


XVII. Introduction aux Templates▲
La composition et l'héritage fournissent un moyen de réutiliser le code objet. La fonctionnalité template fournit, en C++, un moyen de réutiliser du code source.
Bien que les templates du C++ soient un outil de programmation à but générique, quand ils furent introduits dans le langage, ils semblaient décourager l'utilisation de hiérarchies de conteneurs de classes basées sur les objets (démontré à la fin du chapitre 15). Par exemple, les conteneurs et algorithmes du C++ standard (expliqués dans deux chapitres dans le Volume 2 de ce livre, téléchargeable sur www.BruceEckel.com) sont bâtis exclusivement avec des templates et sont relativement faciles à utiliser pour le programmeur.
Ce chapitre montre non seulement les bases des templates, mais c'est également une introduction aux conteneurs, qui sont des composants fondamentaux de la programmation orientée objet et presque complètement réalisés par les conteneurs de la librairie standard du C++. Vous verrez que tout au long de ce livre on a utilisé des exemples de conteneurs – Stash et Stack–, précisément afin de vous rendre à l'aise avec les conteneurs ; dans ce chapitre le concept d' itérateur sera également introduit. Bien que les conteneurs soient des exemples idéaux pour l'utilisation des templates, dans le Volume 2 (qui a un chapitre avancé sur les templates) vous apprendrez qu'il y a également beaucoup d'autres manières d'utiliser les templates.
XVII-A. Les conteneurs▲
Imaginez que vous vouliez créer une pile (stack, ndt), comme nous l'avons tout au long du livre. Cette classe stack contiendra des int, pour faire simple :
//: C16:IntStack.cpp
// Pile d'entiers simple
//{L} fibonacci
#include "fibonacci.h"
#include "../require.h"
#include <iostream>
using namespace std;
class IntStack {
enum { ssize = 100 };
int stack[ssize];
int top;
public:
IntStack() : top(0) {}
void push(int i) {
require(top < ssize, "Too many push()es");
stack[top++] = i;
}
int pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
};
int main() {
IntStack is;
// Ajoute des nombres des Fibonacci, par curiosité :
for(int i = 0; i < 20; i++)
is.push(fibonacci(i));
// Les dépile & les affiche :
for(int k = 0; k < 20; k++)
cout << is.pop() << endl;
} ///:~La classs IntStack est un exemple trivial d'une pile refoulée. Par souci de simplicité, elle a été créée ici avec une taille constante, mais vous pouvez aussi la modifier pour s'accroître automatiquement en allouant de la mémoire sur le tas, comme dans la classe Stack que l'on a examinée tout au long de ce livre.
main( ) ajoute des entiers à la pile, puis les dépile. Pour rendre l'exemple plus intéressant, les entiers sont créés à l'aide de la fonction fibonacci( ), qui génère les traditionnels nombres de la reproduction des lapins (ndt : la suite de Fibonacci trouve son origine dans l'étude de la vitesse de reproduction des lapins dans un milieu idéal par Fibonacci (XIIIe siècle)). Voici le fichier d'en-tête qui déclare la fonction :
//: C16:fibonacci.h
// Générateur de nombres de Fibonacci
int fibonacci(int n); ///:~Voici l'implémentation :
//: C16:fibonacci.cpp {O}
#include "../require.h"
int fibonacci(int n) {
const int sz = 100;
require(n < sz);
static int f[sz]; // Initialisé à zéro
f[0] = f[1] = 1;
// recherche d'éléments non remplis du tableau :
int i;
for(i = 0; i < sz; i++)
if(f[i] == 0) break;
while(i <= n) {
f[i] = f[i-1] + f[i-2];
i++;
}
return f[n];
} ///:~C'est une implémentation relativement efficace, parce qu'elle ne génère jamais les nombres plus d'une fois. Elle utilise un tableau static de int, et repose sur le fait que le compilateur initialisera un tableau de static à zéro. La première boucle for déplace l'index i au niveau du premier élément à zéro du tableau, puis une boucle while ajoute des nombres de Fibonacci au tableau jusqu'à ce que l'élément voulu soit atteint. Mais remarquez que si les nombres de Fibonacci jusqu'à l'élément n sont déjà initialisés, la boucle while est entièrement évitée.
XVII-A-1. Le besoin de conteneurs▲
De toute évidence, une pile d'entiers n'est pas un outil de première importance. Le vrai besoin de conteneurs se fait sentir quand vous commencez à créer des objets sur le tas en utilisant new et que vous les détruisez avec delete. Dans le cas général de programmation, vous ne savez pas de combien d'objets vous allez avoir besoin lorsque vous écrivez le programme. Par exemple, dans un système de contrôle du trafic aérien vous ne voulez pas limiter le nombre d'avions que votre système peut gérer. Vous ne voulez pas que le programme plante juste parce que vous avez dépassé un certain nombre. Dans un système de conception assisté par ordinateur, vous traitez beaucoup de formes, mais seul l'utilisateur détermine (à l'exécution) de combien de formes exactement vous allez avoir besoin. Une fois que vous avez remarqué cette tendance, vous découvrirez beaucoup d'exemples de ce type dans vos propres cas de programmation.
Les programmeurs C qui s'appuient sur la mémoire virtuelle pour traiter leur “gestion mémoire” trouvent souvent perturbante l'idée de new, delete et des classes de conteneurs. Apparemment, une pratique en C est de créer un énorme tableau global, plus grand que tout ce dont pourrait avoir besoin le programme. Ceci ne nécessite peut-être pas beaucoup de réflexion (ou de connaissance de malloc( ) et free( )), mais cela produit des programmes qui ne sont pas très portables et qui cachent des bugs subtils.
En outre, si vous créez un énorme tableau global d'objets en C++, le surcout de temps d'appel du constructeur et du destructeur peut ralentir les choses significativement. L'approche C++ marche beaucoup mieux : quand vous avez besoin d'un objet, créez-le avec new, et placez son pointeur dans un conteneur. Plus tard, repêchez-le et faites quelque chose avec. Ainsi, vous ne créez que les objets dont vous avez absolument besoin. Et vous ne disposez habituellement pas de toutes les conditions d'initialisation au démarrage du programme. new vous permet d'attendre jusqu'à ce que quelque chose se produise dans l'environnement qui vous donne les moyens de vraiment créer l'objet.
Ainsi dans la situation la plus courante, vous créerez un conteneur qui contient des pointeurs vers les objets d'intérêt. Vous créerez ces objets en utilisant new et placerez le pointeur résultant dans le conteneur (potentiellement en upcastant au cours de ce processus), le retirant plus tard, quand vous voudrez faire quelque chose avec l'objet. Cette technique produit les programmes les plus flexibles et les plus généraux.
XVII-B. Survol des templates▲
Un problème apparaît, à présent. Vous disposez d'un IntStack, qui contient des entiers. Mais vous voulez une pile qui contient des formes ou des avions ou des plantes ou autres choses. Réinventer votre code source à chaque fois ne semble pas être une approche très intelligente avec un langage qui promeut la réutilisabilité. Il doit exister une meilleure technique.
Il y a trois techniques pour la réutilisation du code source dans cette situation : la manière du C, présentée ici pour comparer ; l'approche de Smalltalk, qui a significativement influencé le C++ ; et l'approche du C++ : les templates.
La solution du C. Bien sûr, vous essayez de vous affranchir de l'approche du C parce qu'elle est sale, source d'erreurs et complètement inélégante. Dans cette approche, vous copiez le code source pour un Stack et faites les modifications à la main, introduisant de cette façon de nouvelles erreurs. Ce n'est certainement pas une technique très productive.
La solution Smalltalk. Le Smalltalk (et Java, qui suit son exemple) a adopté une approche simple et directe : vous voulez réutiliser le code, utilisez donc l'héritage. Pour implémenter cela, chaque classe de conteneur contient des items de la classe de base générique Object(similaire à l'exemple de la fin du Chapite 15). Mais puisque la bibliothèque en Smalltalk est d'une importance si fondamentale, vous ne créez jamais une classe à partir de rien. Au lieu de cela, vous devez toujours la faire hériter d'une classe existante. Vous trouvez une classe aussi proche que possible de celle que vous voulez, vous en dérivez, et faites quelques changements. De toute évidence, c'est un progrès parce que cela minimise vos efforts (et explique pourquoi vous devez passer beaucoup de temps à apprendre la bibliothèque de classes avant de devenir un programmeur efficace en Smalltalk).
Mais cela signifie également que toutes les classes en Smalltalk finissent par appartenir à un arbre d'héritage unique. Vous devez hériter d'une branche de cet arbre quand vous créez une classe. L'essentiel de l'arbre est déjà là (c'est la bibliothèque de classes de Smalltalk), et à la racine de l'arbre se trouve une classe appelée Object–la même classe que contient chaque conteneur de Smalltalk.
C'est une belle astuce parce que cela signifie que toute classe dans la hiérarchie de classe de Smalltalk (et de Java (59)) est dérivée d' Object, si bien que toute classe peut être contenue dans chaque conteneur (y compris le conteneur lui-même). Ce type de hiérarchie à arbre unique basée sur un type générique fondamental (souvent appelé Object, ce qui est aussi le cas en Java) est dénommée “hiérarchie basée sur une classe object”. Vous avez peut-être entendu ce terme et imaginé que c'était un nouveau concept fondamental en POO, comme le polymorphisme. Cela fait simplement référence à une hiérarchie de classe avec Object(ou un nom similaire) à sa racine et des classes conteneurs qui contiennent Object.
Comme il y a beaucoup plus d'histoire et d'expérience derrière la bibliothèque de classes de Smalltalk que celle du C++, et puisque les compilateurs originaux du C++ n'avaient aucune bibliothèque de classes de conteneurs, cela semblait une bonne idée de dupliquer la bibliothèque de Smalltalk en C++. Ceci a été fait à titre expérimental avec une ancienne implémentation du C++ (60), et comme cela représentait une quantité de code importante, beaucoup de gens ont commencé à l'utiliser. En essayant d'utiliser les classes de conteneurs, ils ont découvert un problème.
Le problème était qu'en Smalltalk (et dans la plupart des autres langages orientés objet que je connais), toutes les classes sont automatiquement dérivées d'une hiérarchie unique, mais ce n'est pas vrai en C++. Vous pourriez avoir votre sympathique hiérarchie basée sur une classe object, avec ses classes de conteneurs, mais vous pouvez alors acheter un ensemble de classes de formes ou d'avions d'un autre vendeur qui n'utilise pas cette hiérarchie. (Pour une raison, utiliser cette hiérarchie coûte du temps système, ce que les programmeurs C évitent). Comment insérez-vous un arbre de classe différent dans la classe de conteneurs de votre hiérarchie basée sur une classe object ? Voici à quoi ressemble le problème :
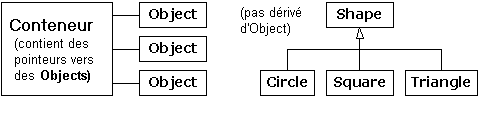
Parce que le C++ supporte plusieurs hiérarchies indépendantes, la hiérarchie basée sur une classe object de Smalltalk ne fonctionne pas si bien.
La solution parut évidente. Si vous pouvez avoir beaucoup de hiérarchies d'héritage, vous devriez alors pouvoir hériter de plus d'une classe : l'héritage multiple résoudra le problème. Vous procédez alors comme suit (un exemple similaire a été donné à la fin du Chapitre 15) :
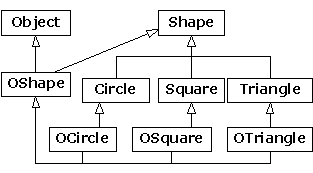
À présent OShape a les caractéristiques et le comportement de Shape, mais comme il dérive aussi de Object il peut être placé dans un Container. L'héritage supplémentaire dans OCircle, OSquare, etc. est nécessaire afin que ces classes puissent être transtypées en OShape et conserver ainsi le comportement correct. Vous vous rendez compte que les choses deviennent rapidement embrouillées.
Les vendeurs de compilateurs ont inventé et inclus leurs propres hiérarchies de classes de conteneurs basées sur une classe object, la plupart desquelles ont depuis été remplacées par des versions templates. Vous pouvez souligner que l'héritage multiple est nécessaire pour résoudre des problèmes de programmation générale, mais vous verrez dans le volume 2 de ce livre qu'il vaut mieux éviter sa complexité sauf dans certains cas particuliers.
XVII-B-1. La solution template▲
Bien qu'une hiérarchie basée sur une classe object avec héritage multiple soit conceptuellement claire, son utilisation s'avère douloureuse. Dans son livre original (61)Stroustrup a démontré ce qu'il considérait comme une alternative préférable à la hiérarchie basée sur une classe object. Les classes de conteneurs étaient créées sous forme de grandes macros du préprocesseur avec des arguments qui pouvaient être substitués par le type que vous désirez. Quand vous vouliez créer un conteneur pour stocker un type particulier, vous faisiez une paire d'appels de macros.
Malheureusement, cette approche a été embrouillée par toute la littérature et l'expérience de programmation existantes en Smalltalk, et elle était un peu difficile à manier. En gros, personne ne la comprenait.
Entre temps, Stroustrup et l'équipe C++ des Bell Labs avaient modifié leur approche macro originale, en la simplifiant et en la déplaçant du domaine du préprocesseur vers celui du compilateur. Ce nouvel outil de substitution de code est appelé un template(62), et cela représente une façon complètement différente de réutiliser le code. Au lieu de réutiliser le code objet, comme avec l'héritage et la composition, un template réutilise le code source. Le conteneur ne stocke plus une classe générique de base appelée Object, mais stocke à la place un paramètre non spécifié. Quand vous utilisez un template, le paramètre est substitué par le compilateur, de manière très semblable à l'ancienne approche par les macros, mais de façon plus propre et plus facile à utiliser.
Maintenant, au lieu de devoir s'inquiéter d'héritage ou de composition quand vous voulez utiliser une classe de conteneur, vous prenez la version template du conteneur et fabriquez une version spécifique pour votre problème particulier, comme ceci :
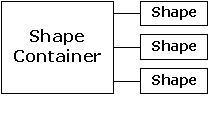
Le compilateur fait le travail pour vous, et vous vous retrouvez avec exactement le conteneur dont vous avez besoin pour faire le travail, plutôt qu'une hiérarchie d'héritage indémêlable. En C++, le template implémente le concept de type paramétré. Un autre bénéfice de l'approche template est que le programmeur novice qui n'est pas nécessairement familier ou à l'aise avec l'héritage peut tout de même utiliser les classes de conteneurs immédiatement (comme nous l'avons fait avec vector tout au long du livre).
XVII-C. Syntaxe des templates▲
Le mot-clé template dit au compilateur que la définition de classe qui suit manipulera un ou plusieurs types non spécifiés. Au moment où le code réel de la classe est généré à partir du template, ces types doivent être spécifiés afin que le compilateur puisse les substituer.
Pour démontrer la syntaxe, voici un petit exemple qui produit un tableau dont les bornes sont vérifiées :
//: C16:Array.cpp
#include "../require.h"
#include <iostream>
using namespace std;
template<class T>
class Array {
enum { size = 100 };
T A[size];
public:
T& operator[](int index) {
require(index >= 0 && index < size,
"Index out of range");
return A[index];
}
};
int main() {
Array<int> ia;
Array<float> fa;
for(int i = 0; i < 20; i++) {
ia[i] = i * i;
fa[i] = float(i) * 1.414;
}
for(int j = 0; j < 20; j++)
cout << j << ": " << ia[j]
<< ", " << fa[j] << endl;
} ///:~Vous pouvez voir que cela ressemble à une classe normale, sauf en ce qui concerne la ligne
template<class T>qui dit que T est le paramètre de substitution, et qu'il représente un nom de type. Vous voyez également que T est utilisé dans la classe partout où vous verriez normalement le type spécifique stocké par le conteneur.
Dans Array, les éléments sont insérés et extraits avec la même fonction : l'opérateur surchargé operator [ ]. Il renvoie une référence, afin qu'il puisse être utilisé des deux côtés d'un signe égal (c'est-à-dire à la fois comme lvalue et comme rvalue). Notez que si l'index est hors limite, la fonction require( ) est utilisée pour afficher un message. Comme operator[] est inline, vous pourriez utiliser cette approche pour garantir qu'aucune violation des limites du tableau ne se produit, puis retirer require( ) pour le code livré.
Dans main( ), vous pouvez voir comme il est facile de créer des Array qui contiennent différents types. Quand vous dites
Array<int> ia;
Array<float> fa;le compilateur développe le template Array(c'est appelé instanciation) deux fois, pour créer deux nouvelles classes générées, que vous pouvez considérer comme Array_int et Array_float. (Différents compilateurs peuvent décorer les noms de façons différentes.) Ce sont des classes exactement comme celles que vous auriez produites si vous aviez réalisé la substitution à la main, sauf que le compilateur les crée pour vous quand vous définissez les objets ia et fa. Notez également les définitions de classes dupliquées sont soit évitées par le compilateur, soit fusionnées par l'éditeur de liens.
XVII-C-1. Définitions de fonctions non inline▲
Bien sûr, vous voudrez parfois définir des fonctions non inline. Dans ce cas, le compilateur a besoin de voir la déclaration template avant la définition de la fonction membre. Voici l'exempleci-dessus, modifié pour montrer la définition de fonctions non inline :
//: C16:Array2.cpp
// Définition de template non-inline
#include "../require.h"
template<class T>
class Array {
enum { size = 100 };
T A[size];
public:
T& operator[](int index);
};
template<class T>
T& Array<T>::operator[](int index) {
require(index >= 0 && index < size,
"Index out of range");
return A[index];
}
int main() {
Array<float> fa;
fa[0] = 1.414;
} ///:~Toute référence au nom de la classe d'un template doit être accompagnée par sa liste d'arguments de template, comme dans Array<T>::operator[]. Vous pouvez imaginer qu'au niveau interne, le nom de classe est décoré avec les arguments de la liste des arguments du template pour produire un unique identifiant de nom de classe pour chaque instanciation du template.
Fichiers d'en-tête
Même si vous créez des définitions de fonctions non inline, vous voudrez généralement mettre toutes les déclarations et les définitions d'un template dans un fichier d'en-tête. Ceci paraît violer la règle normale des fichiers d'en-tête qui est “Ne mettez dedans rien qui alloue de l'espace de stockage”, (ce qui évite les erreurs de définitions multiples à l'édition de liens), mais les définitions de template sont spéciales. Tout ce qui est précédé par template<…> signifie que le compilateur n'allouera pas d'espace de stockage pour cela à ce moment, mais, à la place, attendra qu'il lui soit dit de le faire (par l'instanciation du template). En outre, quelque part dans le compilateur ou le linker il y a un mécanisme pour supprimer les définitions multiples d'un template identique. Donc vous placerez presque toujours la déclaration et la définition complètes dans le fichier d'en-tête, par commodité.
Vous pourrez avoir parfois besoin de placer la définition du template dans un fichier cpp séparé pour satisfaire à des besoins spéciaux (par exemple, forcer les instanciations de templates à n'exister que dans un seul fichier dll de Windows). La plupart des compilateurs ont des mécanismes pour permettre cela ; vous aurez besoin de chercher dans la notice propre à votre compilateur pour ce faire.
Certaines personnes pensent que placer tout le code source de votre implémentation dans un fichier d'en-tête permet à des gens de voler et modifier votre code s’ils vous achètent une bibliothèque. Cela peut être un problème, mais cela dépend probablement de la façon dont vous regardez la question : achètent-ils un produit ou un service ? Si c'est un produit, alors vous devez faire tout ce que vous pouvez pour le protéger, et vous ne voulez probablement pas donner votre code source, mais seulement du code compilé. Mais beaucoup de gens considèrent les logiciels comme des services, et même plus que cela, un abonnement à un service. Le client veut votre expertise, il veut que vous continuiez à maintenir cet élément de code réutilisable afin qu'ils n'aient pas à le faire et qu'ils puissent se concentrer sur le travail qu' ils ont à faire. Je pense personnellement que la plupart des clients vous traiteront comme une ressource de valeur et ne voudront pas mettre leurs relations avec vous en péril. Pour le peu de personnes qui veulent voler plutôt qu'acheter ou produire un travail original, ils ne peuvent probablement pas continuer avec vous de toute façon.
XVII-C-2. IntStack comme template▲
Voici le conteneur et l'itérateur de IntStack.cpp, implémentés comme une classe de conteneur générique en utilisant les templates :
//: C16:StackTemplate.h
// Template stack simple
#ifndef STACKTEMPLATE_H
#define STACKTEMPLATE_H
#include "../require.h"
template<class T>
class StackTemplate {
enum { ssize = 100 };
T stack[ssize];
int top;
public:
StackTemplate() : top(0) {}
void push(const T& i) {
require(top < ssize, "Too many push()es");
stack[top++] = i;
}
T pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
int size() { return top; }
};
#endif // STACKTEMPLATE_H ///:~Remarquez qu'un template fait quelques suppositions sur les objets qu'il contient. Par exemple, StackTemplate suppose qu'il existe une sorte d'opération d'assignation pour T dans la fonction push( ). Vous pourriez dire qu'un template “implique une interface” pour les types qu'il est capable de contenir.
Une autre façon de le dire est que les templates fournissent une sorte de mécanisme de typage faible en C++, qui est ordinairement un langage fortement typé. Au lieu d'insister sur le fait qu'un objet soit d'un certain type pour être acceptable, le typage faible requiert seulement que les fonctions membres qu'il veut appeler soient disponibles pour un objet particulier. Ainsi, le code faiblement typé peut être appliqué à n'importe quel objet qui peut accepter ces appels de fonctions membres, et est ainsi beaucoup plus flexible (63).
Voici l'exemple révisé pour tester le template :
//: C16:StackTemplateTest.cpp
// Teste le template stack simple
//{L} fibonacci
#include "fibonacci.h"
#include "StackTemplate.h"
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main() {
StackTemplate<int> is;
for(int i = 0; i < 20; i++)
is.push(fibonacci(i));
for(int k = 0; k < 20; k++)
cout << is.pop() << endl;
ifstream in("StackTemplateTest.cpp");
assure(in, "StackTemplateTest.cpp");
string line;
StackTemplate<string> strings;
while(getline(in, line))
strings.push(line);
while(strings.size() > 0)
cout << strings.pop() << endl;
} ///:~La seule différence se trouve dans la création de is. Dans la liste d'arguments du template vous spécifiez le type d'objet que la pile et l'itérateur devraient contenir. Pour démontrer la généricité du template, un StackTemplate est également créé pour contenir des string. On le teste en lisant des lignes depuis le fichier du code source.
XVII-C-3. Constantes dans les templates▲
Les arguments des templates ne sont pas restreints à des types classes ; vous pouvez également utiliser des types prédéfinis. La valeur de ces arguments devient alors des constantes à la compilation pour cette instanciation particulière du template. Vous pouvez même utiliser des valeurs par défaut pour ces arguments. L'exemple suivant vous permet de fixer la taille de la classe Array pendant l'instanciation, mais fournit également une valeur par défaut :
//: C16:Array3.cpp
// Types prédéfinis comme arguments de template
#include "../require.h"
#include <iostream>
using namespace std;
template<class T, int size = 100>
class Array {
T array[size];
public:
T& operator[](int index) {
require(index >= 0 && index < size,
"Index out of range");
return array[index];
}
int length() const { return size; }
};
class Number {
float f;
public:
Number(float ff = 0.0f) : f(ff) {}
Number& operator=(const Number& n) {
f = n.f;
return *this;
}
operator float() const { return f; }
friend ostream&
operator<<(ostream& os, const Number& x) {
return os << x.f;
}
};
template<class T, int size = 20>
class Holder {
Array<T, size>* np;
public:
Holder() : np(0) {}
T& operator[](int i) {
require(0 <= i && i < size);
if(!np) np = new Array<T, size>;
return np->operator[](i);
}
int length() const { return size; }
~Holder() { delete np; }
};
int main() {
Holder<Number> h;
for(int i = 0; i < 20; i++)
h[i] = i;
for(int j = 0; j < 20; j++)
cout << h[j] << endl;
} ///:~Comme précédemment, Array est un tableau vérifié d'objets et vous empêche d'indexer en dehors des limites. La classe Holder ressemble beaucoup à Array sauf qu'elle contient un pointeur vers un Array au lieu d'inclure objet de type Array. Ce pointeur n'est pas initialisé dans le constructeur ; l'initialisation est repoussée jusqu'au premier accès. On appelle cela l' initialisation paresseuse; vous pourriez utiliser une technique comme celle-ci si vous créez beaucoup d'objets, mais n'accédez pas à tous, et que vous voulez économiser de l'espace de stockage.
Vous remarquerez que la valeur size dans les deux templates n'est jamais stockée au sein de la classe, mais est utilisée comme si elle était une donnée membre dans les fonctions membres.
XVII-D. Stack et Stash comme templates▲
Les problèmes récurrents de “propriété” avec les classes de conteneurs Stash et Stack qui ont été revisitées tout au long de ce livre viennent du fait que ces conteneurs n'ont pas été capables de savoir exactement quels types ils contiennent. Le plus proche qu'ils ont trouvé est le conteneur Stack“conteneur d' Object”qui a été vu à la fin du Chapitre 15 dans OStackTest.cpp.
Si le programmeur client ne supprime pas explicitement les pointeurs sur objets qui sont contenus dans le conteneur, alors le conteneur devrait être capable d'effacer correctement ces pointeurs. Il faut le dire, le conteneur “s'approprie” tous les objets qui n'ont pas été supprimés, et est ainsi chargé de leur effacement. Le hic est que le nettoyage nécessite de connaitre le type de l'objet, et que la création d'une classe de conteneur générique nécessite de ne pas connaitre le type de l'objet. Avec les templates, cependant, nous pouvons écrire du code qui ne connait pas le type de l'objet, et modéliser facilement une nouvelle version du conteneur pour chaque type que nous voulons contenir. Les conteneurs modélisés individuels connaissent le type des objets qu'ils contiennent et peuvent ainsi appeler le destructeur correct (en supposant, dans le cas typique où le polymorphisme est mis en jeu, qu'un destructeur virtuel a été fourni).
Pour Stack cela se révèle être assez simple puisque toutes les fonctions membres peuvent être raisonnablement « inlined »:
//: C16:TStack.h
// Stack comme template
#ifndef TSTACK_H
#define TSTACK_H
template<class T>
class Stack {
struct Link {
T* data;
Link* next;
Link(T* dat, Link* nxt):
data(dat), next(nxt) {}
}* head;
public:
Stack() : head(0) {}
~Stack(){
while(head)
delete pop();
}
void push(T* dat) {
head = new Link(dat, head);
}
T* peek() const {
return head ? head->data : 0;
}
T* pop(){
if(head == 0) return 0;
T* result = head->data;
Link* oldHead = head;
head = head->next;
delete oldHead;
return result;
}
};
#endif // TSTACK_H ///:~Si vous comparez cela à l'exemple OStack.h à la fin du Chapitre 15, vous verrez que Stack est virtuellement identique, excepté le fait que Object a été remplacé par T. Le programme de test est aussi presque identique, excepté le fait que la nécessité pour le multihéritage, de string et de Object(et même la nécessité pour Object lui-même) a été éliminée. Maintenant il n'y a pas de classe MyString pour annoncer sa destruction, ainsi une nouvelle petite classe est ajoutée pour montrer qu'un conteneur Stack efface ses objets:
//: C16:TStackTest.cpp
//{T} TStackTest.cpp
#include "TStack.h"
#include "../require.h"
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
class X {
public:
virtual ~X() { cout << "~X " << endl; }
};
int main(int argc, char* argv[]) {
requireArgs(argc, 1); // File name is argument
ifstream in(argv[1]);
assure(in, argv[1]);
Stack<string> textlines;
string line;
// Lit le fichier et stocke les lignes dans Stack:
while(getline(in, line))
textlines.push(new string(line));
// Saute quelques lignes de Stack:
string* s;
for(int i = 0; i < 10; i++) {
if((s = (string*)textlines.pop())==0) break;
cout << *s << endl;
delete s;
} // Le destructeur efface les autres chaines de caractères.
// Montre que la destruction correcte a lieu:
Stack<X> xx;
for(int j = 0; j < 10; j++)
xx.push(new X);
} ///:~Le destructeur pour X est virtuel, non pas parce que cela est nécessaire ici, mais parce que xx pourrait être utilisé plus tard pour contenir des objets derivés de X.
Notez comme il est facile de créer différentes sortes de Stacks pour strings et pour X. Grâce au template, vous obtenez le meilleur des deux mondes: la facilité d'utilisation de la classe Stack avec un nettoyage approprié.
XVII-D-1. Pointeur Stash modélisé▲
Réorganiser le code de PStash dans un template n'est pas si simple parce qu'un certain nombre de fonctions membres ne devraient pas être « inlined ». Néanmoins, en tant que templates ces définitions de fonctions sont toujours présentes dans le fichier d'en-tête (le compilateur et l'éditeur de liens s'occupent de tout problème de définition multiple). Le code semble assez similaire à l'ordinaire PStash excepté que vous noterez que la taille de l'incrémentation (utilisée par inflate( )) a été modélisée comme un paramètre non-classe avec une valeur par défaut, si bien que la taille d'incrémentation peut être modifiée au point de modélisation (notez que cela signifie que la taille d'incrémentation est fixée ; vous pourriez aussi objecter que la taille d'incrémentation devrait être changeable tout au long de la durée de vie de l'objet):
//: C16:TPStash.h
#ifndef TPSTASH_H
#define TPSTASH_H
template<class T, int incr = 10>
class PStash {
int quantity; // Nombre d'espaces de stockage
int next; // Prochain espace vide
T** storage;
void inflate(int increase = incr);
public:
PStash() : quantity(0), next(0), storage(0) {}
~PStash();
int add(T* element);
T* operator[](int index) const; // Fetch
// Efface la référence de ce PStash:
T* remove(int index);
// Nombre d'éléments dans Stash:
int count() const { return next; }
};
template<class T, int incr>
int PStash<T, incr>::add(T* element) {
if(next >= quantity)
inflate(incr);
storage[next++] = element;
return(next - 1); // Index number
}
// Propriété des pointeurs restants:
template<class T, int incr>
PStash<T, incr>::~PStash() {
for(int i = 0; i < next; i++) {
delete storage[i]; // Null pointers OK
storage[i] = 0; // Just to be safe
}
delete []storage;
}
template<class T, int incr>
T* PStash<T, incr>::operator[](int index) const {
require(index >= 0,
"PStash::operator[] index negative");
if(index >= next)
return 0; // To indicate the end
require(storage[index] != 0,
"PStash::operator[] returned null pointer");
// Produit un pointeur pour l'élément désiré:
return storage[index];
}
template<class T, int incr>
T* PStash<T, incr>::remove(int index) {
// operator[] exécute des contrôles de validité:
T* v = operator[](index);
// "Supprime" le pointeur:
if(v != 0) storage[index] = 0;
return v;
}
template<class T, int incr>
void PStash<T, incr>::inflate(int increase) {
const int psz = sizeof(T*);
T** st = new T*[quantity + increase];
memset(st, 0, (quantity + increase) * psz);
memcpy(st, storage, quantity * psz);
quantity += increase;
delete []storage; // Ancien stockage
storage = st; // Pointe vers la nouvelle mémoire
}
#endif // TPSTASH_H ///:~La taille d'incrémentation par défaut utilisée ici est petite pour garantir que les appels à inflate( ) ont lieu. De cette manière nous pouvons nous assurer que cela fonctionne correctement.
Pour tester le contrôle de propriété du PStash modélisé, la classe suivante va afficher les créations et destructions d'elle-même, et ainsi garantir que tous les objets qui ont été créés ont aussi été détruits. AutoCounter va seulement autoriser les objets de son type à être créés sur le Stack:
//: C16:AutoCounter.h
#ifndef AUTOCOUNTER_H
#define AUTOCOUNTER_H
#include "../require.h"
#include <iostream>
#include <set> // conteneur de la Bibliothèque Standard C++
#include <string>
class AutoCounter {
static int count;
int id;
class CleanupCheck {
std::set<AutoCounter*> trace;
public:
void add(AutoCounter* ap) {
trace.insert(ap);
}
void remove(AutoCounter* ap) {
require(trace.erase(ap) == 1,
"Tentative de double suppression de AutoCounter");
}
~CleanupCheck() {
std::cout << "~CleanupCheck()"<< std::endl;
require(trace.size() == 0,
"Tous les objets AutoCounter ne sont pas effacés");
}
};
static CleanupCheck verifier;
AutoCounter() : id(count++) {
verifier.add(this); // Register itself
std::cout << "created[" << id << "]"
<< std::endl;
}
// Empêche l'affectation et la construction de copie:
AutoCounter(const AutoCounter&);
void operator=(const AutoCounter&);
public:
// Vous pouvez seulement créer des objets avec cela:
static AutoCounter* create() {
return new AutoCounter();
}
~AutoCounter() {
std::cout << "destroying[" << id
<< "]" << std::endl;
verifier.remove(this);
}
// Affiche les objets et les pointeurs:
friend std::ostream& operator<<(
std::ostream& os, const AutoCounter& ac){
return os << "AutoCounter " << ac.id;
}
friend std::ostream& operator<<(
std::ostream& os, const AutoCounter* ac){
return os << "AutoCounter " << ac->id;
}
};
#endif // AUTOCOUNTER_H ///:~La classe AutoCounter effectue deux choses. Premièrement, elle dénombre séquentiellement chaque instance de l' AutoCounter: la valeur de ce nombre est gardée dans id, et le nombre est généré en utilisant la donnée membre statique count.
Deuxièmement, plus complexe encore, une instance static(appelée verifier) de la classe imbriquée CleanupCheck garde la trace de tous les objets AutoCounter qui sont créés et détruits, et vous l'affiche en retour si vous ne les nettoyez pas tous (i.e. s'il y a une fuite de mémoire). Ce comportement est accompli en utilisant une classe set de la Bibliothèque Standard C++, ce qui est un merveilleux exemple montrant comment les bibliothèques de templates optimisées peuvent rendre la vie facile (vous pouvez prendre connaissance de tous les conteneurs de la Bibliothèque Standard C++ dans le Volume 2 de ce livre , disponible en ligne).
La classe set est modélisée sur le type qu'elle contient; ici, elle est représentée par une instance pour contenir les pointeurs AutoCounter. Un set permet seulement d'ajouter une instance distincte de chaque objet; dans add( ) vous pouvez voir cela intervenir avec la fonction set::insert( ). insert( ) vous informe en réalité par la valeur qu'elle retourne, si vous essayez d'ajouter quelque chose qui a déjà été ajouté; néanmoins, puisque les adresses d'objets sont ajoutées, nous pouvons compter sur la garantie du C++ que tous les objets ont des adresses uniques.
Dans remove( ), set::erase( ) est utilisé pour effacer du set le pointeur de l' AutoCounter. La valeur retournée vous indique combien d'instances de l'élément ont été effacées; dans notre cas nous attendons seulement zéro ou une. Si la valeur est zéro, toutefois, cela signifie que cet objet a déjà été effacé du set et que vous essayez de l'effacer une seconde fois, ce qui est une erreur de programmation qui va être affichée par require( ).
Le destructeur pour CleanupCheck effectue une vérification finale en s'assurant que la taille du set est zéro – cela signifie que tous les objets ont été proprement effacés. Si elle n'est pas de zéro, vous avez une fuite de mémoire, ce qui est affiché par require( ).
Le constructeur et le destructeur pour AutoCounter s'inscrivent et se désinscrivent avec l'objet verifier. Notez que le constructeur, le constructeur de copie, et l'opérateur d'affectation sont private, ainsi le seul moyen pour vous de créer un objet est avec la fonction membre static create( )– ceci est un exemple simple de factory, et cela garantit que tous les objets sont créés sur le tas, ainsi le verifier ne va pas s'y perdre entre les affectations et les constructeurs de copies.
Puisque toutes les fonctions membres ont été « inlined », le seul intérêt du fichier d'implémentation est de contenir les définitions des données membres statiques:
//: C16:AutoCounter.cpp {O}
// Definition des classes membres statiques
#include "AutoCounter.h"
AutoCounter::CleanupCheck AutoCounter::verifier;
int AutoCounter::count = 0;
///:~Avec l' AutoCounter en main, nous pouvons maintenant tester les possibilités du PStash. L'exemple suivant ne montre pas seulement que le destructeur PStash nettoie tous les objets qu'il possède, mais il démontre aussi comment la classe d' AutoCounter détecte les objets qui n'ont pas été nettoyés:
//: C16:TPStashTest.cpp
//{L} AutoCounter
#include "AutoCounter.h"
#include "TPStash.h"
#include <iostream>
#include <fstream>
using namespace std;
int main() {
PStash<AutoCounter> acStash;
for(int i = 0; i < 10; i++)
acStash.add(AutoCounter::create());
cout << "Enlève 5 manuellement:" << endl;
for(int j = 0; j < 5; j++)
delete acStash.remove(j);
cout << "En enlève deux sans les effacer:"
<< endl;
// ... pour générer le message d'erreur de nettoyage.
cout << acStash.remove(5) << endl;
cout << acStash.remove(6) << endl;
cout << "Le destructeur nettoie le reste:"
<< endl;
// Répete le test des chapitres précédents:
ifstream in("TPStashTest.cpp");
assure(in, "TPStashTest.cpp");
PStash<string> stringStash;
string line;
while(getline(in, line))
stringStash.add(new string(line));
// Affiche les chaînes de caractères:
for(int u = 0; stringStash[u]; u++)
cout << "stringStash[" << u << "] = "
<< *stringStash[u] << endl;
} ///:~Quand les éléments de l' AutoCounter 5 et 6 sont effacés du PStash, ils passent sous la responsabilité de l'appelant, mais tant que l'appelant ne les nettoie pas, ils causent des fuites de mémoire, qui sont ensuite détectées par l' AutoCounter au moment de l'exécution.
Quand vous démarrez le programme, vous voyez que le message d'erreur n'est pas aussi spécifique qu'il pourrait l'être. Si vous utilisez le schéma présenté dans l' AutoCounter pour découvrir les fuites de mémoire dans votre propre système vous voudrez probablement voir s'afficher des informations plus détaillées sur les objets qui n'ont pas été nettoyés. Le Volume 2 de ce livre montre des manières plus sophistiquées de le faire.
XVII-E. Activer et désactiver la possession▲
Revenons sur le cas de la possession. Les conteneurs qui stockent les objets par valeur ne tiennent pas compte de la possession parce qu'ils possèdent clairement l'objet qu'ils contiennent. Mais si votre conteneur stocke des pointeurs (ce qui est plus courant en C++, spécialement avec le polymorphisme), il est alors très probable que ces pointeurs soient aussi utilisés autre part dans le programme, et vous ne voulez pas nécessairement supprimer l'objet parce qu'alors les autres pointeurs du programme référenceraient un objet détruit. Pour éviter ça, vous devez penser à la possession quand vous concevez et utilisez un conteneur.
Beaucoup de programmes sont plus simples que cela et ne rencontrent pas le problème de possession : un conteneur stocke des pointeurs sur des objets qui sont utilisés uniquement par ce conteneur. Dans ce cas la possession est vraiment simple : le conteneur possède ses objets.
La meilleure approche pour gérer le problème de possession est de donner un choix au programmeur client. C'est souvent accompli par un argument du constructeur qui indique par défaut la possession (cas le plus simple). En outre il peut y avoir des fonctions “get” et “set” pour lire et modifier la possession du conteneur. Si le conteneur a des fonctions pour supprimer un objet, l'état de possession affecte généralement cette suppression, et vous pouvez donc trouver des options pour contrôler la destruction dans la fonction de suppression. On peut concevoir que vous puissiez ajouter une donnée de possession pour chaque élément dans le conteneur, de telle sorte que chaque position saurait si elle a besoin d'être détruite ; c'est une variante du compteur de référence, excepté que le conteneur et non l'objet connait le nombre de références pointant sur un objet.
//: C16:OwnerStack.h
// Stack avec contrôle de possession à l'exécution
#ifndef OWNERSTACK_H
#define OWNERSTACK_H
template<class T> class Stack {
struct Link {
T* data;
Link* next;
Link(T* dat, Link* nxt)
: data(dat), next(nxt) {}
}* head;
bool own;
public:
Stack(bool own = true) : head(0), own(own) {}
~Stack();
void push(T* dat) {
head = new Link(dat,head);
}
T* peek() const {
return head ? head->data : 0;
}
T* pop();
bool owns() const { return own; }
void owns(bool newownership) {
own = newownership;
}
// Auto-conversion de type : vrai si pas vide :
operator bool() const { return head != 0; }
};
template<class T> T* Stack<T>::pop() {
if(head == 0) return 0;
T* result = head->data;
Link* oldHead = head;
head = head->next;
delete oldHead;
return result;
}
template<class T> Stack<T>::~Stack() {
if(!own) return;
while(head)
delete pop();
}
#endif // OWNERSTACK_H ///:~Le comportement par défaut pour le conteneur est de détruire ses objets, mais vous pouvez le changer soit en modifiant l'argument du constructeur soit en utilisant les fonctions membres owns( ) de lecture/écriture.
Comme avec le plus grand nombre de templates que vous êtes susceptibles de voir, toute l'implémentation est contenue dans le fichier d'en-tête. Voici un petit test qui exerce les facultés de possession :
//: C16:OwnerStackTest.cpp
//{L} AutoCounter
#include "AutoCounter.h"
#include "OwnerStack.h"
#include "../require.h"
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main() {
Stack<AutoCounter> ac; // possession activée
Stack<AutoCounter> ac2(false); // Désactive la possession
AutoCounter* ap;
for(int i = 0; i < 10; i++) {
ap = AutoCounter::create();
ac.push(ap);
if(i % 2 == 0)
ac2.push(ap);
}
while(ac2)
cout << ac2.pop() << endl;
// Pas de destruction nécessaire puisque
// ac "possède" tous les objets
} ///:~L'objet ac2 ne possède pas les objets que vous mettez dedans, ainsi ac est le conteneur “maître” qui prend la responsabilité de la possession. Si, à un moment quelconque de la durée de vie du conteneur, vous voulez changer le fait que le conteneur possède ses objets, vous pouvez le faire en utilisant owns( ).
Il serait aussi possible aussi de changer la granularité de la possession afin qu'elle soit définie objet par objet, mais cela rendra probablement la solution au problème de possession plus complexe que le problème lui-même.
XVII-F. Stocker des objets par valeur▲
En fait, créer une copie des objets dans un conteneur générique est un problème complexe si vous n'avez pas les templates. Avec les templates, ces choses sont relativement simples – vous dites juste que vous stockez des objets plutôt que des pointeurs :
//: C16:ValueStack.h
// Stockage d'objets par valeur dans une pile
#ifndef VALUESTACK_H
#define VALUESTACK_H
#include "../require.h"
template<class T, int ssize = 100>
class Stack {
// Le constructeur par défaut effectue
// l'initialisation de chaque élément dans le tableau :
T stack[ssize];
int top;
public:
Stack() : top(0) {}
// Le constructeur pa recopie copie les objets dans le tableau :
void push(const T& x) {
require(top < ssize, "Too many push()es");
stack[top++] = x;
}
T peek() const { return stack[top]; }
// L'Objet existe encore quand vous le dépilez ;
// il est seulement plus disponible :
T pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
};
#endif // VALUESTACK_H ///:~Le constructeur par recopie pour l'objet contenu effectue la majorité du travail en passant et retournant les objets par valeur. À l'intérieur de push( ), le stockage de l'objet dans la table de la Pile est accompli avec T::operator=. Pour garantir que ceci fonctionne, une classe appelée SelfCounter garde la trace des créations d'objets et des constructeurs par recopie :
//: C16:SelfCounter.h
#ifndef SELFCOUNTER_H
#define SELFCOUNTER_H
#include "ValueStack.h"
#include <iostream>
class SelfCounter {
static int counter;
int id;
public:
SelfCounter() : id(counter++) {
std::cout << "Created: " << id << std::endl;
}
SelfCounter(const SelfCounter& rv) : id(rv.id){
std::cout << "Copied: " << id << std::endl;
}
SelfCounter operator=(const SelfCounter& rv) {
std::cout << "Assigned " << rv.id << " to "
<< id << std::endl;
return *this;
}
~SelfCounter() {
std::cout << "Destroyed: "<< id << std::endl;
}
friend std::ostream& operator<<(
std::ostream& os, const SelfCounter& sc){
return os << "SelfCounter: " << sc.id;
}
};
#endif // SELFCOUNTER_H ///:~
//: C16:SelfCounter.cpp {O}
#include "SelfCounter.h"
int SelfCounter::counter = 0; ///:~
//: C16:ValueStackTest.cpp
//{L} SelfCounter
#include "ValueStack.h"
#include "SelfCounter.h"
#include <iostream>
using namespace std;
int main() {
Stack<SelfCounter> sc;
for(int i = 0; i < 10; i++)
sc.push(SelfCounter());
// peek() possible, le résultat est un temporaire :
cout << sc.peek() << endl;
for(int k = 0; k < 10; k++)
cout << sc.pop() << endl;
} ///:~Quand un conteneur Stack est créé, le constructeur par défaut de l'objet contenu est appelé pour chaque objet dans le tableau. Vous verrez initialement 100 objets SelfCounter créés pour raison apparente, mais c'est juste l'initialisation du tableau. Cela peut être un peu onéreux, mais il n'y a pas d'autre façon de faire dans une conception simple comme celle-ci. Une situation bien plus complexe surgit si vous rendez Stack plus générale en permettant à la taille d'augmenter dynamiquement, parce que dans l'implémentation montrée précédemment ceci impliquerait de créer un nouveau tableau (plus large), en copiant l'ancien tableau dans le nouveau, et en détruisant l'ancien tableau (ceci est, en fait, ce que fait la classe vector de la librairie standard C++).
XVII-G. Présentation des itérateurs▲
Un itérateur est un objet qui parcourt un conteneur d'autres objets et en sélectionne un à la fois, sans fournir d'accès direct à l'implémentation de ce conteneur. Les itérateurs fournissent une manière standardisée d'accéder aux éléments, qu'un conteneur fournisse ou non un moyen d'accéder directement aux éléments. Vous verrez les itérateurs utilisés le plus souvent en association avec des classes conteneurs, et les itérateurs sont un concept fondamental dans la conception et l'utilisation des conteneurs standards du C++, qui sont complètement décrits dans le Volume 2 de ce livre (téléchargeable à www.BruceEckel.com). Un itérateur est également une sorte de modèle de conception, qui est le sujet d'un chapitre du Volume 2.
De bien des façons, un itérateur est un “pointeur futé”, et vous noterez en fait que les itérateurs imitent généralement la plupart des opérations des pointeurs. Contrairement à un pointeur, toutefois, l'itérateur est conçu pour être sûr, et il est donc moins probable que vous fassiez l'équivalent d'excéder les limites d'un tableau (ou si vous le faites, vous le découvrez plus facilement).
Considérez le premier exemple dans ce chapitre. Le voilà, avec un simple itérateur ajouté :
//: C16:IterIntStack.cpp
// Pile simple d'entiers avec des itérateurs
//{L} fibonacci
#include "fibonacci.h"
#include "../require.h"
#include <iostream>
using namespace std;
class IntStack {
enum { ssize = 100 };
int stack[ssize];
int top;
public:
IntStack() : top(0) {}
void push(int i) {
require(top < ssize, "Too many push()es");
stack[top++] = i;
}
int pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
friend class IntStackIter;
};
// Un itérateur est comme un pointeur "futé" :
class IntStackIter {
IntStack& s;
int index;
public:
IntStackIter(IntStack& is) : s(is), index(0) {}
int operator++() { // Prefix
require(index < s.top,
"iterator moved out of range");
return s.stack[++index];
}
int operator++(int) { // Postfix
require(index < s.top,
"iterator moved out of range");
return s.stack[index++];
}
};
int main() {
IntStack is;
for(int i = 0; i < 20; i++)
is.push(fibonacci(i));
// Traverse avec un itérateur:
IntStackIter it(is);
for(int j = 0; j < 20; j++)
cout << it++ << endl;
} ///:~Le IntStackIter a été créé pour fonctionner seulement avec un IntStack. Notez que IntStackIter est un friend de IntStack, ce qui lui donne accès à tous les éléments private de IntStack.
Comme un pointeur, le travail de IntStackIter et de se déplacer dans un IntStack et de récupérer des valeurs. Dans cet exemple simple, le IntStackIter ne peut se déplacer que vers l'avant (utilisant les deux formes, pre- et postfixée, de operator++). Toutefois, il n'y a pas de limite à la façon dont un itérateur peut être défini, autre que celles imposées par les contraintes du conteneur avec lequel il travaille. Il est tout à fait acceptable pour un itérateur (dans les limites du conteneur sous-jacent) de se déplacer de n'importe quelle façon au sein de son conteneur associé et d'être à l'origine de modifications des valeurs contenues.
Il est habituel qu'un itérateur soit créé avec un constructeur qui l'attache à un unique conteneur d'objets, et que l'itérateur ne soit pas attaché à un autre conteneur pendant sa durée de vie. (Les itérateurs sont souvent petits et peu coûteux, et vous pouvez donc facilement en faire un autre.)
Avec l'itérateur, vous pouvez traverser les éléments de la pile sans les dépiler, exactement de la même façon qu'un pointeur qui peut se déplacer à travers les éléments d'un tableau. Toutefois, l'itérateur connait la structure sous-jacente de la pile et comment traverser les éléments, et donc bien que vous vous déplaciez comme si vous “incrémentiez un pointeur”, ce qui se déroule en dessous est plus compliqué. C'est la clef des itérateurs : ils abstraient le processus complexe du déplacement d'un élément d'un conteneur au suivant en quelque chose qui ressemble à un pointeur. Le but est que chaque itérateur dans votre programme ait la même interface si bien que n'importe quel code qui utilise l'itérateur n'ait pas à se soucier de ce vers quoi il pointe – il sait juste qu'il peut repositionner tous les itérateurs de la même façon, et le conteneur vers lequel pointe l'itérateur n'a pas d'importance. De cette façon, vous pouvez écrire du code plus générique. Tous les conteneurs et algorithmes dans la bibliothèque standard du C++ sont basés sur ce principe d'itérateurs.
Pour aider à faire des choses plus génériques, il serait pratique d'être capable de dire “chaque conteneur a une classe associée appelée iterator, « mais cela causera généralement des problèmes de noms. La solution est d'ajouter une classe iterator imbriquée à chaque conteneur (remarquez que dans ce cas, « iterator” commence par une minuscule afin de se conformer au style de la bibliothèque standard du C++). Voici IterIntStack.cpp avec un iterator imbriqué :
//: C16:NestedIterator.cpp
// Imbriquer un itérateur dans le conteneur
//{L} fibonacci
#include "fibonacci.h"
#include "../require.h"
#include <iostream>
#include <string>
using namespace std;
class IntStack {
enum { ssize = 100 };
int stack[ssize];
int top;
public:
IntStack() : top(0) {}
void push(int i) {
require(top < ssize, "Too many push()es");
stack[top++] = i;
}
int pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
class iterator;
friend class iterator;
class iterator {
IntStack& s;
int index;
public:
iterator(IntStack& is) : s(is), index(0) {}
// Pour créer l'itérateur surveillant la fin :
iterator(IntStack& is, bool)
: s(is), index(s.top) {}
int current() const { return s.stack[index]; }
int operator++() { // Prefix
require(index < s.top,
"iterator moved out of range");
return s.stack[++index];
}
int operator++(int) { // Postfix
require(index < s.top,
"iterator moved out of range");
return s.stack[index++];
}
// Déplace un itérateur vers l'avant
iterator& operator+=(int amount) {
require(index + amount < s.top,
"IntStack::iterator::operator+=() "
"tried to move out of bounds");
index += amount;
return *this;
}
// Pour voir sivous êtes au bout :
bool operator==(const iterator& rv) const {
return index == rv.index;
}
bool operator!=(const iterator& rv) const {
return index != rv.index;
}
friend ostream&
operator<<(ostream& os, const iterator& it) {
return os << it.current();
}
};
iterator begin() { return iterator(*this); }
// Créer la "sentinelle de fin" :
iterator end() { return iterator(*this, true);}
};
int main() {
IntStack is;
for(int i = 0; i < 20; i++)
is.push(fibonacci(i));
cout << "Traverse the whole IntStack\n";
IntStack::iterator it = is.begin();
while(it != is.end())
cout << it++ << endl;
cout << "Traverse a portion of the IntStack\n";
IntStack::iterator
start = is.begin(), end = is.begin();
start += 5, end += 15;
cout << "start = " << start << endl;
cout << "end = " << end << endl;
while(start != end)
cout << start++ << endl;
} ///:~Quand vous créez une classe friend imbriquée, vous devez suivre la procédure qui consiste à déclarer d'abord le nom de la classe, puis de la déclarer comme une friend, enfin de définir la classe. Autrement, le compilateur sera perdu.
De nouveaux trucs ont été ajoutés à l'itérateur. La fonction membre current( ) produit l'élément du conteneur que sélectionne actuellement l'itérateur. Vous pouvez faire “sauter” un itérateur vers l'avant d'un nombre arbitraire d'éléments en utilisant operator+=. Vous verrez également deux opérateurs surchargés : == et != qui compareront un itérateur avec un autre. Ils peuvent comparer n'importe quel couple de IntStack::iterator, mais ils sont avant tout destinés à vérifier si un itérateur est à la fin d'une séquence, de la même façon dont les itérateurs de la “vraie” bibliothèque standard du C++ le font. L'idée est que deux itérateurs définissent un intervalle, incluant le premier élément pointé par le premier itérateur jusqu'au dernier élément pointé par le deuxième itérateur, sans l'inclure. Donc si vous voulez vous déplacer dans l'intervalle défini par les deux itérateurs, vous dites quelque chose comme :
while(start != end)
cout << start++ << endl;où start et end sont les deux itérateurs dans l'intervalle. Notez que l'itérateur end, auquel nous nous référons souvent comme à la sentinelle de la fin, n'est pas déréférencé et est ici pour vous dire que vous êtes à la fin de la séquence. Ainsi il représente “un pas après la fin”.
La plupart du temps, vous voudrez vous déplacer à travers toute la séquence d'un conteneur, et le conteneur a donc besoin d'un moyen de produire les itérateurs indiquant le début de la séquence et la sentinelle de la fin. Ici, comme dans la bibliothèque standard du C++, ces itérateurs sont produits par les fonctions membres du conteneur begin( ) et end( ). begin( ) utilise le premier constructeur de iterator qui pointe par défaut au début du conteneur (c'est le premier élément poussé sur la pile). Toutefois un second constructeur, utilisé par end( ), est nécessaire pour créer l' iterator sentinelle de la fin. Être “à la fin” signifie pointer vers le haut de la pile, parce que top indique toujours le prochain espace disponible – mais non utilisé – sur la pile. Ce constructeur d' iterator prend un second argument du type bool, qui est un argument factice pour distinguer les deux constructeurs.
Les nombres Fibonacci sont utilisés à nouveau pour remplir le IntStack dans main( ), et les iterator sont utilisés pour se déplacer à travers tout le IntStack ainsi que dans un intervalle étroit de la séquence.
L'étape suivante, bien sûr, est de rendre le code général en le transformant en template sur le type qu'il contient, afin qu'au lieu d'être forcé à contenir uniquement des int vous puissiez stocker n'importe quel type :
//: C16:IterStackTemplate.h
// Template de pile simple avec itérateur imbriqué
#ifndef ITERSTACKTEMPLATE_H
#define ITERSTACKTEMPLATE_H
#include "../require.h"
#include <iostream>
template<class T, int ssize = 100>
class StackTemplate {
T stack[ssize];
int top;
public:
StackTemplate() : top(0) {}
void push(const T& i) {
require(top < ssize, "Too many push()es");
stack[top++] = i;
}
T pop() {
require(top > 0, "Too many pop()s");
return stack[--top];
}
class iterator; // Déclaration requise
friend class iterator; // Faites-en un ami
class iterator { // A présent définissez-le
StackTemplate& s;
int index;
public:
iterator(StackTemplate& st): s(st),index(0){}
// pour créer l'itérateur "sentinelle de fin" :
iterator(StackTemplate& st, bool)
: s(st), index(s.top) {}
T operator*() const { return s.stack[index];}
T operator++() { // Forme préfixe
require(index < s.top,
"iterator moved out of range");
return s.stack[++index];
}
T operator++(int) { // Forme postfix
require(index < s.top,
"iterator moved out of range");
return s.stack[index++];
}
// Fait avancer un itérateur
iterator& operator+=(int amount) {
require(index + amount < s.top,
" StackTemplate::iterator::operator+=() "
"tried to move out of bounds");
index += amount;
return *this;
}
// Pour voir si vous êtes à la fin :
bool operator==(const iterator& rv) const {
return index == rv.index;
}
bool operator!=(const iterator& rv) const {
return index != rv.index;
}
friend std::ostream& operator<<(
std::ostream& os, const iterator& it) {
return os << *it;
}
};
iterator begin() { return iterator(*this); }
// Crée la "sentinelle de la fin" :
iterator end() { return iterator(*this, true);}
};
#endif // ITERSTACKTEMPLATE_H ///:~Vous pouvez voir que la transformation d'une classe normale en un template est relativement claire. Cette approche qui consiste à créer et déboguer d'abord une classe ordinaire, puis d'en faire un template, est généralement considérée plus simple que de créer le template à partir de rien.
Notez qu'au lieu de dire simplement :
friend iterator; // Faites-en un amiCe code a :
friend class iterator; // Faites-en un amiC'est important parce que le nom “iterator” est déjà dans la portée, depuis un fichier inclus.
Au lieu de la fonction membre current( ), l' iterator a un operator* pour sélectionner le membre courant, qui fait plus ressembler l'itérateur à un pointeur. C'est une pratique commune.
Voici l'exemple révisé pour tester le template :
//: C16:IterStackTemplateTest.cpp
//{L} fibonacci
#include "fibonacci.h"
#include "IterStackTemplate.h"
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main() {
StackTemplate<int> is;
for(int i = 0; i < 20; i++)
is.push(fibonacci(i));
// Traverse avec un iterateur :
cout << "Traverse the whole StackTemplate\n";
StackTemplate<int>::iterator it = is.begin();
while(it != is.end())
cout << it++ << endl;
cout << "Traverse a portion\n";
StackTemplate<int>::iterator
start = is.begin(), end = is.begin();
start += 5, end += 15;
cout << "start = " << start << endl;
cout << "end = " << end << endl;
while(start != end)
cout << start++ << endl;
ifstream in("IterStackTemplateTest.cpp");
assure(in, "IterStackTemplateTest.cpp");
string line;
StackTemplate<string> strings;
while(getline(in, line))
strings.push(line);
StackTemplate<string>::iterator
sb = strings.begin(), se = strings.end();
while(sb != se)
cout << sb++ << endl;
} ///:~La première utilisation de l'itérateur se déplace simplement du début à la fin (et montre que la sentinelle de fin fonctionne correctement). Dans la deuxième utilisation, vous pouvez voir comment les itérateurs vous permettent de spécifier facilement un intervalle d'éléments (les conteneurs et les itérateurs dans la bibliothèque standard du C++ utilisent ce concept d'intervalle presque partout). Le operator+= surchargé déplace les itérateurs start et end vers des positions situées au milieu de l'intervalle des éléments dans is, et ces éléments sont affichés. Notez dans la sortie que la sentinelle n'est pas incluse dans l'intervalle, ainsi elle peut se trouver un cran au-delà de la fin pour vous faire savoir que vous avez passé la fin – mais vous ne déréférencez pas la sentinelle de fin, ou sinon vous pouvez finir par déréférencer un pointeur nul. (J'ai mis une garde dans le StackTemplate::iterator, mais il n'y a pas de code de ce genre dans les conteneurs et les itérateurs de la bibliothèque standard du C++ – pour des raisons d'efficacité – et vous devez donc faire attention.)
Finalement, pour vérifier que le StackTemplate fonctionne avec des objets de classes, on en instancie un pour string et on le remplit de lignes du fichier de code source, qui sont ensuite affichées.
XVII-G-1. Stack avec itérateurs▲
Nous pouvons répéter le procédé avec la classe Stack dimensionnée dynamiquement qui a été utilisée comme exemple tout au long du livre. Voici la classe Stack dans laquelle on a glissé un itérateur imbriqué :
//: C16:TStack2.h
// Stack rendue template avec itérateur imbriqué
#ifndef TSTACK2_H
#define TSTACK2_H
template<class T> class Stack {
struct Link {
T* data;
Link* next;
Link(T* dat, Link* nxt)
: data(dat), next(nxt) {}
}* head;
public:
Stack() : head(0) {}
~Stack();
void push(T* dat) {
head = new Link(dat, head);
}
T* peek() const {
return head ? head->data : 0;
}
T* pop();
// Classe iterator imbriquée :
class iterator; // Déclaration requise
friend class iterator; // En fait un friend
class iterator { // Le définit maintenant
Stack::Link* p;
public:
iterator(const Stack<T>& tl) : p(tl.head) {}
// Constructeur par recopie :
iterator(const iterator& tl) : p(tl.p) {}
// Itérateur sentinelle de fin :
iterator() : p(0) {}
// operator++ retourne un booléen indiquant la fin :
bool operator++() {
if(p->next)
p = p->next;
else p = 0; // Indique la fin de la liste
return bool(p);
}
bool operator++(int) { return operator++(); }
T* current() const {
if(!p) return 0;
return p->data;
}
// opérateur de déréférencement de pointeur :
T* operator->() const {
require(p != 0,
"PStack::iterator::operator->returns 0");
return current();
}
T* operator*() const { return current(); }
// Conversion en bool pour test conditionnel :
operator bool() const { return bool(p); }
// Comparaison pour tester la fin :
bool operator==(const iterator&) const {
return p == 0;
}
bool operator!=(const iterator&) const {
return p != 0;
}
};
iterator begin() const {
return iterator(*this);
}
iterator end() const { return iterator(); }
};
template<class T> Stack<T>::~Stack() {
while(head)
delete pop();
}
template<class T> T* Stack<T>::pop() {
if(head == 0) return 0;
T* result = head->data;
Link* oldHead = head;
head = head->next;
delete oldHead;
return result;
}
#endif // TSTACK2_H ///:~Vous remarquerez également que la classe a été modifiée pour supporter la propriété, qui maintenant fonctionne parce que la classe connait le type exact (ou au moins le type de base, ce qui fonctionnera en supposant que les destructeurs virtuels sont utilisés). Par défaut le conteneur détruit ses objets, mais vous êtes responsable de chaque pointeur que vous dépilez avec pop( ).
L'itérateur est simple, et physiquement très petit – de la taille d'un simple pointeur. Quand vous créez un iterator, il est initialisé à la tête de la liste chaînée, et vous ne pouvez l'incrémenter que vers l'avant de la liste. Si vous voulez recommencer au début, vous créez un nouvel itérateur, et si vous voulez vous rappeler d'un point dans la liste, vous créez un nouvel itérateur à partir de l'itérateur existant qui pointe vers ce point (en utilisant le constructeur par recopie de l'itérateur).
Pour appeler des fonctions pour l'objet référencé par l'itérateur, vous pouvez utiliser la fonction current( ), le operator*, ou le operator-> déréférenceur (commun dans les itérateurs). Ce dernier a une implémentation qui paraît identique à current( ) parce qu'il retourne un pointeur vers l'objet courant, mais il est différent parce que l'opérateur déréfenceur réalise des niveaux supplémentaires de déréférencement (cf. Chapitre 12).
La classe iterator suit la forme que vous avez vue dans l'exemple précédent. La classe iterator est imbriquée dans la classe conteneur, il contient des constructeurs pour créer un itérateur pointant vers un élément dans le conteneur et pour créer un itérateur “sentinelle de fin”, et la classe conteneur possède les méthodes begin( ) et end( ) pour produire ces itérateurs. (Quand vous en apprendrez plus sur la bibliothèque standard du C++, vous verrez que les noms iterator, begin( ), et end( ) utilisés ici étaient clairement inspirés des classes conteneur standards. À la fin de ce chapitre, vous verrez que cela permet à ces classes de conteneur d'être utilisées comme si elles étaient des classes conteneurs de la bibliothèque standard du C++.)
L'implémentation entière est contenue dans le fichier d'en-tête, et il n'y a donc pas de fichier cpp distinct. Voici un petit test qui expérimente l'itérateur :
//: C16:TStack2Test.cpp
#include "TStack2.h"
#include "../require.h"
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main() {
ifstream file("TStack2Test.cpp");
assure(file, "TStack2Test.cpp");
Stack<string> textlines;
// Lit le fichier et stocke les lignes dans la Stack :
string line;
while(getline(file, line))
textlines.push(new string(line));
int i = 0;
// Utilise l'iterateur pour afficher les lignes de la liste :
Stack<string>::iterator it = textlines.begin();
Stack<string>::iterator* it2 = 0;
while(it != textlines.end()) {
cout << it->c_str() << endl;
it++;
if(++i == 10) // se souvenir de la 10e ligne
it2 = new Stack<string>::iterator(it);
}
cout << (*it2)->c_str() << endl;
delete it2;
} ///:~Un Stack est instancié pour contenir des objets string et rempli par les lignes d'un fichier. Puis un itérateur est créé et utilisé pour se déplacer dans la séquence. La dixième ligne est mémorisée par copie-construction d'un deuxième itérateur à partir du premier ; plus tard, cette ligne est affichée et l'itérateur – créé dynamiquement – est détruit. Ici, la création dynamique des objets est utilisée pour contrôler la durée de vie de l'objet.
XVII-G-2. PStash avec les itérateurs▲
Pour la plupart des classes de conteneur, il est logique d'avoir un itérateur. Voici un itérateur ajouté à la classe PStash:
//: C16:TPStash2.h
// PStash rendu template avec itérateur imbriqué
#ifndef TPSTASH2_H
#define TPSTASH2_H
#include "../require.h"
#include <cstdlib>
template<class T, int incr = 20>
class PStash {
int quantity;
int next;
T** storage;
void inflate(int increase = incr);
public:
PStash() : quantity(0), storage(0), next(0) {}
~PStash();
int add(T* element);
T* operator[](int index) const;
T* remove(int index);
int count() const { return next; }
// Classe itérateur imbriquée :
class iterator; // Declaration requise
friend class iterator; // En fait un ami
class iterator { // A présent le définit
PStash& ps;
int index;
public:
iterator(PStash& pStash)
: ps(pStash), index(0) {}
// Pour créer la sentinelle de fin :
iterator(PStash& pStash, bool)
: ps(pStash), index(ps.next) {}
// Constructeur par recopie :
iterator(const iterator& rv)
: ps(rv.ps), index(rv.index) {}
iterator& operator=(const iterator& rv) {
ps = rv.ps;
index = rv.index;
return *this;
}
iterator& operator++() {
require(++index <= ps.next,
"PStash::iterator::operator++ "
"moves index out of bounds");
return *this;
}
iterator& operator++(int) {
return operator++();
}
iterator& operator--() {
require(--index >= 0,
"PStash::iterator::operator-- "
"moves index out of bounds");
return *this;
}
iterator& operator--(int) {
return operator--();
}
// Déplace l'itérateur vers l'avant ou l'arrière :
iterator& operator+=(int amount) {
require(index + amount < ps.next &&
index + amount >= 0,
"PStash::iterator::operator+= "
"attempt to index out of bounds");
index += amount;
return *this;
}
iterator& operator-=(int amount) {
require(index - amount < ps.next &&
index - amount >= 0,
"PStash::iterator::operator-= "
"attempt to index out of bounds");
index -= amount;
return *this;
}
// Crée un nouvel itérateur qui est déplacé vers l'avant
iterator operator+(int amount) const {
iterator ret(*this);
ret += amount; // op+= does bounds check
return ret;
}
T* current() const {
return ps.storage[index];
}
T* operator*() const { return current(); }
T* operator->() const {
require(ps.storage[index] != 0,
"PStash::iterator::operator->returns 0");
return current();
}
// Supprime l'élément courant :
T* remove(){
return ps.remove(index);
}
// Test de comparaison pour la fin :
bool operator==(const iterator& rv) const {
return index == rv.index;
}
bool operator!=(const iterator& rv) const {
return index != rv.index;
}
};
iterator begin() { return iterator(*this); }
iterator end() { return iterator(*this, true);}
};
// Destruction des objets contenus :
template<class T, int incr>
PStash<T, incr>::~PStash() {
for(int i = 0; i < next; i++) {
delete storage[i]; // Pointeurs nuls OK
storage[i] = 0; // Juste pour être sûr
}
delete []storage;
}
template<class T, int incr>
int PStash<T, incr>::add(T* element) {
if(next >= quantity)
inflate();
storage[next++] = element;
return(next - 1); // Numéro de l'index
}
template<class T, int incr> inline
T* PStash<T, incr>::operator[](int index) const {
require(index >= 0,
"PStash::operator[] index negative");
if(index >= next)
return 0; // Pour indiquer la fin
require(storage[index] != 0,
"PStash::operator[] returned null pointer");
return storage[index];
}
template<class T, int incr>
T* PStash<T, incr>::remove(int index) {
// operator[] vérifie la validité :
T* v = operator[](index);
// "Supprime" le pointeur:
storage[index] = 0;
return v;
}
template<class T, int incr>
void PStash<T, incr>::inflate(int increase) {
const int tsz = sizeof(T*);
T** st = new T*[quantity + increase];
memset(st, 0, (quantity + increase) * tsz);
memcpy(st, storage, quantity * tsz);
quantity += increase;
delete []storage; // Vieux stockage
storage = st; // Pointe vers le nouvel emplacement
}
#endif // TPSTASH2_H ///:~L'essentiel de ce fichier est une traduction relativement directe du précédent PStash et de l' iterator imbriqué en un template. Cette fois-ci, cependant, les opérateurs retournent des références vers l'itérateur courant, ce qui est l'approche la plus typique et la plus flexible qu'il convient d'adopter.
Le destructeur appelle delete pour tous les pointeurs contenus, et comme le type est capturé par le template, une destruction appropriée aura lieu. Vous devriez être conscient du fait que si le conteneur contient des pointeurs vers un type de classe de base, ce type devra avoir un destructeur virtuel pour garantir le nettoyage correct des objets dérivés dont les adresses ont été transtypée lorsqu'elles ont été placées dans le conteneur.
Le PStash::iterator suit le modèle d'itérateur attaché à un objet conteneur unique pour toute sa durée de vie. En outre, le constructeur par recopie vous permet de créer un nouvel itérateur pointant sur le même point que l'itérateur depuis lequel vous le créez, créant de fait un marque-page dans le conteneur. Les fonctions membres operator+= et operator-= vous permettent de déplacer un itérateur d'un certain nombre d'emplacements, tout en respectant les limites du conteneur. Les opérateurs d'incrémentation et décrémentation surchargés déplacent l'itérateur d'un emplacement. operator+ produit un nouvel itérateur qui est déplacé vers l'avant de la quantité de l'ajout. Comme dans l'exemple précédent, les opérateurs de déréférencement de pointeurs sont utilisés pour agir sur l'élément auquel renvoie l'itérateur, et remove( ) détruit l'objet courant en appelant le remove( ) du conteneur.
Le même genre de code qu'avant (dans le style des conteneurs de la bibliothèque standard du C++) est utilisé pour créer la sentinelle de fin : un deuxième constructeur, la fonction membre end( ) du conteneur, et operator== et operator!= pour comparaison.
L'exemple suivant crée et teste deux types différents d'objets Stash, un pour une nouvelle classe appelée Int qui annonce sa construction et sa destruction et une qui contient des objets de la classe string de la bibliothèque standard.
//: C16:TPStash2Test.cpp
#include "TPStash2.h"
#include "../require.h"
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Int {
int i;
public:
Int(int ii = 0) : i(ii) {
cout << ">" << i << ' ';
}
~Int() { cout << "~" << i << ' '; }
operator int() const { return i; }
friend ostream&
operator<<(ostream& os, const Int& x) {
return os << "Int: " << x.i;
}
friend ostream&
operator<<(ostream& os, const Int* x) {
return os << "Int: " << x->i;
}
};
int main() {
{ // Pour forcer l'appel au destructeur
PStash<Int> ints;
for(int i = 0; i < 30; i++)
ints.add(new Int(i));
cout << endl;
PStash<Int>::iterator it = ints.begin();
it += 5;
PStash<Int>::iterator it2 = it + 10;
for(; it != it2; it++)
delete it.remove(); // suppression par défaut
cout << endl;
for(it = ints.begin();it != ints.end();it++)
if(*it) // Remove() provoque des "trous"
cout << *it << endl;
} // Destructeur de "ints" appelé ici
cout << "\n-------------------\n";
ifstream in("TPStash2Test.cpp");
assure(in, "TPStash2Test.cpp");
// Instancié pour String:
PStash<string> strings;
string line;
while(getline(in, line))
strings.add(new string(line));
PStash<string>::iterator sit = strings.begin();
for(; sit != strings.end(); sit++)
cout << **sit << endl;
sit = strings.begin();
int n = 26;
sit += n;
for(; sit != strings.end(); sit++)
cout << n++ << ": " << **sit << endl;
} ///:~Par commodité, Int a un ostream operator<< associé pour un Int& comme pour un Int*.
Le premier bloc de code dans main( ) est entouré d'accolades pour forcer la destruction du PStash<Int> et ainsi le nettoyage automatique par ce destructeur. Un ensemble d'éléments est enlevé et effacé à la main pour montrer que le PStash nettoie le reste.
Pour les deux instances de PStash, un itérateur est créé et utilisé pour se déplacer dans le conteneur. Notez l'élégance qui résulte de l'utilisation de ces constructions ; vous n'êtes pas assaillis par les détails de l'implémentation de l'utilisation d'un tableau. Vous dites aux objets conteneur et itérateur que faire, pas comment. Ceci permet de conceptualiser, construire et modifier plus facilement la solution.
XVII-H. Pourquoi les itérateurs ?▲
Jusqu'à maintenant vous avez vu la mécanique des itérateurs, mais comprendre pourquoi ils sont aussi importants nécessite un exemple plus complexe.
Il est courant de voir le polymorphisme, la création d'objets dynamique, et les conteneurs utilisés ensemble dans un vrai programme orienté objet. Les conteneurs et la création dynamique des objets résolvent le problème de ne pas savoir combien ou de quel type d'objets vous aurez besoin. Et si le conteneur est configuré pour contenir des pointeurs vers des objets d'une classe de base, un transtypage a lieu à chaque fois que vous mettez un pointeur vers une classe dérivée dans le conteneur (avec les avantages associés de l'organisation du code et de l'extensibilité). Comme le code final du Volume 1 de ce livre, cet exemple assemblera également les différents aspects de tout ce que vous avez appris jusqu'ici – si vous pouvez suivre cet exemple, alors vous êtes prêt pour le volume 2.
Supposez que vous créez un programme qui permette à l'utilisateur d'éditer et de produire différents types de dessins. Chaque dessin est un objet qui contient une collection d'objets Shape:
//: C16:Shape.h
#ifndef SHAPE_H
#define SHAPE_H
#include <iostream>
#include <string>
class Shape {
public:
virtual void draw() = 0;
virtual void erase() = 0;
virtual ~Shape() {}
};
class Circle : public Shape {
public:
Circle() {}
~Circle() { std::cout << "Circle::~Circle\n"; }
void draw() { std::cout << "Circle::draw\n";}
void erase() { std::cout << "Circle::erase\n";}
};
class Square : public Shape {
public:
Square() {}
~Square() { std::cout << "Square::~Square\n"; }
void draw() { std::cout << "Square::draw\n";}
void erase() { std::cout << "Square::erase\n";}
};
class Line : public Shape {
public:
Line() {}
~Line() { std::cout << "Line::~Line\n"; }
void draw() { std::cout << "Line::draw\n";}
void erase() { std::cout << "Line::erase\n";}
};
#endif // SHAPE_H ///:~Cela utilise la structure classique des fonctions virtuelles dans la classe de base, qui sont redéfinies dans la classe dérivée. Remarquez que la classe Shape inclut un destructeur virtuel, ce que vous devriez automatiquement ajouter à chaque classe dotée de fonctions virtuelles. Si un conteneur stocke des pointeurs ou des références vers des objets Shape, alors quand les destructeurs virtuels sont appelés pour ces objets tout sera proprement nettoyé.
Chaque type de dessin dans l'exemple suivant fait usage d'un type différent de classe conteneur via les templates : PStash et Stack qui ont été définies dans ce chapitre, et la classe vector de la bibliothèque standard du C++. L'utilisation des conteneurs est extrêmement simple, et en général l'héritage ne constitue pas la meilleure approche (la composition paraît plus logique), mais dans le cas présent l'héritage est une approche simple et n'amoindrit pas l'aspect abordé dans l'exemple.
//: C16:Drawing.cpp
#include <vector> // Utilise les vecteurs standard également !
#include "TPStash2.h"
#include "TStack2.h"
#include "Shape.h"
using namespace std;
// Un dessin est fondamentalement un conteneur de Shapes :
class Drawing : public PStash<Shape> {
public:
~Drawing() { cout << "~Drawing" << endl; }
};
// Un Plan est un autre conteneur de Shapes :
class Plan : public Stack<Shape> {
public:
~Plan() { cout << "~Plan" << endl; }
};
// Un Schematic est un autre conteneur de Shapes :
class Schematic : public vector<Shape*> {
public:
~Schematic() { cout << "~Schematic" << endl; }
};
// Un template de fonction :
template<class Iter>
void drawAll(Iter start, Iter end) {
while(start != end) {
(*start)->draw();
start++;
}
}
int main() {
// Chaque type de conteneur a
// une interface différente :
Drawing d;
d.add(new Circle);
d.add(new Square);
d.add(new Line);
Plan p;
p.push(new Line);
p.push(new Square);
p.push(new Circle);
Schematic s;
s.push_back(new Square);
s.push_back(new Circle);
s.push_back(new Line);
Shape* sarray[] = {
new Circle, new Square, new Line
};
// Les itérateurs et le template de fonction
// leur permet d'être traité de manière générique :
cout << "Drawing d:" << endl;
drawAll(d.begin(), d.end());
cout << "Plan p:" << endl;
drawAll(p.begin(), p.end());
cout << "Schematic s:" << endl;
drawAll(s.begin(), s.end());
cout << "Array sarray:" << endl;
// Fonctionne même avec les tableaux de pointeurs :
drawAll(sarray,
sarray + sizeof(sarray)/sizeof(*sarray));
cout << "End of main" << endl;
} ///:~Les différents types de conteneurs contiennent tous des pointeurs vers Shape et des pointeurs pour transtyper des objets des classes dérivées de Shape. Toutefois, grâce au polymorphisme, le comportement correct se produit toujours quand les fonctions virtuelles sont appelées.
Remarquez que sarray, le tableau de Shape* peut aussi être considéré comme un conteneur.
XVII-H-1. Les templates de fonction▲
Dans drawAll( ) vous voyez quelque chose de nouveau. Jusqu'ici, dans ce chapitre, nous n'avions utilisé que des templates de classes, qui instancient des nouvelles classes basées sur un ou plusieurs types paramètrés. Toutefois, vous pouvez facilement créer des templates de fonction, qui créent de nouvelles fonctions basées sur les types paramètrés. La raison pour laquelle vous créez un template de fonction est la même que celle qui motive les templates de classes : vous essayez de créer du code générique, et vous le faites en retardant la spécification d'un ou de plusieurs types. Vous voulez juste dire que ces types paramètrés supportent certaines opérations, mais pas quels types ils sont exactement.
Le template de fonction drawAll( ) peut être considéré comme un algorithme(et c'est comme cela que sont appelés la plupart des templates de fonctions dans la bibliothèque standard du C++). Il dit juste comment faire quelque chose avec des itérateurs décrivant un ensemble d'éléments, tant que ces itérateurs peuvent être déréférencés, incrémentés, et comparés. C'est exactement le type d'itérateurs que nous avons développés dans ce chapitre, et aussi – pas par coïncidence – le type d'itérateurs qui sont produits par les conteneurs dans la bibliothèque standard du C++, mise en évidence par l'utilisation de vector dans cet exemple.
Nous aimerions également que drawAll( ) fût un algorithme générique, afin que les conteneurs puissent être de n'importe quel type et que nous n'ayons pas à écrire une nouvelle version de l'algorithme pour chaque type de conteneur différent. C'est là que les templates de fonctions sont essentiels, parce qu'ils génèrent automatiquement le code spécifique pour chaque type de conteneur. Mais sans l'indirection supplémentaire fournie par les itérateurs, cette généricité ne serait pas possible. C'est pourquoi les itérateurs sont importants ; ils vous permettent d'écrire du code à visée générale qui implique les conteneurs sans connaitre la structure sous-jacente du conteneur. (Notez qu'en C++ les itérateurs et les algorithmes génériques requièrent les templates de fonction pour fonctionner.)
Vous pouvez en voir la preuve dans main( ), puisque drawAll( ) fonctionne sans modification avec chaque type de conteneur différent. Et, encore plus intéressant, drawAll( ) fonctionne également avec des pointeurs vers le début et la fin du tableau sarray. Cette capacité à traiter les tableaux comme des conteneurs est intégrée à la conception de la bibliothèque standard du C++, dont les algorithmes ressemblent beaucoup à drawAll( ).
Parce que les templates de classes de conteneurs sont rarement soumis à l'héritage et au transtypage ascendant que vous voyez avec les classes “ordinaires”, vous ne verrez presque jamais de fonctions virtuelles dans les classes conteneurs. La réutilisation des classes conteneurs est implémentée avec des templates, pas avec l'héritage.
XVII-I. Résumé▲
Les classes conteneurs sont une partie essentielle de la programmation orientée objet. Ils sont une autre manière de simplifier et de dissimuler les détails d'un programme et d'en accélérer le processus de développement. En outre, ils fournissent beaucoup plus de sécurité et de flexibilité en remplaçant les tableaux primitifs et les techniques relativement grossières de structures de données trouvées en C.
Comme le programmeur client a besoin de conteneurs, il est essentiel qu'ils soient faciles à utiliser. C'est là que les template s interviennent. Avec les templates la syntaxe pour la réutilisation du code source (par opposition à la réutilisation du code objet fournie par l'héritage et la composition) devient suffisamment simple pour l'utilisateur novice. De fait, réutiliser du code avec les templates est nettement plus facile que l'héritage et la composition.
Bien que vous ayez appris comment créer des classes de conteneurs et d'itérateurs dans ce livre, il est en pratique beaucoup plus opportun d'apprendre les conteneurs et itérateurs de la bibliothèque standard du C++, puisque vous pouvez vous attendre à ce qu'ils soient disponibles sur chaque compilateur. Comme vous le verrez dans le Volume 2 de ce livre (téléchargeable depuis www.BruceEckel.com), les conteneurs et les algorithmes de la bibliothèque standard du C++ satisferont presque toujours vos besoins et vous n'avez donc pas besoin d'en créer vous-mêmes de nouveaux.
Certaines questions liées à la conception des classes de conteneurs ont été abordées dans ce chapitre, mais vous avez pu deviner qu'ils peuvent aller beaucoup plus loin. Une bibliothèque compliquée de classes de conteneurs peut couvrir toutes sortes d'autres aspects, en incluant le multithreading, la persistance et le ramasse-miettes (garbage collector, ndt).
XVII-J. Exercices▲
Les solutions à certains exercices peuvent être trouvées dans le document électronique The Thinking in C++ Annotated Solution Guide, disponible pour une somme modique sur www.BruceEckel.com.
- Implémentez la hiérarchie du diagramme OShape de ce chapitre.
- Modifiez le résultat de l'exercice 1 du Chapitre 15 de façon à utiliser Stack et iterator dans TStack2.h au lieu d'un tableau de pointeurs vers Shape. Ajoutez des destructeurs à la hiérarchie de classe afin que vous puissiez voir que les objets Shape sont détruits quand le Stack sort de la portée.
- Modifiez TPStash.h de telle sorte que la valeur d'incrément utilisée par inflate( ) puisse être changée durant la durée de vie d'un objet conteneur particulier.
- Modifiez TPStash.h de façon à ce que la valeur d'incrément utilisée par inflate( ) se réajuste automatiquement pour réduire le nombre de fois nécessaires à son appel. Par exemple, à chaque fois qu'elle est appelée, elle pourrait doubler la valeur de l'incrément à utiliser dans l'appel suivant. Démontrez cette fonctionnalité en en rapportant chaque fois qu' inflate( ) est appelée, et écrivez du code test dans main( ).
- Transformez en template la fonction fibonacci( ) sur le type de valeur qu'elle produit (de façon qu'elle puisse produire des long, des float, etc. au lieu d'uniquement des int).
- En utilisant la bibliothèque standard du C++ vector comme implémentation sous-jacente, créez une classe template Set qui accepte uniquement un seul de chaque type d'objet que vous placez dedans. Faites une classe iterator imbriquée qui supporte le concept de “sentinelle de fin” développé dans ce chapitre. Écrivez un code de test pour votre Set dans main( ), puis substituez le template set de la bibliothèque standard du C++ pour vérifier que son comportement est correct.
- Modifiez AutoCounter.h afin qu'il puisse être utilisé comme objet membre au sein de n'importe quelle classe dont vous voulez suivre la création et la destruction. Ajoutez un membre string pour retenir le nom de la classe. Testez cet outil dans une classe de votre cru.
- Créez une version de OwnerStack.h qui utilise un vector de la bibliothèque standard du C++ comme implémentation sous-jacente. Vous pourriez avoir besoin de chercher certaines des fonctions membres de vector pour ce faire (ou bien regardez simplement le fichier d'en-tête <vector>).
- Modifiez ValueStack.h de façon à ce qu'elle croisse dynamiquement lorsque vous empilez des objets avec push( ) et qu'elle se trouve à court d'espace. Modifiez ValueStackTest.cpp pour tester la nouvelle fonctionnalité.
- Répétez l'exercice 9, mais utilisez un vector de la bibliothèque standard du C++ comme implémentation interne de ValueStack. Notez comme s'est plus facile.
- Modifiez ValueStackTest.cpp de façon à utiliser un vector decla bibliothèque standard du C++ au lieu d'un Stack dans main( ). Notez le comportement à l'exécution : est-ce que le vector crée automatiquement un paquet d'objets par défaut lorsqu'il est créé ?
- Modifiez TStack2.h de telle sorte qu'elle utilise un vector de la bibliothèque standard du C++ comme implémentation sous-jacente. Assurez-vous que vous ne modifiez pas l'interface, pour que TStack2Test.cpp fonctionne sans modification.
- Répétez l'exercice 12 en utilisant une stack de la bibliothèque standard du C++ au lieu d'un vector(vous pouvez avoir besoin de chercher de l'information sur stack ou bien d'examiner le fichier d'en-tête <stack>).
- Modifiez TPStash2.h de telle sorte qu'elle utilise un vector de la bibliothèque standard du C++ comme implémentation sous-jacente. Assurez-vous que vous ne modifiez pas l'interface, pour que TPStash2Test.cpp fonctionne sans modification.
- Dans IterIntStack.cpp, modifiez IntStackIter pour lui donner un constructeur “sentinelle de fin”, et ajoutez operator== et operator!=. Dans main( ), utilisez un itérateur pour vous déplacer à travers des éléments du conteneur jusqu'à ce que vous ayez atteint la sentinelle de fin.
- En utilisant TStack2.h, TPStash2.h, et Shape.h, instanciez les conteneurs Stack et PStash pour des Shape*, remplissez-les avec un assortiment de pointeurs Shape upcastés, puis utilisez les itérateurs pour vous déplacer à travers chaque conteneur et appelez draw( ) pour chaque objet.
- Transformez en template la classe Int dans TPStash2Test.cpp de façon à ce qu'elle puisse contenir n'importe quel type d'objet (sentez-vous libre de modifier le nom de la classe en quelque chose de plus approprié).
- Transformez en template la classe IntArray dans IostreamOperatorOverloading.cpp du chapitre 12, en paramétrant à la fois le type d'objet qu'elle contient et la taille du tableau interne.
- Changez ObjContainer(dans NestedSmartPointer.cpp du chapitre 12) en template. Testez avec deux classes différentes.
- Modifiez C15:OStack.h et C15:OStackTest.cpp en transformant en template la class Stack de telle sorte qu'elle hérite automatiquement de la classe contenue et d' Object(héritage multiple). La Stack générée devrait accepter et produire uniquement des pointeurs du type contenu.
- Répétez l'exercice 20 en utilisant vector au lieu de Stack.
- Dérivez une classe StringVector de vector<void*> et redéfinissez les fonctions membres push_back( ) et operator[] pour n'accepter et ne produire que des string*(et réalisez le transtypage approprié). À présent créez un template qui créera automatiquement une classe conteneur pour faire la même chose pour des pointeurs de n'importe quel type. Cette technique est souvent utilisée pour réduire le gonflement de code résultant de nombreuses instanciations de template.
- Dans TPStash2.h, ajoutez et testez un operator- à PStash::iterator, suivant la logique de operator+.
- Dans Drawing.cpp, ajoutez et testez une fonction template pour appeler les fonctions membres erase( ).
- (Avancé) Modifiez la classe Stack dans TStack2.h pour permettre une granularité complète de la propriété : ajoutez un signal à chaque lien pour indiquer si ce lien possède l'objet vers lequel il pointe, et supportez cette information dans la fonction push( ) et dans le destructeur. Ajoutez des fonctions membres pour lire et changer la propriété de chaque lien.
- (Avancé) Modifiez PointerToMemberOperator.cpp du Chapitre 12 de telle sorte que FunctionObject et operator->* soient des templates qui puissent fonctionner avec n'importe quel type de retour (pour operator->* vous aurez à utilisez des templates membres décrits au volume 2). Ajoutez et testez un support pour zéro, un et deux arguments dans les fonctions membres de Dog.