++ à l'aide des fonctions virtuelles – signifie “formes variées”. Dans la programmation orientée objet, vous avez le même visage (l'interface commune dans la classe de base) et plusieurs formes utilisant ce visage : les différentes versions des fonctions virtuelles.
Vous avez vu dans ce chapitre qu'il est impossible de comprendre, ou même de créer, un exemple de polymorphisme sans utiliser l'abstraction des données et l'héritage. Le polymorphisme est une fonctionnalité qui ne peut être vue isolément (comme les instructions const ou switch, par exemple), mais au lieu de cela ne fonctionne que de concert, comme un élément d'un “grand tableau” des relations entre classes. Les gens sont souvent embrouillés par d'autres aspects du C++, qui ne sont pas orientés objet, comme la surcharge et les arguments par défaut, qui sont parfois présentés comme orientés objet. Ne vous laissez pas avoir : si ce n'est pas de la liaison tardive, ce n'est pas du polymorphisme.
Pour utiliser le polymorphisme – et donc les techniques orientées objet – efficacement dans vos programmes, vous devez élargir votre vision de la programmation pour inclure non seulement les membres et les messages d'une classe individuelle, mais également ce qu'il y a de commun entre des classes et leurs relations les unes avec les autres. Bien que cela demande des efforts significatifs, c'est un jeu qui vaut la chandelle, parce que les résultats sont un développement plus rapide, une meilleure organisation du code, des programmes extensibles et une maintenance plus facile du code.
Le polymorphisme complète les fonctionnalités orientées objet du langage, mais il y a deux autres fonctionnalités majeures en C++ : les templates (qui sont introduits au Chapitre 16 et couverts plus en détails dans le Volume 2), et la gestion des exceptions (qui est couverte dans le Volume 2). Ces fonctionnalités vous apportent autant d'augmentation de la puissance de programmation que chacune des fonctionnalités orientées objet : typage abstrait des données , héritage et polymorphisme.
15.15. Exercices▲
Les solutions à certains exercices peuvent être trouvées dans le document électronique The Thinking in C++ Annotated Solution Guide, disponible pour une somme modique sur www.BruceEckel.com.
- Créez une hiérarchie simple de “shape” (formes ndt) : une classe de base appelée Shape et des classes dérivées appelées Circle, Square, et Triangle. Dans la classe de base, créez une fonction virtuelle appelée draw( ) et redéfinissez-là dans les classes dérivées. Faites un tableau de pointeurs vers les objets Shape que vous créez sur le tas (et ainsi réalisez un transtypage ascendant des pointeurs), et appelez draw( ) via les pointeurs de la classe de base, pour vérifier le comportement de la fonction virtuelle. Si votre debogueur le supporte, suivez le code pas à pas.
- Modifiez l'exercice 1 de telle sorte que draw( ) soit une fonction virtuelle pure. Essayez de créer un objet de type Shape. Essayez d'appeler la fonction virtuelle pure dans le constructeur et voyez ce qui se produit. En laissant draw( ) virtuelle pure, donnez-lui une définition.
- En développant l'exercice 2, créez une fonction qui prenne un objet Shapepar valeur et essayez de réaliser le transtypage ascendant d'un objet dérivé passé comme argument. Voyez ce qui se produit. Corrigez la fonction en prenant une référence vers l'objet Shape.
- Modifiez C14:Combined.cpp pour que f( ) soit virtual dans la classe de base. Modifiez main( ) pour réaliser un transtypage ascendant et un appel virtuel.
- Modifez Instrument3.cpp en ajoutant une fonction virtual prepare( ). Appelez prepare( ) depuis tune( ).
- Créez une hiérarchie d'héritage de Rodent: Mouse, Gerbil, Hamster, etc. Dans la classe de base, fournissez des méthodes qui sont communes à tous les Rodent, et redéfinissez-les dans les classes dérivées pour générer des comportements différents selon le type spécifique de Rodent. Créez un tableau de pointeurs vers Rodent, remplissez-le avec différents types spécifiques de Rodent, et appelez vos méthodes de la classe de base pour voir ce qui se produit.
- Modifiez l'exercice 6 pour utiliser un vector<Rodent*> au lieu d'un tableau de pointeurs. Assurez-vous que la mémoire est nettoyée proprement.
- En partant de la hiérarchie Rodent précédente, faites hériter BlueHamster de Hamster(oui, un tel animal existe ; j'en ai eu un quand j'étais enfant), redéfinissez les méthodes de la classe de base, et montrez que le code qui appelle les méthodes de la classe de base n'a pas besoin d'être modifié pour s"asapter au nouveau type.
- En partant de la hiérarchie Rodent précédente, ajoutez un destructeur non virtuel, créez un objet de classe Hamster en utilisant new, réalisez un transtypage ascendant du pointeur vers un Rodent*, et detruisez le pointeur pour montrer qu'il n'appelle pas tous les destructeurs dans la hiérarchie. Rendez le destructeur virtuel et démontrez que le comportement est à présent correct.
- En partant de la hiérarchie Rodent précédente, modifiez Rodent pour en faire une classe de base abstraite pure.
- Créez un système de contrôle aérien avec la classe de base Aircraft et différents types dérivés. Créez une classe Tower avecc un vector<Aircraft*> qui envoie les messages appropriés aux différents aircraft sous son contrôle.
- Créez un modèle de serre en héritant différents types de Plantes et en construisant des mécanismes dans votre serre qui prennnent soin des plantes.
- Dans Early.cpp, faites de Pet une classe abstraite pure.
- Dans AddingVirtuals.cpp, rendez toutes les fonctions membre de Pet virtuelles pures, mais donnez une définition pour name( ). Corrigez Dog comme il faut, en utilisant la définition de la classe de base de name( ).
- Ecrivez un petit programme pour montrer la différencee entre appeler une fonction virtuelle dans une fonction membre normale et appeler une fonction virtuelle dans un constructeur. Le programme devrait prouver que les deux appels produisent des résultats différents.
- Modifiez VirtualsInDestructors.cpp en faisant hériter une classe de Derived et en redéfinissant f( ) et le destructeur. Dans main( ), créez une objet de votre nouveau type puis réalisez un transtypage ascendant et détruisez-le avec delete.
- Prenez l'exercice 16 et ajoutez des appels à f( ) dans chaque destructeur. Expliquez ce qui se passe.
- Créez une classe qui contient une donnée membre et une classe dérivée qui ajoute une autre donnée membre. Ecrivez une fonction non-membre qui prend un objet de la classe de base par valeur et affiche la taille de cet objet en utilisant sizeof. Dans main( ), créez un objet de la classe dérivée, affichez sa taille, puis appelez votre fonction. Expliquez ce qui se passe.
- Créez un exemple simple d'un appel à une fonction virtuelle et générez la sortie assembleur. Localisez le code assembleur pour l'appel virtuel et tracez et expliquez le code.
- Ecrivez une classe avec une fonction virtuelle et une non virtuelle. Faites-en hériter une nouvelle classe, créez un objet de cette classe, et faites un transtypage ascendant vers un pointeur du type de la classe de base. Utilisez la fonction clock( ) qui se trouve dans <ctime>(vous aurez besoin de chercher cela dans votre guide local de la bibliothèque C) pour mesurer la différence entre un appel virtuel et non virtuel. Vous aurez besoin de faire plusieurs appels à chaque fonction dans votre boucle de chronométrage afin de voir la différence.
- Modifiez C14:Order.cpp en ajoutant une fonction virtuelle dans la classe de base de la macro CLASS(faites-la afficher quelque chose) et en rendant le destructeur virtuel. Créez des objets des différentes sous-classes et transtypez les vers la classe de base. Vérifiez que le comportement virtuel fonctionne et que la construction et la destruction appropriées ont lieu.
- Créez une classe avec trois focntions virtuelles suchargées. Héritez une nouvelle classe de celle-ci et redéfinissez une des fonctions. Créez un objet de votre classe dérivée. Pouvez-vous appeler toutes les fonctions de la classe de base via l'objet de la classe dérivée ? Transtypez l'adresse de l'objet vers la base. Pouvez-vous appeler les trois fonctions via la base ? Supprimez la redéfinition dans la classe dérivée. A présent, pouvez-vous appeler toutes les fonctions de la classe de base via l'objet de la classe dérivée ?
- Modifiez VariantReturn.cpp pour montrer que son comportement fonctionne avec les références comme avec les pointeurs.
- Dans Early.cpp, comment pouvez-vous dire si le compilateur fait l'appel en utilisant la liaison précoce ou retardée ? Déterminez ce qu'il en est pour votre propre compilateur.
- Créez une classe de base contenant une fonction clone( ) qui retourne un pointeur vers une copie de l'objet courant. Dérivez deux sous-classes qui redéfinissent clone( ) pour retourner des copies de leur type spécifique. Dans main( ), créez puis transtypez des objets de vos deux types dérivés, puis appelez clone( ) pour chacun d'eux et vérifiez que les copies clonées sont du sous-type correct. Testez votre fonction clone( ) pour que vous retourniez le type de base, puis essayez de retourner le type dérivé exact. Pouvez-vous imaginer des situations pour lesquelles cette dernière approche soit nécessaire ?
- Modifiez OStackTest.cpp en créant votre propre classe, puis en faisant une dérivée multiple avec Object pour créer quelque chose qui peut être placé dans Stack. Testez votre classe dans main( ).
- Ajoutez un type appelé Tensor à OperatorPolymorphism.cpp.
- (Intermédiaire) Créez une classe X de base sans donnée membre ni constructeur, mais avec une fonction virtuelle. Créez une classe Y qui hérite de X, mais sans constructeur explicite. Générer le code assembleur et examinez-le pour déterminer si un constructeur est créé et appelé pour X, et si c'est le cas, ce que fait le code. Expliquez ce que vous découvrez. X n'a pas de constructeur par défaut, alors pourquoi le compilateur ne se plaint-il pas ?
- (Intermédiaire) Modifiez l'exercise 28 en écrivant des constructeurs pour les deux classes afin que chaque constructeur appelle une fonction virtuelle. Générez le code assembleur. Déterminez où le VPTR est affecté dans chaque constructeur. Est-ce que le mécanisme virtuel est utilisé par votre compilateur dans le constructeur ? Etablissez pourquoi la version locale de la fonction est toujours appelée.
- (Avancé) Si les appels aux fonctions contenant un objet passé par valeur n'étaient pas lié précocément, un appel virtuel pourrait accéder à des parties qui n'existent pas. Est-ce possible ? Ecrivez du code qui force un appel virtuel, et voyez si cela provoque un plantage. Pour expliquer le comportement, examinez ce qui se passe quand vous passez un objet par valeur.
- (Avancé) Trouvez exactement combien de temps supplémentaire est requis pour un appel à une fonction virtuelle en allant consulter l'information concernant le langage assembleur de votre processeur ou un autre manuel technique et trouvez le nombre de cycles d'horloge requis pour un simple appel contre celui requis pour les instructions de l'appel de la fonction virtuelle.
- Déterminez la taille du VPTR avec sizeof pour vorte implémentation. A présent, héritez multiple de deux classes qui contiennent des fonctions virtuelles. Avez-vous obtenu un ou deux VPTR dans la classe dérivée ?
- Créez une classe avec des données membres et des fonctions virtuelles. Ecrivez une fonction qui regarde le contenu mémoire dans un objet de votre classe et en affiche les différentes parties de celui-ci. Pour ce faire, vous aurez besoin d'expérimenter et de découvrir par itérations où est localisé le VPTR dans l'objet.
- Imaginez que les fonctions virtuelles n'existent pas, et modifiez Instrument4.cpp afin qu'elle utilise dynamic_cast pour faire l'équivalent des appels virtuels. Expliquez pourquoi c'est une mauvaise idée.
- Modifiez StaticHierarchyNavigation.cpp afin qu'au lieu d'utiliser la RTTI du C++ vous créiez votre propre RTTI via une fonction virtuelle dans la classe de base appelée whatAmI( ) et une énumération { Circles, Squares };.
- Partez de PointerToMemberOperator.cpp du chapitre 12 et montrez que le polymorphisme fonctionne toujours avec des pointeurs vers membres, même si operator->* est surchargé.