


1. Introduction sur les Objets▲
La genèse de la révolution informatique fut dans l'invention d'une machine. La genèse de nos langage de programmation tend donc à ressembler à cette machine.
Mais les ordinateurs ne sont pas tant des machines que des outils d'amplification de l'esprit(« des vélos pour le cerveau », comme aime à le répéter Steve Jobs) et un nouveau moyen d'expression. Ainsi, ces outils commencent à ressembler moins à des machines et plus à des parties de notre cerveau ou d'autres moyens d'expressions telles que l'écriture, la peinture, la sculpture ou la réalisation de films. La Programmation Orientée Objet fait partie de cette tendance de l'utilisation de l'ordinateur en tant que moyen d'expression.
Ce chapitre présente les concepts de base de la programmation orientée objet (POO), ainsi qu'un survol des méthodes de développement de la POO. Ce chapitre et ce livre présupposent que vous avez déjà expérimenté un langage de programmation procédural, qui ne soit pas forcément le C. Si vous pensez que vous avez besoin de plus de pratique dans la programmation et/ou la syntaxe du C avant de commencer ce livre, vous devriez explorer le CD ROM fourni avec le livre, Thinking in C: Foundations for C++ and Java, également disponible sur www.BruceEckel.com.
Ce chapitre tient plus de la culture générale. Beaucoup de personnes ne veulent pas se lancer dans la programmation orientée objet sans en comprendre d'abord les tenants et les aboutissants. C'est pourquoi beaucoup de concepts seront introduits ici afin de vous donner un solide aperçu de la POO. Au contraire, certaines personnes ne saisissent les concepts généraux qu'après en avoir compris une partie des mécanismes; ces gens-là se sentent embourbés et perdus s'ils n'ont pas un bout de code à se mettre sous la dent. Si vous faites partie de cette catégorie de personnes et êtes impatients d'attaquer les spécificités du langage, vous pouvez sauter ce chapitre - cela ne vous gênera pas pour l'écriture de programmes ou l'apprentissage du langage. Mais vous voudrez peut-être y revenir plus tard pour approfondir vos connaissances sur les objets, les comprendre et assimiler la conception objet.
1.1. Les bienfaits de l'abstraction▲
Tous les langages de programmation fournissent des abstractions. On peut dire que la complexité des problèmes que vous êtes capable de résoudre est directement proportionnelle au type et à la qualité d'abstraction. Par « type », il faut comprendre « Que tentez-vous d'abstraire ? ». Le langage assembleur est une petite abstraction de la machine sous-jacente. Beaucoup de langages « impératifs » (tels que Fortran, BASIC, et C) sont des abstractions du langage assembleur. Ces langages sont de nettes améliorations par rapport à l'assembleur, mais leur abstraction première requiert que vous réfléchissiez en termes de structure de l'ordinateur plutôt qu'à la structure du problème que vous essayez de résoudre. Le programmeur doit établir l'association entre le modèle de la machine (dans « l'espace solution », qui est le lieu où vous modélisez le problème, tel que l'ordinateur) et le modèle du problème à résoudre (dans « l'espace problème », qui est l'endroit où se trouve le problème). Les efforts requis pour réaliser cette association, et le fait qu'elle est étrangère au langage de programmation, produit des programmes difficiles à écrire et à entretenir, ce qui a mené à la création de l'industrie du « Génie Logiciel».
L'alternative à la modélisation de la machine est de modéliser le problème que vous tentez de résoudre. Les premiers langages tels que LISP ou APL choisirent une vue particulière du monde (« Tous les problèmes se ramènent à des listes » ou « Tous les problèmes sont algorithmiques »). PROLOG convertit tous les problèmes en chaînes de décision. Des langages ont été créés pour la programmation par contrainte, ou pour la programmation ne manipulant que des symboles graphiques (ces derniers se sont révélés être trop restrictifs). Chacune de ces approches est une bonne solution pour la classe particulière de problèmes qu'ils ont a résoudre, mais devient plus délicate dès lors que vous les sortez de leur domaine.
L'approche orientée objet va un pas plus loin en fournissant des outils au programmeur pour représenter des éléments dans l'espace problème. Cette représentation est assez générale pour que le programmeur ne soit restreint à aucun type particulier de problème. Nous nous référons aux éléments dans l'espace problème et leur représentation dans l'espace solution en tant qu'« objets ». (Bien sûr, vous aurez aussi besoin d'autres objets qui n'ont pas leur analogue dans l'espace problème). L'idée est qu'on permet au programme de s'adapter au fond du problème en ajoutant de nouveaux types d'objets , de façon à ce que, quand vous lisez le code décrivant la solution, vous lisez aussi quelque chose qui décrit le problème. C'est un langage d'abstraction plus flexible et puissant que tout ce que nous avons eu jusqu'à présent. Ainsi, la POO vous permet de décrire le problème selon les termes du problème plutôt que selon les termes de la machine sur laquelle la solution sera exécutée. Cependant, il y a toujours une connexion à l'ordinateur. Chaque objet ressemble à un mini-ordinateur ; il a un état, et il a des opérations que vous pouvez lui demander d'exécuter. Cependant, cela ne semble pas être une si mauvaise analogie avec les objets du monde réel - ils ont tous des caractéristiques et des comportements.
Des concepteurs de langage ont décrété que la programmation orientée objet en elle-même n'était pas adéquate pour résoudre facilement tous les problèmes de programmation, et recommandent la combinaison d'approches variées dans des langages de programmation multiparadigmes.
Alan Kay a résumé les cinq caractéristiques de base de Smalltalk, le premier véritable langage de programmation orienté objet et l'un des langages sur lequel est basé C++. Ces caractéristiques représentent une approche pure de la programmation orientée objet :
- Toute chose est un objet. Pensez à un objet comme à une variable améliorée : il stocke des données, mais vous pouvez « effectuer des requêtes » sur cet objet, lui demander de faire des opérations sur lui-même. En théorie, vous pouvez prendre n'importe quel composant conceptuel du problème que vous essayez de résoudre (un chien, un immeuble, un service administratif, etc...) et le représenter en tant qu'objet dans le programme.
- Un programme est un groupe d'objets s'indiquant quoi faire en envoyant des messages. Pour qu'un objet effectue une requête, vous « envoyez un message » à cet objet. Plus concrètement, vous pouvez penser à un message comme à un appel de fonction appartenant à un objet particulier.
- Chaque objet a sa propre mémoire composée d'autres objets. Autrement dit, vous créez un nouveau type d'objet en créant un paquetage contenant des objets déjà existants. Ainsi, vous pouvez créer un programme dont la complexité est cachée derrière la simplicité des objets.
- Chaque objet a un type. Dans le jargon, chaque objet est une instance d'une classe, où « classe » est synonyme de « type ». La caractéristique distinctive la plus importante d'une classe est : « Quels messages pouvez-vous lui envoyer ? ».
- Tous les objets d'un type particulier peuvent recevoir les mêmes messages. C'est une caractéristique lourde de signification, comme vous le verrez plus tard. Parce qu'un objet de type « cercle » est également un objet de type « forme », un cercle garanti d'accepter les messages de forme. Cela signifie que vous pouvez écrire du code qui parle aux formes et qui sera automatiquement accepté par tout ce qui correspond à la description d'une forme. Cette substituabilité est l'un des concepts les plus puissants de la POO.
1.2. Un objet dispose d'une interface▲
Aristote fut probablement le premier à commencer une étude approfondie du concept de type; il parle de « la classe des poissons et la classe des oiseaux ». L'idée que tous les objets, tout en étant uniques, appartiennent à une classe d'objets qui ont des caractéristiques et des comportements en commun fut utilisée directement dans le premier langage orienté objet, Simula-67, avec son mot clef fondamental class qui introduit un nouveau type dans un programme.
Simula, comme son nom l'indique, a été conçu pour développer des simulations telles que "le problème du guichet de banque" (4)Dans celle-ci, vous avez un ensemble de guichetiers, de clients, de comptes, de transactions et de devises - un tas « d'objets ». Des objets semblables, leur état durant l'exécution du programme mis à part, sont groupés ensemble en tant que « classes d'objets » et c'est de là que vient le mot clef class. Créer des types de données abstraits (des classes) est un concept fondamental dans la programmation orientée objet. On utilise les types de données abstraits de manière quasi identique aux types de données prédéfinis. On peut créer des variables d'un type particulier (appelés objets ou instances dans le jargon orienté objet) et manipuler ces variables (ce qu'on appelle envoyer des messages ou des requêtes; on envoie un message et l'objet se débrouille pour le traiter). Les membres (éléments) d'une même classe partagent des caractéristiques communes : chaque compte dispose d'un solde, chaque guichetier peut accepter un dépôt, etc. Cependant, chaque élément a son propre état, chaque compte a un solde différent, chaque guichetier a un nom. Ainsi, les guichetiers, clients, comptes, transactions, etc. peuvent tous être représentés par une unique entité au sein du programme. Cette entité est l'objet, et chaque objet appartient à une classe particulière qui définit ses caractéristiques et ses comportements.
Donc, comme la programmation orientée objet consiste en la création de nouveaux types de données, quasiment tous les langages orientés objet utilisent le mot clef « class ». Quand vous voyez le mot « type » pensez « classe » et inversement (5)
Comme une classe décrit un ensemble d'objets partageant des caractéristiques (données) et des comportements (fonctionnalités) communs, une classe est réellement un type de données. En effet, un nombre en virgule flottante par exemple, dispose d'un ensemble de caractéristiques et de comportements. La différence est qu'un programmeur définit une classe pour représenter un problème au lieu d'être forcé d'utiliser un type de données conçu pour représenter une unité de stockage de l'ordinateur. Le langage de programmation est étendu en ajoutant de nouveaux types de données spécifiques à nos besoins. Le système de programmation accepte la nouvelle classe et lui donne toute l'attention et le contrôle de type qu'il fournit aux types prédéfinis.
L'approche orientée objet n'est pas limitée aux simulations. Que vous pensiez ou non que tout programme n'est qu'une simulation du système qu'on représente, l'utilisation des techniques de la POO peut facilement réduire un ensemble de problèmes à une solution simple.
Une fois qu'une classe est créée, on peut créer autant d'objets de cette classe qu'on veut et les manipuler comme s'ils étaient les éléments du problème qu'on tente de résoudre. En fait, l'une des difficultés de la programmation orientée objet est de créer une bijection entre les éléments de l'espace problème et les éléments de l'espace solution.
Mais comment utiliser un objet? Il faut pouvoir lui demander d'exécuter une requête, telle que terminer une transaction, dessiner quelque chose à l'écran, ou allumer un interrupteur. Et chaque objet ne peut traiter que certaines requêtes. Les requêtes qu'un objet est capable de traiter sont définies par son interface, et son type est ce qui détermine son interface. Prenons l'exemple d'une ampoule électrique :
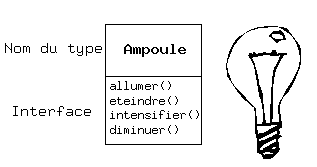
Ampoule amp;
amp.allumer();L'interface précise quelles opérations on peut effectuer sur un objet particulier. Cependant, il doit exister du code quelque part pour satisfaire cette requête. Ceci, avec les données cachées, constitue l' implémentation. Du point de vue de la programmation procédurale, ce n'est pas si compliqué. Un type dispose d'une fonction associée à chaque requête possible, et quand on effectue une requête particulière sur un objet, cette fonction est appelée. Ce mécanisme est souvent résumé en disant qu'on « envoie un message » (fait une requête) à un objet, et l'objet se débrouille pour l'interpréter (il exécute le code associé).
Ici, le nom du type / de la classe est Ampoule, le nom de l'objet Ampoule créé est amp, et on peut demander à un objet Ampoule de s'allumer, de s'éteindre, d'intensifier ou de diminuer sa luminosité. Un objet Ampoule est créé en déclarant un nom ( amp) pour cet objet. Pour envoyer un message à cet objet, il suffit de spécifier le nom de l'objet suivi de la requête avec un point entre les deux. Du point de vue de l'utilisateur d'une classe prédéfinie, c'est à peu prés tout ce qu'il faut savoir pour programmer avec des objets.
L'illustration ci-dessus reprend le formalisme Unified Modeling Language (UML). Chaque classe est représentée par une boîte, avec le nom du type dans la partie supérieure, les données membres qu'on décide de décrire dans la partie du milieu et les fonctions membres(les fonctions appartenant à cet objet qui reçoivent les messages envoyés à cet objet) dans la partie du bas de la boîte. Souvent on ne montre dans les diagrammes UML que le nom de la classe et les fonctions publiques, et la partie du milieu n'existe donc pas. Si seul le nom de la classe nous intéresse, alors la portion du bas n'a pas besoin d'être montrée non plus.
1.3. L'implémentation cachée▲
Il est utile de diviser le terrain de jeu en créateurs de classe (ceux qui créent les nouveaux types de données) et programmeurs clients(6)(ceux qui utilisent ces types de données dans leurs applications). Le but des programmeurs clients est de se monter une boîte à outils pleine de classes réutilisables pour le développement rapide d'applications (RAD, Rapid Application Development en anglais). Les créateurs de classes, eux, se focalisent sur la construction d'une classe qui n'expose que le nécessaire aux programmeurs clients et cache tout le reste. Pourquoi cela ? Parce que si c'est caché, le programmeur client ne peut l'utiliser, et le créateur de la classe peut changer la portion cachée comme il l'entend sans se préoccuper de l'impact que cela pourrait avoir chez les utilisateurs de sa classe. La portion cachée correspond en général aux données de l'objet qui pourraient facilement être corrompues par un programmeur client négligent ou mal informé. Ainsi, cacher l'implémentation réduit considérablement les bugs.
Le concept d'implémentation cachée ne saurait être trop loué : dans chaque relation il est important de fixer des frontières respectées par toutes les parties concernées. Quand on crée une bibliothèque, on établit une relation avec un programmeur client, programmeur qui crée une application (ou une bibliothèque plus conséquente) en utilisant notre bibliothèque.
Si tous les membres d'une classe sont accessibles pour tout le monde, alors le programmeur client peut faire ce qu'il veut avec cette classe et il n'y a aucun moyen de faire respecter certaines règles. Même s'il est vraiment préférable que l'utilisateur de la classe ne manipule pas directement certains membres de la classe, sans contrôle d'accès il n'y a aucun moyen de l'empêcher : tout est exposé à tout le monde.
La raison première du contrôle d'accès est donc d'empêcher les programmeurs clients de toucher à certaines portions auxquelles ils ne devraient pas avoir accès - les parties qui sont nécessaires pour les manipulations internes du type de données mais n'appartiennent pas à l'interface dont les utilisateurs ont besoin pour résoudre leur problème. C'est en réalité un service rendu aux utilisateurs car ils peuvent voir facilement ce qui est important pour leurs besoins et ce qu'ils peuvent ignorer.
La seconde raison d'être du contrôle d'accès est de permettre au concepteur de la bibliothèque de changer le fonctionnement interne de la classe sans se soucier des effets que cela peut avoir sur les programmeurs clients. Par exemple, on peut implémenter une classe particulière d'une manière simpliste afin d'accélérer le développement, et se rendre compte plus tard qu'on a besoin de la réécrire afin de gagner en performances. Si l'interface et l'implémentation sont clairement séparées et protégées, cela peut être réalisé facilement et nécessite simplement une réédition des liens par l'utilisateur.
Le C++ utilise trois mots clefs pour fixer des limites au sein d'une classe : public, private et protected. Leur signification et leur utilisation est relativement explicite. Ces spécificateurs d'accès déterminent qui peut utiliser les définitions qui suivent. public veut dire que les définitions suivantes sont disponibles pour tout le monde. Le mot clef private, au contraire, veut dire que personne, le créateur de la classe et les fonctions internes de ce type mis à part, ne peut accéder à ces définitions. private est un mur de briques entre le créateur de la classe et le programmeur client. Si quelqu'un tente d'accéder à un membre défini comme private, ils récupèreront une erreur lors de la compilation. protected se comporte tout comme private, en moins restrictif : une classe dérivée a accès aux membres protected, mais pas aux membres private. L'héritage sera introduit bientôt.
1.4. Réutilisation de l'implémentation▲
Une fois qu'une classe a été créée et testée, elle devrait (idéalement) représenter une partie de code utile. Il s'avère que cette réutilisabilité n'est pas aussi facile à obtenir que cela ; cela demande de l'expérience et de la perspicacité pour produire une bonne conception. Mais une fois bien conçue, cette classe ne demande qu'à être réutilisée. La réutilisation de code est l'un des plus grands avantages que les langages orientés objets fournissent.
La manière la plus simple de réutiliser une classe est d'utiliser directement un objet de cette classe, mais on peut aussi placer un objet de cette classe à l'intérieur d'une nouvelle classe. On appelle cela « créer un objet membre ». La nouvelle classe peut être constituée de n'importe quel nombre d'objets d'autres types, selon la combinaison nécessaire pour que la nouvelle classe puisse réaliser ce pour quoi elle a été conçue. Parce que la nouvelle classe est composée à partir de classes existantes, ce concept est appelé composition(ou, plus généralement, agrégation). On se réfère souvent à la composition comme à une relation « possède-un », comme dans « une voiture possède un moteur ».
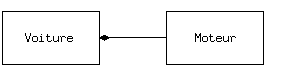
(Le diagramme UML ci-dessus indique la composition avec le losange rempli, qui indique qu'il y a un moteur dans une voiture. J'utiliserai une forme plus simple : juste une ligne, sans le losange, pour indiquer une association. (7))
La composition s'accompagne d'une grande flexibilité : les objets membres de la nouvelle classe sont généralement privés, ce qui les rend inaccessibles aux programmeurs clients de la classe. Cela permet de modifier ces membres sans perturber le code des clients existants. On peut aussi changer les objets membres lors la phase d'exécution, pour changer dynamiquement le comportement du programme. L'héritage, décrit juste après, ne dispose pas de cette flexibilité car le compilateur doit placer des restrictions lors de la compilation sur les classes créées avec héritage.
Parce que la notion d'héritage est très importante au sein de la programmation orientée objet, elle est trop souvent accentuée, et le programmeur novice pourrait croire que l'héritage doit être utilisé partout. Cela mène à des conceptions ultra compliquées et cauchemardesques. La composition est la première approche à examiner lorsqu'on crée une nouvelle classe, car elle est plus simple et plus flexible. Le design de la classe en sera plus propre. Avec de l'expérience, les endroits où utiliser l'héritage deviendront raisonnablement évidents.
1.5. Héritage : réutilisation de l'interface▲
L'idée d'objet en elle-même est un outil efficace. Elle permet de fournir des données et des fonctionnalités liées entre elles par concept, afin de représenter une idée de l'espace problème plutôt que d'être forcé d'utiliser les idiomes internes de la machine. Ces concepts sont exprimés en tant qu'unité fondamentale dans le langage de programmation en utilisant le mot clef class.
Il serait toutefois dommage, après s'être donné beaucoup de mal pour créer une classe, de devoir en créer une toute nouvelle qui aurait des fonctionnalités similaires. Ce serait mieux si on pouvait prendre la classe existante, la cloner, et faire des ajouts ou des modifications à ce clone. C'est ce que l' héritage permet de faire, avec la restriction suivante : si la classe originale (aussi appelée classe de base, superclasse ou classe parent) est changée, le « clone » modifié (appelé classe dérivée, héritée, enfant ou sous-classe) répercutera aussi ces changements.
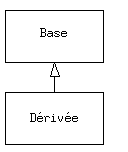
(La flèche dans le diagramme UML ci-dessus pointe de la classe dérivée vers la classe de base. Comme vous le verrez, il peut y avoir plus d'une classe dérivée.)
Un type fait plus que décrire des contraintes sur un ensemble d'objets ; il a aussi des relations avec d'autres types. Deux types peuvent avoir des caractéristiques et des comportements en commun, mais l'un des deux peut avoir plus de caractéristiques que l'autre et peut aussi réagir à plus de messages (ou y réagir de manière différente). L'héritage exprime cette similarité entre les types en introduisant le concept de types de base et de types dérivés. Un type de base contient toutes les caractéristiques et comportements partagés entre les types dérivés. Un type de base est créé pour représenter le coeur de certains objets du système. De ce type de base, on dérive d'autres types pour exprimer les différentes manières existantes pour réaliser ce coeur.
Prenons l'exemple d'une machine de recyclage qui trie les détritus. Le type de base serait « détritus », caractérisé par un poids, une valeur, etc. et peut être concassé, fondu, ou décomposé. A partir de ce type de base, sont dérivés des types de détritus plus spécifiques qui peuvent avoir des caractéristiques supplémentaires (une bouteille a une couleur) ou des actions additionnelles (une canette peut être découpée, un container d'acier est magnétique). De plus, des comportements peuvent être différents (la valeur du papier dépend de son type et de son état général). En utilisant l'héritage, on peut bâtir une hiérarchie qui exprime le problème avec ses propres termes.
Un autre exemple classique : les « formes géométriques », utilisées entre autres dans les systèmes d'aide à la conception ou dans les jeux vidéo. Le type de base est la « forme géométrique », et chaque forme a une taille, une couleur, une position, etc. Chaque forme peut être dessinée, effacée, déplacée, peinte, etc. A partir de ce type de base, des types spécifiques sont dérivés (hérités) : des cercles, des carrés, des triangles et autres, chacun avec des caractéristiques et des comportements supplémentaires (certaines figures peuvent être inversées par exemple). Certains comportements peuvent être différents, par exemple quand on veut calculer l'aire de la forme. La hiérarchie des types révèle à la fois les similarités et les différences entre les formes.
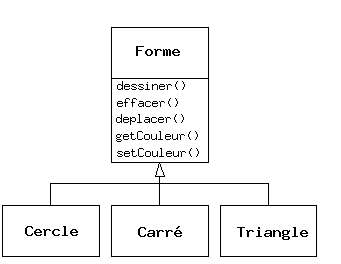
Représenter la solution avec les mêmes termes que ceux du problème est extraordinairement bénéfique car on n'a pas besoin de modèles intermédiaires pour passer de la description du problème à la description de la solution. Avec les objets, la hiérarchie de types est le modèle primaire, on passe donc du système dans le monde réel directement au système du code. En fait, l'une des difficultés à laquelle les gens se trouvent confrontés lors de la conception orientée objet est que c'est trop simple de passer du début à la fin. Les esprits habitués à des solutions compliquées sont toujours stupéfaits par cette simplicité.
Quand on hérite d'un certain type, on crée un nouveau type. Ce nouveau type non seulement contient tous les membres du type existant (bien que les membres private soient cachés et inaccessibles), mais plus important, il duplique aussi l'interface de la classe de la base. Autrement dit, tous les messages acceptés par les objets de la classe de base seront acceptés par les objets de la classe dérivée. Comme on connaît le type de la classe par les messages qu'on peut lui envoyer, cela veut dire que la classe dérivée est du même type que la classe de base. Dans l'exemple précédent, « un cercle est une forme ». Cette équivalence de type via l'héritage est l'une des notions fondamentales dans la compréhension de la programmation orientée objet.
Comme la classe de base et la classe dérivée ont toutes les deux la même interface, certaines implémentations accompagnent cette interface. C'est à dire qu'il doit y avoir du code à exécuter quand un objet reçoit un message particulier. Si on ne fait qu'hériter une classe sans rien lui rajouter, les méthodes de l'interface de la classe de base sont importées dans la classe dérivée. Cela veut dire que les objets de la classe dérivée n'ont pas seulement le même type, ils ont aussi le même comportement, ce qui n'est pas particulièrement intéressant.
Il y a deux façons de différencier la nouvelle classe dérivée de la classe de base originale. La première est relativement directe : il suffit d'ajouter de nouvelles fonctions à la classe dérivée. Ces nouvelles fonctions ne font pas partie de la classe parent. Cela veut dire que la classe de base n'était pas assez complète pour ce qu'on voulait en faire, on a donc ajouté de nouvelles fonctions. Cet usage simple de l'héritage se révèle souvent être une solution idéale. Cependant, il faut tout de même vérifier s'il ne serait pas souhaitable d'intégrer ces fonctions dans la classe de base qui pourrait aussi en avoir l'usage. Ce processus de découverte et d'itération dans la conception est fréquent dans la programmation orientée objet.
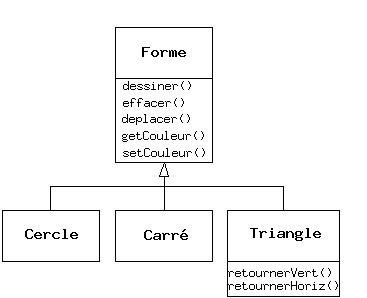
Bien que l'héritage puisse parfois impliquer (spécialement en Java, où le mot clef qui indique l'héritage est extends) que de nouvelles fonctions vont être ajoutées à l'interface, ce n'est pas toujours vrai. La seconde et plus importante manière de différencier la nouvelle classe est de changer le comportement d'une des fonctions existantes de la classe de base. Cela s'appelle redéfinir cette fonction.
Pour redéfinir une fonction, il suffit de créer une nouvelle définition pour la fonction dans la classe dérivée. C'est comme dire : « j'utilise la même interface ici, mais je la traite d'une manière différente dans ce nouveau type ».
1.5.1. Les relations est-un vs. est-comme-un▲
Un certain débat est récurrent à propos de l'héritage : l'héritage ne devrait-il pas seulement redéfinir les fonctions de la classe de base (et ne pas ajouter de nouvelles fonctions membres qui ne font pas partie de la superclasse) ? Cela voudrait dire que le type dérivé serait exactement le même que celui de la classe de base puisqu'il aurait exactement la même interface. Avec comme conséquence logique le fait qu'on puisse exactement substituer un objet de la classe dérivée à un objet de la classe de base. On fait souvent référence à cette substitution pure sous le nom de principe de substitution. Dans un sens, c'est la manière idéale de traiter l'héritage. La relation entre la classe de base et la classe dérivée dans ce cas est une relation est-un, parce qu'on peut dire « un cercle est une forme ». Un test pour l'héritage est de déterminer si la relation est-un entre les deux classes considérées a un sens.
Mais parfois il est nécessaire d'ajouter de nouveaux éléments à l'interface d'un type dérivé, et donc étendre l'interface et créer un nouveau type. Le nouveau type peut toujours être substitué au type de base, mais la substitution n'est plus parfaite parce que les nouvelles fonctions ne sont pas accessibles à partir de la classe parent. On appelle cette relation une relation est-comme-un- le nouveau type dispose de l'interface de l'ancien type mais il contient aussi d'autres fonctions, on ne peut donc pas réellement dire qu'ils soient exactement identiques. Prenons le cas d'un système de climatisation. Supposons que notre maison dispose des tuyaux et des systèmes de contrôle pour le refroidissement, autrement dit, elle dispose d'une interface qui nous permet de contrôler le refroidissement. Imaginons que le système de climatisation tombe en panne et qu'on le remplace par une pompe à chaleur, qui peut à la fois chauffer et refroidir. La pompe à chaleur est-comme-un système de climatisation, mais il peut faire plus de choses. Parce que le système de contrôle n'a été conçu que pour contrôler le refroidissement, il en est restreint à ne communiquer qu'avec la partie refroidissement du nouvel objet. L'interface du nouvel objet a été étendue, mais le système existant ne connaît rien qui ne soit dans l'interface originale.
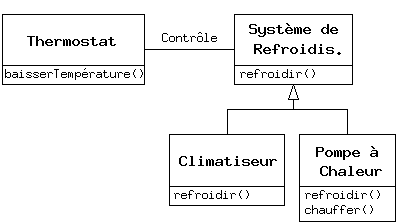
Bien sûr, quand on voit cette modélisation, il est clair que la classe de base « Système de refroidissement » n'est pas assez générale, et devrait être renommée en « Système de contrôle de température » afin de pouvoir inclure le chauffage - auquel cas le principe de substitution marcherait. Cependant, le diagramme ci-dessus est un exemple de ce qui peut arriver dans le monde réel.
Quand on considère le principe de substitution, il est tentant de se dire que cette approche (la substitution pure) est la seule manière correcte de modéliser, et de fait c'est appréciable si la conception fonctionne ainsi. Mais dans certains cas il est tout aussi clair qu'il faut ajouter de nouvelles fonctions à l'interface d'une classe dérivée. En examinant le problème, les deux cas deviennent relativement évidents.
1.6. Polymorphisme : des objets interchangeables▲
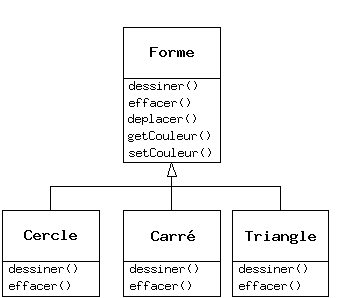
Lorsqu'on manipule des hiérarchies de types, il arrive souvent qu'on veuille traiter un objet en n'utilisant pas son type spécifique, mais en tant qu'objet de son type de base. Cela permet d'écrire du code indépendant des types spécifiques. Dans l'exemple de la forme géométrique, les fonctions manipulent des formes génériques sans se soucier de savoir si ce sont des cercles, des carrés, des triangles, et ainsi de suite. Toutes les formes peuvent être dessinées, effacées, et déplacées, donc ces fonctions envoient simplement un message à un objet forme, elles ne se soucient pas de la manière dont l'objet traite le message.
Un tel code n'est pas affecté par l'addition de nouveaux types, et ajouter de nouveaux types est la façon la plus commune d'étendre un programme orienté objet pour traiter de nouvelles situations. Par exemple, on peut dériver un nouveau type de forme appelé pentagone sans modifier les fonctions qui traitent des formes génériques. Cette capacité à étendre facilement un programme en dérivant de nouveaux sous-types est importante car elle améliore considérablement la conception tout en réduisant le coût de maintenance.
Un problème se pose cependant en voulant traiter les types dérivés comme leur type de base générique (les cercles comme des formes géométriques, les vélos comme des véhicules, les cormorans comme des oiseaux, etc.). Si une fonction demande à une forme générique de se dessiner, ou à un véhicule générique de tourner, ou à un oiseau générique de se déplacer, le compilateur ne peut savoir précisément, lors de la phase de compilation, quelle portion de code sera exécutée. C'est d'ailleurs le point crucial : quand le message est envoyé, le programmeur ne veut pas savoir quelle portion de code sera exécutée ; la fonction dessiner peut être appliquée aussi bien à un cercle qu'à un carré ou un triangle, et l'objet va exécuter le bon code suivant son type spécifique. Si on n'a pas besoin de savoir quelle portion de code est exécutée, alors le code exécuté lorsqu'on ajoute un nouveau sous-type peut être différent sans exiger de modification dans l'appel de la fonction. Le compilateur ne peut donc précisément savoir quelle partie de code sera exécutée, donc que va-t-il faire ? Par exemple, dans le diagramme suivant, l'objet Contrôleur d'oiseaux travaille seulement avec des objets Oiseaux génériques, et ne sait pas de quel type ils sont. C'est pratique du point de vue de Contrôleur d'oiseaux, car il n'a pas besoin d'écrire du code spécifique pour déterminer le type exact d' Oiseau avec lequel il travaille, ou le comportement de cet Oiseau. Comment se fait-il donc que, lorsque bouger() est appelé tout en ignorant le type spécifique de l' Oiseau, on obtienne le bon comportement (une Oie court, vole ou nage, et un Pingouin court ou nage) ?
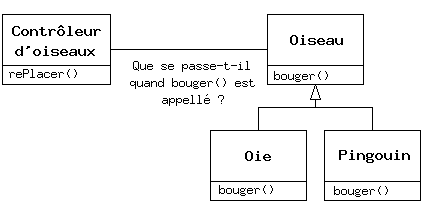
La réponse constitue l'astuce fondamentale de la programmation orientée objet : le compilateur ne peut faire un appel de fonction au sens traditionnel du terme. Un appel de fonction généré par un compilateur non orienté objet crée ce qu'on appelle une association prédéfinie, un terme que vous n'avez sans doute jamais entendu auparavant car vous ne pensiez pas qu'on puisse faire autrement. En d'autres termes, le compilateur génère un appel à un nom de fonction spécifique, et l'éditeur de liens résout cet appel à l'adresse absolue du code à exécuter. En POO, le programme ne peut déterminer l'adresse du code avant la phase d'exécution, un autre mécanisme est donc nécessaire quand un message est envoyé à un objet générique.
Pour résoudre ce problème, les langages orientés objet utilisent le concept d' association tardive. Quand un objet reçoit un message, le code appelé n'est pas déterminé avant l'exécution. Le compilateur s'assure que la fonction existe et vérifie le type des arguments et de la valeur de retour (un langage omettant ces vérifications est dit faiblement typé), mais il ne sait pas exactement quel est le code à exécuter.
Pour créer une association tardive, le compilateur C++ insère une portion spéciale de code en lieu et place de l'appel absolu. Ce code calcule l'adresse du corps de la fonction, en utilisant des informations stockées dans l'objet (ce mécanisme est couvert plus en détails dans le Chapitre 15). Ainsi, chaque objet peut se comporter différemment suivant le contenu de cette portion spéciale de code. Quand un objet reçoit un message, l'objet sait quoi faire de ce message.
On déclare qu'on veut une fonction qui ait la flexibilité des propriétés de l'association tardive en utilisant le mot-clé virtual. On n'a pas besoin de comprendre les mécanismes de virtual pour l'utiliser, mais sans lui on ne peut pas faire de la programmation orientée objet en C++. En C++, on doit se souvenir d'ajouter le mot-clé virtual parce que, par défaut, les fonctions membre ne sont pas liées dynamiquement. Les fonctions virtuelles permettent d'exprimer des différences de comportement entre des classes de la même famille. Ces différences sont ce qui engendre un comportement polymorphe.
Reprenons l'exemple de la forme géométrique. Le diagramme de la hiérarchie des classes (toutes basées sur la même interface) se trouve plus haut dans le chapitre. Pour illustrer le polymorphisme, écrivons un bout de code qui ignore les détails spécifiques du type et parle uniquement à la classe de base. Ce code est déconnecté des informations spécifiques au type, donc plus facile à écrire et à comprendre. Et si un nouveau type - un Hexagone, par exemple - est ajouté grâce à l'héritage, le code continuera de fonctionner aussi bien pour ce nouveau type de Forme qu'il le faisait avec les types existants. Le programme est donc extensible.
Si nous écrivons une fonction en C++ (comme vous allez bientôt apprendre à le faire) :
void faireQuelqueChose(Forme &f) {
f.effacer();
// ...
f.dessiner();
}Cette fonction s'adresse à n'importe quelle Forme, elle est donc indépendante du type spécifique de l'objet qu'elle dessine et efface (le ‘ &' signifie «Prends l'adresse de l'objet qui est passé à faireQuelqueChose()» mais ce n'est pas important que vous compreniez les détails de cela pour l'instant). Si nous utilisons cette fonction faireQuelqueChose() dans une autre partie du programme :
Cercle c;
Triangle t;
Ligne l;
faireQuelqueChose(c);
faireQuelqueChose(t);
faireQuelqueChose(l);Les appels à faireQuelqueChose() fonctionnent correctement, sans se préoccuper du type exact de l'objet.
En fait c'est une manière de faire très élégante. Considérons la ligne :
faireQuelqueChose(c);Un Cercle est ici passé à une fonction qui attend une Forme. Comme un Cercleest une Forme, il peut être traité comme tel par faireQuelqueChose(). C'est à dire qu'un Cercle peut accepter tous les messages que faireQuelqueChose() pourrait envoyer à une forme. C'est donc une façon parfaitement logique et sûre de procéder.
Traiter un type dérivé comme s'il était son type de base est appelé transtypage ascendant, surtypage ou généralisation(upcasting). L'adjectif ascendant vient du fait que dans un diagramme d'héritage typique, le type de base est représenté en haut, les classes dérivées s'y rattachant par le bas. Ainsi, changer un type vers son type de base revient à remonter dans le diagramme d'héritage : transtypage « ascendant ».
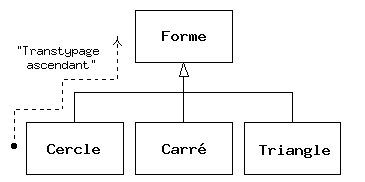
Un programme orienté objet contient obligatoirement des transtypages ascendants, car c'est de cette manière que le type spécifique de l'objet peut être délibérément ignoré. Examinons le code de faireQuelqueChose():
f.effacer();
// ...
f.dessiner();Remarquez qu'il ne dit pas « Si tu es un Cercle, fais ceci, si tu es un Carré, fais cela, etc. ». Ce genre de code qui vérifie tous les types possibles que peut prendre une Forme est confus et il faut le changer à chaque extension de la classe Forme. Ici, il suffit de dire : « Tu es une forme géométrique, je sais que tu peux te dessiner() et t' effacer(), alors fais-le et occupe-toi des détails spécifiques ».
Ce qui est impressionnant dans le code de faireQuelqueChose(), c'est que tout fonctionne comme on le souhaite. Appeler dessiner() pour un Cercle exécute une portion de code différente de celle exécutée lorsqu'on appelle dessiner() pour un Carré ou une Ligne, mais lorsque le message dessiner() est envoyé à une Forme anonyme, on obtient le comportement idoine basé sur le type réel de la Forme. C'est impressionnant dans la mesure où le compilateur C++ ne sait pas à quel type d'objet il a affaire lors de la compilation du code de faireQuelqueChose(). On serait en droit de s'attendre à un appel aux versions effacer() et dessiner() de Forme, et non celles des classes spécifiques Cercle, Carré et Ligne. Mais quand on envoie un message à un objet, il fera ce qu'il a à faire, même quand la généralisation est impliquée. C'est ce qu'implique le polymorphisme. Le compilateur et le système d'exécution s'occupent des détails, et c'est tout ce que vous avez besoin de savoir en plus de savoir comment modéliser avec. Si une fonction membre est virtual, alors quand on envoie un message à un objet, l'objet le traite correctement, même quand le transtypage ascendant est mis en jeu.
1.7. Créer et détruire les objets▲
Techniquement, le domaine de la POO est celui de l'abstraction du typage des données, de l'héritage et du polymorphisme, mais d'autres questions peuvent être au moins aussi importantes.
La façon dont les objets sont créés et détruits est particulièrement importante. Où sont les données d'un objet et comment la durée de vie de l'objet est-elle gérée ? Différents langages de programmation utiliseront ici différentes philosophies. L'approche du C++ est de privilégier le contrôle de l'efficacité, alors le choix est laissé au programmeur. Pour maximiser la vitesse, le stockage et la durée de vie peuvent être déterminés à l'écriture du programme en plaçant les objets sur la pile ou dans un espace de stockage statique. La pile est une région de la mémoire utilisée directement par le microprocesseur pour stocker les données durant l'exécution du programme. Les variables sur la pile sont souvent qualifiées de variables automatiques ou de portée. La zone de stockage statique est simplement une zone fixée de la mémoire allouée avant le début de l'exécution du programme. L'utilisation de la pile ou des zones de stockage statiques met la priorité sur la vitesse d'allocation et de libération, ce qui est peut être avantageux dans certaines situations. Cependant vous sacrifiez la flexibilité parce que vous êtes obligés de connaître la quantité exacte, la durée de vie et le type des objets au moment où vous écrivez le programme. Si vous tentez de résoudre un problème beaucoup plus général, comme de la conception assistée par ordinateur, de la gestion d'entrepôt ou du contrôle de trafic aérien, c'est trop restrictif.
La seconde approche est de créer des objets dynamiquement dans un emplacement mémoire appelé le tas. Dans cette approche vous ne connaissez pas, avant l'exécution, le nombre d'objets dont vous aurez besoin, leur durée de vie ou leur type exact. Ces décisions seront prises en leur temps pendant l'exécution. Si vous avez besoin d'un nouvel objet vous le créez simplement sur le tas lorsque vous en avez besoin en utilisant le mot-clé new. Lorsque vous en avez fini avec le stockage, vous devez libérer la mémoire en utilisant le mot-clé delete.
Parce que le stockage est géré dynamiquement pendant l'exécution, la durée nécessaire à l'allocation sur le tas est significativement plus longue que celle pour allouer sur la pile. (Créer sur la pile consite souvent en une seule instruction du microprocesseur pour abaisser le pointeur de la pile, et une autre pour l'élever à nouveau.) L'approche dynamique donne généralement l'impression que les objets tendent à se complexifier, or les frais supplémentaires pour le stockage et la libération n'ont pas un impact important sur la création d'un objet. En plus, la plus grande flexibilité offerte est essentielle à la résolution de problèmes généraux de programmation.
Il y a une autre question, cependant, c'est la durée de vie d'un objet. Si vous créez un objet sur la pile ou dans un espace de stockage statique, le compilateur détermine la durée de l'objet et peu automatiquement le détruire. Cependant, si vous le créez sur le tas, le compilateur ne connaît pas sa durée de vie. En C++, le programmeur est obligé de déterminer par programme le moment où l'objet est détruit, et effectue cette destruction en utilisant le mot-clé delete. Comme une alternative, l'environnement peut offrir un dispositif appelé garbage collector(ramasse-miettes) qui détermine automatiquement quand un objet n'est plus utilisé et le détruit. Bien sûr, écrire un programme utilisant un garbage collector est plus pratique, mais cela requiert que toutes les applications tolèrent l'existence de ce collecteur et les frais inhérents à la collecte des déchets. Ceci ne satisfait pas les conditions de conception du langage C++ et ainsi il n'en est pas fait mention, mais les collecteurs tiers existent en C++.
1.8. Traitement des exceptions : gérer les erreurs▲
Depuis les débuts des langages de programmation, le traitement des erreurs s'est révélé l'un des problèmes les plus ardus. Parce qu'il est difficile de concevoir un bon mécanisme de gestion des erreurs, beaucoup de langages ignorent ce problème et le délèguent aux concepteurs de bibliothèques qui fournissent des mécanismes de demi-mesure qui fonctionnent dans beaucoup de situations mais peuvent être facilement contournés, généralement en les ignorant. L'une des faiblesses de la plupart des mécanismes d'erreur est qu'ils reposent sur la vigilance du programmeur à suivre des conventions non imposées par le langage. Si les programmeurs ne sont pas assez vigilants, ce qui est souvent le cas s'ils sont pressés, ces mécanismes peuvent facilement être oubliés.
La gestion des exceptions intègre la gestion des erreurs directement au niveau du langage de programmation et parfois même au niveau du système d'exploitation. Une exception est un objet qui est « émis » depuis l'endroit où l'erreur est apparue et peut être intercepté par un gestionnaire d'exception conçu pour gérer ce type particulier d'erreur. C'est comme si la gestion des exceptions était un chemin d'exécution parallèle à suivre quand les choses se gâtent. Et parce qu'elle utilise un chemin d'exécution séparé, elle n'interfère pas avec le code s'exécutant normalement. Cela rend le code plus simple à écrire car on n'a pas à vérifier constamment si des erreurs sont survenues. De plus, une exception émise n'est pas comme une valeur de retour d'une fonction signalant une erreur ou un drapeau positionné par une fonction pour indiquer une erreur - ils peuvent être ignorés. Une exception ne peut pas être ignorée, on a donc l'assurance qu'elle sera traitée quelque part. Enfin, les exceptions permettent de revenir d'une mauvaise situation assez facilement. Plutôt que de terminer un programme, il est souvent possible de remettre les choses en place et de restaurer son exécution, ce qui produit des systèmes plus robustes.
Il est bon de noter que le traitement des exceptions n'est pas une caractéristique orientée objet, bien que dans les langages OO une exception soit normalement représentée par un objet. Le traitement des exceptions existait avant les langages orientés objet.
La gestion des exceptions est simplement introduite et utilisée de manière superficielle dans ce volume - le Volume 2 (disponible sur www.BruceEckel.com) traite en profondeur la gestion des exceptions.
1.9. Analyse et conception▲
Le paradigme de la POO constitue une approche nouvelle et différente de la programmation et beaucoup de personnes rencontrent des difficultés pour appréhender leur premier projet orienté objet. Une fois compris que tout est supposé être un objet, et au fur et à mesure qu'on se met à penser dans un style plus orienté objet, on commence à créer de « bonnes » conceptions qui s'appuient sur tous les avantages que la POO offre.
Une méthode(ou méthodologie) est un ensemble de processus et d'heuristiques utilisés pour réduire la complexité d'un problème. Beaucoup de méthodes orientées objet ont été formulées depuis l'apparition de la POO. Cette section vous donne un aperçu de ce que vous essayez d'accomplir en utilisant une méthode.
Spécialement en POO, une méthodologie s'appuie sur un certain nombre d'expériences, il est donc important de comprendre quel problème la méthode tente de résoudre avant d'en adopter une. Ceci est particulièrement vrai avec le C++, qui a été conçu pour réduire la complexité (comparé au C) dans l'écriture d'un programme. Cette philosophie supprime le besoin de méthodologies toujours plus complexes. Au contraire, des méthodologies plus simples peuvent se révéler tout à fait suffisantes avec le C++ pour une classe de problèmes plus large que ce qu'elles pourraient traiter avec des langages procéduraux.
Il est important de réaliser que le terme « méthodologie » est trompeur et promet trop de choses. Tout ce qui est mis en oeuvre quand on conçoit et réalise un programme est une méthode. Ca peut être une méthode personnelle, et on peut ne pas en être conscient, mais c'est une démarche qu'on suit au fur et à mesure de l'avancement du projet. Si cette méthode est efficace, elle ne nécessitera sans doute que quelques petites adaptations pour fonctionner avec le C++. Si vous n'êtes pas satisfait de votre productivité ou du résultat obtenu, vous serez peut-être tenté d'adopter une méthode plus formelle, ou d'en composer une à partir de plusieurs méthodes formelles.
Au fur et à mesure que le projet avance, le plus important est de ne pas se perdre, ce qui est malheureusement très facile. La plupart des méthodes d'analyse et de conception sont conçues pour résoudre même les problèmes les plus gros. Il faut donc bien être conscient que la plupart des projets ne rentrant pas dans cette catégorie, on peut arriver à une bonne analyse et conception avec juste une petite partie de ce qu'une méthode recommande (8). Une méthode de conception, même limitée, met sur la voie bien mieux que si on commence à coder directement.
Il est aussi facile de rester coincé et tomber dans la « paralysie analytique » où on se dit qu'on ne peut passer à la phase suivante car on n'a pas traqué le moindre petit détail de la phase courante. Il faut bien se dire que quelle que soit la profondeur de l'analyse, certains aspects d'un problème ne se révéleront qu'en phase de conception, et d'autres en phase de réalisation, voire même pas avant que le programme ne soit achevé et exécuté. A cause de ceci, il est crucial d'avancer relativement rapidement dans l'analyse et la conception, et d'implémenter un test du système proposé.
Il est bon de développer un peu ce point. A cause des déboires rencontrés avec les langages procéduraux, il est louable qu'une équipe veuille avancer avec précautions et comprendre tous les détails avant de passer à la conception et l'implémentation. Il est certain que lors de la création d'une base de données, il est capital de comprendre à fond les besoins du client. Mais la conception d'une base de données fait partie d'une classe de problèmes bien définie et bien comprise ; dans ce genre de programmes, la structure de la base de données est le problème à résoudre. Les problèmes traités dans ce chapitre font partie de la classe de problèmes « joker » (invention personnelle), dans laquelle la solution n'est pas une simple reformulation d'une solution déjà éprouvée de nombreuses fois, mais implique un ou plusieurs « facteurs joker » - des éléments pour lesquels il n'existe aucune solution préétablie connue, et qui nécessitent de pousser les recherches. (9). Tenter d'analyser à fond un problème joker avant de passer à la conception et l'implémentation mène à la paralysie analytique parce qu'on ne dispose pas d'assez d'informations pour résoudre ce type de problèmes durant la phase d'analyse. Résoudre ce genre de problèmes requiert de répéter le cycle complet, et cela demande de prendre certains risques (ce qui est sensé, car on essaie de faire quelque chose de nouveau et les revenus potentiels en sont plus élevés). On pourrait croire que le risque est augmenté par cette ruée vers une première implémentation, mais elle peut réduire le risque dans un projet joker car on peut tout de suite se rendre compte si telle approche du problème est viable ou non. Le développement d'un produit s'apparente à de la gestion de risque.
Souvent cela se traduit par « construire un prototype qu'il va falloir jeter ». Avec la POO, on peut encore avoir à en jeter une partie, mais comme le code est encapsulé dans des classes, on aura inévitablement produit durant la première itération quelques classes qui valent la peine d'être conservées, et développé des idées sur la conception du système. Ainsi, une première passe rapide sur un problème fournit non seulement des informations critiques pour la prochaine itération d'analyse, de conception et d'implémentation, mais elle produit aussi une base du code pour cette itération.
Ceci dit, si on cherche une méthode qui contient de nombreux détails et suggère de nombreuses étapes et documents, il est toujours difficile de savoir où s'arrêter. Il faut garder à l'esprit ce qu'on essaye de découvrir :
- Quels sont les objets ? (Comment partitionner le projet en ses composants élémentaires ?)
- Quelles en sont les interfaces ? (Quels sont les messages qu'on a besoin d'envoyer à chaque objet ?)
Si on arrive à trouver quels sont les objets et leur interface, alors on peut commencer à coder. On pourra avoir besoin d'autres descriptions et documents, mais on ne peut pas faire avec moins que ça.
Le développement peut être décomposé en cinq phases, et une phase 0 qui est juste l'engagement initial à respecter une structure de base.
1.9.1. Phase 0 : Faire un plan▲
Il faut d'abord décider quelles étapes on va suivre dans le développement. Cela semble simple (en fait, tout semble simple) et malgré tout les gens ne prennent cette décision qu'après avoir commencé à coder. Si le plan se résume à « retroussons nos manches et codons », alors ça ne pose pas de problèmes (quelquefois c'est une approche valable quand on a affaire à un problème bien connu). Mais il faut néanmoins accepter que ce soit le plan.
On peut aussi décider dans cette phase qu'une structure additionnelle est nécessaire. Certains programmeurs aiment travailler en « mode vacances » sans structure imposée sur le processus de développement de leur travail : « Ce sera fait lorsque ce sera fait ». Cela peut être séduisant un moment, mais disposer de quelques jalons aide à se concentrer et focalise les efforts sur ces jalons au lieu d'être obnubilé par le but unique de « finir le projet ». De plus, cela divise le projet en parties plus petites, ce qui le rend moins redoutable (sans compter que les jalons offrent des opportunités de fête).
Quand j'ai commencé à étudier la structure des histoires (afin de pouvoir un jour écrire un roman), j'étais réticent au début à l'idée de structure, trouvant que quand j'écrivais, je laissais juste la plume courir sur le papier. Mais j'ai réalisé plus tard que quand j'écris à propos des ordinateurs, la structure est suffisamment claire pour que je n'y réfléchisse pas trop. Mais je structure tout de même mon travail, bien que ce soit inconsciemment dans ma tête. Donc même si on pense que le plan est juste de commencer à coder, on passe tout de même par les phases successives en se posant certaines questions et en y répondant.
L'exposé de la mission
Tout système qu'on construit, quelle que soit sa complexité, a un but, un besoin fondamental qu'il satisfait. Si on peut voir au delà de l'interface utilisateur, des détails spécifiques au matériel - ou au système -, des algorithmes de codage et des problèmes d'efficacité, on arrive finalement au coeur du problème, simple et nu. Comme le soi-disant concept fondamental d'un film hollywoodien, on peut le décrire en une ou deux phrases. Cette description pure est le point de départ.
Le concept fondamental est assez important car il donne le ton du projet ; c'est l'exposé de la mission. Ce ne sera pas nécessairement le premier jet qui sera le bon (on peut être dans une phase ultérieure du projet avant qu'il ne soit complètement clair), mais il faut continuer d'essayer jusqu'à ce que ça sonne bien. Par exemple, dans un système de contrôle de trafic aérien, on peut commencer avec un concept fondamental basé sur le système qu'on construit : « Le programme tour de contrôle garde la trace d'un avion ». Mais cela n'est plus valable quand le système se réduit à un petit aérodrome, avec un seul contrôleur ou même aucun. Un modèle plus utile ne décrira pas tant la solution qu'on crée que le problème : « Des avions arrivent, déchargent, partent en révision, rechargent et repartent ».
1.9.2. Phase 1 : Que construit-on ?▲
Dans la génération précédente de conception de programmes ( conception procédurale), cela s'appelait « l' analyse des besoins et les spécifications du système». C'étaient des endroits où on se perdait facilement, avec des documents au nom intimidant qui pouvaient occulter le projet. Leurs intentions étaient bonnes, pourtant. L'analyse des besoins consiste à « faire une liste des indicateurs qu'on utilisera pour savoir quand le travail sera terminé et le client satisfait ». Les spécifications du système consistent en « une description de ce que le programme fera (sans ce préoccuper du comment) pour satisfaire les besoins ». L'analyse des besoins est un contrat entre le développeur et le client (même si le client travaille dans la même entreprise ou se trouve être un objet ou un autre système). Les spécifications du système sont une exploration générale du problème, et en un sens permettent de savoir s'il peut être résolu et en combien de temps. Comme ils requièrent des consensus entre les intervenants sur le projet (et parce qu'ils changent au cours du temps), il vaut mieux les garder aussi bruts que possible - idéalement en tant que listes et diagrammes - pour ne pas perdre de temps. Il peut y avoir d'autres contraintes qui demandent de produire de gros documents, mais en gardant les documents initiaux petits et concis, cela permet de les créer en quelques sessions de brainstorming avec un leader qui affine la description dynamiquement. Cela permet d'impliquer tous les acteurs du projet, et encourage la participation de toute l'équipe. Plus important encore, cela permet de lancer un projet dans l'enthousiasme.
Il est nécessaire de rester concentré sur ce qu'on essaye d'accomplir dans cette phase : déterminer ce que le système est supposé faire. L'outil le plus utile pour cela est une collection de ce qu'on appelle « cas d'utilisation ». Les cas d'utilisation identifient les caractéristiques clefs du système qui vont révéler certaines des classes fondamentales qu'on utilisera. Ce sont essentiellement des réponses descriptives à des questions comme (10):
- « Qui utilisera le système ? »
- « Que peuvent faire ces personnes avec le système ? »
- « Comment tel acteur fait-il cela avec le système ? »
- « Comment cela pourrait-il fonctionner si quelqu'un d'autre faisait cela, ou si le même acteur avait un objectif différent ? » (pour trouver les variations)
- « Quels problèmes peuvent apparaître quand on fait cela avec le système ? » (pour trouver les exceptions)
Si on conçoit un guichet automatique, par exemple, le cas d'utilisation pour un aspect particulier des fonctionnalités du système est capable de décrire ce que le guichet fait dans chaque situation possible. Chacune de ces situations est appelée un scénario, et un cas d'utilisation peut être considéré comme une collection de scénarios. On peut penser à un scénario comme à une question qui commence par « Qu'est-ce que le système fait si... ? ». Par exemple, « Qu'est que le guichet fait si un client vient de déposer un chèque dans 24 heures et qu'il n'y a pas assez dans le compte sans le chèque pour fournir le retrait demandé ? ».
Les diagrammes de cas d'utilisations sont voulus simples pour ne pas se perdre prématurément dans les détails de l'implémentation du système :
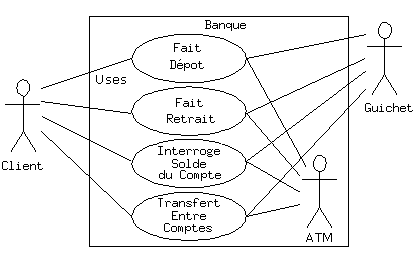
Chaque bonhomme représente un « acteur », typiquement une personne ou une autre sorte d'agent (cela peut même être un autre système informatique, comme c'est le cas avec « ATM »). La boîte représente les limites du système. Les ellipses représentent les cas d'utilisation, qui sont les descriptions des actions qui peuvent être réalisées avec le système. Les lignes entre les acteurs et les cas d'utilisation représentent les interactions.
Tant que le système est perçu ainsi par l'utilisateur, son implémentation n'est pas importante.
Un cas d'utilisation n'a pas besoin d'être complexe, même si le système sous-jacent l'est. Il est seulement destiné à montrer le système tel qu'il apparaît à l'utilisateur. Par exemple:

Les cas d'utilisation produisent les spécifications des besoins en déterminant toutes les interactions que l'utilisateur peut avoir avec le système. Il faut trouver un ensemble complet de cas d'utilisations du système, et cela terminé on se retrouve avec le coeur de ce que le système est censé faire. La beauté des cas d'utilisation est qu'ils ramènent toujours aux points essentiels et empêchent de se disperser dans des discussions non essentielles à la réalisation du travail à faire. Autrement dit, si on dispose d'un ensemble complet de cas d'utilisation on peut décrire le système et passer à la phase suivante. Tout ne sera pas parfaitement clair dès le premier jet, mais ça ne fait rien. Tout se décantera avec le temps, et si on cherche à obtenir des spécifications du système parfaites à ce point on se retrouvera coincé.
Si on est bloqué, on peut lancer cette phase en utilisant un outil d'approximation grossier : décrire le système en quelques paragraphes et chercher les noms et les verbes. Les noms suggèrent les acteurs, le contexte des cas d'utilisation ou les objets manipulés dans les cas d'utilisation. Les verbes suggèrent les interactions entre les acteurs et les cas d'utilisation, et spécifient les étapes à l'intérieur des cas d'utilisation. On verra aussi que les noms et les verbes produisent des objets et des messages durant la phase de design (on peut noter que les cas d'utilisation décrivent les interactions entre les sous-systèmes, donc la technique « des noms et des verbes » ne peut être utilisée qu'en tant qu'outil de brainstorming car il ne fournit pas les cas d'utilisation (11)).
La frontière entre un cas d'utilisation et un acteur peut révéler l'existence d'une interface utilisateur, mais ne définit pas cette interface utilisateur. Pour une méthode de définition et de création d'interfaces utilisateur, se référer à Software for Use de Larry Constantine et Lucy Lockwood, (Addison Wesley Longman, 1999) ou sur www.ForUse.com.
Bien que cela tienne plus de l'art obscur, à ce point un calendrier de base est important. On dispose maintenant d'une vue d'ensemble de ce qu'on construit et on peut donc se faire une idée du temps nécessaire à sa réalisation. Un grand nombre de facteurs entre en jeu ici. Si on surestime le temps de travail, l'entreprise peut décider d'abandonner le projet (et utiliser leurs ressources sur quelque chose de plus raisonnable - ce qui est une bonne chose). Ou un directeur peut avoir déjà décidé du temps que le projet devrait prendre et voudra influencer les estimations. Mais il vaut mieux proposer un calendrier honnête et prendre les décisions importantes au début. Beaucoup de techniques pour obtenir des calendriers précis ont été proposées (de même que pour prédire l'évolution de la bourse), mais la meilleure approche est probablement de se baser sur son expérience et son intuition. Proposer une estimation du temps nécessaire pour réaliser le système, puis doubler cette estimation et ajouter 10 pour cent. L'estimation initiale est probablement correcte, on peut obtenir un système fonctionnel avec ce temps. Le doublement transforme le délai en quelque chose de décent, et les 10 pour cent permettront de poser le vernis final et de traiter les détails. (12). Peu importe comment on l'explique et les gémissements obtenus quand on révèle un tel planning, il semble juste que ça fonctionne de cette façon.
1.9.3. Phase 2 : Comment allons-nous le construire ?▲
Dans cette phase on doit fournir une conception qui décrive ce à quoi les classes ressemblent et comment elles interagissent. Un bon outil pour déterminer les classes et les interactions est la méthode des cartes Classes-Responsabilités-Collaboration(CRC). L'un des avantages de cet outil est sa simplicité : on prend des cartes vierges et on écrit dessus au fur et à mesure. Chaque carte représente une classe, et sur la carte on écrit :
- Le nom de la classe. Il est important que le nom de cette classe reflète l'essence de ce que la classe fait, afin que sa compréhension soit immédiate.
- Les « responsabilités » de la classe : ce qu'elle doit faire. Typiquement, cela peut être résumé par le nom des fonctions membres (puisque ces noms doivent être explicites dans une bonne conception), mais cela n'empêche pas de compléter par d'autres notes. Pour s'aider, on peut se placer du point de vue d'un programmeur fainéant : quels objets voudrait-on voir apparaître pour résoudre le problème ?
- Les « collaborations » de la classe : avec quelles classes interagit-elle ? « Interagir » est intentionnellement évasif, il peut se référer à une agrégation ou indiquer qu'un autre objet existant va travailler pour le compte d'un objet de la classe. Les collaborations doivent aussi prendre en compte l'audience de cette classe. Par exemple, si on crée une classe Pétard, qui va l'observer, un Chimiste ou un Spectateur? Le premier voudra connaître la composition chimique, tandis que le deuxième sera préoccupé par les couleurs et le bruit produits quand il explose.
On pourrait se dire que les cartes devraient être plus grandes à cause de toutes les informations qu'on aimerait mettre dessus, mais il vaut mieux les garder les plus petites possibles, non seulement pour concevoir de petites classes, mais aussi pour éviter de plonger trop tôt dans les détails. Si on ne peut pas mettre toutes les informations nécessaires à propos d'une classe sur une petite carte, la classe est trop complexe (soit le niveau de détails est trop élevé, soit il faut créer plus d'une classe). La classe idéale doit être comprise en un coup d'oeil. L'objectif des cartes CRC est de fournir un premier jet de la conception afin de saisir le plan général pour pouvoir ensuite affiner cette conception.
L'un des avantages des cartes CRC réside dans la communication. Il vaut mieux les réaliser en groupe, sans ordinateur. Chacun prend le rôle d'une ou plusieurs classes (qui au début n'ont pas de nom ni d'information associée). Il suffit alors de dérouler une simulation impliquant un scénario à la fois, et décider quels messages sont envoyés aux différents objets pour satisfaire chaque scénario. Au fur et à mesure du processus, on découvre quelles sont les classes nécessaires, leurs responsabilités et collaborations, et on peut remplir les cartes. Quand tous les scénarios ont été couverts, on devrait disposer d'une bonne approximation de la conception.
Avant d'utiliser les cartes CRC, la meilleure conception initiale que j'ai fourni sur un projet fut obtenue en dessinant des objets sur un tableau devant une équipe qui n'avait jamais participé à un projet de POO auparavant. Nous avons discuté de la communication entre ces objets, effacé et remplacé certains d'entre eux par d'autres objets. De fait, je recréais la méthode des cartes CRC au tableau. L'équipe (qui connaissait ce que le projet était censé faire) a effectivement créé la conception ; et de ce fait ils la contrôlaient. Je me contentais de guider le processus en posant les bonnes questions, proposant quelques hypothèses et utilisant les réponses de l'équipe pour modifier ces hypothèses. La beauté de la chose fut que l'équipe a appris à bâtir une conception orientée objet non en potassant des exemples abstraits, mais en travaillant sur la conception qui les intéressait au moment présent : celle de leur projet.
Une fois qu'on dispose d'un ensemble de cartes CRC, on peut vouloir une description plus formelle de la conception en utilisant l'UML. (13). L'utilisation de l'UML n'est pas une obligation, mais cela peut être utile, surtout si on veut afficher au mur un diagramme auquel tout le monde puisse se référer, ce qui est une bonne idée. Une alternative à l'UML est une description textuelle des objets et de leur interface, ou suivant le langage de programmation, (14).
L'UML fournit aussi une notation pour décrire le modèle dynamique du système. C'est pratique dans les cas où les états de transition d'un système ou d'un sous-système sont suffisamment importants pour nécessiter leurs propres diagrammes (dans un système de contrôle par exemple). On peut aussi décrire les structures de données, pour les systèmes ou sous-systèmes dans lesquels les données sont le facteur dominant (comme une base de données).
On sait que la phase 2 est terminée quand on dispose de la description des objets et de leur interface. Ou du moins de la majorité d'entre eux - il y en a toujours quelques-uns qu'on ne découvre qu'en phase 3. Mais cela ne fait rien. La préoccupation principale est de découvrir tous les objets. Il est plus agréable de les découvrir le plus tôt possible mais la POO est assez souple pour pouvoir s'adapter si on en découvre de nouveaux par la suite. En fait, la conception d'un objet se fait en cinq étapes.
Les cinq étapes de la conception d'un objet
La conception d'un objet n'est pas limitée à la phase de codage du programme. En fait, la conception d'un objet passe par une suite d'étapes. Garder cela à l'esprit permet d'éviter de prétendre à la perfection immédiate. On réalise que la compréhension de ce que fait un objet et de ce à quoi il doit ressembler se fait progressivement. Ceci s'applique d'ailleurs aussi à la conception de nombreux types de programmes ; le modèle d'un type de programme n'émerge qu'après s'être confronté encore et encore au problème (les Design Patterns sont traités dans le Volume 2). Les objets aussi ne se révèlent à la compréhension qu'après un long processus.
1. Découverte de l'objet. Cette étape se situe durant l'analyse initiale du programme. Les objets peuvent être découverts en cherchant les facteurs extérieurs et les frontières, la duplication d'éléments dans le système, et les plus petites unités conceptuelles. Certains objets sont évidents si on dispose d'un ensemble de bibliothèques de classes. La ressemblance entre les classes peut suggérer des classes de base et l'héritage peut en être déduit immédiatement, ou plus tard dans la phase de conception.
2. Assemblage des objets. Lors de la construction d'un objet, on peut découvrir le besoin de nouveaux membres qui n'était pas apparu durant l'étape de découverte. Les besoins internes d'un objet peuvent requérir d'autres classes pour les supporter.
3. Construction du système. Une fois de plus, un objet peut révéler des besoins supplémentaires durant cette étape. Au fur et à mesure de l'avancement du projet, les objets évoluent. Les besoins de la communication et de l'interconnexion avec les autres objets du système peuvent changer les besoins des classes ou demander de nouvelles classes. Par exemple, on peut découvrir le besoin de classes d'utilitaires, telles que des listes chaînées, qui contiennent peu ou pas d'information et sont juste là pour aider les autres classes.
4. Extension du système. Si on ajoute de nouvelles fonctionnalités au système, on peut se rendre compte que sa conception ne facilite pas l'extension du système. Avec cette nouvelle information, on peut restructurer certaines parties du système, éventuellement en ajoutant de nouvelles classes ou de nouvelles hiérarchies de classes.
5. Réutilisation des objets. Ceci est le test final pour une classe. Si quelqu'un tente de réutiliser une classe dans une situation entièrement différente, il y découvrira certainement des imperfections. La modification de la classe pour s'adapter à de nouveaux programmes va en révéler les principes généraux, jusqu'à l'obtention d'un type vraiment réutilisable. Cependant, il ne faut pas s'attendre à ce que tous les objets d'un système soient réutilisables - il est tout à fait légitime que la majorité des objets soient spécifiques au système. Les classes réutilisables sont moins fréquentes, et doivent traiter de problèmes plus génériques pour être réutilisables.
Indications quant au développement des objets
Ces étapes suggèrent quelques règles de base concernant le développement des classes :
- Quand un problème spécifique génère une classe, la laisser grandir et mûrir durant la résolution d'autres problèmes.
- Se rappeler que la conception du système consiste principalement à découvrir les classes dont on a besoin (et leurs interfaces). Si on dispose déjà de ces classes, le projet ne devrait pas être compliqué.
- Ne pas vouloir tout savoir dès le début ; compléter ses connaissances au fur et à mesure de l'avancement du projet. La connaissance viendra de toutes façons tôt ou tard.
- Commencer à programmer ; obtenir un prototype qui marche afin de pouvoir approuver la conception ou au contraire la dénoncer. Ne pas avoir peur de se retrouver avec du code-spaghetti à la procédurale - les classes partitionnent le problème et aident à contrôler l'anarchie. Les mauvaises classes n'affectent pas les classes bien conçues.
- Toujours rester le plus simple possible. De petits objets propres avec une utilité apparente sont toujours mieux conçus que ceux disposant de grosses interfaces compliquées. Quand une décision doit être prise, utiliser l'approche du « rasoir d'Occam » : choisir la solution la plus simple, car les classes simples sont presque toujours les meilleures. Commencer petit et simple, et étendre l'interface de la classe quand on la comprend mieux, mais au fil du temps il devient difficile d'enlever des éléments d'une classe.
1.9.4. Phase 3 : Construire le coeur du système▲
Ceci est la conversion initiale de la conception brute en portion de code compilable et exécutable qui peut être testée, et surtout qui va permettre d'approuver ou d'invalider l'architecture retenue. Ce n'est pas un processus qui se fait en une passe, mais plutôt le début d'une série d'étapes qui vont construire le système au fur et à mesure comme le montre la phase 4.
Le but ici est de trouver le coeur de l'architecture du système qui a besoin d'être implémenté afin de générer un système fonctionnel, sans se soucier de l'état de complétion du système dans cette passe initiale. Il s'agit ici de créer un cadre sur lequel on va pouvoir s'appuyer pour les itérations suivantes. On réalise aussi la première des nombreuses intégrations et phases de tests, et on donne les premiers retours aux clients sur ce à quoi leur système ressemblera et son état d'avancement. Idéalement, on découvre quelques-uns des risques critiques. Des changements ou des améliorations sur l'architecture originelle seront probablement découverts - des choses qu'on n'aurait pas découvert avant l'implémentation du système.
Une partie de la construction du système consiste à confronter le système avec l'analyse des besoins et les spécifications du système (quelle que soit la forme sous laquelle ils existent). Il faut s'assurer en effet que les tests vérifient les besoins et les cas d'utilisations. Quand le coeur du système est stable, on peut passer à la suite et ajouter des fonctionnalités supplémentaires.
1.9.5. Phase 4 : Itérer sur les cas d'utilisation▲
Une fois que le cadre de base fonctionne, chaque fonctionnalité ajoutée est un petit projet en elle-même. On ajoute une fonctionnalité durant une itération, période relativement courte du développement.
Combien de temps dure une itération ? Idéalement, chaque itération dure entre une et trois semaines (ceci peut varier suivant le langage d'implémentation choisi). A la fin de cette période, on dispose d'un système intégré et testé avec plus de fonctionnalités que celles dont il disposait auparavant. Mais ce qu'il est intéressant de noter, c'est qu'un simple cas d'utilisation constitue la base d'une itération. Chaque cas d'utilisation est un ensemble de fonctionnalités qu'on ajoute au système toutes en même temps, durant une itération. Non seulement cela permet de se faire une meilleure idée de ce que recouvre ce cas d'utilisation, mais cela permet de le valider, puisqu'il n'est pas abandonné après l'analyse et la conception, mais sert au contraire tout au long du processus de création.
Les répétitions s'arrêtent quand on dispose d'un système comportant toutes les fonctionnalités souhaitées ou qu'une date limite arrive et que le client se contente de la version courante (se rappeler que les commanditaires dirigent l'industrie du logiciel). Puisque le processus est itératif, on dispose de nombreuses opportunités pour délivrer une version intermédiaire au lieu qu'un produit final ; les projets open-source travaillent uniquement dans un environnement itératif avec de nombreux retours, ce qui précisément les rend si productifs.
Un processus de développement itératif est intéressant pour de nombreuses raisons. Cela permet de révéler et de résoudre des risques critiques très tôt, les clients ont de nombreuses opportunités pour changer d'avis, la satisfaction des programmeurs est plus élevée, et le projet peut être piloté avec plus de précision. Mais un bénéfice additionnel particulièrement important est le retour aux commanditaires du projet, qui peuvent voir grâce à l'état courant du produit où le projet en est. Ceci peut réduire ou éliminer le besoin de réunions soporifiques sur le projet, et améliore la confiance et le support des commanditaires.
1.9.6. Phase 5 : Evolution▲
Cette phase du cycle de développement a traditionnellement été appelée « maintenance », un terme fourre-tout qui peut tout vouloir dire depuis « faire marcher le produit comme il était supposé le faire dès le début » à « ajouter de nouvelles fonctionnalités que le client a oublié de mentionner » au plus traditionnel « corriger les bugs qui apparaissent » et « ajouter de nouvelles fonctionnalités quand le besoin s'en fait sentir ». Le terme « maintenance » a été la cause de si nombreux malentendus qu'il en est arrivé à prendre un sens péjoratif, en partie parce qu'il suggère qu'on a fourni un programme parfait et que tout ce qu'on a besoin de faire est d'en changer quelques parties, le graisser et l'empêcher de rouiller. Il existe peut-être un meilleur terme pour décrire ce qu'il en est réellement.
J'utiliserai plutôt le terme évolution(15). C'est à dire, « Tout ne sera pas parfait dès le premier jet, il faut se laisser la latitude d'apprendre et de revenir en arrière pour faire des modifications ». De nombreux changements seront peut-être nécessaires au fur et à mesure que l'appréhension et la compréhension du problème augmentent. Si on continue d'évoluer ainsi jusqu'au bout, l'élégance obtenue sera payante, à la fois à court et long terme. L'évolution permet de passer d'un bon à un excellent programme, et clarifie les points restés obscurs durant la première passe. C'est aussi dans cette phase que les classes passent d'un statut d'utilité limitée au système à ressources réutilisables.
Ici, « jusqu'au bout » ne veut pas simplement dire que le programme fonctionne suivant les exigences et les cas d'utilisation. Cela veut aussi dire que la structure interne du code présente une logique d'organisation et semble bien s'assembler, sans abus de syntaxe, d'objets surdimensionnés ou de code inutilement exposé. De plus, il faut s'assurer que la structure du programme puisse s'adapter aux changements qui vont inévitablement arriver pendant sa durée vie, et que ces changements puissent se faire aisément et proprement. Ceci n'est pas une petite caractéristique. Il faut comprendre non seulement ce qu'on construit, mais aussi comment le programme va évoluer (ce que j'appelle le vecteur changement(16)). Heureusement, les langages de programmation orientés objet sont particulièrement adaptés à ce genre de modifications continuelles - les frontières créées par les objets sont ce qui empêche la structure du programme de s'effondrer. Ils permettent aussi de faire des changements - même ceux qui seraient considérés comme sévères dans un programme procédural - sans causer de ravages dans l'ensemble du code. En fait le support de l'évolution pourrait bien être le bénéfice le plus important de la programmation orientée objet.
Avec l'évolution, on crée quelque chose qui approche ce qu l'on croit avoir construit, on le compare avec les exigences et on repère les endroits où ça coince. On peut alors revenir en arrière et corriger ça en remodélisant et réimplémentant les portions du programme qui ne fonctionnaient pas correctement (17). De fait, on peut avoir besoin de résoudre le problème ou un de ses aspects un certain nombre de fois avant de trouver la bonne solution (une étude de Design Patterns, dépeinte dans le Volume 2, s'avère généralement utile ici).
Il faut aussi évoluer quand on construit un système, que l'on voit qu'il remplit les exigences et que l'on découvre finalement que ce n'était pas ce que l'on voulait. Quand on se rend compte après avoir vu le système en action qu'on essayait de résoudre un autre problème. Si on pense que ce genre d'évolution est à prendre en considération, alors on se doit de construire une première version aussi rapidement que possible afin de déterminer au plus tôt si c'est réellement ce qu'on veut.
La chose la plus importante à retenir est que par défaut - par définition, plutôt - si on modifie une classe alors ses classes parentes et dérivées continueront de fonctionner. Il ne faut pas craindre les modifications (surtout si on dispose d'un ensemble de tests qui permettent de vérifier les modifications apportées). Les modifications ne vont pas nécessairement casser le programme, et tout changement apporté sera limité aux sous-classes et / ou aux collaborateurs spécifiques de la classe qu'on change.
1.9.7. Les plans sont payants▲
Bien sûr on ne bâtirait pas une maison sans une multitude de plans dessinés avec attention. Si on construit un pont ou une niche pour chien, les plans ne seront pas aussi élaborés mais on démarre avec quelques esquisses pour se guider. Le développement de logiciels a connu les extrêmes. Longtemps les gens ont travaillé sans structure, mais on a commencé à assister à l'effondrement de gros projets. En réaction, on en est arrivé à des méthodologies comprenant un luxe de structure et de détails, destinées justement à ces gros projets. Ces méthodologies étaient trop intimidantes pour qu'on les utilise - on avait l'impression de passer son temps à écrire des documents et aucun moment à coder (ce qui était souvent le cas). J'espère que ce que je vous ai montré ici suggère un juste milieu. Utilisez une approche qui corresponde à vos besoins (et votre personnalité). Même s'il est minimal, la présence d'un plan vous apportera beaucoup dans la gestion de votre projet. Rappelez-vous que selon la plupart des estimations, plus de 50 pour cent des projets échouent (certaines estimations vont jusqu'à 70 pour cent).
En suivant un plan - de préférence un qui soit simple et concis - et en produisant une modélisation de la structure avant de commencer à coder, vous découvrirez que les choses s'arrangent bien mieux que si on se lance comme ça dans l'écriture, et vous en retirerez aussi une plus grande satisfaction. Suivant mon expérience, arriver à une solution élégante procure une satisfaction à un niveau entièrement différent ; cela ressemble plus à de l'art qu'à de la technologie. Et l'élégance est toujours payante, ce n'est pas une vaine poursuite. Non seulement on obtient un programme plus facile à construire et déboguer, mais qui est aussi plus facile à comprendre et maintenir, et c'est là que sa valeur financière réside.
1.10. Extreme programming▲
J'ai étudié à différentes reprises les techniques d'analyse et de conception depuis que je suis sorti de l'école. Le concept de Extreme programming(XP) est le plus radical et divertissant que j'ai vu. Il est rapporté dans Extreme Programming Explained de Kent Beck (Addison-Wesley 2000) et sur le web à www.xprogramming.com.
XP est à la fois une philosophie à propos de la programmation et un ensemble de règles de base. Certaines de ces règles sont reprises dans d'autres méthodologies récentes, mais les deux contributions les plus importantes et novatrices, sont à mon sens « commencer par écrire les tests » et « programmation en binôme ». Bien qu'il soutienne et argumente l'ensemble de la théorie, Beck insiste sur le fait que l'adoption de ces deux pratiques améliore grandement la productivité et la fiabilité.
1.10.1. Commencer par écrire les tests▲
Les tests ont traditionnellement été relégués à la dernière partie d'un projet, une fois que « tout marche, mais c'est juste pour s'en assurer ». Ils ne sont généralement pas prioritaires et les gens qui se spécialisent dedans ne sont pas reconnus à leur juste valeur et se sont souvent vus cantonnés dans un sous-sol, loin des « véritables programmeurs ». Les équipes de test ont réagi en conséquence, allant jusqu'à porter des vêtements de deuil et glousser joyeusement quand ils trouvaient des erreurs (pour être honnête, j'ai eu moi aussi ce genre de sentiments lorsque je mettais des compilateurs C++ en faute).
XP révolutionne complètement le concept du test en lui donnant une priorité aussi importante (ou même plus forte) que le code. En fait, les tests sont écrits avant le code qui est testé, et les tests restent tout le temps avec le code. Ces tests doivent être exécutés avec succès à chaque nouvelle intégration dans le projet (ce qui peut arriver plus d'une fois par jour).
Ecrire les tests d'abord a deux effets extrêmement importants.
Premièrement, cela nécessite une définition claire de l'interface d'une classe. J'ai souvent suggéré que les gens « imaginent la classe parfaite qui résolve un problème particulier » comme outil pour concevoir le système. La stratégie de test de XP va plus loin - elle spécifie exactement ce à quoi la classe doit ressembler pour le client de cette classe, et comment la classe doit se comporter, dans des termes non ambigus. On peut écrire tout ce qu'on veut, ou créer tous les diagrammes décrivant comment une classe devrait se comporter et ce à quoi elle ressemble, mais rien n'est aussi réel qu'une batterie de tests. Le premier est une liste de voeux, mais les tests sont un contrat certifié par un compilateur et un programme qui marche. Il est difficile d'imaginer une description plus concrète d'une classe que les tests.
En créant les tests, on est forcé de penser complètement la classe et souvent on découvre des fonctionnalités nécessaires qui ont pu être manquées lors de l'utilisation des diagrammes UML, des cartes CRC, des cas d'utilisation, etc.
Le deuxième effet important dans l'écriture des tests en premier vient du fait qu'on peut lancer les tests à chaque nouvelle version du logiciel. Cela permet d'obtenir l'autre moitié des tests réalisés par le compilateur. Si on regarde l'évolution des langages de programmation de ce point de vue, on se rend compte que les améliorations réelles dans la technologie ont en fait tourné autour du test. Les langages assembleur vérifiaient uniquement la syntaxe, puis le C a imposé des restrictions sémantiques, et cela permettait d'éviter certains types d'erreurs. Les langages orientés objet imposent encore plus de restrictions sémantiques, qui sont quand on y pense des formes de test. « Est-ce que ce type de données est utilisé correctement ? Est-ce que cette fonction est appelée correctement ? » sont le genre de tests effectués par le compilateur ou le système d'exécution. On a pu voir le résultat d'avoir ces tests dans le langage même : les gens ont été capables de construire des systèmes plus complexes, et de les faire marcher, et ce en moins de temps et d'efforts. Je me suis souvent demandé pourquoi, mais maintenant je réalise que c'est grâce aux tests : si on fait quelque chose de faux, le filet de sécurité des tests intégré au langage prévient qu'il y a un problème et montre même où il réside.
Mais les tests intégrés permis par la conception du langage ne peuvent aller plus loin. A partir d'un certain point, il est de notre responsabilité de produire une suite complète de tests (en coopération avec le compilateur et le système d'exécution) qui vérifie tout le programme. Et, de même qu'il est agréable d'avoir un compilateur qui vérifie ce qu'on code, ne serait-il pas préférable que ces tests soient présents depuis le début ? C'est pourquoi on les écrit en premier, et qu'on les exécute automatiquement à chaque nouvelle version du système. Les tests deviennent une extension du filet de sécurité fourni par le langage.
L'utilisation de langages de programmation de plus en plus puissants m'a permis de tenter plus de choses audacieuses, parce que je sais que le langage m'empêchera de perdre mon temps à chasser les bugs. La stratégie de tests de XP réalise la même chose pour l'ensemble du projet. Et parce qu'on sait que les tests vont révéler tous les problèmes introduits (et on ajoute de nouveaux tests au fur et à mesure qu'on les imagine), on peut faire de gros changements sans se soucier de mettre le projet complet en déroute. Ceci est une approche particulièrement puissante.
1.10.2. Programmation en binôme▲
La programmation en binôme va à l'encontre de l'individualisme farouche endoctriné, depuis l'école (où on réussit ou échoue suivant nos mérites personnels, et où travailler avec ses voisins est considéré comme « tricher ») et jusqu'aux médias, en particulier les films hollywoodiens dans lequel le héros se bat contre la conformité stupide. (18)Les programmeurs aussi sont considérés comme des parangons d'individualisme - des « codeurs cowboys » comme aime à le dire Larry Constantine. Et XP, qui se bat lui-même contre la pensée conventionnelle, soutient que le code devrait être écrit avec deux personnes par station de travail. Et cela devrait être fait dans un endroit regroupant plusieurs stations de travail, sans les barrières dont raffolent les spécialistes de l'aménagement de bureau. En fait, Beck dit que la première tâche nécessaire pour implémenter XP est de venir avec des tournevis et d'enlever tout ce qui se trouve dans le passage (19)(Cela nécessite un responsable qui puisse absorber la colère des responsables de l'équipement).
Dans la programmation en binôme, une personne produit le code tandis que l'autre y réfléchit. Le penseur garde la conception générale à l'esprit, pas seulement la description du problème en cours, mais aussi les règles de XP à portée de main. Si deux personnes travaillent, il y a moins de chance que l'une d'entre elles s'en aille en disant « Je ne veux pas commencer en écrivant les tests », par exemple. Et si le codeur reste bloqué, ils peuvent changer leurs places. Si les deux restent bloqués, leurs songeries peuvent être remarquées par quelqu'un d'autre dans la zone de travail qui peut venir les aider. Travailler en binôme permet de garder une bonne productivité et de rester sur la bonne pente. Probablement plus important, cela rend la programmation beaucoup plus sociable et amusante.
J'ai commencé à utiliser la programmation en binôme durant les périodes d'exercice dans certains de mes séminaires et il semblerait que cela enrichisse l'expérience personnelle de chacun.
1.11. Les raisons du succès du C++▲
Une des raisons pour laquelle le C++ connait autant de succès est qu'il n'a pas pour unique vocation d'apporter au C une approche orientée objet (malgré le fait qu'il ait été conçu dans ce sens), mais il a aussi pour but de résoudre beaucoup d'autres problèmes auxquels font face les développeurs actuels, spécialement ceux qui ont beaucoup investi dans le C. Traditionnellement, les langages orientés objets souffrent du fait que vous devez abandonner tout ce que vous savez déjà et repartir de zéro avec un nouvel ensemble de concepts et une nouvelle syntaxe, argumentant qu'il est bénéfique à long terme de se débarrasser de tout les vieux bagages des langages procéduraux. Cela peut être vrai à long terme. Mais à court terme, beaucoup de ces vieux bagages ont encore de la valeur. L'élément ayant le plus de valeur peut ne pas être le code de base (qui, avec les outils adéquats, peut être traduit), mais plutôt dans la base spirituelle existante. Si vous êtes un développeur C fonctionnel et que vous devez abandonner toutes vos connaissances dans ce langage afin d'en adopter un nouveau, vous devenez immédiatement moins productif pendant plusieurs mois, le temps que votre esprit s'adapte à ce nouveau paradigme. Si l'on considère que vous pouvez conserver vos connaissances en C et les étendre, vous pouvez continuer d'être productif avec vos connaissances actuelles pendant que vous vous tournez vers la POO. Comme tout le monde a son propre modèle mental de programmation, ce changement est suffisamment handicapant pour ne pas avoir à ajouter des coûts de démarrage avec un nouveau modèle de langage. Donc, la raison du succès du C++, en résumé, est économique: Passer à un langage orienté objet a toujours un coût, mais le C++ peut coûter moins. (20)
Le but du C++ est d'augmenter la productivité. Cette productivité peux intervenir en de nombreux points, mais le langage est construit pour vous aider autant que possible, tout en vous gênant le moins possible avec des règles arbitraires ou des conditions à utiliser dans un environnement particulier. Le C++ est conçu pour être pratique; les décisions de conception du langage C++ ont été basées sur l'offre d'un maximum de bénéfice au développeur (au moins, d'un point de vue par rapport au C).
1.11.1. Un meilleur C▲
Vous êtes tout de suite gagnant, même si vous continuez à écrire du code C, car le C++ à comblé de nombreuses lacunes du langage C et offre une meilleure vérification de types ainsi qu'une meilleur analyse du temps de compilation. Vous êtes forcé de déclarer des fonctions ce qui permet au compilateur de vérifier leurs utilisations. La nécessité du préprocesseur a virtuellement été eliminée concernant la substitution de valeurs et les macros, ce qui enlève bon nombre de bugs difficile à trouver. Le C++ possède un dispositif appellé référence qui apporte des facilités pour l'utilisation des adresses concernant les arguments des fonctions et les valeurs de retour. La prise en charge des noms est améliorée avec une fonctionnalité appelée surcharge de fonction, qui vous permet d'utiliser le même nom pour différentes fonction. Un autre dispositif nommé espace de nommage améliore également le contrôle des noms. Il existe de nombreuses autres fonctionnalités moins importantes qui améliorent la sécurité du C.
1.11.2. Vous êtes déjà sur la courbe d'apprentissage.▲
Le problème avec l'apprentissage d'un nouveau langage est la productivité. Aucune entreprise ne peut se permettre de perdre subitement un ingénieur productif parce qu'il apprend un nouveau langage. Le C++ est une extension du C, il n'y a pas de nouvelle syntaxe ni de nouveau modèle de programmation. Il vous permet de continuer de créer du code utile, appliquant graduellement les nouvelles fonctionnalités au fur et à mesure que vous les apprenez et les comprenez. C'est certainement une des plus importantes raisons du succès du C++.
En plus de cela, tout votre code C reste viable en C++, cependant, parce que le compilateur C++ est plus pointilleux, vous trouverez toujours des erreurs C cachées lors de votre compilation en C++.
1.11.3. Efficacité▲
Parfois il est plus approprié de négliger la vitesse d'exécution pour gagner en productivité. Un modèle financier, par exemple, peut être utile pour une courte période de temps, aussi il est plus important de créer le modèle rapidement plutôt que de l'exécuter rapidement. Cependant, la plupart des applications nécessitent un certain degré d'efficacité, aussi, le C++ se range toujours du coté d'une plus grande efficacité. Comme les développeurs ont tendance à avoir un esprit d'efficacité, c'est également une manière de s'assurer qu'ils ne pourront pas arguer que le langage est trop lourd et trop lent. Un grand nombre de fonctionnalités en C++ ont pour objectif de vous permettre de personnaliser les performances lorsque le code généré n'est pas suffisamment efficace.
Non seulement vous avez le même contrôle bas niveau qu'en C (et la possibilité d'écrire directement en assembleur dans un programme C++), mais s'il faut croire ce que l'on dit la rapidité d'un programme orienté objet en C++ tend à être dans les ±10% par rapport à un programme écrit en C, et souvent plus près. (21)La conception produite pour un programme orienté objet peut être réellement plus efficace que sa contrepartie en C.
1.11.4. Les systèmes sont plus faciles à exprimer et à comprendre▲
Les classes conçues pour s'adapter au problème ont tendance à mieux l'exprimer. Cela signifie que quand vous écrivez du code, vous décrivez votre solution dans les termes de l'espace du problème(“Mettre un tore dans le casier”) plutôt que de la décrire dans les termes de la machine (“Activer le bit du circuit integré qui va déclancher la fermeture du relais”). Vous manipulez des concepts de haut niveau et pouvez faire beaucoup plus avec une seule ligne de code.
L'autre bénéfice de cette facilité d'expression est la maintenance, qui (si l'on en croit les rapports) a un énorme coût dans la vie d'un programme. Si un programme est plus simple à comprendre, alors il est plus facile de le maintenir. Cela peut également réduire les coûts de création et de maintenance de la documentation.
1.11.5. Puissance maximale grâce aux bibliothèques▲
La façon la plus rapide de créer un programme est d'utiliser du code déjà écrit : une bibliothèque. Un des buts fondamentaux du C++ est de faciliter l'emploi des bibliothèques. Ce but est obtenu en convertissant ces bibliothèques en nouveaux types de données (classes), et utiliser une bibliothèque revient à ajouter de nouveaux types au langage. Comme le compilateur C++ s'occupe de l'interfaçage avec la bibliothèque - garantissant une initialisation et un nettoyage propres, et s'assurant que les fonctions sont appelées correctement - on peut se concentrer sur ce qu'on attend de la bibliothèque, et non sur les moyens de le faire.
Parce que les noms peuvent être isolés dans une portion de votre programme via les espace de nom C++, vous pouvez utiliser autant de bibliothèques que vous le désirez sans les conflits de noms que vous encourez en C.
1.11.6. Réutilisation des sources avec les templates▲
Il existe une classe significative de types qui exigent une modification du code source avant de pouvoir les réutiliser efficacement. Le dispositif de template en C++ opère une modification du code source automatiquement, ce qui en fait un outil particulièrement performant pour réutiliser les codes des bibliothèques. Un type conçu avec l'utilisation de templates va fonctionner avec moins d'efforts avec beaucoup d'autres types. Les templates sont spécialement intéressants car ils cachent au développeur client la complexité de cette partie de code réutilisée au développeur client.
1.11.7. Traitement des erreurs▲
L'une des difficultés du C est la gestion des erreurs, problème connu et largement ignoré - on compte souvent sur la chance. Si on construit un programme gros et complexe, il n'y a rien de pire que de trouver une erreur enfouie quelque part sans qu'on sache d'où elle vient. Le traitement des exceptions du C++ (introduit dans ce Volume, et traité de manière complète dans le Volume 2, téléchargeable depuis www.BruceEckel.com) est une façon de garantir qu'une erreur a été remarquée, et que quelque chose est mis en oeuvre pour la traiter.
1.11.8. Mise en oeuvre de gros projets▲
Beaucoup de langages traditionnels imposent des limitations internes sur la taille des programmes et leur complexité. BASIC, par exemple, peut s'avérer intéressant pour mettre en oeuvre rapidement des solutions pour certains types de problèmes ; mais si le programme dépasse quelques pages de long ou s'aventure en dehors du domaine du langage, cela revient à tenter de nager dans un liquide encore plus visqueux. C, lui aussi, possède ces limitations. Par exemple, quand un programme dépasse peut-être 50.000 lignes de code, les conflits de noms commencent à devenir un problème - concrètement, vous êtes à court de noms de fonctions et de variables. Un autre problème particulièrement grave est le nombre de lacunes du langage C - les erreurs disséminées au sein d'un gros programme peuvent être extrêmement difficiles à localiser.
Aucune limite ne prévient que le cadre du langage est dépassé, et même s'il en existait, elle serait probablement ignorée. On devrait se dire : « Mon programme BASIC devient trop gros, je vais le réécrire en C ! », mais à la place on tente de glisser quelques lignes supplémentaires pour implémenter cette nouvelle fonctionnalité. Le coût total continue donc à augmenter.
C++ est conçu pour aider à programmer en grand, c'est à dire, qu'il supprime les frontières de complexité qui séparent les petits programmes et les grands. Vous n'avez certainement pas besoin d'utiliser la POO, les templates, les espaces de noms, et autres gestionnaire d'exception quand vous programmez un programme du style "Hello World", cependant ces dispositifs sont là quand vous en avez besoin. De plus, le compilateur est intransigeant quant il s'agit de jeter dehors les erreurs productrices de bugs pour les petits et gros programmes.
1.12. Stratégies de transition▲
Si vous investissez dans la POO, votre prochaine question est probablement "Comment puis-je faire en sorte que mes responsables/collègues/départements/pairs commencent à utiliser des objets?". Demandez-vous comment vous - un programmeur indépendant - voudriez commencer à apprendre à utiliser un nouveau langage et une nouvelle vision de la programmation. Vous avez déjà fait cela auparavant. Premièrement, il y a l'éducation et les exemples ; ensuite arrivent les projets d'essai qui vous donnent les bases sans faire des choses trop déroutantes. Ensuite, vient un projet du "monde réel", qui fait vraiment quelque chose d'utile. Au travers de vos premiers projets, vous continuez votre éducation en lisant, en posant des questions aux experts et en échangeant des petites astuces entre amis. C'est l'approche que de nombreux programmeurs expérimentés suggèrent pour passer du C au C++. Convertir une entreprise entière apportera bien sûr une certaine dynamique de groupe, mais cela aidera à chaque étape de se rappeler comment une seule personne le ferait.
1.12.1. Les grandes lignes▲
Vous trouverez ici les grandes lignes à prendre en compte lors de votre transition vers la POO et le C++ :
1. L'entraînement
La première étape est une forme d'éducation. Rappelez vous de l'investissement de l'entreprise dans du code C, et essayez de ne pas sombrer dans le désarroi pendant six à neuf mois alors que tout le monde cherche à comprendre le fonctionnement de l'héritage multiple. Prenez un petit groupe pour l'endoctrinement, de préférence composé de personnes curieuses, qui travaillent bien ensemble, et sont capables de créer leur propre réseau de soutien tout en apprenant le C++.
Une approche alternative qui est parfois suggérée est la formation de tous les niveaux de la société d'un seul coup, comprenant aussi bien les cours de stratégie pour les directeurs que les cours de conception et programmation pour les chefs de projets. Cette méthode est spécialement bonne pour les plus petites entreprises souhaitant opérer des changements majeurs dans la manière de faire les choses, ou au niveau de la division pour les plus grosses entreprises. Puisque le coût est plus élevé, cependant, certains choisiront de commencer avec un entraînement au niveau du projet, la création d'un projet pilote (peut-être avec un mentor extérieur), et laisseront l'équipe du projet devenir les formateurs du reste de l'entreprise.
2. Projets à faibles risques
Essayez tout d'abord un projet à faibles risques et tenez compte des erreurs. Une fois que vous avez acquis une certaine expérience, vous pouvez soit commencer d'autres projets avec les membres de cette première équipe soit utiliser les membres de l'équipe comme supports techniques de la POO. Ce premier projet ne peut pas fonctionner correctement la première fois, ainsi il ne devrait pas être critique pour la compagnie. Il devrait être simple, d'un seul bloc, et instructif ; ceci signifie qu'il devrait impliquer de créer les classes qui seront significatives pour les autres programmeurs de l'entreprise quand ils commenceront à leur tour à apprendre le C++.
3. Le modèle du succès
Cherchez des exemples d'une bonne conception orientée objet plutôt que commencer à zéro. Il y a une bonne probabilité que quelqu'un ait déjà résolu votre problème, et s'ils ne l'ont pas tout à fait résolu vous pouvez probablement appliquer ce que vous avez appris sur l'abstraction pour modifier une conception existante pour adapter à vos besoins. C'est le concept général des modèles de conception( design patterns), couverts par le Volume 2.
4. Utiliser des bibliothèques de classes existantes
La principale motivation économique pour passer à la POO est la facilité d'utilisation du code existant sous forme de bibliothèques de classe (en particulier, les bibliothèques du Standard C++, qui sont détaillées dans le Volume 2 de ce livre). Le cycle de développement d'application le plus court s'ensuivra quand vous n'aurez rien d'autre à écrire que main( ), en créant et en utilisant des objets de bibliothèques disponibles immédiatement. Cependant, certains nouveaux programmeurs ne le comprennent pas, ignorent les bibliothèques de classe existantes, ou, par fascination du langage, désirent écrire des classes qui existent peut-être déjà. Votre succès avec la POO et le C++ sera optimisé si vous faites un effort de recherche et de réutilisation du code d'autres personnes rapidement dans le processus de transition.
5. Ne réécrivez pas du code existant en C++
Bien que compiler votre code C avec un compilateur C++ a habituellement des avantages (parfois énormes) en trouvant des problèmes dans l'ancien code, la meilleure façon de passer votre temps n'est généralement pas de prendre le code existant, fonctionnel, et de le réécrire en C++. (Si vous devez le transformer en objets, vous pouvez "envelopper" le code C dans des classes C++.) Il y a des avantages importants, particulièrement si le code est prévu pour être réutilisé. Mais il y a des chances que vous ne voyiez pas les augmentations spectaculaires de la productivité que vous espériez dans vos premiers projets à moins que ces projets n'en soient de nouveaux. Le C++ et la POO brillent mieux en prenant un projet de la conception à la réalisation.
1.12.2. Ecueils de la gestion▲
Si vous êtes directeur, votre travail est d'acquérir des ressources pour votre équipe, de franchir les obstacles sur la route du succès de votre équipe, et en général d'essayer de fournir l'environnement le plus productif et le plus agréable possible, ainsi votre équipe est-elle plus susceptible de réaliser ces miracles que vous demandez toujours. Passer au C++ rentre dans chacune de ces trois catégories, et ce serait fantastique si ça ne vous coûtait également rien. Bien que se convertir au C++ peut être meilleur marché - selon vos contraintes (22)- que les alternatives de POO pour une équipe de programmeurs en langage C (et probablement pour des programmeurs dans d'autres langages procéduraux), ce n'est pas gratuit, et il y a des obstacles dont vous devez être conscient avant de tenter de vendre le passage à C++ au sein de votre entreprise et de commencer la transition elle-même.
Coûts de démarrage
Le coût du passage au C++ est plus que simplement l'acquisition des compilateurs C++ (le compilateur GNU C++, un des meilleurs, est gratuit). Vos coûts à moyen et long terme seront réduits au minimum si vous investissez dans la formation (et probablement la tutelle pour votre premier projet) et aussi si vous identifiez et achetez les bibliothèques de classe qui résolvent votre problème plutôt que d'essayer de construire ces bibliothèques par vous-même. Ce sont des coûts financiers bruts qui doivent être pris en compte dans une proposition réaliste. En outre, il y a les coûts cachés dans la perte de productivité lors de l'apprentissage d'un nouveau langage et probablement un nouvel environnement de programmation. La formation et la tutelle peuvent certainement les réduire, mais les membres d'équipe doivent gagner leurs propres luttes pour comprendre la nouvelle technologie. Pendant ce processus ils feront plus d'erreurs (c'est une caractéristique, parce que les erreurs reconnues permettent d'apprendre plus rapidement) et seront moins productifs. Même à ce moment là, avec certains types de problèmes de programmation, les bonnes classes, et le bon environnement de développement, il est possible d'être plus productif en apprenant le C++ (même en considérant que vous faites plus d'erreurs et écrivez moins de lignes de code par jour) qu'en étant resté en C.
Questions de performance
Une question habituelle est, "La POO ne rend-t-elle pas automatiquement mes programmes beaucoup plus volumineux et plus lents ?" La réponse est, "Ca dépend." La plupart des langages traditionnels de POO ont été conçus pour une expérimentation et un prototypage rapide à l'esprit plutôt qu'une cure d'amaigrissement. Ainsi, elles ont pratiquement garanti une augmentation significative de taille et une diminution de la vitesse. Cependant, le C++ est conçu avec la programmation de production à l'esprit. Quand votre accent se porte sur le prototypage rapide, vous pouvez rassembler des composants aussi rapidement que possible tout en ignorant les questions d'efficacité. Si vous utilisez des bibliothèques tierces, elles sont généralement déjà optimisées par leurs fournisseurs ; de toutes façons ce n'est pas un problème si vous êtes en mode de développement rapide. Quand vous avez un système que vous appréciez, s'il est petit et assez rapide, alors c'est bon. Sinon, vous commencez à l'ajuster avec un outil d'analyse, regardant d'abord les accélérations qui peuvent être obtenues avec des applications simples des fonctionnalités intégrées du C++. Si cela n'aide pas, vous recherchez les modifications qui peuvent être faites dans l'implémentation sous-jacente de telle façon qu'aucun code qui utilise une classe particulière n'ait à être changé. C'est seulement si rien d'autre ne résout le problème que vous devez modifier la conception. Le fait que la performance soit si critique dans cette partie de la conception est un indicateur qu'elle doit faire partie des critères principaux de conception. Vous avez l'avantage de le trouver précocement en utilisant le développement rapide.
Comme cité précédemment, le nombre qui est le plus souvent donné pour la différence en taille et en vitesse entre le C et le C++ est ±10%, et souvent beaucoup plus proche de l'égalité. Vous pourriez même obtenir une amélioration significative de taille et de vitesse en utilisant le C++ plutôt que le C parce que la conception que vous faites en C++ pourrait être tout à fait différente de celle que vous feriez en C.
Les comparaisons de taille et de vitesse entre le C et le C++ sont affaire d'opinion et de ouï-dire plutôt que de mesures incontestables, et il est probable qu'elles le restent. Indépendamment du nombre de personnes qui proposent qu'une entreprise teste le même projet en utilisant le C et le C++, aucune société n'est susceptible de gaspiller de l'argent de cette façon à moins qu'elle soit très grande et intéressée par de tels projets de recherche. Même dans ce cas, il semble que l'argent pourrait être mieux dépensé. Presque universellement, les programmeurs qui sont passés du C (ou d'un autre langage procédural) au C++ (ou à un autre langage de POO) ont eu une expérience personnelle de grande accélération dans leur productivité de programmation, et c'est l'argument le plus incontestable que vous pouvez trouver.
Erreurs courantes de conception
Quand vous engagez votre équipe dans la POO et le C++, les programmeurs passeront classiquement par une série d'erreurs communes de conception. Ceci se produit souvent du fait des faibles remontées des experts pendant la conception et l'implémentation des premiers projets, parce qu'aucun expert n'existe encore au sein de l'entreprise et qu'il peut y avoir de la résistance à l'engagement de consultants. Il est facile de s'apercevoir que vous mettez en oeuvre la POO trop tôt dans le cycle et prenez une mauvaise direction. Une évidence pour quelqu'un d'expérimenté dans le langage peut être un sujet de grande débat interne pour un débutant. Une grande part de ce traumatisme peut être évitée en employant un expert extérieur expérimenté pour la formation et la tutelle.
D'autre part, le fait qu'il soit facile de faire ces erreurs de conception montre l'inconvénient principal du C++ : sa compatibilité ascendante avec le C (naturellement, c'est également sa principale force). Pour accomplir l'exploit de pouvoir compiler du code C, le langage a dû faire quelques compromis, qui ont eu comme conséquence un certain nombre de "coins sombres". Ils existent, et constituent une grande partie de la courbe d'apprentissage du langage. Dans ce livre et le volume suivant (et dans d'autres livres ; voir l'annexe C), j'essaierai d'indiquer la plupart des pièges que vous êtes susceptibles de rencontrer en travaillant en C++. Vous devriez toujours être conscient qu'il y a quelques trous dans le filet de sécurité.
1.13. Résumé▲
Ce chapitre tente de vous donner un aperçu des sujets couverts par la programmation orientée objet et le C++ (les raisons qui font que la POO est particulière, de même que le C++), les concepts des méthodologies de la POO, et finalement le genre de problèmes que vous rencontrerez quand vous migrerez dans votre entreprise à la programmation orientée objet et le C++.
La POO et le C++ ne sont pas forcément destinés à tout le monde. Il est important d'évaluer ses besoins et décider si le C++ satisfera au mieux ces besoins, ou si un autre système de programmation ne conviendrait pas mieux (celui qu'on utilise actuellement y compris). Si on connaît ses besoins futurs et qu'ils impliquent des contraintes spécifiques non satisfaites par le C++, alors on se doit d'étudier les alternatives existantes. (23)Et même si finalement le C++ est retenu, on saura au moins quelles étaient les options et les raisons de ce choix.
On sait à quoi ressemble un programme procédural : des définitions de données et des appels de fonctions. Pour trouver le sens d'un tel programme il faut se plonger dans la chaîne des appels de fonctions et des concepts de bas niveau pour se représenter le modèle du programme. C'est la raison pour laquelle on a besoin de représentations intermédiaires quand on conçoit des programmes procéduraux - par nature, ces programmes tendent à être confus car le code utilise des termes plus orientés vers la machine que vers le problème qu'on tente de résoudre.
Parce que le C++ introduit de nombreux nouveaux concepts au langage C, on pourrait se dire que la fonction main() dans un programme C++ sera bien plus compliquée que son équivalent dans un programme C. On sera agréablement surpris de constater qu'un programme C++ bien écrit est généralement beaucoup plus simple et facile à comprendre que son équivalent en C. On n'y voit que les définitions des objets qui représentent les concepts de l'espace problème (plutôt que leur représentation dans l'espace machine) et les messages envoyés à ces objets pour représenter les activités dans cet espace. L'un des avantages de la POO est qu'avec un programme bien conçu, il est facile de comprendre le code en le lisant. De plus, il y a généralement moins de code, car beaucoup de problèmes sont résolus en réutilisant du code existant dans des bibliothèques.