


I. Introduction aux Objets▲
…« Nous découpons la nature, l'organisons en concepts, et attribuons des significations comme nous le faisons, principalement parce que nous sommes les parties d'un accord qui tient dans l'emprise de toute notre société de la parole et est codifié dans les modèles de notre langue… nous ne pouvons pas parler du tout excepté par l'abonnement à l'organisation et à la classification des données que l'accord décrète. » Benjamin Lee Whorf (1897-1941)
La révolution informatique a pris naissance dans une machine. Nos langages de programmation ont donc tendance à ressembler à cette machine.
Mais les ordinateurs ne sont pas tant des machines que des outils au service de l'esprit (« des vélos pour le cerveau », comme aime à le répéter Steve Jobs) et un nouveau moyen d'expression. Ainsi, ces outils commencent à moins ressembler à des machines et plus à des parties de notre cerveau ou d'autres formes d'expressions telles que l'écriture, la peinture, la sculpture ou la réalisation de films. La Programmation Orientée Objet (POO) fait partie de ce mouvement qui utilise l'ordinateur en tant que moyen d'expression.
Ce chapitre présente les concepts de base de la POO, y compris quelques méthodes de développement. Ce chapitre et ce livre présupposent que vous avez déjà expérimenté un langage de programmation procédural, bien que celui-ci ne soit pas forcément le C. Si vous pensez que vous avez besoin de plus de pratique dans la programmation et / ou la syntaxe du C avant de commencer ce livre, vous devriez explorer le CD ROM d'entraînement Foundations for Java, fourni avec ce livre.
Ce chapitre tient plus de la culture générale. Beaucoup de personnes ne veulent pas se lancer dans la programmation orientée objet sans en comprendre l'idée principale. C'est pourquoi nous allons introduire ici de nombreux concepts afin de vous donner un solide aperçu de la POO. Au contraire, certaines personnes ne saisissent les concepts généraux qu'après en avoir vu quelques mécanismes mis en œuvre ; ces gens-là se sentent perdus s'ils n'ont pas un bout de code à se mettre sous la dent. Si vous faites partie de cette catégorie de personnes et êtes impatients d'attaquer les spécificités du langage, vous pouvez sauter ce chapitre - cela ne vous gênera pas pour l'écriture de programme ou l'apprentissage du langage. Mais vous voudrez peut-être y revenir plus tard pour approfondir vos connaissances sur les objets, les comprendre et assimiler la conception objet.
I-A. Les bienfaits de l'abstraction▲
Tous les langages de programmation fournissent des abstractions. On peut dire que la complexité des problèmes qu'on est capable de résoudre est directement proportionnelle au type et à la qualité de nos capacités d'abstraction. Par « type », il faut comprendre « Qu'est-ce qu'on tente d'abstraire ? » Le langage assembleur est une petite abstraction de la machine sous-jacente. Beaucoup de langages « impératifs » (tels que Fortran, BASIC et C) sont des abstractions du langage assembleur. Ces langages sont de nettes améliorations par rapport à l'assembleur, mais leur abstraction première requiert une réflexion en termes de structure ordinateur plutôt que de structure du problème qu'on essaye de résoudre. Le programmeur doit établir l'association entre le modèle de la machine (dans « l'espace solution », qui est l'endroit où le problème est modélisé, tel que l'ordinateur) et le modèle du problème à résoudre (dans « l'espace problème », qui est l'endroit où se trouve le problème). Les efforts requis pour réaliser cette association, et le fait qu'elle est étrangère au langage de programmation, produit des programmes difficiles à écrire et à maintenir, et comme effet de bord a mené à la création de l'industrie du « Génie Logiciel ».
L'autre alternative à la modélisation de la machine est de modéliser le problème qu'on tente de résoudre. Les premiers langages tels que LISP ou APL choisirent une vue particulière du monde (« Tous les problèmes se ramènent à des listes » ou « Tous les problèmes sont algorithmiques », respectivement). PROLOG convertit tous les problèmes en chaînes de décisions. Des langages ont été créés en vue de programmer par contrainte, ou pour programmer en ne manipulant que des symboles graphiques (ces derniers se sont révélés être trop restrictifs). Chacune de ces approches est une bonne solution pour la classe particulière de problèmes pour laquelle ils ont été conçus, mais devient une horreur dès lors que vous les sortez de leur domaine d'application.
L'approche orientée objet va un cran plus loin en fournissant des outils au programmeur pour représenter des éléments dans l'espace problème. Cette représentation se veut assez générale pour ne pas restreindre le programmeur à un type particulier de problèmes. Nous nous référons aux éléments dans l'espace problème et leur représentation dans l'espace solution en tant qu'« objets ». L'idée est que le programme est autorisé à s'adapter à l'esprit du problème en ajoutant de nouveaux types d'objets, de façon à ce que, quand on lit le code décrivant la solution, on lit aussi quelque chose qui décrit le problème. C'est une abstraction plus flexible et puissante que tout ce qu'on a pu voir jusqu'à présent. (2) Ainsi la POO vous permet de décrire le problème dans les termes du problème, plutôt que dans les termes de l'ordinateur sur lequel la solution tournera. Il y a toujours un lien avec l'ordinateur : chaque objet ressemble un peu à un petit ordinateur. Il a un état, et des opérations que vous pouvez lui demander d'exécuter. Cependant, ce ne semble pas être une si mauvaise analogie aux objets du monde réel - ils en ont les caractéristiques et les comportements.
Alan Kay résume les cinq caractéristiques principales de Smalltalk, le premier véritable langage de programmation orienté objet et l'un des langages sur lequel est basé Java. Ces caractéristiques représentent une approche purement orientée objet :
- Tout est objet. Pensez à un objet comme à une variable spéciale ; il stocke les données, mais vous pouvez « faire des requêtes » sur cet objet, lui demander de réaliser des opérations sur lui-même. En théorie, on peut prendre n'importe quel composant conceptuel du problème qu'on essaye de résoudre (un chien, un immeuble, un service administratif… ) et le représenter en tant qu'objet dans le programme.
- Un programme est une série d'objets se disant mutuellement ce qu'ils ont à faire en s'envoyant des messages. Pour faire une requête à un objet, vous « envoyez un message » à cet objet. Plus concrètement, vous pouvez penser à un message comme à un appel à une méthode qui appartient à un objet particulier.
- Chaque objet a son propre espace de mémoire composé d'autres objets. Dit d'une autre manière, on crée un nouveau type d'objet en créant un paquetage contenant des objets déjà existants. Ainsi, la complexité d'un programme est cachée par la simplicité des objets mis en œuvre.
- Chaque objet a un type. En jargon, chaque objet est une instance de sa classe, et ici « classe » est synonyme de « type ». La plus importante caractéristique distinctive d'une classe est : « Quels messages peut-on lui envoyer ? »
- Tous les objets d'un type particulier peuvent recevoir les mêmes messages. C'est vraiment une caractéristique lourde de sens, comme vous le verrez plus tard. Parce qu'un objet de type « Cercle » est aussi un objet de type « forme », un cercle garantit d'accepter les messages des formes. Ce qui veut dire que vous pouvez écrire du code qui parle avec les formes et sera automatiquement accepté par tout ce qui correspond à la description d'une forme. Cette capacité de substitution est l'un des concepts les plus puissants de la POO.
Booch donne une description encore plus succincte d'un objet :
Un objet a un état, un comportement et une identité.
Ce qui veut dire qu'un objet peut avoir des données internes (qui lui donne son état), des méthodes (qui lui donne son comportement), et chaque objet peut être distingué de n'importe quel autre objet - ce qui concrètement veut dire qu'un objet a une adresse unique en mémoire. (3)
I-B. Un objet a une interface▲
Aristote fut probablement le premier à étudier soigneusement le concept de type ; il parla « de la classe des poissons et de la classe des oiseaux ». L'idée que chaque objet, bien qu'étant unique, fait aussi partie d'une classe d'objets qui ont des caractéristiques et des comportements en commun fut utilisée directement dans le premier langage orienté objet, Simula-67, grâce à son mot clé fondamental, class, qui introduit un nouveau type dans un programme.
Simula, comme son nom l'indique, fut créé pour construire des simulations, telles que le problème classique du « guichetier de banque ». Dans cette simulation, on a un groupe de guichetiers, de clients, de comptes, de transactions et d'unités monétaires - soit un grand nombre d'« objets ». Les objets qui sont identiques, hormis leur état durant l'exécution d'un programme, sont regroupés dans des « classes d'objets » ; c'est de là que vient le mot clé class. La création de types abstraits de données (les classes) est un concept fondamental de la programmation orientée objet. Les types abstraits de données fonctionnent presque exactement comme les types intégrés : on peut créer des variables de ce type (appelées objets ou instances dans le jargon orienté objet) et manipuler ces variables (c'est ce qu'on appelle l'envoi de messages ou les requêtes; on envoie un message et l'objet comprend ce qu'il faut faire avec lui). Les membres (éléments) d'une classe donnée ont quelques points en commun : chaque compte a un solde, chaque guichetier peut recevoir un dépôt, etc. Cependant, chaque membre a un état qui lui est propre : chaque compte a un solde différent, chaque guichetier a un nom. De cette manière, guichetiers, clients, comptes, transactions, etc. peuvent être chacun représentés par une entité unique dans le programme informatique. Cette entité est l'objet, et chaque objet appartient à une classe particulière qui définit ses caractéristiques et son fonctionnement.
Ainsi, bien que ce soient de nouveaux types de données que l'on crée réellement dans la programmation orientée objet, tous les langages de programmation orientée objet utilisent en pratique le mot clé « class ». Quand on voit le mot « type », il faut penser « classe » et vice-versa. (4)
Puisqu'une classe décrit un ensemble d'objets qui ont des caractéristiques identiques (éléments d'information) et un fonctionnement identique (fonctionnalités), une classe est vraiment un type de données, parce que, par exemple, un nombre en virgule flottante possède également un ensemble de caractéristiques et de fonctionnalités. La différence est qu'un programmeur définit une classe qui s'adapte à un problème plutôt que d'être contraint d'utiliser un type de données existant qui a été conçu pour représenter une unité de mémoire dans une machine. On étend le langage de programmation en lui ajoutant de nouveaux types de données spécifiques aux besoins que l'on a. Le système de programmation accepte les nouvelles classes, se charge d'elles et vérifie leur type de la même manière qu'il le fait pour les types intégrés.
L'approche orientée objet n'est pas limitée à la construction de simulations. Que vous admettiez ou non que tout programme est une simulation du système en cours de conception, l'utilisation des techniques de POO peut faciliter la réduction d'un grand ensemble de problèmes à une solution simple.
À partir du moment où la classe est créée, on peut fabriquer autant d'objets de cette classe que l'on veut, puis les manipuler comme s'ils étaient les éléments existants dans le problème que l'on essaie de résoudre. En effet, un des défis de la programmation orientée objet est de créer une correspondance univoque entre les éléments dans l'espace du problème et les objets dans l'espace de la solution.
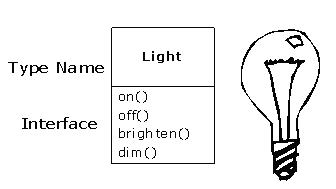
Mais comment obtenir d'un objet qu'il fasse un travail utile pour soi ? Il doit y avoir un moyen de requérir de l'objet qu'il fasse quelque chose, tel qu’effectuer une transaction, tracer quelque chose sur l'écran ou mettre en marche un commutateur. Et chaque objet ne pourra satisfaire que certaines requêtes. Les requêtes que l'on peut faire sur un objet sont définies par son interface, et le type est ce qui détermine l'interface. Un exemple simple pourrait être la représentation d'une ampoule électrique :
Light lt = new Light();
lt.on();L'interface précise quelles requêtes peuvent être faites sur un objet particulier. Néanmoins, il faut du code quelque part pour satisfaire cette requête. Ceci, ainsi que les données cachées, constitue l'implémentation. Du point de vue de la programmation procédurale, ce n'est pas si compliqué que cela. Un type possède une méthode associée à chaque requête possible, et quand on fait une requête particulière sur un objet, cette méthode est appelée. Ce processus est en général résumé en disant que l'on « envoie un message » (on fait une requête) à un objet, et l'objet comprend ce qu'il faut faire avec ce message (il exécute le code).
Ici, le nom du type/de la classe est Light (N.D.T. : lumière), le nom de cet objet Light particulier est lt et les requêtes que l'on peut faire sur un objet Light sont allumer, éteindre, augmenter l'intensité, diminuer l'intensité. On crée un objet Light en définissant une « référence » (lt) à cet objet et en appelant new pour demander un nouvel objet de ce type. Pour envoyer un message à l'objet, on donne le nom de l'objet et on le relie à la demande de message par un point. Du point de vue de l'utilisateur d'une classe prédéfinie, c'est à peu près tout ce que recouvre la programmation objet.
Le diagramme ci-dessus utilise le format du Langage de Modélisation Unifié (UML). Chaque classe est représentée par un rectangle, avec le nom du type dans sa partie haute, tous les membres de données que l'on estime intéressants à décrire dans sa partie médiane et les méthodes (les fonctions qui appartiennent à l'objet, qui reçoivent tout message envoyé à l'objet) dans sa partie basse. Souvent, seuls le nom de la classe et les méthodes publiques sont indiqués dans le rectangle, ce qui fait que la partie médiane n'est pas affichée. Si l'on n'est intéressé que par le nom de la classe, alors on n'a pas besoin non plus d'afficher la partie basse.
I-C. Un objet fournit des services▲
Quand on essaie de développer ou de comprendre la conception d'un programme, une des meilleures façons d'appréhender les objets est d'y penser en tant que « fournisseurs de services ». Votre programme lui-même fournira des services à l'utilisateur et il accomplira cela en utilisant les services offerts par d'autres objets. Votre but est de produire (ou mieux encore de repérer dans des bibliothèques de code existantes) un ensemble d'objets qui fournisse les services idéaux pour résoudre votre problème.
Un moyen de démarrer ce processus est de vous demander « Quels objets résoudraient mon problème, si je pouvais les sortir d'un chapeau comme par magie ? » Supposons, par exemple, que vous êtes en train de créer un programme de comptabilité. Vous pourriez imaginer certains objets qui contiennent des écrans de saisie comptable prédéfinis, un autre ensemble d'objets qui effectuent des calculs comptables et un objet qui gère l'impression des chèques et des factures sur toutes sortes d'imprimantes. Certains de ces objets existent peut-être déjà, et pour ceux qui n'existent pas, à quoi devraient-ils ressembler, quels services ces objets devraient-ils fournir, et de quels objets auraient-ils besoin pour remplir leurs obligations ? Si vous continuez ce processus, vous arriverez à un stade où vous pourrez dire, soit « cet objet est suffisamment simple pour s'arrêter là et le coder », ou bien « je suis sûr que cet objet existe déjà ». C'est une manière réfléchie de décomposer un problème en un ensemble d'objets.
Penser à un objet en tant que fournisseur de services a un autre avantage : cela permet d'améliorer la cohésion de l'objet. Un haut degré de cohésion est une qualité fondamentale de la conception d'un logiciel : cela signifie que les différents aspects d'un composant logiciel (tel un objet, encore que cela pourrait aussi s'appliquer à une méthode ou à une bibliothèque d'objets) « vont bien ensemble ». Un des problèmes que les gens rencontrent quand ils conçoivent des objets est de fourrer beaucoup trop de fonctionnalités dedans. Par exemple, dans votre module d'impression de chèques, vous pourriez décider que vous avez besoin d'un objet qui sait tout du formatage et de l'impression. Vous découvrirez probablement que c'est beaucoup trop pour un objet et que ce dont vous avez besoin est trois objets ou plus. Un des objets pourrait être un catalogue de tous les formats possibles de chèques, que l'on pourrait interroger pour savoir comment imprimer un chèque. Un autre objet ou un jeu d'objets pourrait être une interface générique d'impression qui connaîtrait tous les types d'imprimantes (mais rien à la comptabilité - cet objet serait susceptible d'être acheté plutôt que d'être écrit par vous-même). Et un troisième objet pourrait utiliser les services des deux autres pour accomplir la tâche. Ainsi chaque objet aurait un jeu cohésif de services à offrir. Dans une bonne conception orientée objet, chaque objet fait bien une chose, mais n'essaie pas d'en faire trop. Comme on l'a vu ici, cela permet de découvrir non seulement les objets à acheter éventuellement (l'objet interface imprimante), mais aussi ceux qui pourraient être réutilisés ailleurs (le catalogue de formats de chèques).
Traiter les objets comme des fournisseurs de services est un formidable instrument de simplification. C'est très utile non seulement pendant le processus de conception, mais aussi quand quelqu'un d'autre essaie de comprendre votre code ou de réutiliser un objet - si l'on peut voir la valeur de l'objet sur la base des services qu'il fournit, cela permet de l'adapter beaucoup plus facilement à la conception.
I-D. L'implémentation cachée▲
Il est utile de distinguer les créateurs de classes (ceux qui créent les nouveaux types de données) et les programmeurs clients(5) (les consommateurs de classes qui utilisent ces types de données dans leurs applications). Le but du programmeur client est de se constituer une boîte à outils pleine de classes réutilisables pour le développement rapide d'applications (RAD, Rapid Application Development en anglais). Le but du créateur de classes est la construction d'une classe qui n'expose que ce qui est nécessaire au programmeur client et qui conserve tout le reste caché. Pourquoi cela ? Parce que si une portion de code est cachée, le programmeur client ne pouvant pas y accéder, cela signifie que le créateur de la classe peut la modifier à volonté sans se préoccuper de l'impact que cela pourrait avoir chez les utilisateurs de sa classe. La portion cachée correspond généralement aux parties sensibles d'un objet qui pourraient facilement être corrompues par un programmeur client négligent ou mal informé. Ainsi, cacher l'implémentation réduit considérablement les bogues dans les programmes.
Le concept d'implémentation cachée ne saurait être trop recommandé. Dans n'importe quelle relation, il est important de fixer les frontières à respecter par toutes les parties impliquées. Quand on crée une bibliothèque, on établit une relation avec un programmeur client, programmeur qui assemble une application en utilisant notre bibliothèque, éventuellement pour créer une bibliothèque plus conséquente. Si tous les membres d'une classe sont accessibles par tout le monde, alors le programmeur client peut faire ce qu'il veut avec cette classe et il n'y a aucun moyen de faire respecter les règles. Même s'il est vraiment préférable que l'utilisateur de la classe ne manipule pas directement certains membres de la classe, sans contrôle d'accès, il n'y a aucun moyen de l'en empêcher. Tout est exposé à tout le monde.
La raison première du contrôle d'accès est donc d'empêcher les programmeurs clients de toucher à certaines portions auxquelles ils ne devraient pas avoir accès - parties qui sont nécessaires pour le fonctionnement interne du type de données, mais qui n'appartiennent pas à l'interface dont les utilisateurs ont besoin pour résoudre leur problème. C'est en réalité un service rendu aux utilisateurs, car ils peuvent voir facilement ce qui est important pour leurs besoins et ce qu'ils peuvent ignorer.
La deuxième raison d'être du contrôle d'accès est de permettre au concepteur de la bibliothèque de modifier les mécanismes internes de la classe sans se soucier de la manière avec laquelle cela affectera le programmeur client. Par exemple, on peut implémenter une classe particulière d'une manière simpliste afin de faciliter le développement, et se rendre compte plus tard que l'on a besoin de la réécrire afin de rendre son exécution plus rapide. Si l'interface et l'implémentation sont clairement séparées et protégées, cela peut être réalisé facilement.
Java utilise trois mots clés pour fixer les limites au sein d'une classe : public, private et protected. Leur utilisation et leur signification sont assez explicites. Ces spécificateurs d'accès déterminent qui peut utiliser les définitions qui les suivent. public signifie que l'élément qui le suit est disponible pour tout le monde. Le mot clé private, au contraire, signifie que personne ne peut y accéder, excepté le créateur de la classe à l'intérieur des méthodes de la classe. private est un mur de briques entre le créateur de la classe et le programmeur client. Quelqu'un qui tente d'accéder à un membre défini comme private obtiendra une erreur lors de la compilation. Le mot clé protected se comporte comme private, excepté qu'une classe dérivée a accès aux membres protected, mais pas aux membres private. L'héritage sera présenté plus loin.
Java dispose également d'un accès « par défaut », qui entre en jeu si aucun des spécificateurs d'accès mentionnés précédemment n'est utilisé. Cet accès est généralement appelé accès « amical » (ou « package access »), car les classes peuvent accéder aux membres des autres classes du même package, mais, en dehors du package, ces mêmes membres apparaissent comme s'ils étaient déclarés private.
I-E. Réutilisation de l'implémentation▲
Une fois qu'une classe a été créée et testée, elle devrait (idéalement) représenter une partie de code utile. Il s'avère que cette réutilisabilité n'est pas si facile à obtenir ; cela demande de l'expérience et de l'anticipation pour produire une conception objet réutilisable. Mais une fois bien conçue, cette classe ne demande qu'à être réutilisée. La réutilisation de code est l'un des plus grands avantages offerts par les langages orientés objet.
La manière la plus simple de réutiliser une classe est d'utiliser directement un objet de cette classe, mais on peut aussi placer un objet de cette classe à l'intérieur d'une nouvelle classe. On appelle cela « créer un objet membre ». La nouvelle classe peut être constituée de n'importe quel nombre d'objets d'autres types, selon la combinaison nécessaire pour que la nouvelle classe puisse réaliser ce pour quoi elle a été conçue. Parce que la nouvelle classe est composée à partir de classes existantes, ce concept est appelé composition (si la composition a lieu dynamiquement, on parle d'agrégation). On se réfère souvent à la composition comme à une relation « possède-un », comme dans « une voiture possède un moteur ».
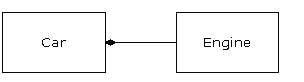
(Ce diagramme UML indique la composition avec le losange rempli, qui indique qu'il y a un moteur dans une voiture. J'utiliserai une forme plus simple : juste une ligne, sans le losange, pour indiquer une association.) (6)
La composition s'accompagne d'une grande flexibilité : les objets membres de la nouvelle classe sont généralement privés, ce qui les rend inaccessibles aux programmeurs clients de la classe. Cela permet de modifier ces membres sans perturber le code des clients existants. On peut aussi changer les objets membres lors la phase d'exécution, pour changer dynamiquement le comportement du programme. L'héritage, décrit juste après, ne dispose pas de cette flexibilité, car le compilateur doit placer des restrictions lors de la compilation sur les classes créées avec héritage.
Parce que la notion d'héritage est très importante au sein de la programmation orientée objet, elle est trop souvent mise en avant, et le nouveau programmeur pourrait croire que l'héritage doit être utilisé partout. Cela mène à des conceptions ultras compliquées et cauchemardesques. La composition est la première approche à examiner lorsqu'on crée une nouvelle classe, car elle est plus simple et plus flexible. Le design de la classe en sera plus propre. Avec de l'expérience, les endroits où utiliser l'héritage deviendront raisonnablement évidents.
I-F. Héritage : réutilisation de l'interface▲
L'idée d'objet en elle-même est un outil efficace. Elle permet de fournir des données et des fonctionnalités liées entre elles par concept, afin de représenter une idée de l'espace problème plutôt que d'être forcé d'utiliser les idiomes internes de la machine. Ces concepts sont exprimés en tant qu'unités fondamentales dans le langage de programmation en utilisant le mot clef class.
Il serait toutefois dommage, après s'être donné beaucoup de mal pour créer une classe de devoir en créer une toute nouvelle qui aurait des fonctionnalités similaires. Ce serait mieux si on pouvait prendre la classe existante, la cloner, et faire des ajouts ou des modifications à ce clone. C'est ce que l'héritage permet de faire, avec la différence suivante : si la classe originale (aussi appelée classe de base, superclasse ou classe parent) est changée, le « clone » modifié (appelé classe dérivée, héritée, enfant ou sous-classe) répercutera aussi ces changements.
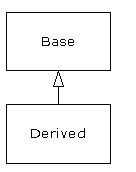
(La flèche dans ce diagramme UML pointe de la classe dérivée vers la classe de base. Comme vous le verrez, il y a souvent plus d'une classe dérivée.)
Un type fait plus que simplement décrire les contraintes d'un ensemble d'objets; il a aussi une relation avec d'autres types. Deux types peuvent avoir des caractéristiques et des comportements en commun, mais un type peut contenir plus de caractéristiques qu'un autre type, et peut aussi gérer plus de messages (ou les gérer différemment). L'héritage exprime cette similarité entre les types en utilisant le concept des types de base et des types dérivés. Un type de base contient tous les caractéristiques et comportements partagés par les types dérivés à partir de lui. On crée un type de base pour représenter le noyau de ses idées à propos de certains objets dans son système. À partir du type de base, on dérive d'autres types pour exprimer les différentes façons dont ce noyau peut être réalisé.
Par exemple, une machine recyclant les ordures trie les morceaux d'ordure. Le type de base est « ordure », et chaque morceau d'ordure a un poids, une valeur, etc., et peut être déchiqueté, fondu, ou décomposé. À partir de là, des types d'ordures plus spécifiques sont dérivés, qui peuvent avoir des caractéristiques additionnelles (une bouteille a une couleur), ou des comportements (une canette en aluminium peut être écrasée, un bidon d'acier est magnétique). En outre, certains comportements peuvent être différents (la valeur du papier dépend de son type et de son état). En utilisant l'héritage, on peut construire une hiérarchie de types qui exprime le problème à résoudre en termes de types.
Un second exemple est l'exemple classique des « formes », peut-être utilisé dans un système de conception assistée par ordinateur, ou un jeu de simulation. Le type de base est « forme », et chaque forme a une taille, une couleur, une position, etc. Chaque forme peut être dessinée, effacée, déplacée, colorée, etc. À partir de là, des types spécifiques de formes sont dérivés (hérités) - cercle, carré, triangle, etc. -, qui peuvent tous avoir des caractéristiques et des comportements additionnels. Certaines formes peuvent être inversées, par exemple. Certains comportements peuvent être différents, comme quand on veut calculer l'aire d'une forme. La hiérarchie de types englobe à la fois les similarités et les différences entre les formes.
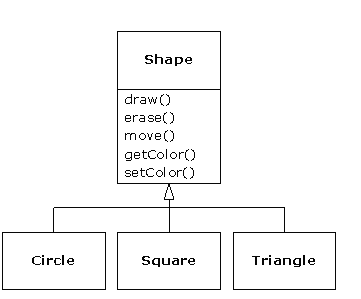
La représentation de la solution dans les mêmes termes que le problème est énormément bénéfique parce que l'on n'a pas besoin de beaucoup de modèles intermédiaires pour aller d'une description du problème à une description de sa solution. Avec des objets, la hiérarchie de types est le modèle primaire, ainsi on va directement de la description du système dans le monde réel à la description du système en code. En effet, l'une des difficultés rencontrées avec la conception orientée objet est qu'il est trop simple d'aller du début à la fin. Un esprit entraîné à chercher des solutions complexes peut être désarçonné par cette simplicité.
En héritant d'un type existant, on crée un nouveau type. Ce dernier, non seulement contient tous les membres du type existant (bien que les membres privés soient cachés et inaccessibles), mais aussi, et c'est le plus important, duplique l'interface de la classe de base. Cela signifie que tous les messages que l'on peut envoyer aux objets de la classe de base peuvent également être envoyés aux objets des classes dérivées. Et puisque l'on reconnaît le type d'une classe en fonction des messages que l'on peut lui envoyer, cela signifie que la classe dérivée est du même type que la classe de base. Dans l'exemple précédent, « un cercle est une forme ». Cette équivalence de types via l'héritage est l'un des points fondamentaux pour la compréhension de la programmation orientée objet.
Comme la classe de base et la classe dérivée ont fondamentalement la même interface, il doit y avoir une implémentation allant avec cette interface. Cela signifie qu'il doit y avoir du code à exécuter quand un objet reçoit un message donné. Si l'on hérite simplement d'une classe sans rien faire d'autre, les méthodes de l'interface de la classe de base sont héritées telles quelles par la classe dérivée. Cela implique que les objets de la classe dérivée n'ont pas seulement le même type, mais aussi le même comportement, ce qui n'est pas particulièrement intéressant.
Il y a deux solutions pour différencier notre nouvelle classe dérivée de la classe de base originale. La première est plutôt franche : on ajoute simplement de nouvelles méthodes à la classe dérivée. Ces nouvelles méthodes ne font pas partie de l'interface de la classe de base. Cela signifie que la classe de base ne faisait pas assez par rapport à ce que nous voulions, donc nous avons ajouté plus de méthodes. Cette utilisation simple et primitive de l'héritage est, parfois, la solution parfaite au problème. Cependant, il faut alors vérifier que la classe de base ne nécessiterait pas l'ajout de ces mêmes nouvelles méthodes. Ce processus de découverte et d'itération de la conception se produit régulièrement dans la programmation orientée objet.
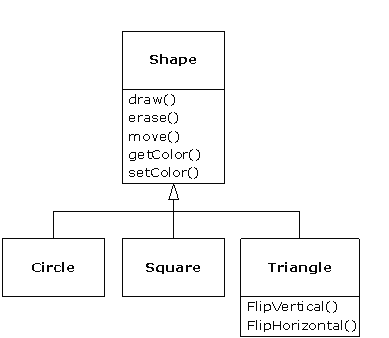
Bien que l'héritage implique parfois (spécialement en Java, où le mot clé pour l'héritage est extends) que l'on va ajouter de nouvelles méthodes à l'interface, ce n'est pas toujours le cas. La deuxième et plus importante solution pour différencier la nouvelle classe est de changer le comportement d'une méthode de la classe de base existante. Cela est appelé surcharger cette méthode.
Pour surcharger une méthode, il suffit de créer une nouvelle définition de cette méthode dans la classe dérivée. On dit « j'utilise la même interface pour cette méthode, mais je veux qu'elle fasse quelque chose de différent pour mon nouveau type ».
I-F-1. Relations est-un versus relations est-comme-un▲
La question de l'héritage soulève un certain débat : l'héritage ne devrait-il pas se contenter, uniquement, de redéfinir les méthodes de la classe parente (et ne pas définir de nouvelles méthodes absentes de cette classe) ? Cela voudrait dire que le type dérivé correspond, exactement, au type de la classe parente, du moment qu'ils partagent exactement la même interface. On pourra, donc, substituer, parfaitement, un objet de la classe dérivée à un objet de la classe parent. Ce genre de substitution pure est souvent appelé principe de substitution. Dans un sens, ce serait la conception idéale de l'héritage. On a, souvent, tendance à qualifier la relation entre la classe parent et la classe dérivée, dans ce cas de figure, de relation est-un, parce qu'on peut dire « un cercle est une forme ». Un test, pour reconnaître la relation d'héritage, serait d'essayer d'appliquer la relation est-un à des classes données et de voir si cela a un sens.
Il existe des cas où il est nécessaire d'ajouter de nouveaux éléments à l'interface du type dérivé, étendant cette interface et créant, ainsi, un nouveau type. Le nouveau type peut toujours remplacer le type parent, mais la substitution n'est pas parfaite puisque les nouvelles méthodes ne sont pas accessibles depuis le type parent.
Cette situation peut être décrite par une relation de type est-comme-un (mon terme). Le nouveau type possède l'interface de l'ancien, mais contient, aussi, d'autres méthodes, c'est pourquoi on ne peut pas vraiment dire qu'il s'agit du même type. Considérons, par exemple, un climatiseur. Supposons que votre maison est équipée pour contrôler le refroidissement de l'air ; en d'autres termes, qu'elle possède une interface permettant de contrôler ce refroidissement. Imaginons, maintenant, que le climatiseur tombe en panne et que vous décidez de le remplacer par une pompe à chaleur, qui peut, à la fois, chauffer et refroidir. La pompe à chaleur est-comme-un climatiseur, mais elle peut faire plus. Puisque le système de contrôle de votre maison est conçu, uniquement, pour contrôler le refroidissement, il ne pourra communiquer qu'avec la partie refroidissement du nouvel objet. L'interface du nouvel objet a été étendue, et le système de contrôle existant ne connaît que l'interface originale.
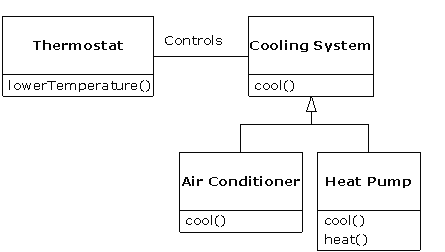
Bien sûr, une fois que vous aurez analysé cette conception, il apparaîtra clairement que « le système de refroidissement » de la classe parente n'est pas suffisamment général et qu'il devrait être renommé « système de contrôle de la température » afin d'inclure la possibilité de chauffage, ce qui rendra possible le principe de substitution. Cette figure représente, néanmoins, un exemple concret de conception dans le monde réel.
Quand on examine le principe de substitution, on a l'impression que cette approche (substitution pure) est la seule manière de concevoir l'héritage, et, en fait, c'est parfait si la conception s'y prête. Mais vous vous apercevrez que, parfois, il est tout aussi évident qu'il faut ajouter de nouvelles méthodes à l'interface d'une classe dérivée. En regardant de plus près la question, les deux cas devraient être assez évidents.
I-G. Objets interchangeables par polymorphisme▲
Quand on a affaire à des hiérarchies de types, on veut souvent traiter un objet non comme le type spécifique qu'il est, mais plutôt comme son type de base. Cela permet d'écrire du code qui ne dépend pas de types spécifiques. Dans l'exemple des formes, les méthodes manipulent des formes génériques sans égard au fait que ce soient des cercles, des carrés, des triangles ou toute autre forme non encore définie. Toutes les formes peuvent être dessinées, supprimées et déplacées, aussi ces méthodes envoient-elles simplement un message à un objet forme ; elles ne s'occupent de savoir comment l'objet réagit au message.
Un tel code reste inchangé lors de l'ajout de nouveaux types, et l'ajout de nouveaux types est la façon la plus courante d'étendre un programme orienté objet afin de gérer de nouvelles situations. Par exemple, on peut dériver un nouveau sous-type de forme appelé pentagone sans modifier les méthodes qui n'opèrent que sur les formes génériques. Cette possibilité d'étendre facilement la conception en dérivant de nouveaux sous-types est l'une des techniques fondamentales d'encapsulation de modifications. Cela améliore grandement la conception tout en réduisant le coût de maintenance du logiciel.
Néanmoins, il y a un problème quand on tente de traiter des objets de type dérivé comme leurs types de base génériques (des cercles comme des formes, des bicyclettes comme des véhicules, des cormorans comme des oiseaux, etc.). Si une méthode est sur le point de dire à une forme générique de se dessiner elle-même, ou à un véhicule générique de se diriger vers un endroit, ou encore à un oiseau générique de se déplacer, le compilateur ne peut pas savoir à la compilation quelle partie précise du code sera exécutée. C'est justement de cela qu'il s'agit - quand le message est envoyé, le programmeur ne veut pas savoir quelle partie du code sera exécutée ; la méthode draw (dessiner) peut être appliquée de la même façon à un cercle, un carré ou un triangle, et l'objet exécutera le code approprié selon son type spécifique. Quand on ne sait pas quelle partie de code sera exécutée, alors on ajoute un nouveau sous-type ; le code qu'il exécutera pourra être différent sans que l'on ait besoin de modifier l'appel de la méthode. Le compilateur ne sait donc pas précisément quelle partie du code sera exécutée, que fait-il alors ? Par exemple, dans le diagramme suivant l'objet BirdController (ContrôleurD'Oiseau) opère uniquement sur des objets génériques Bird (Oiseau) et ne connaît pas leur type exact. C'est parfait du point de vue de BirdController, car il n'a pas besoin d'intégrer un code spécial pour déterminer le type exact de l'objet Bird avec lequel il travaille ou le fonctionnement exact de cet objet. Comment se fait-il donc que lors de l'appel à la méthode move( ) (seDéplacer), le bon fonctionnement se produit, alors même que l'on ignore le type spécifique de l'objet Bird (c'est-à-dire que l'Oie court, vole ou nage et que le Pingouin court ou nage) ?
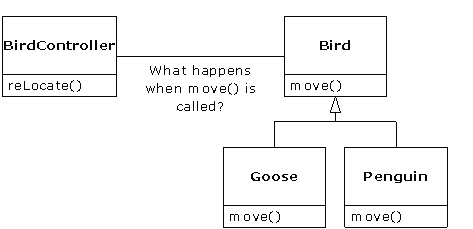
La réponse tient dans la première distorsion de la programmation orientée objet : le compilateur ne peut faire un appel de fonction dans le sens traditionnel. L'appel de fonction généré par un compilateur non OOP est appelé préassociation. C'est un terme que vous n'avez peut-être jamais entendu auparavant, car vous n'avez jamais envisagé qu'un appel de fonction puisse se faire d'une autre manière. Cela signifie que le compilateur génère un appel à un nom de fonction spécifique et que l'éditeur de liens résout cet appel à l'adresse absolue du code à exécuter. En OOP, le programme ne peut déterminer l'adresse du code avant l'exécution, il faut donc utiliser une autre méthode lors de l'envoi du message à un objet générique.
Pour résoudre le problème, les langages orientés objet utilisent le concept d'association tardive. Quand on envoie un message à un objet, le code appelé n'est pas déterminé avant l'exécution. Le compilateur s'assure que la méthode existe et effectue des vérifications de types sur les arguments et sur la valeur retournée (un langage dans lequel ceci n'est pas fait est appelé langage faiblement typé), mais il ne connaît pas le code exact à exécuter.
Pour effectuer l'association tardive, Java utilise une partie de code spéciale au lieu de l'appel absolu. Ce code calcule l'adresse du corps de la méthode, en utilisant les informations stockées dans l'objet (ce processus est couvert en détail au chapitre 7). Ainsi, chaque objet peut se comporter différemment en fonction du contenu de cette partie de code spéciale. Quand on envoie un message à un objet, l'objet arrive en fait à comprendre ce qu'il doit faire avec le message.
Dans certains langages, on doit déclarer explicitement que l'on veut qu'une méthode possède la flexibilité des propriétés d'association tardive (C++ utilise le mot-clé virtual pour ce faire). Par défaut, les méthodes ne sont pas associées dynamiquement dans ces langages. Dans Java, l'association est dynamique par défaut, on n'a donc pas besoin de se souvenir d'ajouter un mot-clé quelconque pour bénéficier du polymorphisme.
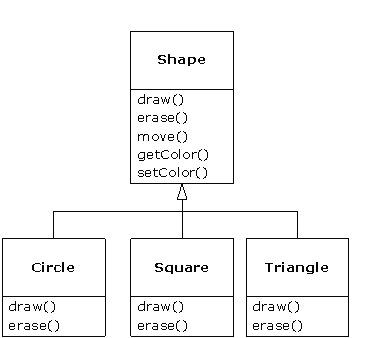
Examinons l'exemple Shape (Forme). La famille des classes (toutes basées sur la même interface uniforme) a été représentée par un diagramme plus haut dans ce chapitre. Pour démontrer le polymorphisme, on veut écrire un bout de code unique qui ignore les détails spécifiques des types et dialogue uniquement avec la classe de base. Ce code est découplé de toute information spécifique au type ; il est donc plus simple à écrire et plus facile à comprendre. De plus, si un nouveau type - un Hexagone par exemple - est ajouté par héritage, le code écrit fonctionnera tout aussi bien pour le nouveau type de Forme que pour les types déjà existants. Ainsi, le programme est extensible.
Si l'on écrit une méthode en Java (ainsi que vous apprendrez à le faire bientôt) :
void doStuff(Shape s) {
s.erase();
// ...
s.draw();
}cette méthode dialogue avec tout objet Shape (Forme). Elle est donc indépendante du type spécifique d'objet dessiné ou effacé. Si une autre partie du programme utilise la méthode doStuff( )(faireQuelqueChose) :
Circle c = new Circle();
Triangle t = new Triangle();
Line l = new Line();
doStuff(c);
doStuff(t);
doStuff(l);les appels à doStuff( ) fonctionnent automatiquement de façon correcte, quel que soit le type exact de l'objet.
C'est une particularité assez étonnante. Examinons la ligne :
doStuff(c);Ici un objet Circle (Cercle) est passé à une méthode qui attend une Forme. Comme un Cercleest une Forme, il peut être traité comme tel par doStuff( ). C'est-à-dire que tout message que doStuff( ) peut envoyer à une Forme est acceptable par un Cercle. Il est donc raisonnable et logique de le faire.
Le processus qui consiste à traiter un type dérivé comme son type de base est appelé transtypage ascendant. Le mot transtypage est utilisé dans le sens de couler dans un moule et le mot ascendant vient de la façon dont le diagramme d'héritage est disposé, avec le type de base en haut et les classes dérivées qui se déploient en éventail vers le bas. Ainsi transtyper vers un type de base, c'est remonter le diagramme d'héritage, d'où le terme : « transtypage ascendant ».
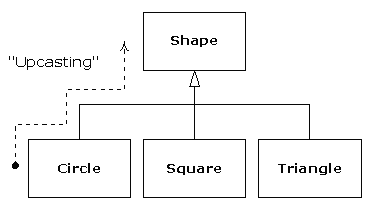
Un programme orienté objet contient quelque part un transtypage ascendant quelconque, car c'est la façon dont on se dégage de l'obligation de savoir avec quel type exact l'on travaille. Observez le code de doStuff( ) :
s.erase();
// ...
s.draw();Notez qu'il ne dit pas « Si vous êtes un Cercle, faites ceci, si vous êtes un Carré, faites cela, etc. ». Si vous écrivez ce genre de code, qui teste tous les types possibles qu'une Forme peut prendre, c'est compliqué et vous devrez le changer chaque fois que vous ajouterez un nouveau type de Forme. Ici, vous dites juste « Vous êtes une forme, je sais que vous pouvez vous effacer (erase) et vous dessiner (draw), faites-le et occupez-vous des détails correctement ».
Ce qui est étonnant dans le code de doStuff( ), c'est que l'action correcte est produite, on ne sait trop comment. L'appel à draw( ) (se dessiner) pour un Cercle fait s'exécuter un code différent de celui exécuté lors de l'appel à draw( ) pour un Carré ou pour une Ligne, mais quand le message draw( ) est envoyé à une Forme anonyme, l'action correcte est exécutée sur la base du type réel de la Forme. C'est étonnant, car, comme mentionné précédemment, quand le compilateur Java compile le code de doStuff( ), il ne peut pas savoir exactement à quel type il aura à faire. On s'attend donc, normalement, à ce qu'il finisse par appeler les versions de erase( ) (effacer) et de draw( ) (dessiner) de la classe de base Shape (Forme), et non celles de la classe spécifique Circle (Cercle), Square (Carré) ou Line (Ligne). Et pourtant tout se passe correctement grâce au polymorphisme. Le compilateur et le système d'exécution gèrent les détails ; tout ce que vous devez savoir pour l'instant est que ceci se produit, et, ce qui est encore plus important, comment concevoir votre programme en en tenant compte. Quand vous enverrez un message à un objet, l'objet fera ce qu'il doit, même lors d'un transtypage ascendant.
I-G-1. Classes mères abstraites et interfaces▲
Souvent dans la conception, vous souhaitez que la classe de base présente seulement une interface à ses classes dérivées. C'est-à-dire que vous voulez que personne ne crée réellement un objet de la classe de base, mais qu'elle soit accédée par transtypage ascendant pour pouvoir utiliser son interface. On réalise cela en rendant la classe abstraite via le mot clé abstract. Si quelqu'un essaye de créer un objet à partir d'une classe abstraite, le compilateur le prévient. C'est un outil qui sert à imposer une conception particulière.
Vous pouvez aussi utiliser le mot clef abstract pour décrire une méthode qui n'a pas encore d'implémentation - comme un squelette de classe indiquant « ici c'est une méthode d'interface pour tous les types hérités de cette classe, mais à ce stade elle n'a pas encore d'implémentation ». Une méthode abstraite ne peut être créée qu'à l'intérieur d'une classe abstraite. Quand la classe est héritée, cette méthode doit être implémentée, ou bien la classe dérivée devient elle aussi abstraite. Créer une méthode abstraite vous permet de mettre une méthode dans une interface sans être obligé de fournir un code sans signification pour cette méthode.
Le mot clef interface pousse le concept de classe abstraite un peu plus loin en interdisant toute définition de méthode. L'interface est un outil très pratique et communément utilisé, car il offre une séparation parfaite entre interface et implémentation. En plus, vous pouvez combiner plusieurs interfaces ensemble, si vous le désirez, alors qu'il est impossible d'hériter de plusieurs classes régulières ou abstraites.
I-H. Création des objets, utilisation et cycle de vie▲
Techniquement, la POO n'est rien d'autre que du typage d'objet abstrait, de l'héritage et du polymorphisme, mais d'autres problèmes peuvent être au moins aussi importants. Cette section va couvrir ces problèmes.
Un des plus importants facteurs des objets est la façon dont ils sont créés et détruits. Où sont les données d'un objet et comment son cycle de vie est-il contrôlé ? Il y a différentes philosophies en œuvre ici. C++ considère que le contrôle de l'efficacité est le point le plus important, aussi donne-t-il le choix au programmeur. Pour une vitesse d'exécution maximum, le stockage et le cycle de vie peuvent être déterminés lorsque le programme est en court d'écriture, en plaçant les objets sur la pile (ceux-ci sont parfois appelés variables automatiques ou variables de portée) ou dans la zone de stockage statique. Ceci place la priorité sur la vitesse de stockage et de libération, et leur contrôle peut être très rentable dans quelques situations. Cependant, vous sacrifiez la flexibilité, car vous devez connaître exactement le nombre exact, le cycle de vie et le type des objets lorsque vous êtes en train d'écrire le programme. Si vous essayez de résoudre un problème plus général comme de la conception assistée par ordinateur, une gestion d'entrepôt ou du contrôle de trafic aérien, cela est trop restrictif.
La seconde approche consiste à créer les objets dynamiquement dans un pool de mémoire appelé le tas. Dans cette approche, vous ne connaissez pas jusqu'à l'exécution de combien d'objets vous avez besoin, quel est leur cycle de vie ou quel est le type exact. Tout cela est déterminé au moment où le programme est exécuté. Si vous avez besoin d'un nouvel objet, vous le fabriquez simplement dans le tas au moment où vous en avez besoin. Comme le stockage est géré dynamiquement, à l'exécution, le temps requis pour allouer le stockage sur le tas peut être notablement plus long que le temps pour créer le stockage sur la pile. (Créer du stockage sur la pile est souvent une simple instruction en assembleur pour déplacer le pointeur de pile vers le bas et une autre pour le remettre en place. Le temps pour créer le stockage sur le tas dépend de la conception du mécanisme de stockage.) L'approche dynamique fait souvent la supposition logique que les objets tendent à être compliqués, aussi la charge supplémentaire pour trouver et libérer le stockage n'aura pas un impact important sur la création de l'objet. De plus, une plus grande flexibilité est essentielle pour résoudre des problèmes de programmation d'ordre général.
Java utilise la seconde approche exclusivement. (7) Chaque fois que vous créez un objet, vous utilisez le mot clé new pour construire une instance dynamique de l'objet.
Il y a un autre problème, cependant, et il s'agit du cycle de vie d'un objet. Avec des langages qui autorisent les objets à être créés sur la pile, le compilateur détermine combien de temps l'objet reste et peut automatiquement le détruire. Cependant, si vous le créez dans le tas, le compilateur n'a aucune connaissance de son temps de vie. Dans un langage comme C++, vous devez déterminer par programmation quand détruire l'objet, ce qui peut conduire à des fuites de mémoire si vous ne le faites pas correctement (et cela est un problème commun dans les programmes C++). Java fournit une fonction appelée un ramasse-miettes qui découvre automatiquement quand un objet n'est plus utilisé et le détruit. Un ramasse-miettes est bien plus pratique, car il réduit le nombre de problèmes que vous devez traquer et le code que vous devez écrire. Bien plus important, le ramasse-miettes fournit un plus grand niveau d'assurance contre les problèmes insidieux de fuite de mémoire (lesquels ont mis sur les rotules de nombreux projets C++).
I-H-1. Collections et itérateurs▲
Si vous ne connaissez pas le nombre d'objets dont vous aurez besoin pour résoudre un problème, ou leur durée de vie, vous ne saurez pas non plus comment stocker ces objets. Comment savoir quel espace sera nécessaire pour ces objets ? Vous ne pouvez pas, dans la mesure où cette information est inconnue jusqu'au lancement du processus.
La solution à la plupart des problèmes dans la conception orientée objet semble relever d'une attitude désinvolte : vous créez un autre type d'objet. Le nouveau type d'objet qui résout ce problème particulier prend des références aux autres objets. Bien entendu, vous pouvez faire la même chose avec un tableau, disponible dans la plupart des langages. Mais ce nouvel objet, généralement appelé un conteneur (aussi appelé une collection, mais la bibliothèque Java utilise ce terme dans un sens différent, donc ce livre utilisera le mot « conteneur »), s'agrandira de lui-même, si nécessaire, afin de s'adapter à tout ce que vous placerez dedans. Par conséquent, vous n'avez pas besoin de connaître le nombre d'objets que vous placerez dans un conteneur. Créez juste un conteneur et laissez-le s'occuper des détails.
Heureusement, un bon langage de programmation orienté-objet est fourni avec un certain nombre de conteneurs intégrés dans le langage. Dans C++, c'est une partie de la bibliothèque standard C++ et elle est parfois appelée la Bibliothèque de Modèles Standard (STL). Pascal Objet possède des conteneurs dans sa Bibliothèque de Composants Visuels (VCL). Smalltalk possède une vaste gamme de conteneurs. Java en possède aussi dans sa bibliothèque standard. Dans certaines bibliothèques, un conteneur générique est considéré comme suffisant pour tous les besoins, et dans d'autres (Java, par exemple) la bibliothèque contient différents types de conteneurs pour des besoins variés : plusieurs sortes différentes de classes List (pour supporter les séquences), des classes Map (aussi connues sous le nom de tableaux associatifs, pour associer des objets les uns aux autres), et des classes Set (pour supporter chacun des types d'objets). Les bibliothèques de conteneurs peuvent aussi contenir des queues, des arbres, des piles, etc.
Tous les conteneurs possèdent un moyen de faire entrer et sortir des éléments ; il y a habituellement des méthodes pour ajouter des éléments à un conteneur, et d'autres pour les récupérer. Mais récupérer un élément peut être plus problématique, car une méthode de sélection unique est restrictive. Que se passe-t-il si vous désirez manipuler ou comparer un ensemble d'éléments du conteneur plutôt qu'un seul élément ?
La solution réside dans un itérateur, un objet dont le rôle consiste à sélectionner les éléments à l'intérieur d'un conteneur et à les présenter à l'utilisateur de l'itérateur. Comme une classe, il offre un certain niveau d'abstraction. Cette abstraction peut être utilisée afin de séparer les détails d'un conteneur du code qui accède à ce conteneur. Le conteneur, par l'intermédiaire de l'itérateur, est abstrait afin de n'être qu'une simple séquence. L'itérateur vous permet de traverser cette séquence sans vous soucier de sa structure sous-jacente, qu'il s'agisse d'une ArrayList, d'une LinkedList, d'une Stack ou de quoi que ce soit d'autre. Cela vous donne la possibilité de changer aisément la structure sous-jacente des données sans perturber le code dans votre programme. Java a commencé (dans les versions 1.0 et 1.1) avec un itérateur standard, appelé Enumeration, pour toutes ses classes conteneur. Java 2 a ajouté une bibliothèque pour les conteneurs beaucoup plus complète, qui contient un itérateur appelé Iterator qui fait beaucoup plus que l'ancien Enumeration.
D'un point de vue conceptuel, tout ce que vous voulez c'est une séquence qui peut être manipulée afin de résoudre votre problème. Si un type unique de séquence pouvait satisfaire tous vos besoins, il n'y aurait aucune raison qu'il en existât plusieurs. Il y a deux raisons pour lesquelles vous avez besoin d'un choix de conteneurs. Premièrement, les conteneurs fournissent différents types d'interfaces et de comportements externes. Une pile a une interface et un comportement différents de ceux d'une queue, qui sont eux-mêmes différents de ceux d'un ensemble ou d'une liste. L'un d'entre eux pourrait fournir une solution plus flexible à votre problème que l'autre. Deuxièmement, les conteneurs ont une efficacité différente pour certaines opérations. Le meilleur exemple est de comparer deux types de List:une ArrayList et une LinkedList. Toutes les deux sont de simples séquences qui peuvent avoir des interfaces et des comportements externes identiques. Mais certaines opérations peuvent avoir des performances radicalement différentes. Accéder de manière aléatoire aux éléments d'une ArrayList est une opération à durée constante; cela prend le même temps, quel que soit l'élément sélectionné. Cependant, il est coûteux de se déplacer dans une LinkedList pour sélectionner un élément de manière aléatoire, et cela prend plus de temps pour trouver un élément plus bas dans la liste. D'un autre côté, si vous voulez insérer un élément au milieu d'une séquence, c'est moins coûteux avec une LinkedList qu'avec une ArrayList. Cette opération et d'autres ont des efficacités différentes selon la structure sous-jacente de la séquence. Dans la phase de conception, vous pourriez commencer avec une LinkedList et, au moment d'affiner les performances, changer pour une ArrayList. Grâce à l'abstraction via la classe de base List et les itérateurs, vous pouvez passer de l'une à l'autre avec un impact minimal sur votre code.
I-H-2. La hiérarchie à racine unique▲
Une des questions en POO qui est devenue particulièrement importante depuis l'introduction du C++ est de savoir si toutes les classes doivent finalement hériter d'une unique classe de base. En Java (comme probablement la plupart des langages OO excepté pour le C++) la réponse est oui, et le nom de cette classe de base unique est Object. Ceci signale que les bénéfices d'une hiérarchie à racine unique sont multiples.
Tous les objets dans une telle hiérarchie ont une interface en commun, ils sont donc tous du même type fondamental. L'alternative (fournie par le C++) est que vous ne savez pas que tout est du même type de base. Du point de vue de la compatibilité ascendante cela coïncide mieux avec le modèle C et peut être perçu comme moins restrictif, mais quand vous voulez programmer intégralement en orienté-objet vous devez alors construire votre propre hiérarchie pour fournir la même facilité qui est intégrée aux autre langages POO. De plus, dans chaque nouvelle bibliothèque que vous acquérez, d'autres interfaces incompatibles seront utilisées. Cela réclame un effort (et potentiellement de l'héritage multiple) pour intégrer cette interface dans la conception. Est-ce que la super « flexibilité » de C++ vaut le coup ? Si vous en avez besoin -si vous avez beaucoup investi dans le C- Cela est sans doute valable. Si vous partez de rien, d'autres alternatives comme Java peuvent être souvent plus productives.
Tous les objets dans une hiérarchie à racine unique (telle que celle que Java fournit) peuvent être garantis pour une certaine fonctionnalité. Vous savez que vous pouvez effectuer certaines opérations élémentaires sur tous les objets de votre système. Une hiérarchie à racine unique, accompagnée de la création de tous les objets sur la pile, simplifie grandement le passage d'arguments (un des sujets les plus complexes en C++).
Une hiérarchie à racine unique simplifie grandement l'implémentation d'un ramasse-miettes (qui est intégré de façon commode dans Java). Le support nécessaire peut être installé dans la classe de base, et le ramasse-miettes peut ainsi envoyer les messages appropriés à chaque objet du système. Sans une hiérarchie à racine unique et un système pour manipuler un objet grâce à une référence, il est difficile d'implémenter un ramasse-miettes.
Puisqu'il est garanti que l'information concernant le type à l'exécution se trouve dans tous les objets, vous ne mettrez jamais fin à un objet dont vous ne pouvez déterminer le type. Cela est d'autant plus important avec les opérations niveau système, telles que la gestion des exceptions, et pour permettre une plus grande flexibilité dans la programmation.
I-H-3. Transtypage descendant vs. modèles/génériques▲
Pour rendre ces conteneurs réutilisables, ils prennent le type unique universel de Java : Object. La hiérarchie à racine unique signifie que toute classe est un Object, par conséquent un conteneur qui contient des Objects peut tout prendre. (8) Cela rend les conteneurs plus faciles à réutiliser.
Pour utiliser un tel conteneur, vous lui ajoutez simplement des références d'objets et les rappelez plus tard. Mais, puisque le conteneur prend seulement des Objects, quand vous ajoutez votre référence d'objet dans le conteneur c'est un transtypage ascendant (upcast) vers Object, cela revient à perdre l'identité de cet objet. Quand vous le rappelez, vous obtenez une référence à un Object, et non une référence du type de celui que vous avez inséré. Alors, comment revenir à quelque chose qui possède l'interface utile de l'objet que vous avez mis dans le conteneur?
Ici, le transtypage est aussi utilisé, mais cette fois vous ne « transtypez pas de manière ascendante » la hiérarchie héritée pour un type plus général. Au lieu de cela, vous « transtypez de manière descendante » (downcast) la hiérarchie pour un type plus spécifique. Cette façon de transtyper est appelée transtypage descendant. Avec le transtypage ascendant, vous savez, par exemple, qu'un Cercle est un genre de Forme il est alors sûr de le transtyper, en revanche, vous ne savez pas nécessairement si un Object est un Cercle ou une Forme il est alors difficile de transtyper de manière descendante de façon sûre à moins de savoir exactement de quoi il s'agit.
Cela n'est pas nécessairement dangereux, pourtant, si vous transtyper de manière descendante pour une classe erronée vous obtiendrez une erreur d'exécution appelée exception, qui sera décrite plus tard. Cependant, quand vous cherchez des références d'objet dans un conteneur, vous devez avoir quelque moyen de vous souvenir exactement de quel type ils sont de manière à procéder à un transtypage descendant approprié.
Le transtypage descendant et la vérification à l'exécution réclament du temps supplémentaire pour le programme exécuté ainsi qu'un effort supplémentaire pour le programmeur. Ne serait-il pas plus sensé, quelque part de créer le conteneur de manière à ce qu'il connaisse les types qu'il prendra, éliminant ainsi la nécessité de transtyper de manière descendante et des erreurs potentielles ? La solution à cela est appelée le mécanisme de type paramétré. Un type paramétré est une classe que le compilateur peut automatiquement adapter afin de fonctionner avec des types particuliers. Par exemple, avec un conteneur paramétré, le compilateur pourrait l'adapter afin qu'il accepte uniquement les Formes et renvoyer uniquement des Formes.
Les types paramétrés sont une partie importante de C++, en partie parce que C++ ne possède pas de hiérarchie à racine unique. En C++, le mot clé qui implémente des types paramétrés est « template ». Java ne possède pas actuellement de types paramétrés puisqu'il lui est possible de passer outre -même maladroitement- en utilisant la hiérarchie à racine unique. Cependant, une proposition actuelle pour les types paramétrés est une syntaxe qui ressemble de façon saisissante aux « templates » de C++, et nous pouvons nous attendre à voir des types paramétrés (qui seront appelés génériques) dans la prochaine version de Java.
I-H-4. Assurer un nettoyage approprié▲
Chaque objet a besoin de ressources, plus spécifiquement de mémoire, afin d'exister. Lorsqu'un objet n'est plus nécessaire, il doit être nettoyé afin que ces ressources soient libérées pour une utilisation future. Dans des situations de programmation simples, la question de la manière de nettoyer un objet ne semble pas excessivement complexe: vous créez l'objet, l'utilisez tant que vous en avez besoin, et alors il devrait être détruit. Cependant, il n'est pas difficile de rencontrer des situations qui sont plus complexes.
Supposez, par exemple, que vous concevez un système qui gère le trafic aérien pour un aéroport. (Le même modèle pourrait être utilisé pour gérer des caisses dans un entrepôt, ou un système de location de vidéos, ou un chenil pour embarquer des animaux.) Au premier abord cela semble simple : créer un conteneur pour prendre les avions, puis créer un nouvel avion et le placer dans le conteneur, et ceci pour chaque avion qui entre dans la zone de contrôle du trafic aérien. Pour le nettoyage, supprimez simplement l'objet avion approprié lorsqu'un avion quitte la zone.
Cependant vous avez peut-être d'autres systèmes pour enregistrer les données concernant les avions; peut-être que les données ne nécessitent pas une même attention immédiate que la fonction principale du contrôleur. Peut-être s'agit-il d'un enregistrement des plans de vol de tous les petits avions qui quittent l'aéroport. Vous avez alors un second conteneur pour les petits avions, et quand vous créez un objet avion vous le mettez aussi dans le second conteneur s'il s'agit d'un petit avion. Alors certains processus d'arrière-plan effectuent des opérations sur les objets dans ce conteneur pendant les moments d'inactivité.
Maintenant le problème est plus difficile : comment pouvez-vous savoir éventuellement quand détruire les objets ? Lorsque vous en avez fini avec l'objet, cela pourrait ne pas être le cas pour d'autres parties de l'application. Ce même problème peut surgir dans d'autres situations, et dans des systèmes de programmation (tels que C++) dans lesquels vous devez explicitement supprimer un objet quand vous en avez fini avec lui et cela peut devenir plutôt complexe.
Avec Java, le ramasse-miettes est conçu pour prendre en charge le problème de la libération de la mémoire (bien que cela n'inclut pas d'autres aspects du nettoyage d'un objet). Le ramasse-miettes « sait » quand un objet n'est plus en cours d'utilisation, et alors il libère automatiquement la mémoire pour cet objet. Ceci (combiné avec le fait que tous les objets sont hérités de la classe racine Object et que vous pouvez créer des objets uniquement sur le tas) rend le processus de programmation en Java beaucoup plus simple qu'en C++. Vous avez beaucoup moins de décisions à prendre et d'obstacles à surmonter.
I-H-5. Ramasses-miettes vs. efficacité et flexibilité▲
Si tout cela est une si bonne idée, pourquoi n'ont-ils pas fait la même chose en C++? Alors bien entendu il y a un prix à payer pour toutes ces facilités de programmation, et ce prix est une surcharge à l'exécution. Comme mentionné auparavant, en C++ vous pouvez créer des objets sur la pile, et dans ce cas ils sont automatiquement nettoyés (mais vous n'avez pas la flexibilité d' en créer autant que vous voulez à l'exécution). Créez des objets sur le tas est le moyen le plus efficace d'allouer du stockage pour l'objet et de libérer ce stockage. Créer des objets sur le tas peut-être infiniment plus coûteux. Toujours hériter une classe de base et rendre tout appel de méthode polymorphique a aussi un petit coût. Mais le ramasse-miette est aussi un problème particulier, car vous ne savez jamais tout à fait le moment où il va démarrer ou combien de temps cela prendra. Cela signifie qu'il y a des fluctuations dans le taux d'exécution d'un programme Java, ce qui fait que vous ne pouvez pas l'utiliser dans certaines situations, comme lorsque le taux d'exécution d'un programme est uniformément critique. (Ces programmes sont généralement appelés temps réel, bien que tous les problèmes de programmation temps-réel ne soient pas tous aussi rigoureux.)
Les concepteurs du langage C++, essayant de courtiser les programmeurs C (et ce le plus efficacement), n'ont pas voulu ajouter une quelconque nouvelle fonctionnalité dans le langage qui aurait pu impacter la vitesse d'utilisation du C++ dans toutes les situations dans lesquelles les programmeurs pourraient tout aussi bien choisir C. Ce but a été atteint, mais au prix d'une plus grande complexité dans la programmation en C++. Java est plus simple que C++, mais la différence réside dans l'efficacité et parfois l'applicabilité. Pour une part significative des problèmes de programmation, cependant, Java est le choix supérieur.
I-I. Traitement des exceptions : gérer les erreurs▲
Depuis les débuts des langages de programmation, le traitement des erreurs s'est révélé l'un des problèmes les plus ardus. Parce qu'il est difficile de concevoir un bon mécanisme de gestion des erreurs, beaucoup de langages ignorent ce problème et le délèguent aux concepteurs de bibliothèques qui fournissent des mécanismes qui fonctionnent dans beaucoup de situations, mais peuvent être facilement contournés, généralement en les ignorant. L'une des faiblesses de la plupart des mécanismes d'erreur est qu'ils reposent sur la vigilance du programmeur à suivre des conventions non imposées par le langage. Si le programmeur n'est pas assez vigilant - ce qui est souvent le cas s'il est pressé - ces mécanismes peuvent facilement être oubliés.
Le système des exceptions pour gérer les erreurs se situe au niveau du langage de programmation et parfois même au niveau du système d'exploitation. Une exception est un objet qui est « émis » depuis l'endroit où l'erreur est apparue et peut être intercepté par un gestionnaire d'exception conçu pour gérer ce type particulier d'erreur. C'est comme si la gestion des exceptions était un chemin d'exécution parallèle à suivre quand les choses se gâtent. Et parce qu'elle utilise un chemin d'exécution séparé, elle n'interfère pas avec le code s'exécutant normalement. Cela rend le code plus simple à écrire, car on n'a pas à vérifier constamment si des erreurs sont survenues. De plus, une exception émise n'est pas comme une valeur de retour d'une fonction signalant une erreur ou un drapeau positionné par une fonction pour indiquer une erreur - ils peuvent être ignorés. Une exception ne peut pas être ignorée, on a donc l'assurance qu'elle sera traitée quelque part. Enfin, les exceptions permettent de revenir d'une mauvaise situation assez facilement. Plutôt que terminer un programme, il est souvent possible de remettre les choses en place et de restaurer son exécution, ce qui produit des programmes plus robustes.
Le traitement des exceptions de Java se distingue parmi les langages de programmation, car en Java le traitement des exceptions a été intégré depuis le début et on est forcé de l'utiliser. Si le code produit ne gère pas correctement les exceptions, le compilateur générera des messages d'erreur. Cette consistance rend la gestion des erreurs bien plus aisée.
Il est bon de noter que le traitement des exceptions n'est pas une caractéristique orientée objet, bien que dans les langages orientés objet une exception soit normalement représentée par un objet. Le traitement des exceptions existait avant les langages orientés objet.
I-J. Concurrence▲
Un concept fondamental dans la programmation informatique est l'idée de la prise en charge de plus d'une tâche à la fois. Beaucoup de problèmes de programmation exigent que le programme puisse arrêter ce qu'il fait, s'occupe d'un autre problème, puis retourne au processus principal. La solution a été approchée de beaucoup de manières. Au commencement, les programmeurs, avec la connaissance des couches de bas niveau de la machine, ont écrit des routines de service d'interruption, et la suspension du processus principal était lancée par une interruption provenant du matériel. Bien que cela fonctionne, ce travail était fastidieux et non portable, déplacer un programme vers un nouveau type de machine étant lent et cher.
Parfois, les interruptions sont nécessaires pour manipuler des tâches critiques, mais il y a un grand nombre de problèmes dans lesquels vous essayez simplement de diviser le problème en morceaux fonctionnant séparément de sorte que le programme entier puisse mieux réagir. Dans un programme, ces morceaux fonctionnant séparément s'appellent les processus (threads en anglais), et le concept général s'appelle concurrence ou environnement multiprocessus(multithreading en anglais). Un exemple commun de multithreading est l'interface utilisateur. En employant des threads, un utilisateur peut appuyer sur un bouton et obtenir une réponse rapide, plutôt que devoir attendre jusqu'à ce que le programme finisse sa tâche en cours.
D'habitude, les threads sont juste une manière d'assigner le temps d'exécution d'un processeur unique. Mais si le système d'exploitation supporte plusieurs processeurs, chaque thread peut être assigné à un processeur différent et tous peuvent fonctionner réellement en parallèle. Une des caractéristiques commodes du multithreading, au niveau de la programmation, est que le programmeur n'a pas besoin de s'inquiéter de savoir s'il y a un seul ou plusieurs processeurs. Le programme est divisé logiquement en threads et si la machine possède plus d'un processeur, le programme s'exécute plus rapidement, sans ajustement particulier.
Tout ceci fait penser que l'utilisation des threads est plutôt simple. Il y a une limitation : les ressources partagées. Si vous avez plus d'un thread en exécution tentant d'accéder à la même ressource, vous avez un problème. Par exemple, deux processus ne peuvent pas simultanément envoyer de l'information à une imprimante. Pour résoudre le problème, les ressources qui peuvent être partagées, comme l'imprimante, doivent être verrouillées tant qu'elles sont employées. Ainsi un thread verrouille l'accès à une ressource, accomplit sa tâche, puis libère le verrou de sorte que quelqu'un d'autre puisse employer la ressource.
La gestion des threads Java est incluse dans le langage, ce qui rend un sujet compliqué beaucoup plus simple. Le threading est supporté au niveau objet, ainsi un thread est représenté par un objet. Java fournit également un verrouillage limité de ressources. Il peut verrouiller la mémoire de n'importe quel genre d'objet (qui est, après tout, une sorte de ressource partagée) de sorte que seulement un thread puisse l'employer à la fois. Ceci est accompli avec le mot-clé synchronized. D'autres types de ressources doivent être verrouillés explicitement par le programmeur, typiquement en créant un objet pour représenter le verrou que tous les threads doivent vérifier avant d'accéder à cette ressource.
I-K. Persistance▲
Lorsque vous créez un objet, celui-ci existe aussi longtemps que vous en aurez besoin, mais cette existence cesse une fois le programme terminé. Même si cela a un sens à première vue, il peut y avoir des situations où il serait extrêmement utile qu'un objet puisse exister avec ses informations en dehors de l'exécution d'un programme. Ainsi, à la prochaine exécution du programme, l'objet serait toujours là et contiendrait les mêmes informations que lors de la précédente exécution du programme. Bien sûr, vous pouvez obtenir le même résultat en inscrivant les informations dans un fichier ou une base de données, mais pour préserver l'aspect purement objet, il serait plus convenable de pouvoir déclarer un objet persistant sans se préoccuper des détails.
Java fournit un support pour une « persistance légère », ce qui veut dire que vous pouvez, facilement, stocker des objets sur disque et les récupérer plus tard. La raison expliquant « légère » est que vous êtes toujours forcé de faire des appels explicites pour le stockage et la récupération. La persistance légère peut être implémentée à travers, à la fois, la serialization d'objet (voir chapitre 12), et Java Data Objects (JDO, voir Thinking in Enterprise Java).
I-L. Java et Internet▲
Si Java n'est, en fait, qu'un autre langage de programmation, il est légitime de se demander pourquoi il est tellement important et pourquoi il est présenté comme une étape révolutionnaire de la programmation en informatique. La réponse n'est pas évidente à trouver du point de vue traditionnel de la programmation. Bien que Java soit très utile dans la résolution des problèmes traditionnels et autonomes, il est aussi important parce qu'il va résoudre les problèmes de programmation du Web.
I-L-1. Qu'est-ce que le Web ?▲
Le Web peut sembler un peu mystérieux au début, avec tout ce vocabulaire de « surf », « présence », et de « pages personnelles ». Il peut être utile de revenir en arrière et voir ce que c'est réellement, mais auparavant il faut comprendre le modèle client/serveur, un autre aspect de l'informatique relativement déroutant.
I-L-1-a. L'informatique Client/Serveur▲
L'idée principale d'un système client/serveur est que vous disposez d'un dépôt centralisé de l'information, quelques choses avec des données, souvent une base de données, que vous voulez distribuer à la demande à un ensemble de personnes ou de machines. Une clé du concept client/serveur est que le dépôt d'informations est centralisé afin qu'il puisse être changé et que ces changements seront propagés jusqu'aux consommateurs de ces informations. Pris ensemble, le dépôt d'informations, le programme qui distribue l'information , et la (les) machine(s) où les informations et le programme résident est appelé le serveur. Le logiciel qui réside sur la machine distante, communique avec le serveur, récupère l'information, la traite et l'affiche alors sur la machine distante est appelé le client .
Le concept de base du client/serveur n'est donc pas si compliqué. Les problèmes surviennent, car vous avez un unique serveur essayant de servir plusieurs clients à la fois. Généralement, un système de gestion de base de données est concerné, ainsi le concepteur « réparti » les données dans les tables pour une utilisation optimale. De plus, les systèmes permettent souvent au client d'insérer des nouvelles informations dans le serveur. Cela veut dire que vous devez vous assurez que les nouvelles données d'un client ne soient pas en conflit avec les nouvelles données d'un autre client, ou que ces données ne sont pas perdues dans le processus d'ajout and la base de données (cela fait appel aux transactions). Comme les programmes d'application client changent, ils doivent être créés, débogués, et installés sur les machines clientes, ce qui se révèle plus compliqué et onéreux que ce que vous pourriez penser. Cela est particulièrement pour supporter différents types de matériels et de systèmes d'exploitation. Finalement, se pose toujours les problèmes de performance : vous pourriez avoir des centaines de clients effectuant des requêtes à votre serveur en même temps, ainsi tout petit délai est crucial. Pour minimiser les temps de latence, les programmeurs travaillent dur pour réduire la charge de travail des tâches incriminées, souvent sur la machine cliente, mais parfois sur d'autres machines côté serveur, utilisant ce que l'on appelle le middleware. (Le middleware est aussi utilisé pour améliorer la maintenabilité).
L'idée simple de distribuer l'information à différents niveaux de complexité est que le problème en entier peut sembler désespérément énigmatique. Pourtant il est crucial : le client/serveur compte pour environ la moitié des activités de programmation. On le retrouve pour tout ce qui va des transactions de cartes de crédit à la distribution de n'importe quel type de données : économique, scientifique, gouvernementale, il suffit de choisir. Dans le passé, on en est arrivé à des solutions particulières aux problèmes particuliers, obligeant à réinventer une solution à chaque fois. Elles étaient difficiles à créer et à utiliser, et l'utilisateur devait apprendre une nouvelle interface pour chacune. Le problème du client/serveur devait être résolu dans son ensemble.
I-L-1-b. Le Web comme un serveur géant▲
Le Web est en fait un système client/serveur géant. C'est encore pire que ça, puisque tous les serveurs et les clients coexistent en même temps sur un seul réseau. Vous n'avez pas besoin de le savoir d'ailleurs, car tout ce dont vous vous souciez est de vous connecter et d'interagir avec un serveur à la fois (même si vous devez parcourir le monde pour trouver le bon serveur).
Initialement, c'était un processus à sens unique. Vous effectuiez une requête à un serveur et il renvoyait un fichier que votre logiciel de navigation (i.e., le client) interprétait en le formatant sur la machine locale. Cependant rapidement les gens commencèrent à vouloir faire plus que d'afficher des pages d'un serveur. Ils voulaient bénéficier de toutes les fonctionnalités du client/serveur afin que le client puisse renvoyer des informations au serveur, par exemple pour faire des requêtes précises dans la base de données, ajouter de nouvelles informations au serveur, ou passer des commandes (ce qui nécessitait plus de sécurité que ce que le système original offrait). Ce sont les changements auxquels nous assistons dans le développement du Web.
Le navigateur Web fut un grand en avant : Le concept qu'une information pouvait être affichée sur n'importe quel ordinateur sans changement. Cependant, les browsers étaient relativement rudimentaires et ne remplissaient pas toutes les demandes placées en eux. Ils n'étaient pas spécialement interactifs, et avaient tendance à encombrer le serveur et Internet parce que chaque fois que vous aviez besoin de faire quelque chose qui requérait un traitement il fallait renvoyer les informations au serveur pour que celui-ci les traite. Cela pouvait prendre plusieurs secondes ou minutes pour finalement se rendre compte que vous aviez fait une faute de frappe dans la requête. Puisque le navigateur était juste une visionneuse, il ne pouvait pas effectuer le moindre traitement. (D'un autre côté, cela était beaucoup sûr, parce qu'il ne pouvait pas exécuter n'importe quel programme sur votre machine locale qui pouvait contenir des bugs ou des virus).
Pour résoudre ce problème, différentes approches ont été prises. Pour commencer les standards graphiques ont été améliorés pour permettre de meilleures animations et la vidéo dans les navigateurs. Le reste du problème ne peut être résolu qu'en incorporant la possibilité d'exécuter des programmes sur le client, dans le navigateur. C'est ce qu'on appelle la programmation côté client.
I-L-2. Client-side programming▲
The Web's initial server-browser design provided for interactive content, but the interactivity was completely provided by the server. The server produced static pages for the client browser, which would simply interpret and display them. Basic HyperText Markup Language (HTML) contains simple mechanisms for data gathering: text-entry boxes, check boxes, radio boxes, lists and drop-down lists, as well as a button that can only be programmed to reset the data on the form or « submit » the data on the form back to the server. This submission passes through the Common Gateway Interface (CGI) provided on all Web servers. The text within the submission tells CGI what to do with it. The most common action is to run a program located on the server in a directory that's typically called « cgi-bin. » (If you watch the address window at the top of your browser when you push a button on a Web page, you can sometimes see « cgi-bin » within all the gobbledygook there.) These programs can be written in most languages. Perl has been a common choice because it is designed for text manipulation and is interpreted, so it can be installed on any server regardless of processor or operating system. However, Python (my favorite-see www.Python.org) has been making inroads because of its greater power and simplicity.
Many powerful Web sites today are built strictly on CGI, and you can in fact do nearly anything with CGI. However, Web sites built on CGI programs can rapidly become overly complicated to maintain, and there is also the problem of response time. The response of a CGI program depends on how much data must be sent, as well as the load on both the server and the Internet. (On top of this, starting a CGI program tends to be slow.) The initial designers of the Web did not foresee how rapidly this bandwidth would be exhausted for the kinds of applications people developed. For example, any sort of dynamic graphing is nearly impossible to perform with consistency because a Graphics Interchange Format (GIF) file must be created and moved from the server to the client for each version of the graph. And you've no doubt had direct experience with something as simple as validating the data on an input form. You press the submit button on a page; the data is shipped back to the server; the server starts a CGI program that discovers an error, formats an HTML page informing you of the error, and then sends the page back to you; you must then back up a page and try again. Not only is this slow, it's inelegant.
The solution is client-side programming. Most machines that run Web browsers are powerful engines capable of doing vast work, and with the original static HTML approach they are sitting there, just idly waiting for the server to dish up the next page. Client-side programming means that the Web browser is harnessed to do whatever work it can, and the result for the user is a much speedier and more interactive experience at your Web site.
The problem with discussions of client-side programming is that they aren't very different from discussions of programming in general. The parameters are almost the same, but the platform is different; a Web browser is like a limited operating system. In the end, you must still program, and this accounts for the dizzying array of problems and solutions produced by client-side programming. The rest of this section provides an overview of the issues and approaches in client-side programming.
I-L-2-a. Plug-ins▲
One of the most significant steps forward in client-side programming is the development of the plug-in. This is a way for a programmer to add new functionality to the browser by downloading a piece of code that plugs itself into the appropriate spot in the browser. It tells the browser « from now on you can perform this new activity. » (You need to download the plug-in only once.) Some fast and powerful behavior is added to browsers via plug-ins, but writing a plug-in is not a trivial task, and isn't something you'd want to do as part of the process of building a particular site. The value of the plug-in for client-side programming is that it allows an expert programmer to develop a new language and add that language to a browser without the permission of the browser manufacturer. Thus, plug-ins provide a « back door » that allows the creation of new client-side programming languages (although not all languages are implemented as plug-ins).
I-L-2-b. Scripting languages▲
Plug-ins resulted in an explosion of scripting languages. With a scripting language, you embed the source code for your client-side program directly into the HTML page, and the plug-in that interprets that language is automatically activated while the HTML page is being displayed. Scripting languages tend to be reasonably easy to understand and, because they are simply text that is part of an HTML page, they load very quickly as part of the single server hit required to procure that page. The trade-off is that your code is exposed for everyone to see (and steal). Generally, however, you aren't doing amazingly sophisticated things with scripting languages, so this is not too much of a hardship.
This points out that the scripting languages used inside Web browsers are really intended to solve specific types of problems, primarily the creation of richer and more interactive graphical user interfaces (GUIs). However, a scripting language might solve 80 percent of the problems encountered in client-side programming. Your problems might very well fit completely within that 80 percent, and since scripting languages can allow easier and faster development, you should probably consider a scripting language before looking at a more involved solution such as Java or ActiveX programming.
The most commonly discussed browser scripting languages are JavaScript (which has nothing to do with Java; it's named that way just to grab some of Java's marketing momentum), VBScript (which looks like Visual BASIC), and Tcl/Tk, which comes from the popular cross-platform GUI-building language. There are others out there, and no doubt more in development.
JavaScript is probably the most commonly supported. It comes built into both Netscape Navigator and the Microsoft Internet Explorer (IE). Unfortunately, the flavor of JavaScript on the two browsers can vary widely (the Mozilla browser, freely downloadable from www.Mozilla.org, supports the ECMAScript standard, which may one day become universally supported). In addition, there are probably more JavaScript books available than there are for the other browser languages, and some tools automatically create pages using JavaScript. However, if you're already fluent in Visual BASIC or Tcl/Tk, you'll be more productive using those scripting languages rather than learning a new one. (You'll have your hands full dealing with the Web issues already.)
I-L-2-c. Java▲
If a scripting language can solve 80 percent of the client-side programming problems, what about the other 20 percent-the « really hard stuff? » Java is a popular solution for this. Not only is it a powerful programming language built to be secure, cross-platform, and international, but Java is being continually extended to provide language features and libraries that elegantly handle problems that are difficult in traditional programming languages, such as multithreading, database access, network programming, and distributed computing. Java allows client-side programming via the applet and with Java Web Start.
An applet is a miniprogram that will run only under a Web browser. The applet is downloaded automatically as part of a Web page (just as, for example, a graphic is automatically downloaded). When the applet is activated, it executes a program. This is part of its beauty-it provides you with a way to automatically distribute the client software from the server at the time the user needs the client software, and no sooner. The user gets the latest version of the client software without fail and without difficult reinstallation. Because of the way Java is designed, the programmer needs to create only a single program, and that program automatically works with all computers that have browsers with built-in Java interpreters. (This safely includes the vast majority of machines.) Since Java is a full-fledged programming language, you can do as much work as possible on the client before and after making requests of the server. For example, you won't need to send a request form across the Internet to discover that you've gotten a date or some other parameter wrong, and your client computer can quickly do the work of plotting data instead of waiting for the server to make a plot and ship a graphic image back to you. Not only do you get the immediate win of speed and responsiveness, but the general network traffic and load on servers can be reduced, preventing the entire Internet from slowing down.
One advantage a Java applet has over a scripted program is that it's in compiled form, so the source code isn't available to the client. On the other hand, a Java applet can be decompiled without too much trouble, but hiding your code is often not an important issue. Two other factors can be important. As you will see later in this book, a compiled Java applet can require extra time to download, if it is large. A scripted program will just be integrated into the Web page as part of its text (and will generally be smaller and reduce server hits). This could be important to the responsiveness of your Web site. Another factor is the all-important learning curve. Regardless of what you've heard, Java is not a trivial language to learn. If you're a VISUAL BASIC programmer, moving to VBScript will be your fastest solution (assuming you can constrain your customers to Windows platforms), and since it will probably solve most typical client/server problems, you might be hard pressed to justify learning Java. If you're experienced with a scripting language you will certainly benefit from looking at JavaScript or VBScript before committing to Java, because they might fit your needs handily and you'll be more productive sooner.
I-L-2-d. .NET and C#▲
For awhile, the main competitor to Java applets was Microsoft's ActiveX, although it required that the client be running Windows. Since then, Microsoft has produced a full competitor to Java in the form of the .NET platform and the C# programming language. The .NET platform is roughly the same as the Java virtual machine and Java libraries, and C# bears unmistakable similarities to Java. This is certainly the best work that Microsoft has done in the arena of programming languages and programming environments. Of course, they had the considerable advantage of being able to see what worked well and what didn't work so well in Java, and build upon that, but build they have. This is the first time since its inception that Java has had any real competition, and if all goes well, the result will be that the Java designers at Sun will take a hard look at C# and why programmers might want to move to it, and will respond by making fundamental improvements to Java.
Currently, the main vulnerability and important question concerning .NET is whether Microsoft will allow it to be completely ported to other platforms. They claim there's no problem doing this, and the Mono project (www.go-mono.com) has a partial implementation of .NET working on Linux, but until the implementation is complete and Microsoft has not decided to squash any part of it, .NET as a cross-platform solution is still a risky bet.
To learn more about .NET and C#, see Thinking in C# by Larry O'Brien and Bruce Eckel, Prentice Hall 2003.
I-L-2-e. Security▲
Automatically downloading and running programs across the Internet can sound like a virus-builder's dream. If you click on a Web site, you might automatically download any number of things along with the HTML page: GIF files, script code, compiled Java code, and ActiveX components. Some of these are benign; GIF files can't do any harm, and scripting languages are generally limited in what they can do. Java was also designed to run its applets within a « sandbox » of safety, which prevents it from writing to disk or accessing memory outside the sandbox.
Microsoft's ActiveX is at the opposite end of the spectrum. Programming with ActiveX is like programming Windows-you can do anything you want. So if you click on a page that downloads an ActiveX component, that component might cause damage to the files on your disk. Of course, programs that you load onto your computer that are not restricted to running inside a Web browser can do the same thing. Viruses downloaded from Bulletin-Board Systems (BBSs) have long been a problem, but the speed of the Internet amplifies the difficulty.
The solution seems to be « digital signatures, » whereby code is verified to show who the author is. This is based on the idea that a virus works because its creator can be anonymous, so if you remove the anonymity, individuals will be forced to be responsible for their actions. This seems like a good plan because it allows programs to be much more functional, and I suspect it will eliminate malicious mischief. If, however, a program has an unintentional destructive bug, it will still cause problems.
The Java approach is to prevent these problems from occurring, via the sandbox. The Java interpreter that lives on your local Web browser examines the applet for any untoward instructions as the applet is being loaded. In particular, the applet cannot write files to disk or erase files (one of the mainstays of viruses). Applets are generally considered to be safe, and since this is essential for reliable client/server systems, any bugs in the Java language that allow viruses are rapidly repaired. (It's worth noting that the browser software actually enforces these security restrictions, and some browsers allow you to select different security levels to provide varying degrees of access to your system.)
You might be skeptical of this rather draconian restriction against writing files to your local disk. For example, you may want to build a local database or save data for later use offline. The initial vision seemed to be that eventually everyone would get online to do anything important, but that was soon seen to be impractical (although low-cost « Internet appliances » might someday satisfy the needs of a significant segment of users). The solution is the « signed applet » that uses public-key encryption to verify that an applet does indeed come from where it claims it does. A signed applet can still trash your disk, but the theory is that since you can now hold the applet creators accountable, they won't do vicious things. Java provides a framework for digital signatures so that you will eventually be able to allow an applet to step outside the sandbox if necessary. Chapter 14 contains an example of how to sign an applet.
In addition, Java Web Start is a relatively new way to easily distribute standalone programs that don't need a web browser in which to run. This technology has the potential of solving many client side problems associated with running programs inside a browser. Web Start programs can either be signed, or they can ask the client for permission every time they are doing something potentially dangerous on the local system. Chapter 14 has a simple example and explanation of Java Web Start.
Digital signatures have missed an important issue, which is the speed that people move around on the Internet. If you download a buggy program and it does something untoward, how long will it be before you discover the damage? It could be days or even weeks. By then, how will you track down the program that's done it? And what good will it do you at that point?
I-L-2-f. Internet vs. intranet▲
The Web is the most general solution to the client/server problem, so it makes sense to use the same technology to solve a subset of the problem, in particular the classic client/server problem within a company. With traditional client/server approaches you have the problem of multiple types of client computers, as well as the difficulty of installing new client software, both of which are handily solved with Web browsers and client-side programming. When Web technology is used for an information network that is restricted to a particular company, it is referred to as an intranet. Intranets provide much greater security than the Internet, since you can physically control access to the servers within your company. In terms of training, it seems that once people understand the general concept of a browser it's much easier for them to deal with differences in the way pages and applets look, so the learning curve for new kinds of systems seems to be reduced.
The security problem brings us to one of the divisions that seems to be automatically forming in the world of client-side programming. If your program is running on the Internet, you don't know what platform it will be working under, and you want to be extra careful that you don't disseminate buggy code. You need something cross-platform and secure, like a scripting language or Java.
If you're running on an intranet, you might have a different set of constraints. It's not uncommon that your machines could all be Intel/Windows platforms. On an intranet, you're responsible for the quality of your own code and can repair bugs when they're discovered. In addition, you might already have a body of legacy code that you've been using in a more traditional client/server approach, whereby you must physically install client programs every time you do an upgrade. The time wasted in installing upgrades is the most compelling reason to move to browsers, because upgrades are invisible and automatic (Java Web Start is also a solution to this problem). If you are involved in such an intranet, the most sensible approach to take is the shortest path that allows you to use your existing code base, rather than trying to recode your programs in a new language.
When faced with this bewildering array of solutions to the client-side programming problem, the best plan of attack is a cost-benefit analysis. Consider the constraints of your problem and what would be the shortest path to your solution. Since client-side programming is still programming, it's always a good idea to take the fastest development approach for your particular situation. This is an aggressive stance to prepare for inevitable encounters with the problems of program development.
I-L-3. Programmation côté serveur▲
Toute cette discussion a passé sous silence la programmation côté serveur. Qu'arrive-t-il lorsque vous faites une requête vers un serveur ? La plupart du temps la requête est simplement « envoie-moi ce fichier ». Ensuite votre navigateur interprète de manière appropriée le fichier : comme une page HTML, une image, une applet Java, un programme script, etc. Une requête plus compliquée vers un serveur comprend généralement une transaction dans une base de données. Généralement les scénarios consistent en une requête complexe de recherche en base de données, que le serveur va ensuite formater sous forme d'une page HTML avant de vous la renvoyer (bien sûr, si le client est un peu plus évolué grâce à du Java ou un langage de script, les données brutes peuvent lui être renvoyées, dans ce cas c'est le client qui effectue le formatage, cela sera plus rapide et allégera la charge du serveur). Ou alors vous pourriez vouloir enregistrer votre nom dans une base de données lorsque par exemple vous rejoignez un groupe ou passez une commande, ce qui implique de modifier cette base. Ces requêtes doivent être traitées par du code s'exécutant sur le serveur, c'est ce qu'on appelle la programmation côté serveur. Traditionnellement, la programmation serveur est effectuée en utilisant Perl, Python, C++, ou d'autres langages, pour créer des scripts CGI, mais des systèmes plus sophistiqués sont apparus. Ces systèmes incluent les serveurs web basés sur Java qui permettent toute la programmation côté serveur en Java via ce que l'on appelle des servlets. Les servlets et leurs descendants, les JSP, sont les deux raisons principales qui poussent les entreprises qui développent un site Web à se tourner vers Java, en particulier parce qu'ils éliminent les problèmes liés aux différences de capacité des navigateurs (ces sujets sont traités dans Thinking in Enterprise Java).
I-L-4. Applications▲
Une grande partie du brouhaha autour de Java se référait aux applets. En réalité, Java est un langage de programmation généraliste qui peut résoudre le même genre de problèmes que vous pouvez résoudre avec un autre langage - du moins en théorie. Et comme précisé précédemment, il pourrait y avoir des moyens plus efficaces de résoudre la plupart des problèmes client/serveur. Quand vous vous aventurez en dehors du domaine des applets (et des restrictions liées, telles que l'écriture sur disque) vous entrez dans le monde des applications à usage universel, fonctionnant de manière autonome, sans navigateur Web, juste comme tout autre programme ordinaire . Ici, la force de Java est non seulement dans sa portabilité, mais également la manière de programmer. Car, vous le verrez dans tout ce livre, Java a beaucoup de fonctionnalités qui permettent de créer des programmes robustes en un temps plus court qu'avec des langages de programmation précédents.
Faites attention, car cela a du bon et du mauvais. Vous payez ces améliorations par une vitesse d'exécution plus lente (bien qu'il y ait un travail significatif et régulier dans ce domaine, comme les prétendues améliorations d'exécution de « hotspot » des versions récentes de Java). Comme n'importe quel langage, Java a des limitations internes qui pourraient le rendre inadéquat pour résoudre certains types de problèmes de programmation. Cependant Java est un langage évoluant rapidement et à chaque nouvelle version, il devient de plus en plus attrayant pour résoudre des ensembles plus larges de problèmes.
I-M. Les raisons du succès de Java▲
La raison pour laquelle Java est si populaire est que son objectif est de résoudre beaucoup de problèmes auxquels les programmeurs font face aujourd'hui. Un but essentiel de Java est d'améliorer la productivité. Des gains de productivité peuvent être obtenus de différentes manières, mais le langage a été conçu pour être une réelle amélioration par rapport à ses prédécesseurs, et pour apporter une aide significative aux programmeurs.
I-M-1. Les systèmes sont plus faciles à décrire et comprendre▲
Les classes conçues pour résoudre le problème sont plus faciles à décrire. Cela signifie que lorsque vous concevez le code, vous décrivez la solution avec les termes et concepts du problème considéré (« Mets le fichier à la poubelle ») plutôt qu'en termes machine, qui correspondent à l'espace solution (« Positionne le bit à 1 ce qui veut dire que le relai va se fermer »). Vous traitez alors avec des concepts de plus haut niveau et vous bénéficiez d'une capacité d'expression beaucoup plus importante avec une ligne de code.
L'autre aspect bénéfique de cette facilité d'expression se retrouve dans la maintenance, qui représente (s'il faut en croire les rapports) une grosse part du coût dans le cycle de vie d'un programme. Si un programme est plus facile à comprendre, il est alors forcément plus facile à maintenir. Cela peut aussi réduire le coût de la création et du maintien de la documentation.
I-M-2. Puissance maximale grâce aux bibliothèques▲
La façon la plus rapide de créer un programme est d'utiliser du code déjà écrit : une bibliothèque. Un des buts fondamentaux de Java est de faciliter l'emploi des bibliothèques. Ce but est atteint en convertissant ces bibliothèques en nouveaux types de données (classes), et utiliser une bibliothèque revient à ajouter de nouveaux types au langage. Comme le compilateur Java s'occupe de l'interfaçage avec la bibliothèque - garantissant une initialisation et un nettoyage propres, et s'assurant que les fonctions sont appelées correctement - on peut se concentrer sur ce qu'on attend de la bibliothèque, et non sur les moyens de le faire.
I-M-3. Traitement des erreurs▲
L'une des difficultés du C est la gestion des erreurs, problème connu et largement ignoré - le croisement de doigts est souvent impliqué. Si on construit un programme gros et complexe, il n'y a rien de pire que de trouver une erreur enfouie quelque part sans qu'on sache d'où elle vienne. Le traitement des exceptions de Java est une façon de garantir qu'une erreur a été remarquée, et que quelque chose est mis en œuvre pour la traiter.
I-M-4. La programmation à grande échelle▲
De nombreux langages de programmation classiques possèdent des limites intrinsèques à la taille et à la complexité des programmes. BASIC par exemple convient très bien pour mettre en place rapidement des solutions pour certains types de problèmes, mais dès que la longueur du programme dépasse quelques pages, ou qu'il s'aventure hors des problématiques classiques de ce langage, on a subitement l'impression de nager dans un liquide sans cesse plus visqueux. Il n'y a pas de moyen sûr pour savoir si on est trahi par son langage de programmation, et même s'il y en existait, vous l'auriez ignoré. On ne dit jamais : « Mon programme en BASIC est devenu trop gros, je vais devoir le réécrire en C ». A la place, on tente d'y plaquer encore quelques lignes supplémentaires pour fournir cette nouvelle fonctionnalité. C'est ainsi que viennent les coûts supplémentaires.
Java est conçu pour faciliter la programmation à grande échelle, c'est-à-dire supprimer la frontière de complexité croissante qui existe entre un petit programme et un gros. On n'a certainement pas besoin de la POO pour écrire un programme du style « Hello World », mais les fonctionnalités seront présentes quand on en aura besoin. Le compilateur est aussi agressif dans les petits que dans les gros programmes pour ce qui est de dénicher les erreurs susceptibles de générer des bogues.
I-N. Java vs. C++ ?▲
Java ressemble beaucoup au C++, aussi, naturellement, il semblerait que C++ sera remplacé par Java. Mais je commence à remettre en question cette logique. Tout d'abord, C++ a encore des fonctionnalités que Java n'a pas, et bien qu'il y ait eu beaucoup de promesses au sujet de Java qui deviendrait un jour aussi rapide ou même plus que le C++, nous avons vu des améliorations régulières, mais aucune percée spectaculaire. En outre, il semble qu'il y ait un intérêt continu pour le C++, aussi je ne pense pas que ce langage ne disparaisse de si tôt. Les langages semblent traîner.
Je commence à penser que la force de Java repose dans un domaine légèrement différent de celui du C++, qui est un langage qui n'essaie pas de rentrer dans un moule. Certainement, il a été adapté dans un nombre de directions pour résoudre des problèmes particuliers. Certains outils C++ combinent des bibliothèques, des modèles de composants et des outils de génération de code pour résoudre le problème du développement d'applications graphiques (pour Windows de Microsoft). Mais qu'utilisent la vaste majorité de développeurs Windows ? Visual Basic de Microsoft (VB). Ceci en dépit du fait que VB produit le type de code qui devient ingérable quand le programme fait seulement quelques pages de long (et la syntaxe qui peut être franchement mystifiante). Aussi réussi et populaire que soit VB, ce n'est pas un très bon exemple de conception de langage. Il serait agréable d'avoir la simplicité et la puissance de VB sans le code ingérable qui en résulte. Et c'est là où je pense que Java brillera : le « prochain VB (9) ». Vous pouvez ou non frissonner en entendant cela, mais pensez-y : tant de choses en Java sont prévues afin de faciliter pour le programmeur la résolution de problèmes de niveau applicatif comme le réseau et les interfaces utilisateur hétérogènes, mais il a une conception de langage qui permet la création de morceaux de code très larges et flexibles. Ajoutez à cela le fait que les vérifications de type et la gestion des erreurs en Java sont une grande amélioration par rapport à la plupart des langages et vous avez les ingrédients d'un saut significatif dans la productivité de programmation.
Si vous développez tout votre code principalement à partir de zéro, alors la simplicité de Java par rapport au C++ réduira significativement votre durée de développement -L'évidence anecdotique (les histoires des équipes C++ à qui j'ai parlé qui ont basculé à Java) suggère un doublement de la vitesse de développement par rapport à C++. Si la performance de Java n'importe pas ou si vous pouvez d'une façon ou d'une autre la compenser, les purs problèmes de délai de réalisation rendent difficile de choisir C++ plutôt que Java.
La plus grande question est la performance. Java interprété a été lent, même 20 à 50 fois plus lent que le C pour les interpréteurs Java d'origine. Ceci a été grandement amélioré avec le temps (particulièrement avec les versions les plus récentes de Java, mais cela reste toujours une quantité importante. L'essentiel pour les ordinateurs c'est la vitesse ; si ce n'était pas significativement plus rapide de faire quelque chose sur un ordinateur, vous le feriez à la main (j'ai même entendu suggérer que vous débutiez avec Java, pour gagner le court temps de développement, ensuite utiliser un outil et des bibliothèques de support pour traduire votre code en C++, si vous avez besoin d'une vitesse d'exécution plus grande).
La clé pour rendre Java faisable pour de nombreux projets de développement est l'apparition d'améliorations de la vitesse telles que compilateurs nommés « Just-in-time » (JIT), la technologie « hotspot » de Sun, et même les compilateurs de code natif. Bien sûr, les compilateurs de code natif élimineront l'exécution multiplateforme si appréciée pour les programmes compilés, mais ils apporteront également la vitesse de l'exécutable proche de celle du C et du C++. Et compiler, pour plusieurs plateformes, un programme en Java devrait être beaucoup plus facile que de le faire en C ou en C++ (en théorie, vous avez juste à recompiler, mais cette promesse a déjà été faite pour d'autres langages).
I-O. Résumé▲
Ce chapitre tente de vous donner un aperçu des sujets couverts par la programmation orientée objet et Java, y compris pourquoi la POO est différente, et particulièrement pourquoi Java est différent.
La POO et Java ne sont pas forcément destinés à tout le monde. Il est important d'évaluer vos propres besoins et décider si Java satisfera au mieux ces besoins, ou si un autre système de programmation ne vous conviendrait pas mieux (y compris celui que vous utilisez actuellement). Si vous savez que vos besoins seront très spécialisés pour le futur et si vous avez des contraintes spécifiques qui ne peuvent pas être satisfaites par Java, alors vous vous devez d'étudier les alternatives (en particulier, je recommande de regarder dans la direction de Python ; voir www.Python.org). Même si vous choisissez finalement Java comme langage, vous comprendrez au moins quelles étaient les options et vous aurez une vision claire de pourquoi vous avez pris cette direction.
Vous savez à quoi ressemble un programme procédural : des définitions de données et des appels de fonction. Pour trouver le sens d'un tel programme, vous devez travailler un peu, cherchant à travers les appels de fonction et des concepts de bas niveau pour créer un modèle dans votre esprit. C'est la raison pour laquelle nous avons besoin de représentations intermédiaires quand on conçoit des programmes procéduraux - par eux-mêmes, ces programmes tendent à être confus parce que les termes de l'expression sont plus orientés vers la machine que vers le problème que vous résolvez.
Parce que Java introduit de nombreux nouveaux concepts au-dessus de ceux que vous trouvez dans un langage procédural, votre supposition naturelle pourrait être que la fonction main( ) dans un programme Java sera bien plus compliquée que pour le programme C équivalent. Ici, vous serez agréablement surpris : un programme Java bien écrit est généralement beaucoup plus simple et plus facile à comprendre le programme C équivalent. Ce que vous verrez est les définitions des objets qui représentent des concepts de l'espace de votre problème (plutôt que des préoccupations de la représentation informatique) et des messages envoyés à ces objets pour représenter les activités dans cet espace. L'un des plaisirs de la POO est qu'avec un programme bien conçu, il est facile de comprendre le code en le lisant. De plus, il y a généralement beaucoup moins de code, car beaucoup de vos problèmes seront résolus en réutilisant du code de bibliothèque existant.